
新智元报道
新智元报道
【新智元导读】百度登顶全球第一!最新模型「PaddleOCR-VL」以0.9B参数量,在全球权威榜单OmniDocBench V1.5中以92.6分夺得综合性能第一,横扫文本识别、公式识别、表格理解与阅读顺序四项SOTA。
今天习惯性地刷Hugging Face,突然发现Trending榜单第一的模型有点眼熟。
点进去一看,这不百度飞桨昨天才发布的PaddleOCR-VL吗,一夜之间就冲上榜首,这个速度也太快了吧!

Hugging Face:https://huggingface.co/PaddlePaddle/PaddleOCR-VL
去社区翻了一下,发现好多人都在聊这个模型,很多人使用后都各种称赞,什么:
PDF天才、PDF之神、OCR之神、又小又棒、难以置信、好用、迄今为止最强、能像人类一样理解文档、将文档AI提升到全新高度、最好的OCR框架。






左右滑动查看
有点夸张啊,这么厉害的嘛,必须去翻一下了。
去看了一下官方文档,10月16日发布并开源的PaddleOCR-VL,已经在OCR领域全球第一啦!
这里插一句,OCR大家都熟悉,日常扫描或者用AI读个图片已经司空见惯,不过效果多多少少不能100%识别。
OCR在AI领域的能力,还有另一个名称,这个能力基准叫做文档视觉语言理解基准。
仔细看了一下16号公布的数据,在最新OmniDocBench榜单中,PaddleOCR-VL以92.6综合得分位列全球第一!而且是双榜单第一。

OmniDocBench v1.0+v1.5双榜:百度的AI模型PaddleOCR-VL,综合性能全球第一
并且在四大核心能力维度——文本识别、公式识别、表格理解、阅读顺序中,PaddleOCR-VL均位居第一,是榜单中唯一在四项指标中全面领先的模型。

然后去查了下OmniDocBench的权威性,这个基准测试榜单竟然是国际上最有代表性的文档视觉语言理解基准之一。
并且GPT-4o、Gemini-2.5 Pro、Qwen2.5-VL、InternVL 1.5、MonkeyOCR Pro等主流模型都采用这个基准测试结果。

OmniDocBench几乎包含能想到的所有PDF文件样式和内容
这下真的好奇心拉满了,必须实测感受一下了。
在百度飞桨AI Studio上,提供了一个PaddleOCR-VL Demo体验链接,可以直接上传文件。

官方Demo体验:https://aistudio.baidu.com/application/detail/98365

在测试完以上四项任务和评测基准外一些专门上难度的例子后,觉得PaddleOCR-VL是真的有点厉害!
最直观的感受就是,非常的准,或者说太准了!不愧是能登顶排第一的模型。
以前我们常用的一些传统OCR,或者说多模态大模型,比如GPT-5/Gemini等,大部分情况下能够识别个80/90%,已经觉得很厉害。
但PaddleOCR-VL给人的感觉就是不管是什么样子的文档上「犄角旮旯的」内容都能识别出来。

任意选择了编程书上的一页,PaddleOCR-VL的特点是对版面分解非常清晰。
分割出的每个模块都带有1、2、3这样的序号,在此基础上,再进行文本识别。
特地选择了带水印的代码和文本混杂章节,PaddleOCR-VL识别的准确率是100%。



