

Google DeepMind 为机器人 “自主进化” 按下的加速键
长期以来,尽管基于网页级数据预训练的具身基础模型(EFM)革新了机器人领域,但这些模型的低阶控制能力始终被困在 “行为克隆” 的框架里 ——
想要提升性能,只能靠人类不断演示新行为、扩大数据集再重新训练,不仅人工成本极高,还让机器人陷入 “只会模仿、不会创新” 的困境。
DeepMind 最新发表的《SELF-IMPROVING EMBODIED FOUNDATION MODELS》,瞄准这一核心痛点:
借鉴大语言模型(LLM)“监督微调 + 强化学习” 的后训练思路,提出了一套 “两阶段后训练框架”。
这套框架彻底打破了机器人 “被动学习” 的循环,首次实现了具身智能从 “模仿” 到 “自主提升” 的跨越,不仅大幅降低训练成本,还能让机器人学会超出演示数据范畴的新技能。

方法
Google DeepMind提出的后训练框架如图所示,它包含2个阶段:
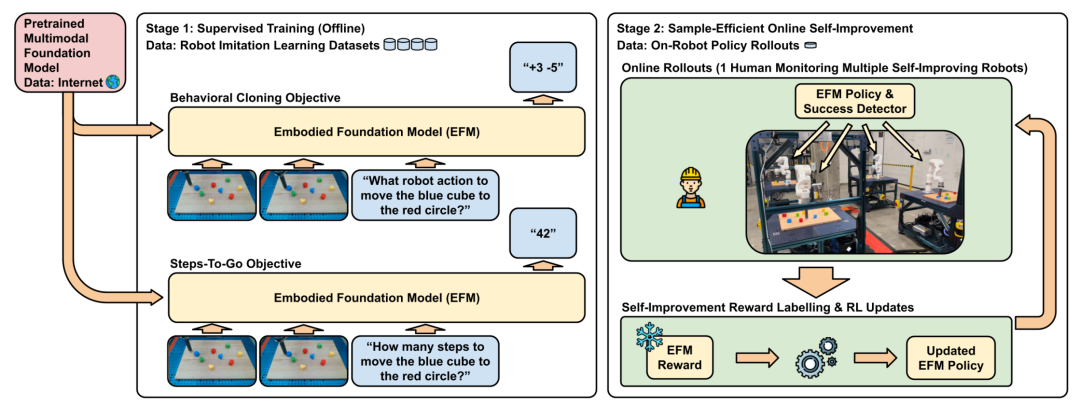
第一阶段:监督微调(SFT)
以预训练的多模态基础模型为起点,利用机器人模仿学习数据集对嵌入式基础模型(EFM)进行微调。
这一阶段有两个核心目标:
① 行为克隆:让模型学习模仿数据集中的动作,使模型在给定相似观测和目标时,能输出与数据集中类似的动作。
② 剩余步数预测:让模型学习根据当前观测状态与目标信息,精准预测距离完成任务还需要的时间步数。

第二阶段:自改进阶段(Self-Improvement)
该阶段的目标是通过“模型生成信号+在线强化学习”,让机器人在极少人类监督下自主优化策略,快速提升其在下游任务上的性能, 还能让机器人掌握那些在训练数据中未出现过的任务或技能。
根据其伪代码,我们来分析下整个流程:

Step1:前期准备:确定基准模型与初始化策略
从第一阶段(监督微调)的训练结果中,选取一个性能稳定的 checkpoint并冻结参数,用于后续“奖励计算”和“成功检测”;另外选一个第一阶段性能更优的checkpoint作为第二阶段初始化的策略;
Step2:收集数据
首先创建一个空的回放缓存(Replay Buffer),用于存储训练数据。
① 回放缓存的作用是什么?
机器人在自主练习时,会生成大量 “时间步级” 的经验,如当前观测、执行的动作、任务目标、动作带来的奖励、下一观测等。
回放缓存的首要功能就是将这些分散的经验按 “元组” 形式统一存储,避免数据随训练流程实时丢弃。后续策略更新时,可从缓存中重复采样数据,无需每次更新都重新收集新轨迹,大幅提升样本利用率。

② 收集数据的策略是什么呢?
从任务指令集合中采样一个目标指令,基于目标指令,在环境中使用当前策略进行动作推理,将这些“观测-动作-剩余步数” 的序列数据记录下来,当满足以下条件之一时,就认为一个episode完成了.
终止条件如下:
实时调用成功检测器进行检测,当检测到成功时可退出;
达到预设的最大episode长度;
人工手中终止。
③ 成功检测器又是怎么设计的?
成功检测器的设计完全基于第一阶段监督微调模型的"剩余步数预测(steps-to-go)"能力:
模型会根据当前机器人的观测与任务目标,输出“完成目标还需的剩余步数”。
Step3:奖励计算和策略更新
当完成1个episode后,就进行蒙特卡洛回报计算,然后将episode保存到Replay Buffer,直到Replay Buffer收集到足够数据,就使用REINFORCE损失来更新策略。
奖励函数如何设计?
奖励函数表示从当前状态 到目标 的期望步数, 这种奖励函数的 使得, 如果机器人在执行动作后更接近目标, 就会获得正奖励;如果远离目标, 就获得负奖励。
蒙特卡洛回报的作用是什么?
通过累积未来奖励, 衡量 “当前动作对整个任务成功的长远贡献”。
小结:纵观第二阶段的整个设计,为什么说这是一个可以自改进的架构呢?
我们认为,之所以说是一个可以自改进的模型架构,核心在于从信号生成、策略优化到运维的全流程实现了高度自主化,无需大量人工干预即可持续提升机器人任务能力:
该架构依托第一阶段冻结的基准模型,自主生成奖励函数(通过剩余步数预测差值来量化动作价值)以及成功检测器(基于剩余步数阈值判定任务完成),无需人工设计奖励规则或标注成功样本;
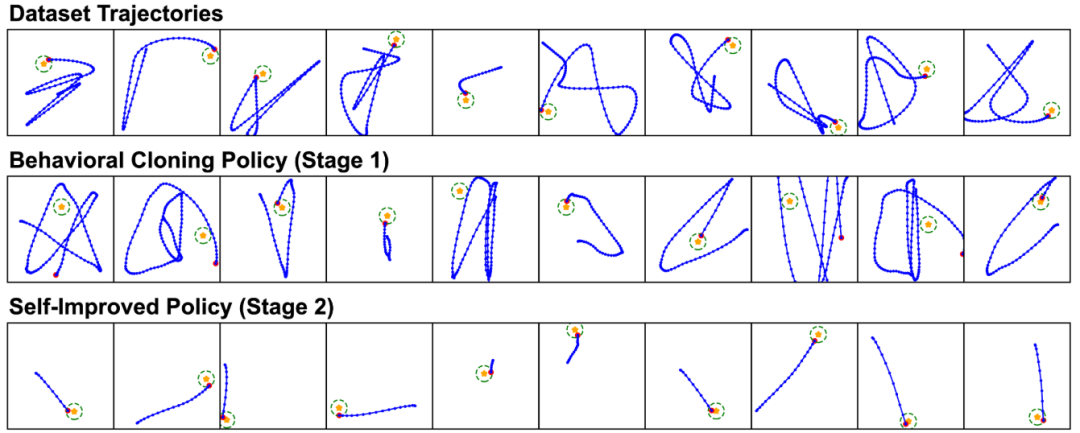
▲说明|从模仿学习数据集以及 BC(第 1 阶段)和自我改进(第 2 阶段)策略中采样轨迹。©️【深蓝具身智能】编译
然后机器人集群能自主抽取任务、执行策略并收集“观测-动作-奖励”轨迹数据,再通过 REINFORCE算法+蒙特卡洛回报(量化动作的长期价值)在线更新策略,让高回报动作更易被选择,形成“自主收集数据-优化策略”的闭环。

实验
实验部分试图验证提出的”自改进“框架的有效性,并回答以下几个问题:
Q1:自改进(Self-Improvement)阶段能否在监督学习阶段的基础上,进一步提升下游任务的性能?
Q2:监督学习与自改进相结合的方式,是否比单纯的监督学习具有更高的样本效率?
Q3:依赖强化学习(RL)的自改进机制,其可靠性和可复现性是否足以应用于真实世界的机器人场景?
Q4:预训练过程对自改进流程有何贡献?
Q5:大规模网络基础模型预训练,是否能让自改进机制在模仿学习数据集中未出现的任务上生效?
针对上面的问题,论文做了以下几个实验:
自改进机制的有效性、稳健性与效率实验
实验目标
验证“监督微调(SFT)+自改进(Self-Improvement)”框架在性能提升、真实场景适配性、效率上的优势。
直接回应研究核心问题 Q1(提升下游任务性能)、Q2(样本效率)、Q3(真实世界可靠性)。
实验内容
以“LanguageTable机器人”和“Aloha双臂机器人”为载体,在“仿真+真实世界” 双场景下进行实验,通过“仅监督学习(BC:行为克隆策略)”与“监督学习+自改进”进行对照,验证框架效果。
具体实验环境如下:

▲说明|LanguageTable机器人的实验环境,任务内容是将指定形状的积木推到目标位置,左侧:用于真实世界实验的4个LanguageTable机器人工作站;右侧上图:真实世界LanguageTable机器人工作站的相机视角;右侧下图:仿真环境中LanguageTable机器人工作站的相机视角©️【深蓝具身智能】编译
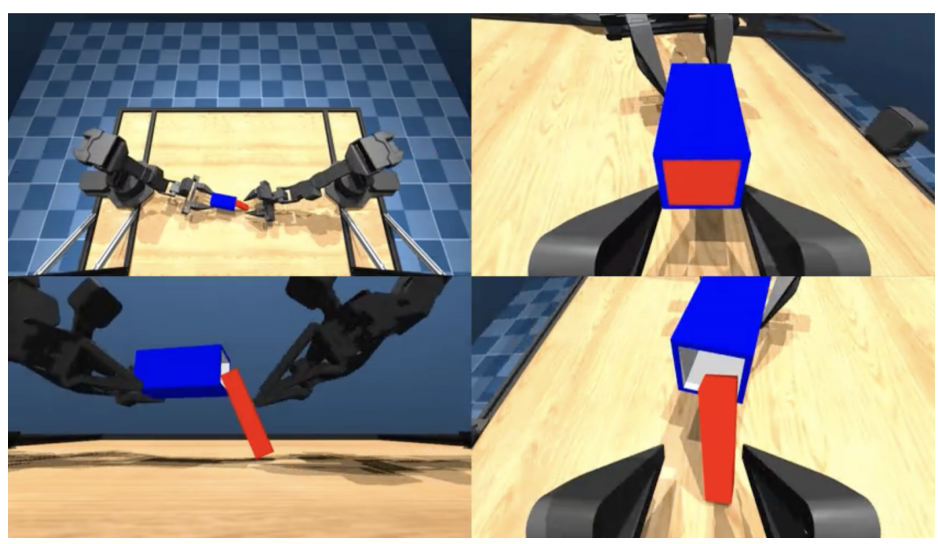
▲说明|仿真环境下Aloha插入任务的四个相机视角,任务内容:左臂抓蓝色套筒,右臂将红色木块插进去©️【深蓝具身智能】编译
实验结果
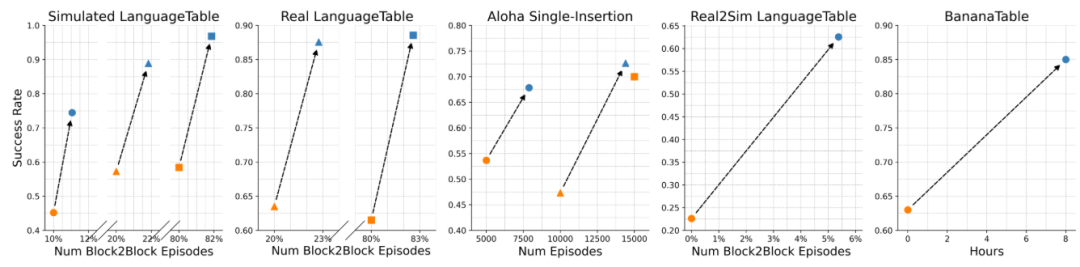
性能提升:自改进显著超越监督学习基线
样本效率:自改进成本远低于“扩大模仿数据”
稳健性:真实世界低监督下稳定可靠

实验结论
回应Q1(自改进能否提升下游任务性能?)
是。无论简单/复杂平台、仿真/真实场景,自改进均能在监督学习基础上提升20-30个百分点成功率,且不受初始数据规模限制。
回应Q2(监督学习+自改进是否更高效?)
是。样本效率远超单纯监督学习:单位性能提升成本仅为“扩大模仿数据”的1/16,少量自主训练可替代数倍人工演示数据。
回应Q3(自改进能否应用于真实世界?)
是。真实环境中具备高可靠性(成功率波动< 2%)与可复现性(多轮实验差异小)。
基础模型预训练重要性实验
实验目标
验证多模态基础模型预训练对自改进(Self-Improvement)流程的支撑作用,明确预训练是否为自改进实现“高样本效率、高稳健性”的关键前提。
直接回应研究核心问题Q4(预训练对自改进流程的贡献)。
实验结果
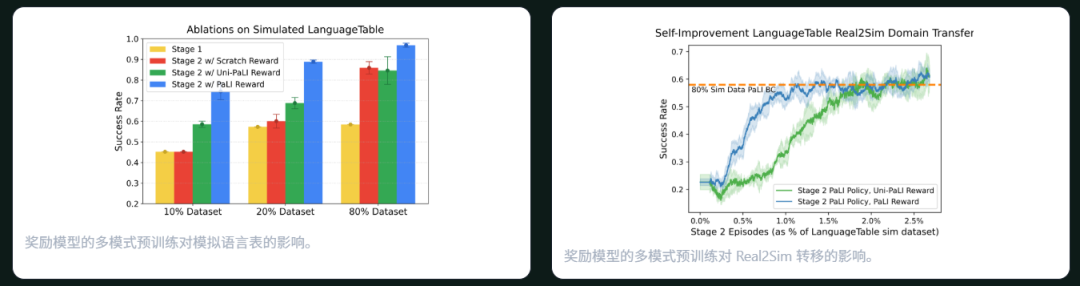
性能呈现明确层级:多模态预训练最优
低数据场景下预训练作用更关键
预训练保障自改进的稳健性
实验结论
回应Q4(预训练对自改进流程的贡献?)
多模态预训练为SFT提供了先验知识,提高了SFT基线的有效性,为自改进奠定基础;另外,预训练可以降低低数据场景下的性能波动,避免自改进失效,还可以加速自改进收敛。
因此多模态预训练可以显著改善自改进策略,是样本效率提升的关键性因素。
泛化性实验
实验目标
验证“预训练多模态基础模型+自改进”的组合能否突破第一阶段模仿学习数据集的局限,实现跨域迁移与全新技能学习这2类泛化能力。
直接回应研究核心问题Q5(大规模预训练能否让自改进在“未见过的任务”上生效)。
实验内容
以“LanguageTable机器人”为核心载体,设计难度逐步提升的两类泛化任务,通过“PaLI多模态预训练模型”与“Uni-PaLI单模态预训练模型”的对比,凸显预训练对泛化的支撑作用。

▲说明|在BananaTable任务上,开展第二阶段(Stage 2)微调前,由于香蕉的几何形态特殊(细长易旋转),策略难以将其在桌面上有效移动。下图左:经过第二阶段微调后,在BananaTable任务上,策略的操作熟练度显著提升。下图右:在对 BananaTable任务开展第二阶段微调前,策略与奖励模型均未接触过任何 BananaTable任务相关数据,这使得该泛化问题极具挑战性。©️【深蓝具身智能】编译
实验结果
跨域迁移(R2S):预训练加速新环境适配
全新技能学习:突破模仿数据行为边界
实验结论
回应Q5(大规模预训练能否让自改进在“未见过的任务”上生效?)
是。大规模网络基础模型预训练为自改进提供了 “超越模仿数据的先验知识”,使其能在两类“未见过的任务”上生效。

总结
本研究以“为机器人基础模型赋予自主进化能力”为核心目标,开创性地将大语言模型“监督微调+强化学习”的两阶段训练范式迁移至机器人领域。
不仅在LanguageTable、Aloha等平台的“仿真+真实世界” 场景中,以单纯监督学习1/16的样本成本将成功率提升20%-30%,更通过多模态预训练与自改进的结合,让机器人首次突破模仿数据局限,自主习得 “推香蕉” 等全新技能,实现行为泛化。
编辑|木木伞
审编|具身君
Ref
论文标题:SELF-IMPROVING EMBODIED FOUNDATION MODELS
论文地址:https://arxiv.org/pdf/2509.15155
项目地址:https://self-improving-efms.github.io/
工作投稿|商务合作|转载
:SL13126828869(微信号)

【具身宝典】||||
【技术深度】|||||||
【先锋观点】|||
【非开源代码复现】||
我们开设此账号,想要向各位对【具身智能】感兴趣的人传递最前沿最权威的知识讯息外,也想和大家一起见证它到底是泡沫还是又一场热浪?
欢迎关注【深蓝具身智能】👇

【深蓝具身智能】的内容均由作者团队倾注个人心血制作而成,希望各位遵守原创规则珍惜作者们的劳动成果。
投稿|商务合作|转载:SL13126828869(微信)

点击❤收藏并推荐本文










