时令 发自 凹非寺
量子位 | 公众号 QbitAI
只花120元,效果吊打70000元微调!
腾讯提出一种升级大模型智能体的新方法——无训练组相对策略优化Training-Free GRPO。
无需调整任何参数,只要在提示词中学习简短经验,即可实现高性价比提升模型性能。

实验表明,在数学推理和网页搜索任务上,利用无训练GRPO的DeepSeek-V3.1-Terminus模型展现出显著的跨领域性能提升。
与微调32B模型相比,该方法在671B大型模型上所需训练数据更少、成本更低。

网友不禁表示:
也太划算了吧!

下面具体来看。
将经验知识作为token先验
如今,大语言模型正逐渐成为强大的通用智能体,在复杂问题解决、网页研究等通用任务中表现出色。
然而,在需外部工具(如计算器、API) 和特定提示策略的专业场景中,LLM往往会因对领域需求和工具不熟悉,而导致性能欠佳。
为了弥补上述差距,基于GRPO的强化学习通过参数空间调整实现对模型行为的定向优化。尽管这些方法能有效提升特定任务的能力,但其对LLM参数调优的依赖仍存在多方面挑战:
算力成本高; 跨领域泛化能力弱; 数据稀缺; 收益递减。
参数调优中的这些局限引发了一个根本性问题:在参数空间中应用强化学习是否是唯一可行的方法?能否以非参数化的方式提升LLM智能体的性能,同时降低数据和计算成本?
为此,腾讯优图团队提出了无训练组相对策略优化,通过轻量级的token先验在上下文中学习经验知识,无需修改模型参数即可提升LLM智能体性能。
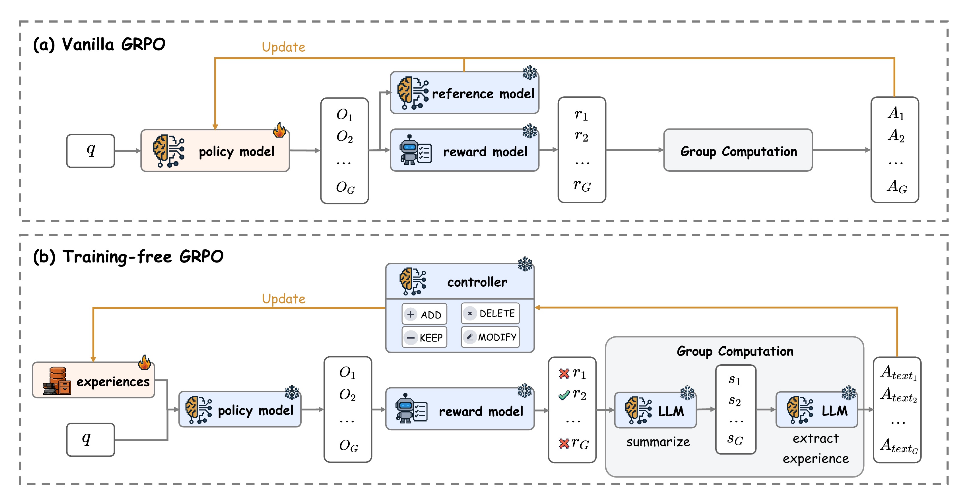
Training-Free GRPO重新利用了传统GRPO基于组间相对评估的核心逻辑,但将其转化为非参数化的推理阶段过程。
该方法保持参数θ永久冻结,转而维护一个外部经验知识库(初始为空集),通过动态更新知识库而非模型参数来实现性能优化。
随后,Training-Free GRPO生成自然语言形式的组相对语义优势。

具体流程如下所示:
1、对于每个输出,免训练GRPO首先让同一个大语言模型M生成对应分析摘要。

2、基于摘要集和当前经验,由M说明每个输出相对成功或失败的原因,然后提取出简明的自然语言经验。
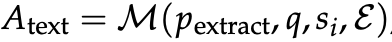
之后,传统GRPO会通过对单个批次中所有优势计算得到的目标函数进行梯度上升,从而更新模型参数θ。
而在Training-Free GRPO中,该方法通过使用当前批次中的所有语义优势A_text来更新经验库,每条操作可能包括:
Add(添加):将A_text中描述的经验直接追加到经验库
中。Delete(删除):根据A_text,从经验库中移除低质量经验。 Modify(修改):根据A_text提供的见解,优化或改进经验库中已有的经验。 Keep(保留):经验库保持不变。
在更新经验库后,条件策略会在随后的批次或训练轮次中生成偏移后的输出分布。
可以说,Training-Free GRPO是通过改变上下文而非模型参数本身,将模型引向高奖励输出。
其中,被冻结的基础模型起到了强先验(strong prior)的作用,不仅保证输出的连贯性,还提供了类似于GRPO中KL散度约束的内在稳定性,防止策略过度偏离参考模型。
实验结果
为评估免训练GRPO方法的性能,团队在数学推理和网络搜索两大基准测试上开展了多维度对比实验。
在实验中,研究主要关注的是现实应用中难以微调且成本高昂的大型高性能LLM,例如DeepSeek-V3.1-Terminus。

