机器人“最后一公里”的灵巧操作瓶颈
世界很大,精度很小;“最后一公里”走不通,等于没到达。
近年来,人工智能在语言理解、视觉识别和规划决策等方面取得巨大进步,但让机器人在物理世界中像人类一样灵活运用双手仍然困难重重。拾取鸡蛋、端起水杯、插拔线缆……这些人类看来轻而易举的日常操作,对机器人而言却是横亘在面前的“最后一公里”难题。根本症结在于:现阶段机器人缺乏大规模、高质量、涵盖多模态(视觉+触觉+运动等)的交互数据来支撑此类精细操作。尤其是涉及力度控制、复杂接触的灵巧手操作,数据短缺更为突出。

图. 人手与灵巧手拿鸡蛋对比
机器人要掌握如人类般灵巧的手部技能,必须解决“看不见的力”信息获取难题。人类之所以能轻松完成抓握易碎鸡蛋等任务,很大程度上依赖于手部密集的触觉神经网络,实时感知物体的质地、重量、微小滑动等,并据此动态调整施力。而机器人目前主要依赖视觉等外部信息,缺乏对接触力的直接感知。这种力反馈的缺失严重限制了机器人执行灵巧操作的能力。正是由于缺少触觉/力觉维度的数据,机器人的灵巧操作能力始终难有质的突破——它们往往“看得到却抓不稳”,难以胜任人类手部那些需要巧劲的工作。
数据困境:“规模-真实-力觉”的不可能三角
量变引起质变”,但劣质的量,只会引来更大的偏差。
面对灵巧手操作这一终极挑战,业界在数据获取上陷入了一个“不可能三角”:规模、真实性、力觉信息三者难以兼得。具体而言:
• 大规模 + 真实:通过真实机器人采集人类演示数据可以获得较高真实性,但受限于成本和效率,数据规模往往只有数千到数万条,而且缺少力觉信息。例如,遥操作让专家用设备控制机器人手获取示范,数据精度高且包含一定力控信息,适合精密任务,但采集设备昂贵、效率低下,人机结构差异导致示范映射困难。
• 大规模 + 力觉:在仿真环境中可以廉价生成海量带力信息的数据,但纯模拟数据缺乏真实性,仿真与现实的鸿沟(sim2real gap)使模型难以直接落地。
• 真实 + 力觉:实验室可以用特制传感器采集少量真实力数据,但往往规模有限(可能仅几十上百条),不足以训练出强大的通用模型。
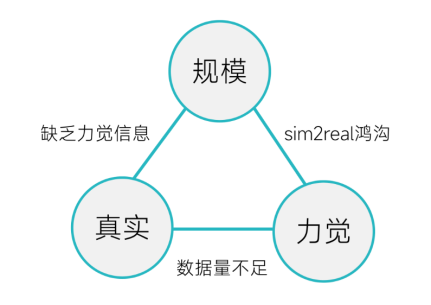
图. 灵巧手数据的“不可能三角”
换句话说,要么数据不够多、要么不够真、要么没力信息。这一困境在五指灵巧手领域尤为严重。五指灵巧手具有20多个自由度,理论上能覆盖人类手的大部分功能,但高自由度也意味着高维数据和控制复杂度。与之相比,常见的机械臂加夹爪只有7个自由度、2种基本操作,覆盖不到人类操作场景的20%;而完整的人形手臂(包含手指)有26个自由度、超过百万种状态,能覆盖约80%的场景,却带来了维度灾难般的决策难题。简而言之,自由度越高,所需数据维度越高,缺乏力信息的弊端也越致命。正如业内所痛陈的:许多号称百万规模的机器人演示数据集中,竟没有一条包含完整的力反馈,形同“躯壳没有灵魂”。
为什么灵巧手的数据采集如此困难?根本原因在于“力太难、力太贵”。要捕获一个20+自由度灵巧手每根手指的用力情况,需要在众多关节和指尖安装力传感器。这不仅会改变手的动力学特性、让动作不再自然,还会带来高昂的成本和工程复杂性。多个手指协同施力时,如何分配传感器读数、区分内力外力,也是传统方法难以解决的难题。所以过去很多研究选择了回避——既然纯视觉的模仿学习在某些任务上也能奏效,业界一度认为“没有力数据也勉强能做”,不值得为此大费周章。
常规路径比较:遥操作、视频、仿真的局限
数据的边界,正是方法论的边界。
在灵巧操作数据采集上,目前常用的三条路径各有优劣,也各有短板:
• 专业遥操作采集:通过人操纵机器人来记录数据,可获得高质量的真实轨迹和力控信息,适合需要精确力控制的任务。然而,遥操作系统价格不菲且采集效率低,人手与灵巧手结构差异还会造成示范动作与机器人无法完全对应。因此,成本高、效率低、泛化性差,难以支撑大规模数据积累。
• 人类视频学习:利用现有大量人类操作视频,以低成本提取视觉层面的动作示范,易于扩展,适合学习高层策略。但纯视频缺乏机器人执行所需的底层细节和感知信息,存在视角遮挡导致的信息不完备、“看得到做不到”等问题。结果是模仿轨迹不精确、缺少力反馈,机器人难以凭此完成微妙操作。
• 仿真合成数据:在虚拟环境中模拟机器人与物体交互,快速生成多样化、标注完善的数据,成本低效率高,对强化学习和稀有场景训练尤为有利。不过,仿真与现实存在物理差异——模拟器里能成功的策略拿到真实世界往往失灵,需要额外的域适配过程。过度依赖仿真还可能出现“利用仿真漏洞”的不现实解法。

