清华大学智能产业研究院(AIR)与上海人工智能实验室联合发布全新通用跨本体具身基座模型:X-VLA。X-VLA是首个实现120min无辅助自主叠衣任务的全开源模型(公开数据、代码与参数),以仅0.9B的参数量在五大权威仿真基准上全面刷新性能纪录,为具身智能领域提供了一个性能强劲、完全开源的新基线与技术范式。
•项目主页:https://thu-air-dream.github.io/X-VLA/
•代码:https://github.com/2toinf/X-VLA.git
•作者:Jinliang Zheng*, Jianxiong Li*, Zhihao Wang, Dongxiu Liu, Xirui Kang, Yuchun Feng, Yinan Zheng, Jiayin Zou, Yilun Chen, Jia Zeng, Ya-Qin Zhang, Jiangmiao Pang, Jingjing Liu, Tai Wang, Xianyuan Zhan

核心亮点
性能突破:率先实现超长时序灵巧操作任务(如自主叠衣)的全流程开源,攻克长期复杂自主作业难题。
极致高效:仅0.9B超轻量参数,即在五大仿真基准上实现SOTA性能,达成卓越的效费比。
创新技术:打破大规模异构数据训练难题,通过Soft-Prompt与定制化训练范式,构建出高效通用的跨本体基座模型。
开源开放:完整公开模型参数、代码与训练数据,助力具身智能社区复现与创新。

核心方法
1.高效模型设计
面向本体泛化的Soft-Prompt机制:为克服不同机器人平台在自由度、相机观测视角等本体参数上的差异,本研究引入了可学习的Soft-Prompt。该机制动态地将具身本体的硬件配置信息编码为一种连续表征,使模型在预训练中能够解耦任务策略与具体执行器,从而显著增强模型对异构机器人平台的适应能力,并提升混合数据训练的稳定性与效率。
基于功能分工的多模态编码策略:针对机器人任务中多源视觉输入的异质性,我们提出了分治编码方案。任务相关的主视角图像由高性能视觉-语言模型编码,以提取高层语义特征;而主要提供低层次空间反馈的辅助视角,则通过轻量化的网络进行局部特征提取。该策略在保证信息完整性的前提下,优化了计算资源的分配,提升了模型的信息处理通量。
基于flow-macthing的生成式动作解码器:模型主干采用标准Transformer架构,以确保良好的扩展性与通用性。动作生成模块摒弃了传统的确定性输出策略,转而采用先进的flow-matching,以概率生成的方式建模机器人动作序列。该方法显著增强了动作轨迹的平滑性与对不确定环境的鲁棒性,为长时序任务的成功执行奠定了坚实基础。

2.大规模高质量异构数据预训练
平衡化数据采样:定制数据采样策略,确保异构数据集的均衡训练,避免模型偏斜。
多模态数据清洗与时空对齐流水线:我们对原始机器人操作数据实施了严格预处理,包括:将不同空间下的动作数据统一映射至标准任务空间;对高频率采集的数据进行时序层面的对齐与重采样。此流程极大提升了状态-动作序列在时间上的一致性逻辑与整体质量。
以语义-动作对齐为导向的数据遴选标准:我们确立了严格的数据质量门槛,核心是筛选视觉帧清晰、语言指令描述精准且与后续动作序列高度关联的数据样本。此举从源头上确保了模型学习到的是有明确因果关系的“行为知识”,而非浅层的虚假关联。

3.定制后训练流程与技巧
分层分组的自适应学习率调整:鉴于模型中不同组件(如预训练冻结的VLM、新引入的Soft-Prompt、主干Transformer等)的参数规模与收敛特性各异,我们为其施加了分组别、差异化的学习率调度策略。该设计既保护了预训练获得的基础知识,又允许关键适配层快速调整,从而在保证训练稳定性的同时,大幅优化了收敛效率。
面向异构模块的渐进式 warm-up 策略:对于模型中新引入的可学习参数(如Soft-Prompt),我们在训练初始阶段采用线性递增的学习率热身机制,使其参数空间得以平稳初始化,再逐步融入全局优化过程。该策略有效避免了训练初期因梯度剧变导致的不稳定性,尤其适用于异构模块的协同训练。
实验结果
高效预训练:可扩展的架构优势
X-VLA 的预训练缩放定律(Scaling Laws)曲线呈现出优异的线性增长趋势。这表明,随着模型参数以及训练数据规模的同步扩大,其在测试集的开环测试性能呈现稳定、可预测的提升。这一现象验证了所提出的 Soft-Prompt 机制与简洁Transformer架构的强大可扩展性,为构建更大规模的具身智能基座模型奠定了坚实基础。

高效后训练:数据与算法的协同优化
得益于高质量的预训练基座,X-VLA 在后训练(微调)阶段展现出极高的数据效率与稳定性。针对不同的下游任务(如自主叠衣),只需使用中小规模的场景专属数据进行微调,模型便能快速适应并达到SOTA性能。这源于预训练阶段学习到的通用视觉-语言-动作表征,以及后训练中采用的定制化学习率策略与慢启动机制,它们共同确保了知识从通用域到特定任务的高效、稳定迁移。
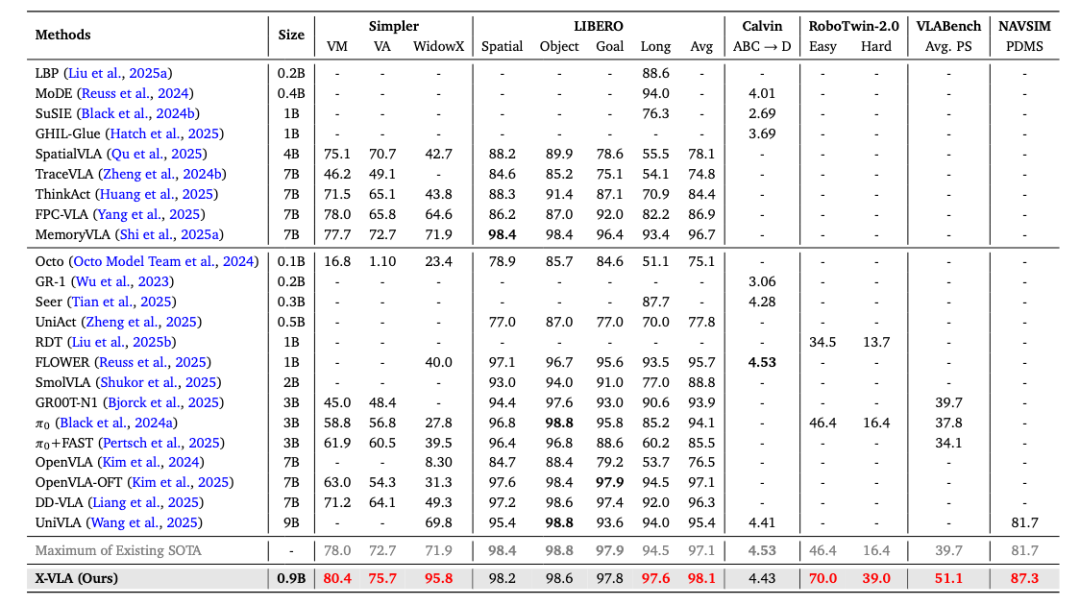
仿真基准测试结果
在包括LIBERO、SIMPLER等在内的权威仿真环境中,X-VLA均取得了SOTA性能,显著优于现有同类模型。
实机实验测试结果
在真实的机器人平台上,X-VLA在大量常规抓取和复杂桌面操作任务中展现了强大性能,并成功完成了不限时长的自主叠衣任务,且可零样本迁移部署至全新的环境,展示了其应对复杂长程任务的卓越能力。详细任务执行效果参见本文开头视频。

AIR长期招聘人工智能领域优秀科研人员
点这里关注我们
关于AIR