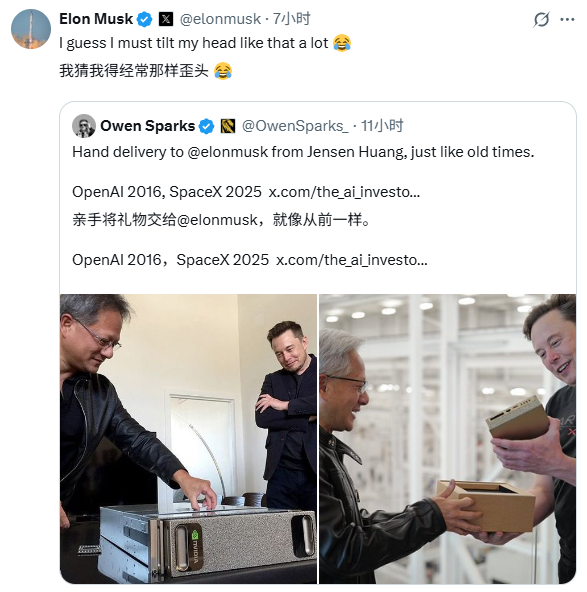
英伟达将在10月15日正式发售DGX Spark,今天他又亲自送给了马斯克一个。
2016年,老黄向马斯克交付了第一款为AI优化的GPU,当时马斯克还是OpenAI的投资人。而9年后,老黄又交给马斯克英伟达最小的超算处理器。
简介
NVIDIA DGX Spark 是英伟达推出的一款革命性 AI 桌面超级计算机,被誉为“世界上最小的 AI 超级计算机”。它将数据中心级别的计算能力浓缩到紧凑的桌面设备中,专为 AI 开发者和研究人员设计,帮助他们在本地高效运行大型 AI 模型,而无需依赖云端资源。这款产品于 2025 年 CES 展会上首次亮相,原计划 5 月上市,但因硬件优化和全球因素推迟至 10 月 15 日正式开售,起售价为 3999 美元(约合人民币 3.5 万元)。
配置

核心规格与性能
处理器与架构:搭载 NVIDIA GB10 Grace Blackwell Superchip,这是一款集成了 20 核 ARM Grace CPU 和 Blackwell GPU 的超级芯片。GPU 配备第五代 Tensor Cores,支持 FP4 精度计算,提供高达 1 petaFLOP(1000 TFLOPS) 的 AI 推理性能。 内存与存储:128GB 统一 LPDDR5X 内存(CPU 和 GPU 共享),支持 NVLink-C2C 技术,带宽是 PCIe Gen 5 的 5 倍。这使得它能轻松加载和运行高达 2000 亿参数 的 AI 模型(如 DeepSeek、Meta 或 Google 的推理模型),在 FP4 量化格式下实现高效推理。 存储:内置 4TB NVMe SSD,便于处理大规模数据集。 尺寸与设计:体积小巧,仅重 2.6 磅(约 1.18 公斤),采用全金属机身,香槟金色外观,前后面板使用金属泡沫设计,散热高效。整体像一个精致的迷你 PC,能轻松放置在办公桌上。
连接性与扩展
DGX Spark 的接口丰富,支持现代办公需求:
4 个 USB-C 端口(其中一个支持高达 240W 电源传输)。 HDMI 输出、10 GbE 以太网口。 两个 QSFP 端口,配备 NVIDIA ConnectX-7 网络卡,支持高达 200 Gbps 速度。 支持 Wi-Fi 7 无线连接。
特别值得一提的是,它允许两个 DGX Spark 通过高速网络互联,形成一个双机集群,总内存达 256GB,能处理高达 4050 亿参数 的超大规模模型,实现无缝扩展。
软件与应用
运行 NVIDIA 定制的 DGX OS(基于 Ubuntu Linux),预装完整的 NVIDIA AI 软件栈,包括 PyTorch、TensorFlow 等主流框架,以及 NVIDIA 的 AI 模型、库和微服务。开发者可以轻松进行模型微调、原型开发、图像生成或聊天机器人创建等任务。它特别适合处理敏感数据,避免云端传输的风险,同时支持从桌面到 DGX 集群的无缝迁移。