左右滑动查看

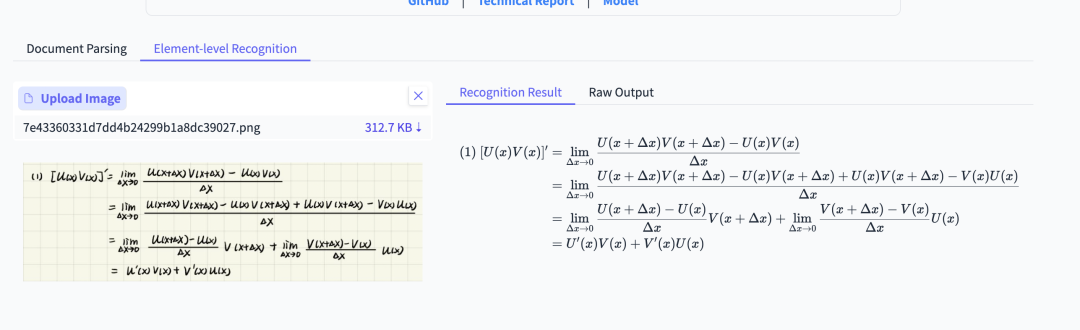
对于复杂的数学公式,比如公式都有上下标、且很长的情况,PaddleOCR-VL也能完美的处理。



左右滑动查看
同样的公式,使用GPT-5 OCR的模式,因为公式太长,GPT-5就没有识别出来。

对于手写公式来说,也基本不在话下:

OCR识别表格算是一个难题,而且表格类型丰富,有时候带边线,有时候不带,数字又多,模型非常容易整错。
用PaddleOCR-VL测了几个表格,发现它是「看得真准」。
用PaddleOCR-VL识别了一下百度的财报,可以直接整理出一个非常好看的表格。


左右滑动查看
识别一下工作报销用的表格,结果也很完美识别,准确率依然100%。


还可以把类似表格的结构整体出来。
比如,App Store的免费APP排行榜就能提取到一张表格之中。


OCR识别的另一个难题就是文档的结构和阅读顺序。
现代社会,信息的主要载体就是文档,而现在的文档不仅内容越来越复杂,而且版面也越来越多变。
多栏布局、图文混排、表格、折页、背景装饰、彩色印刷、倾斜扫描、手写注记……都大大增加了OCR的难度。

文档的阅读顺序不一定总是从上到下,从左到右。
在PaddleOCR-VL技术报告附录中,还展示了模型如何像人一样去理解复杂的文档结构。


以一份《2025百度人工智能创新与专利白皮书》为例,其中一页是这样。

早期传统的OCR只能逐行扫描,会将红框中的字体连成一句本不存在的话。

PaddleOCR-VL首先就对内容的版面进行准确地分割和定位。
这就是PaddleOCR-VL一个很强的能力,也是识别准确率很高的一大原因:能够像人一样理解复杂版面结构。

无论是学术论文、多栏报刊还是技术报告,均可智能解析版面布局,自动还原符合人类阅读习惯的阅读顺序。
比如PaddleOCR-VL对左下角的图片处理也很「巧妙」,它直接「截图」,而没有「多此一举」去截取这些文字。

对于更加复杂版面的识别,PaddleOCR-VL的表现也极其稳定。
以一份手写笔记为例,其中涉及到文本、数字、段落和图片等各种元素,以及人类才能理解的左右、上下分栏。

PaddleOCR-VL(左一)的分法正确、合理,分解难点在于图片分割和上下、左右分栏。
而中间模型和右一其他模型则对版面的分解错误,比如无法理解「右下角的解析部分」其实是一整段。
小小揭秘一下,其他模型也是今年OCR领域其他爆火的VLM模型,中间是MinerU2.5,右边是dots.ocr。

能够登顶权威榜单,并在文本识别、公式识别、表格理解和阅读顺序四个核心维度中均位列第一,背后离不开模型在版面分解与元素识别上的极高准确率。
在精度方面,PaddleOCR-VL于OmniDocBench v1.5上实现了纪录级表现:文本编辑距离仅0.035、公式识别CDM达到91.43、表格TEDS为89.76、阅读顺序预测误差仅0.043。
这一系列数据不仅展现了模型在标准评测中的领先实力,也验证了其在复杂文档、手写稿及历史档案等高难度场景下依然保持稳定、精准的识别能力。
但以上这些还都属于是OCR的常规能力,PaddleOCR-VL的识别能力上限在哪里?