图. 数据获取方式与困境
上述三种主流方式各提供了宝贵的数据基础,但任一单独途径都无法满足灵巧手大规模学习的需求。一些团队开始尝试融合多种手段,典型案例是国外开源的Open X-Embodiment数据集和国内发布的AgiBot World数据集。然而在灵巧手的精细操作维度上,它们并未彻底解决力觉信息匮乏的问题。换言之,大而全的数据集提供了广覆盖的技能演示,但对于五指灵巧手这类需要微妙力控的场景,仍然缺乏足够深入的支持。
DexCanvas登场:真实+合成双轮驱动的新思路
当三角无法兼得,换一张画布重画三角。
面对行业痛点,灵巧智能科技有限公司选择了“第四条道路”:以人类自然操作为锚点,结合强化学习和仿真推理,让隐藏在轨迹背后的物理信息重见天日。他们发布的DexCanvas数据集了一种新的思路来重构问题:以高保真的真人操作轨迹为不可动摇的“骨架”,通过物理仿真推理来填补缺失的“肌肉”——即力与接触信息。 这种方法,在保证行为轨迹绝对真实的前提下,通过计算而非直接测量来获取力信息,从而在可控成本下,实现了兼具大规模、高真实性行为与完备力觉标注的数据集。

图:DexCanvas以“人+物体交互”为中心的数据采集理念,对真人操作进行精细动作捕捉,并在仿真环境中复现接触力学信息。相比传统以设备或单模态为中心的采集方式,这种多模态融合方法能够在可控成本下显著提升数据规模和质量。
DexCanvas的数据构建可概括为“三步走”,每一步都别具匠心:
精确采集:分毫不差,方寸之间皆为数据。
仿真重演:以真实为骨,以物理为筋。
物理增强:在多维扰动中,锻造稳健泛化。
Step 1 – 精准采集人类演示:研究团队搭建了专业的动捕系统,通过20台高精度相机记录人手操作的细微动作轨迹,定位精度达到亚毫米级。演示内容并非随意拼凑,而是参考经典的Cutkosky抓取分类学,精心设计了22类典型抓取和操作模式,系统化地覆盖了人类手部操作空间。从捏取米粒到旋转扳手,各种手势姿态和用力方式均有涉猎。采集过程中同步记录RGB视频、深度信息和物体6自由度姿态等,多模态数据一应俱全。然而初始数据仍缺少力——相机只能捕获几何运动,无法直接获取手指施加的力和物体受力情况。
Step 2 – 仿真重演+物理反推:在这一关键步骤中,DexCanvas引入强化学习智能体,在物理仿真环境中扮演“演员”,力图复现真人演示的每一个动作。智能体控制的是一个仿真的五指人手模型(而非特定机器人手),它只有在施加正确的力并找到正确的接触点时,才能让仿真中的物体运动轨迹与真人演示高度吻合。这一过程中,智能体相当于解了一道反向的物理推理题:已知物体如何运动,求作用于它的力。这道题对传统方法而言无解或极难解(接触点未知导致逆动力学方程无解,或优化方法易陷入局部最优),但强化学习通过试错搜索,最终找到了使轨迹重合的力控制策略。如此一来,每条人类演示轨迹就被“赋予”了物理生命——我们自动获取了每时刻每个手指的用力大小、接触点位置等原本缺失的信息。一句话,DexCanvas让那些“看不见力的轨迹”复活出了完整的力学灵魂。

图. 灵巧操作示范数据采集与合成
值得一提的是,这一步并非简单的“在仿真生成数据”,而是基于真人数据进行的物理推理,因此与纯粹仿真有本质区别。纯仿真往往从零开始生成机器人的动作轨迹,可能钻进模拟器的漏洞走捷径,产生违背真实物理的怪异动作;而DexCanvas以1000小时真人操作为基础,仿真的作用只是显现人类操作中隐藏的物理量,本质上是对真实数据的补完。因此数据的真实性和通用性有了双重保障:首先,真人演示这个“骨架”确保了轨迹合理可信,不会偏离物理现实;其次,在仿真中模拟的是人手模型而非某个特定机器人手,得到的数据不绑定任何硬件平台,具备更普适的价值。
Step 3 – 数据增强 x100:即便有了详尽的真人+力数据,数据规模依然是有限的。为此,DexCanvas进一步利用仿真环境对每条轨迹进行多维度扰动和扩展,生成更多样的数据,以提高模型的泛化能力。具体来说,他们针对每个操作场景,引入了三种变化:(1) 改变物体质量:模拟相同操作对不同重量物体的作用力差异;(2) 调整接触面的摩擦系数:模拟物体材质变化对操作的影响,如玻璃和橡胶的滑腻或粗糙程度;(3) 扰动初始位置和姿态:物体初始状态略有差别,考验策略的鲁棒性。通过这些增强,一个真人演示可以衍生出数百上千条变体数据。粗略统计,约1000小时的人类演示经过物理增强后,相当于产生了10万小时以上的综合数据。以质取胜的数据如今也在规模上达到了业界领先量级(20TB总容量,超过百万种操作状态),为训练数据驱动的灵巧操作模型提供了充沛“燃料”。

图. 22类抓取分类(基于Cutkosky体系)
DexCanvas的独特优势何在?
把力学装进数据,把常识装进模型。
DexCanvas的数据构建“走了另一条路”,却有效破解了灵巧手数据困境,为行业带来几大显著优势:
• 物理信息完备:每条轨迹都附带精细的多指力和接触标注,这是同类数据集前所未有的。毫米级的手指和物体运动轨迹配合同步的力/力矩信息,让模型既能“看到”动作,又能“感觉”用力大小。对于需要力控的任务,这样的数据如同赋予算法触觉神经,使其更好地理解何谓“抓紧”或“轻拿轻放”。
• 物理一致性与真实性:通过对真人操作过程的精细感知和仿真复现,DexCanvas实现了接触几何和力学的一致。传统动作捕捉往往有厘米级误差,且无法获取力,导致模型在训练时可能学到错误的接触关系(如“穿模”现象);DexCanvas则将接触点和力精确对齐于真实物理过程,有效避免了虚假接触和错误力反馈。这些高度可信的交互动态信息,大大提升了数据对下游任务的物理有效性。
• 规模与多样性兼备:得益于仿真增强,DexCanvas在保持真实性的同时,实现了数据规模和多样性的飞跃。10万小时级别的数据量涵盖各种不同重量、摩擦、初始条件的操作,对于训练强化学习或大模型预训练等数据“吞量”巨大的范式而言尤为友好。同时,由于基础是真人演示,多样性的增加并未偏离现实合理性。
• 高维策略抽象:针对高自由度操作带来的复杂决策问题,DexCanvas团队提炼出一套语义化的策略表示方法。他们基于人类常见的动作模式,总结出33类操作原型以及6个关键的语义规则参数,用来描述复杂操作任务。这意味着数据集中每条轨迹除了原始的时序信息,还有对应的语义标签(如力闭合/形闭合、抓取类型等),为上层策略学习提供了结构化、可解释的先验。如果说原始数据是无序的“动作录像”,这些语义标签就像注释与目录,方便研究者从中提炼策略、实现知识迁移。
• 跨硬件的泛化性:DexCanvas的数据源于人类操作本身,不依赖于某一种灵巧手硬件。这一点非常关键。过去不少数据集是用特定型号的机械手采集的,模型往往绑死在该硬件上,换个平台就需要重新适配。DexCanvas由于采用人手模型和高抽象语义,具备良好的跨平台泛化能力。无论是机器人手、假肢,还是不同机构的新型灵巧手,都可以从中汲取通用的操作经验。