英伟达强调,DGX Spark 的出现将“民主化 AI”,让计算资源从昂贵的云集群走向个人桌面,早鸟用户包括 Anaconda、Google、Hugging Face、Meta 和 Microsoft 等巨头,甚至英伟达 CEO 黄仁勋亲自将一台设备交付给 SpaceX 的 Elon Musk。
总之,DGX Spark 不仅是 AI 开发的利器,更是英伟达推动 AI 普惠化的重要一步。如果你是一位 AI 爱好者或专业开发者,这款“桌面超级计算机”值得关注!更多详情可访问 NVIDIA 官网。
NVIDIA DGX Spark 测评结果总结
https://docs.google.com/spreadsheets/d/1SF1u0J2vJ-ou-R_Ry1JZQ0iscOZL8UKHpdVFr85tNLU/edit?pli=1&gid=0=0
根据提供的 Google Sheets 基准测试表格以及网上多来源的评论和评测(如 LMSYS Org、Reddit 的 LocalLLaMA 子版块、The Register、StorageReview 和 HotHardware 等),NVIDIA DGX Spark 在 AI 推理和开发任务中表现出色,尤其适合桌面级本地运行大型语言模型。它搭载 GB10 Grace Blackwell Superchip、128GB 统一内存,支持高达 2000 亿参数模型,但受限于紧凑设计和 273 GB/s 内存带宽,其原始性能不如全尺寸 RTX 系列 GPU(如 RTX Pro 6000 Blackwell Edition,后者约 4-7 倍更快)。以下是关键测评结果的总结,聚焦基准分数、比较和观察。
核心基准结果
测评主要使用 Ollama 和 SGLang 引擎,测试 LLM 推理性能(Prefill:预填充 tokens/秒;Decode:解码 tokens/秒)。所有测试为批次大小 1,除非注明。DGX Spark 在 FP4/FP8 量化下高效运行,但 Prefill 分数较高而 Decode 较低,适合开发而非高吞吐生产。
Ollama 引擎基准(批次大小 1):
SGLang 引擎基准(批次大小 1,FP8 量化):
批次大小扩展测试(SGLang,llama-3.1 8B 示例):
DGX Spark:随着批次从 1 增至 32,Prefill 稳定在 7,000-8,000 tps,Decode 从 20.52 线性提升至 368.09 tps(适合并发请求)。 对比 RTX Pro 6000:Prefill 约 38,000 tps,Decode 高达 2,579 tps(4-7 倍优势)。
与其他系统的比较