看完PaddleOCR-VL的技术报告附录中案例后,发现以上这些只是PaddleOCR-VL能力的冰山一角。

PaddleOCR-VL甚至可以「看懂」复杂金融图表,并给出具体数据的估算结果,这个能力确实有点「逆天」了。
以附录中图表为例(btw,这个能力不属于OmniDocBench评测基准)。

PaddleOCR-VL能够准确提取柱状图和线图节点对应的数值与对应的省份进行匹配。
比如广东省对应的GDP数据在30000~35000之间,GDP增速在4%~5%之间,PaddleOCR-VL可以在这种「细粒度」上识别出一个区间比较准确的数值。
这就非常神奇了,人拿着肉眼看也很难对齐,需要搞把尺子才能目测出来~
而PaddleOCR-VL居然可以细节到这个程度。

其他模型都或多或少的存在问题,并且作为对比的Qwen2.5VL-70B和GPT-4o,一个是参数远大于PaddleOCR-VL的开源VL模型,另一个则是经典的闭源多模态模型。
比如Qwen2.5VL-70B模型完全无法从细粒度上识别线图数据,都识别为了4%。
而GPT-4o则是识别错误,有点幻觉了,比如广东省的GDP直接识别成了6.5%。

还有一个案例也比较夸张,比如纯手写的这封信。

MinerU2.5和MonkeyOCR可能因为贴纸的干扰,未能识别到开头部分。


除了整体文档识别能力,PaddleOCR-VL还可以针对图表进行识别和内容提取。
类似这种需要从图表中提取表格数据的任务。
PaddleOCR-VL一键即可完成,错误率几乎为零。



PaddleOCR-VL还是一个「世界语言引擎」,是一个能够覆盖109种语言的超大规模文字识别体系。
能够精准识别中文、英语、法语、日语、俄语、阿拉伯语、西班牙语等。
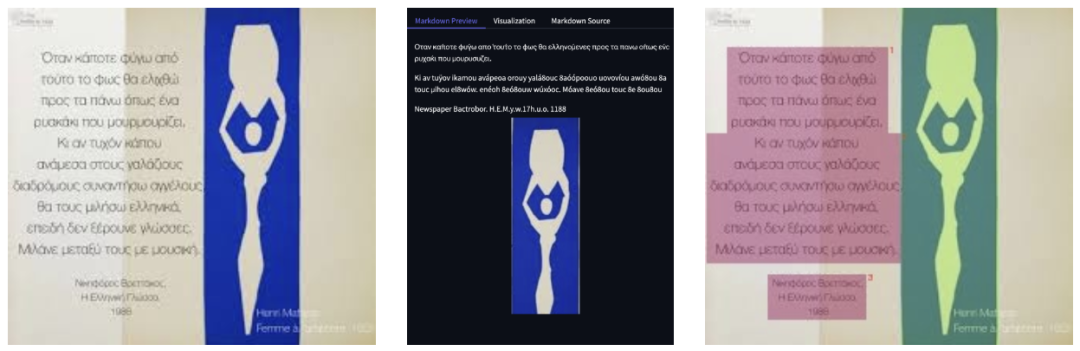
比如,下列希腊语的现代诗歌的模糊图像,PaddleOCR-VL可分割图像和文本。
法国文豪维克多·雨果的名言警句:

文学家陀思妥耶夫斯基的俄语名言:

德国数学家David Hilbert的墓志铭:


除了识别语言,PaddleOCR-VL在识别各个古籍、手写文本和历史文档也非常厉害。
古籍和各类手写文本的挑战在于,如何让AI以人类视角「看懂」这些文字。
PaddleOCR-VL在识别各种非标准化、非结构化文档后,能够按照「人类阅读习惯」来还原文本正确顺序。
不论是分栏、横/纵向、从左向右or从右向左,PaddleOCR-VL能够精准分辨出哪些是标题、正文、图注,文章应该从左向右阅读,还是从右向左阅读。
以下面的楷书字帖为例。

PaddleOCR-VL(左一)的准确率可以做到几乎100%。
其他模型对于「肩膀」的识别都或多或少出现问题,虽然他们也是OCR领域今年的明星项目。

而对于各种历史类、考古类古籍,一是文本的阅读顺序和现代不同,二是存在大量生僻繁体字和模糊文字。



这次PaddleOCR-VL刷新了全球OCR VL模型性能天花板——
不仅超越GPT-4o、Gemini-2.5 Pro、Qwen2.5-VL-72B等主流多模态大模型,还超越了MonkeyOCR-Pro-3B、MinerU2.5、dots.ocr等OCR领域模型。
在公开基准OmniDocBench v1.0、v1.5和olmOCR-Bench以及内部基准上,PaddleOCR-VL均达到了最先进水平SOTA。

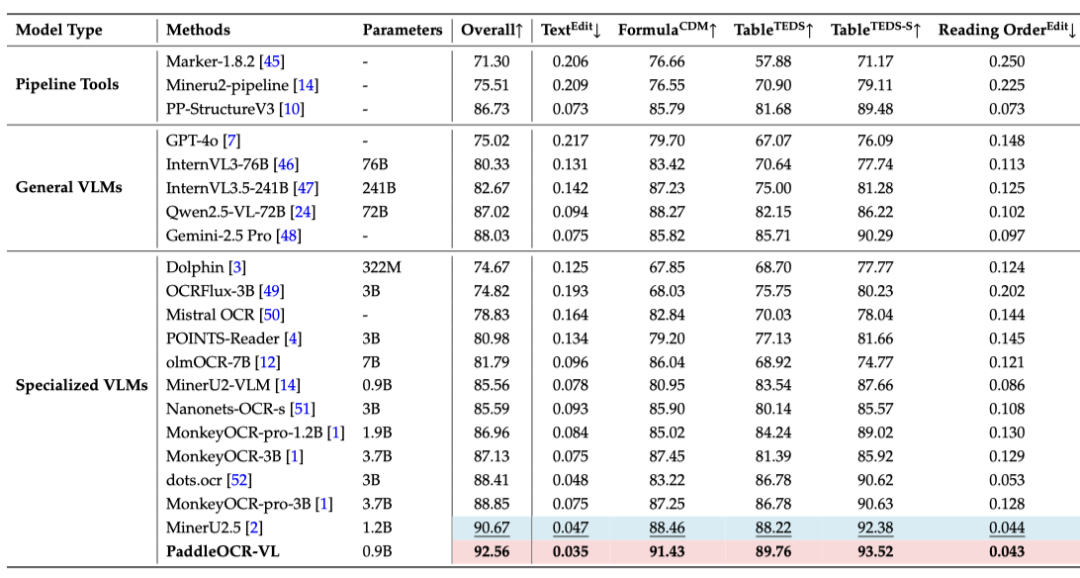

根据自建数据集上的测试,PaddleOCR-VL还具有出色的「跨语言」文本识别能力,在多个测试语种上均取得最佳成绩,对其他的OCR专有模型实现了碾压:
阿拉伯语(0.122)、韩语(0.052)、泰米尔语(0.043)、希腊语(0.135)、泰语(0.081)、泰卢固语(0.114)、天城文(0.097)、西里尔文(0.109)、拉丁文(0.013)和日文(0.086)。
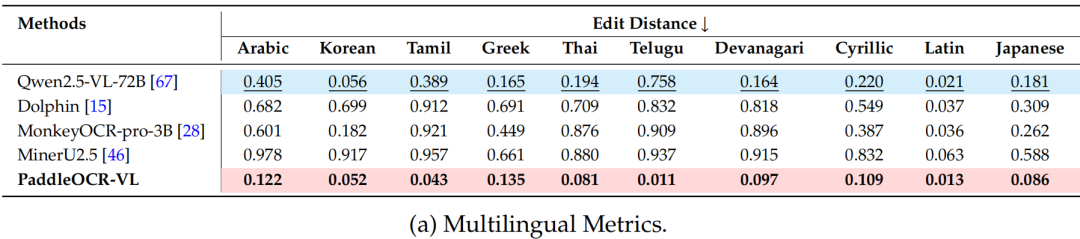
在文本类型指标中,新模型同样表现优异,所有类别均实现了最低错误率:
手写中文(0.089)、手写英文(0.042)、印刷中文(0.035)、印刷英文(0.016)、繁体中文(0.048)、古籍文本(0.198)、自然场景(0.067)、拼音(0.113)、生僻字(0.001)、竖排文本(0.005)、单字符(0.027)、表情符号(0.057)及艺术字体(0.165)。

