ObjectRelator团队 投稿
量子位 | 公众号 QbitAI
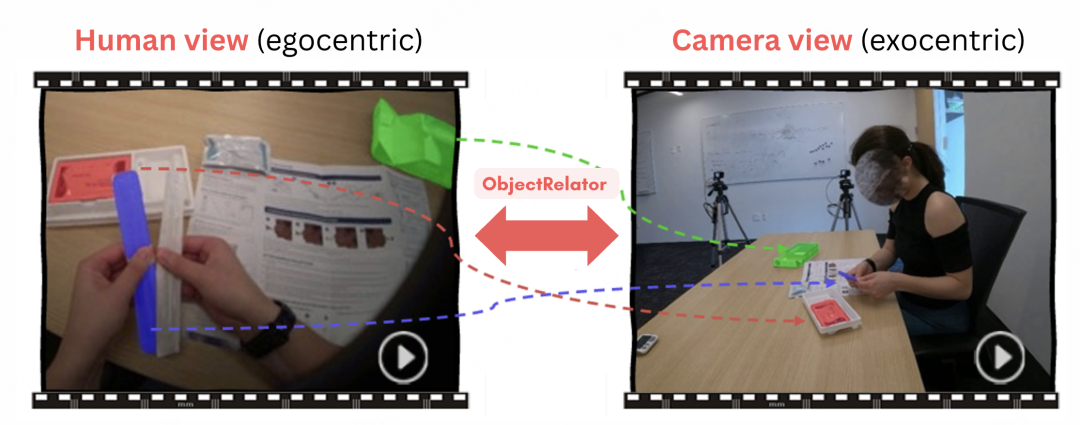
具身智能落地迈出关键一步,AI拥有第一人称与第三人称的“通感”了!
INSAIT、复旦大学等单位联合提出ObjectRelator框架,让AI精准匹配不同视角下的同一物体,实现跨视角的统一表征与理解。
实验中,ObjectRelator在Ego(第一人称视觉)转Exo(三人称视觉)和Exo转Ego两个任务上都显著超越了所有基线模型,拿下SOTA。
Ego→Exo效果,be like:


Exo→Ego也可以很好地对齐:


目前,该工作已被ICCV 2025接收为Highlight论文,代码已开源。

Ego与Exo之间的鸿沟
在人类技能习得过程中,需要在两个视角之间进行流畅的转换。
我们在观看别人的演示过程时,会尝试在脑海中想象自己进行这些操作的场景。然而这一跨视角理解的能力对于计算机和机器人来说却是一个巨大的挑战,制约着机器人学习、VR交互等关键领域的发展。
第一人称视角具备较强的沉浸感与交互细节捕捉能力,能够精确刻画主体与环境之间的动态交互过程。然而,其视觉范围受限、画面稳定性较差,难以全面反映场景全貌。
相比之下,第三人称视角具有更广阔的空间感知能力,能够清晰呈现场景与动作的整体结构及时空关系,但其画面中目标物体通常较小,细节信息相对不足。
如何在物体级别上建立第一人称与第三人称视角之间的视觉对应与语义关联,进而实现跨视角的统一表征与理解,仍是当前领域亟待解决的核心问题。
现有工作的不足与挑战
尽管近年来出现了诸如Mask2Former、SAM、SAM2等高性能图像分割模型,但如下图所示,他们普遍受限于从单一图像(视角)中进行图像分割任务,难以驾驭跨视角分割问题。

PSALM是为数不多可以接受双视角输入进行分割的模型,然而其在面临Ego-Exo跨视角物体分割任务时仍面临两大核心挑战:
1、复杂的背景干扰
在复杂场景下拍摄的Ego/Exo画面,尤其是Exo,其场景通常包含大量结构复杂、语义多样的背景元素,其中部分对象在外观或形态上与目标高度相似。此类高相似度干扰使得仅依赖视觉特征进行匹配极易导致目标混淆或误识别,从而显著削弱模型在跨视角目标辨识与追踪中的判别能力。
2、显著的视觉变换
同一个物体,在Ego视角中可能占据图像的大部分区域,而在Exo视角中则仅表现为画面中的一个小尺度目标,其外观形态、姿态角度以及相对空间位置均发生剧烈变化。此外,由于光照、遮挡和相机参数不同,物体的颜色、纹理等视觉特征在两个视角下也会呈现出明显的视觉差异。
如下对比图显示,(a)PSALM会定位到形状相似而语义错误的物体类型; (b)PSALM不能分割出形状变化较大的正确物体。