RTX Pro 6000 Blackwell Edition:全面领先(例如,llama-3.1 8B q4_K_M:Prefill 38,863 vs. 23,169;Decode 201 vs. 36),但体积更大、功耗更高。 GeForce RTX 5090/5080:小型模型上略胜(Prefill 高 20-30%),但大型模型(如 70B)DGX Spark 更稳;RTX 5090 Decode 达 200 tps。 Mac Studio M1 Max:显著落后(Prefill 仅 457 vs. 23,169),但内存带宽更高(819 GB/s vs. 273 GB/s)。 AMD Strix Halo:规格类似(128GB 统一内存),但 TOPS 仅 126(DGX Spark 达 1,000 TFLOPS FP4),x86 支持更好,适合 Windows 任务。
网上其他测评观察
性能亮点:LMSYS Org 评测显示,DGX Spark 在高负载下无热节流,风扇噪音低,适合长时间推理(如 DeepSeek-R1 14B 批次 8:2,074 tps Prefill)。The Register 测试了 Flux.1 Dev 图像生成(BF16 精度,4 小时微调成功),强调其在扩散模型上的潜力,而非纯速度。 软件与扩展:运行 DGX OS(Ubuntu 24.04 定制版),支持 PyTorch/TensorFlow、NIM 微服务。StorageReview 赞扬 NVMe-oF RDMA 网络(200 Gbps),便于集群(双机达 4050 亿参数)。HotHardware 确认 6144 CUDA 核心,支持 1 PFLOPS FP4 计算。 局限性:Reddit 用户批评价格高($3999 vs. 等效 M3 Ultra),ARM 架构不支持 Windows/游戏;内存带宽瓶颈导致大型模型 Decode 慢(<10 tps)。软件早期阶段,未来更新可优化 20-30% 性能。 适用场景:理想用于 AI 原型开发、敏感数据本地测试(如医疗/金融),而非高吞吐生产。NVIDIA 定位为“桌面超级计算机”,易迁移到 DGX 集群。
总体而言,DGX Spark 的测评结果肯定其工程创新和本地 AI 普惠,但性能更偏向“足够好”而非顶级。
国产的DGX Spark
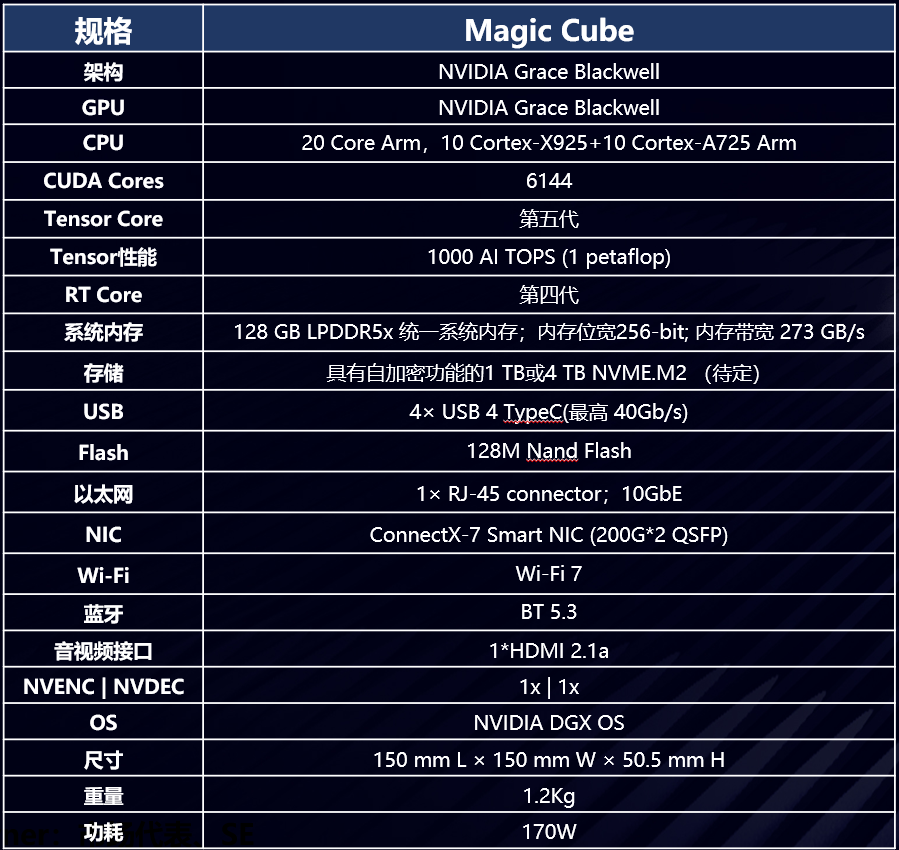
最近华三也出了一款国产版的DGX Spark,规格如下:

产品优势:
NV最新Blackwell架构支持FP4精度,NVFP4较FP8几乎不损失准确度; 单台设备128G内存,在较低投入的情况下即可运行200B模型、做70B模型微调;相较采用L20显卡,由于仅支持FP8,至少需要4张L20组成的服务器,成本极高;
性能:
统一寻址内存128GB, 显存位宽256bit,带宽273GB/s; 最多支持2台设备级联,最大支持405B(FP4)模型; 在高并发情况下token响应速度有上限,对高模型参数量、高精度模型支持有上限;
目标市场及产品定位:
对token生成速度要求不高的200B-400B参数模型推理场景; 对70B模型的微调有需求的场景; 在以上场景中,LinSeer Magic Cube相较与常规GPU组成的服务器有较大的成本、空间占用、易用性的优势; 目标用户为企业开发人员、科研人员及学生、数据科学家等需要;
实际的产品真的非常小:











