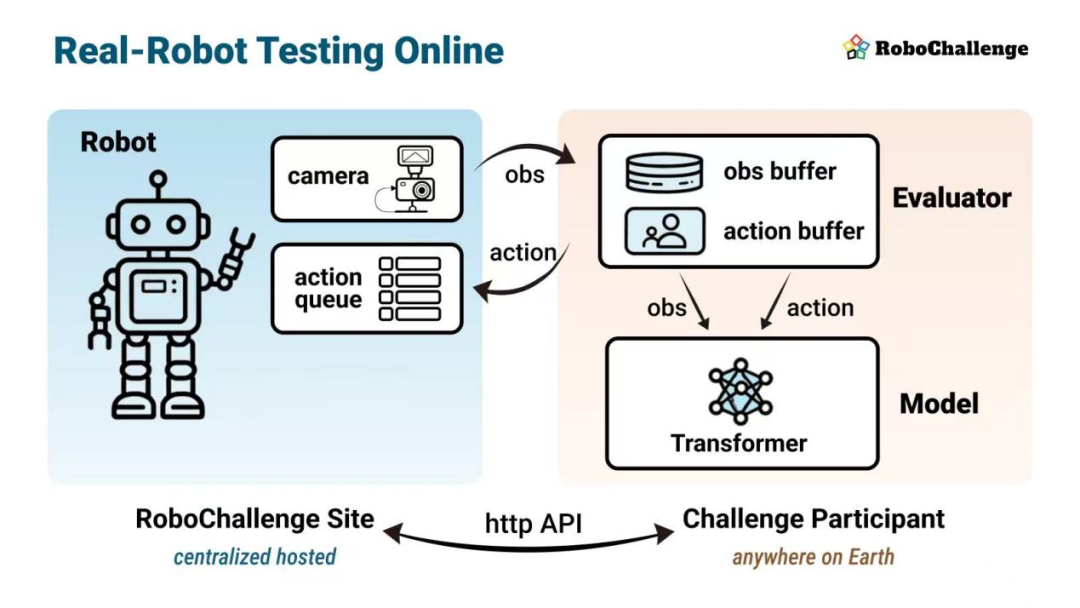
机器人想落地干活,还需要这场真机大考。作者 | 许丽思编辑 | 漠影机器人在视频demo里样样精通,现实里它到底能不能稳定干活?这成了具身智能的新追问。机器人在理想场景中精准抓取、灵巧叠放、丝滑搬运,每一帧都看起来近乎完美。但离开实验室和背景幕布,麻烦就来了。要让机器人从实验室迈向现实世界,仅凭个别场景的展示远远不够,必须经过大规模、多任务的真实评测,才能回答是否具备应用的泛化与稳定性的核心问题。谁都能说自己行,但却缺少一套统一、开放且可复现的真机基准体系,能够公正比较不同方法的优劣。这种缺失,使得机器人领域的技术进步难以被标准化衡量,也让落地可用的门槛始终模糊。近日,全球首个大规模、多任务的在真实物理环境中由真实机器人执行操作任务的基准测试——RoboChallenge发布。该测试能够克服真实环境下的性能验证、标准化测试条件、公开可访问测试平台等挑战,为视觉语言动作模型(VLAs)在机器人的实际应用提供更加可靠和可比较的评估标准。据悉,RoboChallenge由Dexmal原力灵机联合Hugging Face共同发起。相关链接如下:官网:https://robochallenge.ai论文:https://robochallenge.ai/robochallenge_techreport.pdfGitHub:https://github.com/RoboChallenge/RoboChallengeInferenceHuggingFace:https://huggingface.co/RoboChallengeAI01.仿真满分、现实翻车,机器人需要真机大考目前,基于仿真的机器人评测已经取得了较大进展,研究人员可以在数字孪生环境中,以极低成本反复训练、调整算法,并快速验证模型性能。但是仿真终归是仿真,容易出现物理建模失真、和真实环境差距大、难以迁移至真实机体等问题,很难刻画机器人在现实中的鲁棒性与泛化能力。想证明机器人真能在现实中稳定工作,必须上真机测试。但当前真机评测仍存在多个瓶颈,比如任务数量普遍太少,大部分评测或竞赛往往仅设置3-5个任务,任务多聚焦于单一操作环节,难以系统评估模型的跨场景泛化能力。更大的问题在于评价机制单一。传统评测通常采用“成功或失败”的二值化标准,只关注任务是否完成,却忽略了执行过程中的细节、效率与鲁棒性。这样的评价方式,不仅掩盖了算法的进步,也很难指导工程优化。而RoboChallenge的创新在于,它将不确定性、统计性与多元性纳入同一体系。构建起一套科学、透明、可复现的评测框架,使得研发人员在统一环境中验证对比机器人算法,实现从基础任务到复杂现实应用场景的全面覆盖。简单来说,RoboChallenge有以下三大亮点:高可靠性的硬件软件系统:用多款经过工业验证的主流机机器人做底座,每台配2–3台RGB-D相机,统一软件栈实现协同控制;整套系统在真实任务里连续跑了数月,抗压、稳定,能长时间运行。更科学的评估机制:采用端到端任务成功率与过程评分相结合的评估机制,精确测出模型代差;测试集所有任务均提供约1000条演示数据,并已完成基线模型的任务级微调。免费开放、可扩展:面向社区开放,支持用户基于公开演示数据微调自有策略并参与评测;发布任务中间数据与评测结果,推动建立透明、公平的算法评估标准,避免“黑箱式”评测。02.零门槛测评:集成多款主流机型,没有机器人也能做实验RoboChallenge的硬件选型并未追求全面复杂、堆花活,而是聚焦在VLA算法的核心能力上。首期采用配备夹爪的机械臂作为标准化平台,未来会支持更多执行器类型。目前的机械臂虽在一定程度上限制了任务复杂度,却能更精准地验证算法在结构化环境中的泛化性能。具体来看,包括四款经过长期验证的工业机械臂产品:UR5、Franka Panda、COBOT Magic Aloha及ARX-5。它们的共性就在于高可靠性和学术通用性,既能同步输出多视角RGB与对齐深度信息,以利于二维识别与三维推理需求,将来计划集成力控或触觉传感器。另外,还能满足7×24小时持续运行。更具突破性的是,RoboChallenge还通过云端化服务打造了一个远程真机实验室,用户没有机器人,一样做实验,打破机器人测试的硬件资源限制。这套远程系统的便捷性与精准性,源于三大技术设计:无容器化服务架构:用户无需提交Docker镜像或完整模型文件,通过标准化API接口就能直接调用真机;所有观测数据(RGB图像、深度信息、本体感知数据)均附带毫秒级时间戳,方便多模型集成与复杂算法验证。双向异步实现精准控制:通过HTTP API,动作指令的异步提交与图像获取可分离处理,用户可自定义数据块长度与动作持续时间,平台还会实时反馈队列状态,确保控制指令精准同步;整个过程无需暴露本地接口,兼顾安全性与便捷性。智能作业调度提升评测效率:平台提供任务调度状态查询接口,用户可提前预估测试运行时间;同时支持模型预加载与多任务并行管理,避免因等待单任务完成浪费时间,大幅提升评测效率。▲远程异地推理对比为进一步降低测试人员技术门槛、确保测试的稳定性,RoboChallenge提出了“视觉输入匹配”方法:从演示数据中抽取参考图像,并实时叠加于测试画面。测试人员通过调整物体位置使实时场景与参考图像完全吻合,确保每次测试的初始状态一致。03.Table30:30个日常情境任务,全面测出模型到底几斤几两如果说硬件和远程机器人测试构成了RoboChallenge的“骨架”,那么Table30就是其“灵魂”。Table30是RoboChallenge的首套桌面操作基准测试集,包含30个精心设计的日常情境任务,由位置固定的双手或单臂机器人执行。Table不止是测试某项技能,而是系统性地考察模型在真实环境中的综合表现。Table30的情景任务由易到难,聚焦在家庭、工作、厨房等日常场景,覆盖了从基础操作到复杂组合的全过程,具体任务有插花、整理果篮、叠抹布、开关水龙头等。这些任务并非随机选择,而是围绕机器人核心能力设计,覆盖了精确3D定位、遮挡与多视角、时间依赖、分阶段与长时程技能、物体识别、双臂协同以及软体物体操作等要素,能够测试模型的多种能力,包括精准定位抓取、理解物体间空间关系、多视角协同运用、双臂交替协作操作、杂乱环境中重复执行技能、记忆多步骤任务阶段。具体点说,插花要精准对位,叠抹布考验对软体物体的操作精度,整理碗具要按照一定顺序进行摆放,开关水龙头需要精准力控。Table30从四个关键维度构建评估体系:VLA模型难点、机器人类型、任务场景环境和目标物体属性。强模型会在哪些维度拉开差距,薄弱环节又藏在哪些地方,跑完一轮,答案一目了然。比如,研究团队测试了流行的四种VLA模型:π0、π0.5、CogACT、OpenVLA/OFT,发现不同模型之间存在显著性能差距,π0.5模型(经微调)在成功率与进度得分的所有分位点上均显著优于其他模型。进一步分析其累积分布曲线可以发现,各模型的任务难度分布斜率相近,表明任务集的难度分布较为均衡。值得一提的是,即便仅使用约50个示范样本并采用混合任务训练,π0.5仍能获得较高表现。在部分任务上,该模型的表现甚至超越了单任务微调版本。不过,像时序理解与软体物体操作等问题仍是当前VLA模型的薄弱环节。评测标准也不再只是任务成功与否,Table30通过引入“进度得分”来更加细致地刻画机器人行为。每个任务被分为若干阶段,每个阶段分配若干进度点。完成某阶段后模型获得相应得分;若阶段被标记为“非关键”,则即便未完成,任务仍可视为成功。结合成功率与进度得分的双指标体系,平台可以更精确地描绘模型的表现曲线,测出模型代差。以打开抽屉任务为例,进度得分能够很好地揭示过程细节:到达抽屉区域、抓手旋转至把手方向、抽屉拉开、机械臂回到初始位置,每一个步骤都设置不同得分。就算模型未完全拉开抽屉,推进了关键步骤也能得分,细微进步不再被失败掩盖;哪怕两个模型都成功了,进度得分也会衡量出它们还有哪些细微差别。为保障参与者体验,RoboChallenge建立了一套标准化的提交模型至测试平台的流程:数据获取:从Hugging Face平台下载任务示范数据集,包含分开放置的视频文件与JSON格式状态数据,可通过工具脚本转换为LeRobot格式;训练模式:可选通用型或微调型模式,通用型需用提示词区分任务并开展多任务联合训练,微调型无特殊限制;基于同一基础模型的多次提交可共享名称,排名时合并为单一算法条目;API对接:提供框架代码演示“观察-推理-停止”的完整交互逻辑,支持评估前的模型预热与动作队列稳定控制,还配套模拟测试功能,确保提交前模型能正常运行;提交时需注明密钥、任务集及模型名称,多任务提交将按通用模型处理;结果查询:评估请求进入人工调度队列,因场景布置需数小时至数日;结果发布后,研究者可通过rerun.io查看器分析RRD 格式机器日志与视频;平台默认公开结果以促进交流,对评分存疑可申请重新计算。04.结语:推动构建协同创新社区,未来将开放更多基准测试RoboChallenge的价值不止于提供一套评测标准,它更像一座连接技术研发与现实落地的桥梁。通过免费开放评测服务、公开任务演示数据与中间结果,它确保了研究的可复现性与透明度;未来,平台还将通过举办挑战赛、研讨会、共享数据等方式推动社区共建,鼓励研究者参与任务设计与优化,共同破解具身智能的核心难题。Table30的出现只是一个起点。据了解,未来RoboChallenge会持续引入移动机器人、灵巧操作装置等更多硬件平台,拓展跨场景任务测试能力;评测维度将从视觉-动作协调延伸至多模态感知、人机协作等方向,并计划推出动态环境适应、长期规划等更具挑战性的基准测试。当机器人“会不会”变成“能不能长期稳定地做好”,研究就不再是少数人的比赛,而是与每个人相关的进步。RoboChallenge 的出现,将让业界优秀的机器人模型能更快被证明、被迭代、被落地,也让机器人离我们的衣食住行更近一步。