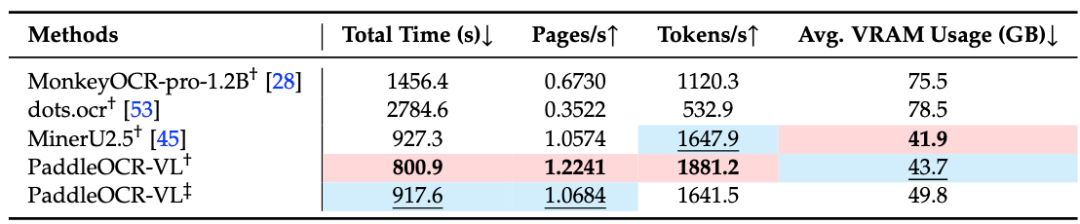
不仅识别效果与这些主流技术比肩,PaddleOCR-VL具有明显更低的时延和更高的吞吐量!
在推理方面,在单张A100 GPU上,PaddleOCR-VL每秒可处理1881个Token,推理速度较 MinerU2.5提升14.2%,较 dots.ocr 提升253.01%。
但模型的核心组件——视觉语言模型文心语言模型ERNIE-4.5-0.3B,非常小,只有0.9B!
这意味着它能部署在普通服务器、个人电脑,甚至还可以当一个插件安装在浏览器里。
但在OCR能力上,性能却能超越70B-200B这种大体积模型,甚至还能击败GPT-4o、Gemini 2.5等顶尖多模态模型!
PaddleOCR-VL堪称文心4.5最强衍生模型!
这既得益于团队在OCR领域不断的技术积累,更是因为在架构设计和数据构建上的创新。

技术报告地址:https://arxiv.org/pdf/2510.14528

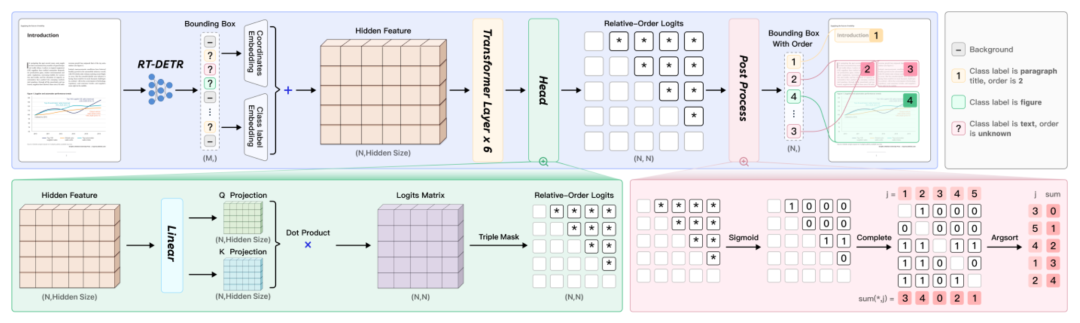
PaddleOCR-VL由PP-DocLayoutV2、PaddleOCR-VL-0.9B两部分组成。
其中,核心部分是PaddleOCR-VL-0.9B,融合了预训练视觉编码器与动态分辨率预处理器、双层MLP投影器以及预训练大语言模型。