图. DexCanvas中的强化学习策略,“复活”轨迹的物理灵魂
当然,有人可能质疑:“用仿真推导力信息,算不算作弊?” 对此灵巧智能团队的回应是:DexCanvas不是凭空捏造数据,而是站在真实数据之上‘水到渠成’地揭示物理。这就好比古生物学家根据真实的恐龙骨骼推断出肌肉分布——骨架千真万确,复原出的肌肉是基于科学规律推演的。只要骨架足够完整且样本足够多,推演出的结果就值得信赖。同理,DexCanvas基于海量真实演示来反推力,大规模真人数据确保了推演不会偏离实际物理规律。因此,这样得到的力觉数据既有真实根基又有推理支撑,能够极大提升机器人的物理认知能力,而无损数据的真实性。
DexCanvas将在今年10月下旬面向全行业开源这一数据集,供研究者便捷获取;同时开放全部数据处理的代码(从动捕、MANO手部模型拟合到物理重演、再到机器人执行的完整流程),以及集成示例,方便开发者上手使用。此外,一份详细的技术报告也将在10月同步发布于arXiv。这意味着,无论是学术研究还是产业应用,有兴趣者都能免费使用这套珍贵的数据资源,验证自己的算法或开发新功能。近年来出现的百万级机器人数据集被誉为具身智能的ImageNet时刻。DexCanvas进一步把数据质量提升到新高度,在触觉维度上丰富了这一领域的数据版图。

图. 灵巧智能发布DexCanvas数据集
结语:从灵巧之手到智慧之躯
大道至简,实干为要。
灵巧手被誉为“具身智能的终极挑战”,它不仅象征着机器人操作能力的巅峰,也代表了机器人全面进入人类工作生活的最后关卡。如今,DexCanvas数据集的出现,让我们看到了破解这一难题的希望:用数据弥补机械之手的触觉缺失,用共享推动整个行业协同创新。
当所有人都在为数据规模竞赛时,DexCanvas选择了另一种“卷”:卷数据的质量与维度。正是这种对“对的方向”的坚持,才能让机器人真正长出灵巧的双手,进而拥有拥抱世界的力量。
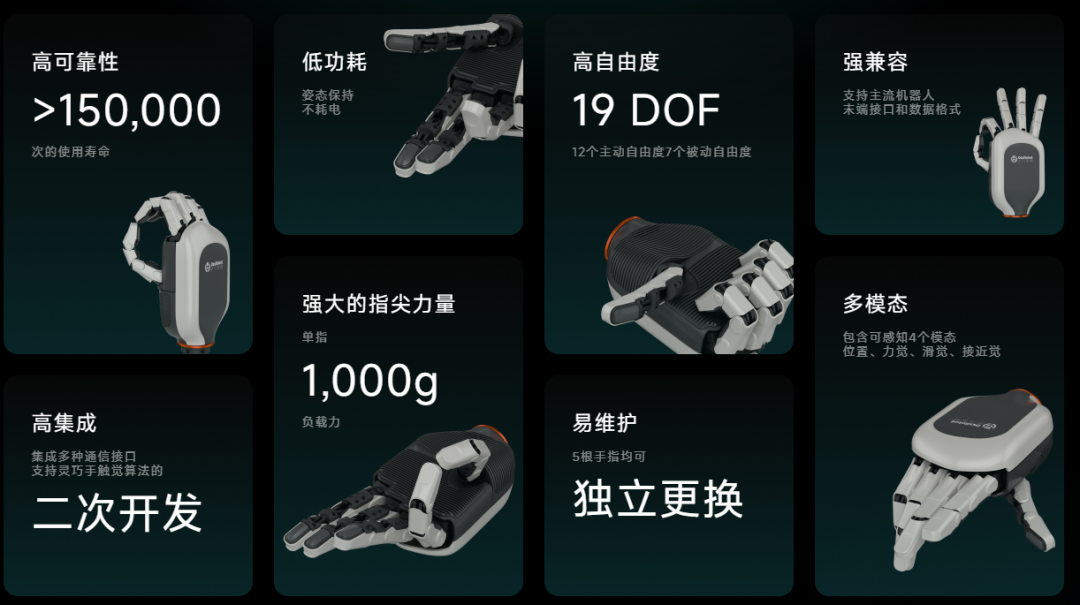
图. 灵巧智能自研的DexHand021,首款商用高自由度多模态感知的智能通用灵巧手
(首批DexCanvas数据及代码将于2025年10月正式开源,技术报告将同步发布在arXiv。有关数据集的最新消息和获取方式,可关注灵巧智能官方渠道。)