实验结果显示,Training-Free GRPO在数学推理任务中取得了显著提升,无论是否使用工具,均表现出明显优势。
基线模型DeepSeek-V3.1-Terminus+ReAct在AIME24和AIME25上的得分分别为80.0%和 67.9%,而应用Training Free GRPO后,冻结模型的表现显著提升至82.7%和73.3%,分别带来2.7%和5.4%的绝对增益。
值得注意的是,这一提升仅使用了100个跨域训练样本,并且无需任何梯度更新。相比之下,传统强化学习方法如ReTool和AFM在32B LLM上通常需要数千个训练样本,成本超过10000美元,而Training Free GRPO仅需约18美元。

在AIME24和AIME25实验中,随着每一步学习,模型表现持续提升,这表明仅从100个问题中学到的经验能够有效泛化,同时也凸显了多步学习的必要性。
此外,在训练过程以及跨域评估中,模型的平均工具调用次数都有所下降。这表明Training-Free GRPO不仅促使模型做出正确的推理和决策,还能教会智能体更高效、更谨慎地使用工具。
学习到的经验知识帮助智能体发现一些捷径,避免错误或冗余的工具调用,从而验证了基于语义优势优化方法的有效性。
在网络搜索任务中,团队选择在WebWalkerQA基准上评估免训练GRPO方法的有效性。

可以看出,该方法在使用DeepSeek-V3.1-Terminus模型时实现了67.8%的Pass@1得分,较基线63.2%有显著提升。
此外,研究还对来自WebWalkerQA的51个实例进行分层随机抽样,以开展消融实验。
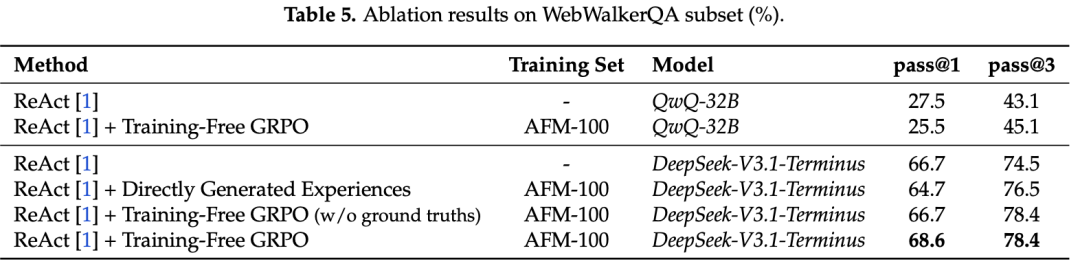
由上图可知,直接使用生成的经验会略微降低ReAct的性能(Pass@1 为64.7%,相比原来的66.7%),这说明仅靠上下文示例而没有经过优化,难以带来性能提升。
不使用真实答案的Training-Free GRPO在Pass@1上与ReAct保持一致(66.7%),但在Pass@3上提升到78.4%,表明即使没有真实答案,通过相对奖励评估也能提高输出的一致性。
完整的Training-Free GRPO则取得了最佳表现(Pass@1为68.6%,Pass@3为78.4%),凸显了结合真实答案指导、语义优势和经验优化的重要性。
此外,研究还验证了模型能力是基于经验优化能否有效的前提条件。
实验将Training-Free GRPO应用于QwQ-32B时,Pass@1仅为25.5%,远低于DeepSeek-V3.1-Terminus的66.7%,甚至低于其自身的ReAct基线(27.5%)。这表明该方法的有效性依赖于基础模型在复杂工具使用场景中的推理和工具使用能力。
论文链接:https://arxiv.org/abs/2510.08191
参考链接:https://x.com/rohanpaul_ai/status/1978048482003890625
Github链接:https://github.com/TencentCloudADP/youtu-agent/tree/training_free_GRPO