预处理技术采用原生动态高分辨率。视觉编码器,用了NaViT风格编码器,其支持原生分辨率输入。
这一设计让视觉语言模型PaddleOCR-VL-0.9B减少了幻觉、提升了性能。
投影器则高效地将视觉编码器的特征连接到语言模型的嵌入空间中。
在自回归语言模型中,整个序列是通过一次预测一个标记来生成的。这意味着解码器的规模直接影响整体推理延迟,因此更小的模型解码速度会更快。
考虑到这一点,团队选择ERNIE-4.5-0.3B模型。
这是一个开源语言模型,参数数量虽少,但推理效率很强。
可以说ERNIE-4.5-0.3B是PaddleOCR-VL-0.9B的「文本侧大脑」,高效地解读视觉编码器「看到的」内容。
文心ERNIE-4.5-0.3B语言模型+NaViT风格动态分辨率视觉编码器,双管齐下显著提升了PaddleOCR-VL的文档解析性能,同时实现了最低的内存占用和更快的推理速度。
在A100上,不同文档解析模型的端到端推理速度
整体上,相较端到端方案,能够在复杂版面中更稳定、更高效,有效避免多模态模型常见的幻觉与错位问题。

如上所述,PaddleOCR-VL由两个核心模块组成:
PP-DocLayoutV2:负责版面分析(layout analysis),定位文档中的语义区域,并预测其阅读顺序(reading order)。
PaddleOCR-VL-0.9B:进一步细粒度识别多种内容(fine-grained recognition)。
在架构上,PP-DocLayoutV2由两个按顺序连接的网络组成。
与其他专用模型相比,PP-DocLayoutV2模型通过将RT-DETR高效扩展为带指针网络的结构,以更少的参数实现了更高的性能。

为构建高质量、且多样化的训练数据集,PaddleOCR-VL团队创新了数据构建方法。

为支撑复杂文档理解,团队构建了广泛、多源、高难度的数据体系:
开源数据集+ 合成数据 +可公开获取的网络数据+内部数据,总数据量超过3000万样本,而「自动化标注+难例挖掘」保证数据高质量Scaling。
特别是,「难例挖掘」流程突破了特定复杂场景下的性能瓶颈。
评测引擎与数据构建:覆盖多类型任务的评测引擎,并人工构建了大规模评测集,包含23类文本、20类表格、4类公式、11类图表;
难例识别:在该评测集上执行推理,并结合对应的专业指标即可精确定位模型表现欠佳的「硬样本」。
难例合成与强化:针对识别出的薄弱点,系统利用丰富的资源与渲染工具,批量合成高质量的新增难例,用于定向训练与性能提升。

纵观历史,信息抽象和检索的进步一直推动着人类的发展。
从象形文字到莎草纸,从印刷术到数字化,每一次飞跃都让人类知识变得更容易获取和应用,从而激发更多创新。
如今,我们正处于下一个重大飞跃的边缘——解锁所有数字化信息的集体智慧。
技术上,OCR任务成为VL大模型竞争关键之一。
价值上,大模型时代,OCR越来越越来越重要——
现实世界的信息以非结构化形态存在,大模型要发挥价值,必须依赖OCR进行信息转化。
OCR地位上升的三大原因:
产业流程自动化:金融、物流、保险等场景需要大规模文档处理。高精度低成本的OCR是唯一可持续路径,成为大模型的高效「信息提取层」。
RAG应用:企业知识多沉淀在扫描件、合同、报告中。OCR质量决定了RAG链路的「输入质量」,影响最终输出。
大模型进化:人类知识需经OCR数字化才能成为大模型训练的养料。

全球科技巨头在OCR领域展开激烈竞争,纷纷推出创新模型。
比如,IBM联合HuggingFace推出专用小模型SmolDocling;Mistral AI推出1000页1美元的OCR服务等。
2023年,市场研究与咨询公司Grand View Research预计,到2030年将增长至329亿美元,2024-2030年复合年增长率达14.8%;市场增长主要驱动力,源于生产效率提升及自动内容识别系统普及。

最近,Allied Market Research预计,从2025年到2034年将以15.1%的复合年增长率增长,到2034年将达到506.065亿美元。
而Adobe、ABBYY、亚马逊、微软、IBM、谷歌母公司Alphabet等早已成为市场的主要玩家。
这些公司正通过扩展服务范围、建立战略合作、提升数字可及性、加强客户触达和技术创新等方式巩固市场竞争力。

而PaddleOCR-VL的这次开源,或将进一步冲击市场。

PaddleOCR-VL的冲榜速度确实让人很吃惊。
乍一看,PaddleOCR-VL好像是突然冒出来的一个模型,但其实背后的团队和模型已经打磨好多年了~
PaddleOCR-VL是由百度飞桨PaddleOCR团队出品,PaddleOCR-VL模型是在PaddleOCR基础上迭代而来,而PaddleOCR在OCR领域是很早就出名了。
PaddleOCR自2020年开源以来,累计下载量已经突破900万,被超过6k开源项目直接或间接使用。

该项目也是GitHub社区中唯一一个Star数超过50k的中国OCR项目。

PaddleOCR,这个经典的模型可以说是「久经考验」。
在历经多年打磨后的PaddleOCR VL能够一飞冲天,其实本质上还是厚积薄发,也是很能说得过去了。
OCR行业也可以说是踩中了AI的浪潮,成为「风口上的猪」。
现在AI不论是从需要阅读文档的角度,还是为AI提供训练语料的角度,OCR是最开始也是最重要的环节之一。
未来,随着AI原生应用的加速到来,文档将不再只是信息的容器,而是大模型学习和认知世界的入口。
而PaddleOCR-VL,正成为AI认识世界的一双眼睛。

1989年,Yann LeCun(图灵奖得主)首次将反向传播神经网络应用于手写数字识别。
他让神经网络直接「学」到字符识别的映射,而无需复杂的特征工程。

不管是图像识别还是OCR,这是机器能够看懂「文字」的一个关键节点。
那么25年过去了,现在的OCR技术能不能准确识别这些数字?
用PaddleOCR-VL试了下,能够准确地识别了这些数字。
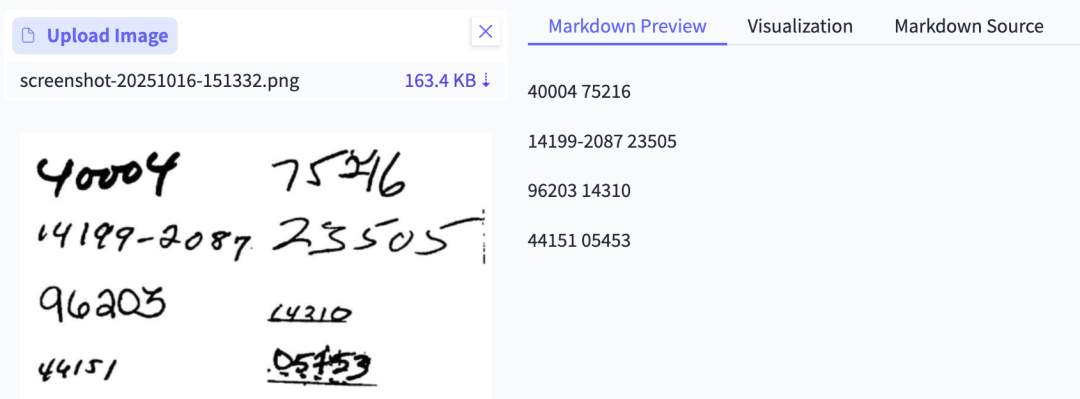
意外的是,GPT-5 OCR在识别右上角「75216」时,错误的识别成「75316」。(因为数字2上面有个干扰项)
第二行右侧的「23505」也莫名多了一个「5」,变成了「235505」。

谷歌的Gemini 2.5 Pro同样在多处识别错误。

看来还是术业有专攻,在OCR领域,PaddleOCR-VL更胜一筹。