两大创新模块,解锁跨视角“通感”
为了攻克上述难题,ObjectRelator基于PSALM构建了第一个跨视角多模态分割模型,能够有效支持以Ego-Exo为代表的跨视角物体关联人物。方法主要包含两个核心模块:
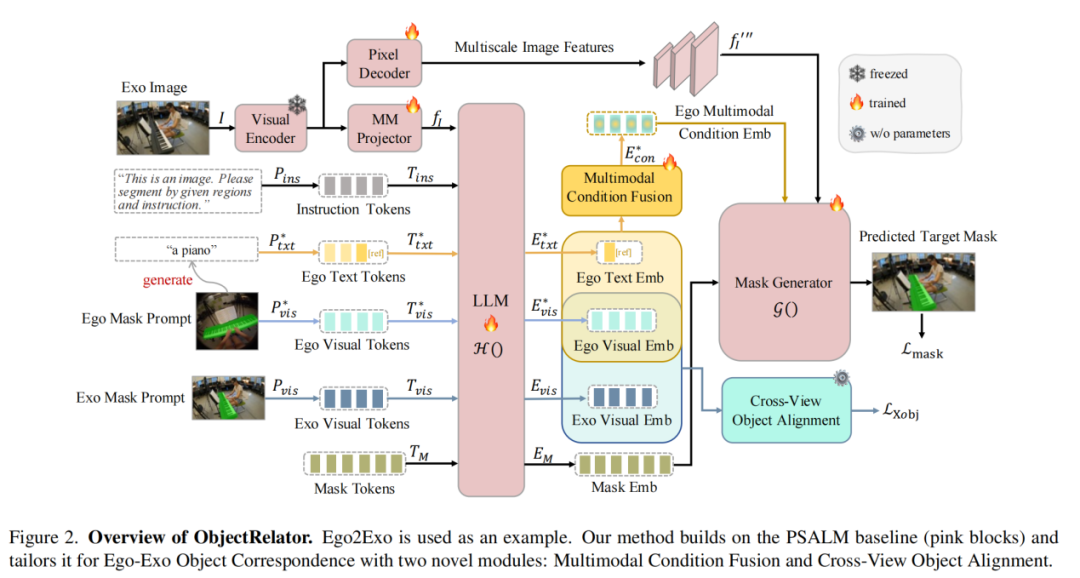
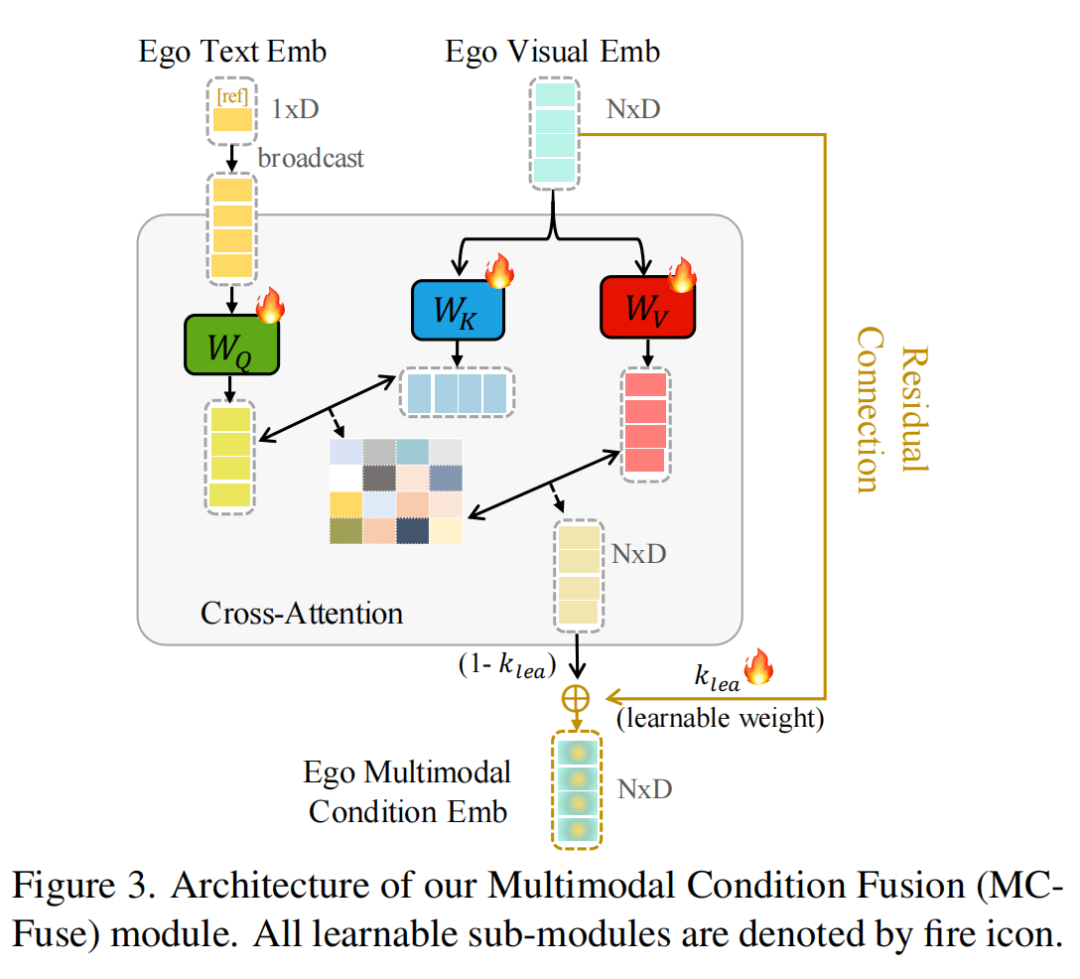
1、多模态条件融合模块(MCFuse)
为了让模型不只“看形状”,还要“懂语义”,MCFuse首次将语言描述引入跨视角分割任务。它通过预训练的视觉语言模型(LLaVA)为查询物体生成一句简短的文本描述(如“一把黑色的剪刀”),再与视觉掩码特征进行融合。
融合过程中,模型通过交叉注意力机制、残差链接、以及动态融合权重三种策略共同权衡视觉与语言信息的重要性,从而更准确地锁定目标物体。
2、跨视角对象对齐模块(XObjAlign)
为了应对物体在不同视角下的外观变化,XObjAlign提出了一种自监督对齐策略:在训练中,模型会同时提取同一物体在Ego视角和Exo视角下的特征,并通过一个一致性损失函数拉近它们的距离。这意味着,模型被强制学习一种“视角不变”的物体表示,从而在面对视角变化时仍能保持稳定的识别能力。
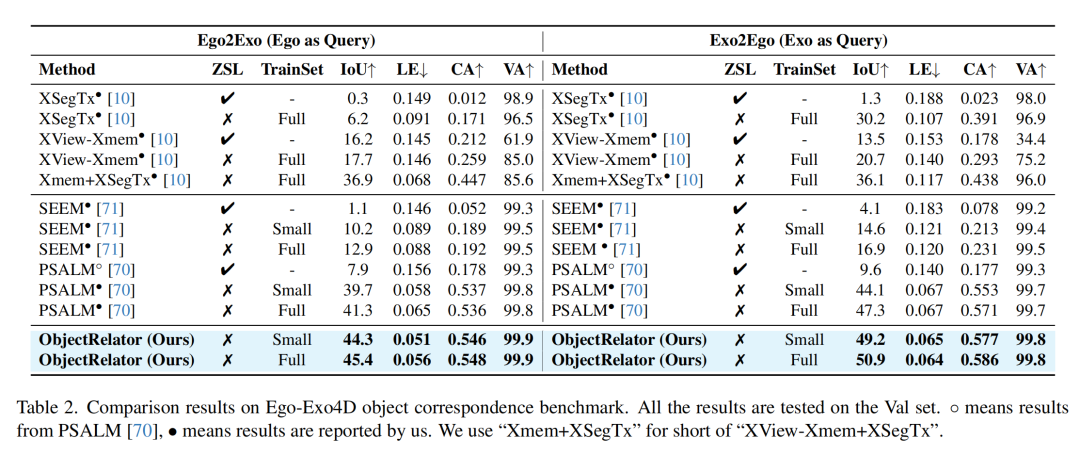
实验结果:SOTA性能+任意跨视角的泛化能力
ObjectRelator在两大跨视角数据集上进行了验证:
Ego-Exo4D:目前最大的Ego-Exo跨视角数据集,涵盖烹饪、维修、运动等六大场景。 HANDAL-X:作者构建的新基准,专注于机器人操作场景下的物体分割。
1、主要实验结果与指标
实验结果显示,ObjectRelator在Ego→Exo和Exo→Ego两个任务上都显著超越了所有基线模型,在Small TrainSet上相比于微调后的PSALM模型IoU指标分别提升4.6% 和5.1%,达到SOTA性能。
2、模块有效性验证
消融实验充分验证了各个模块的有效性与必要性。无论是单独引入MCFuse还是XObjAlign,都能带来显著的性能提升。这一结果表明:融入语义信息与强化跨视角一致性是解决该任务的两个正确且相互补的方向。

3、强大的泛化能力
在HANDAL-X数据集上的零样本测试中,使用Ego-Exo4D数据训练的ObjectRelator模型,其性能远超在COCO等传统数据集上训练的模型。
这证明了通过在跨视角数据上进行训练,模型能够学到一种可泛化到全新场景的跨视角理解能力。 同样的,针对HANDAL-X数据集微调后的ObjectRelator模型能达到进一步的性能提醒,超越PSALM的同时达到SOTA的效果。

4、可视化结果



更多的视频可视化结果可以点击项目主页或项目demo进行观看。
论文链接:https://arxiv.org/pdf/2411.19083
项目主页:https://yuqianfu.com/ObjectRelator/ (代码已开源)
项目demo:https://huggingface.co/spaces/YuqianFu/ObjectRelatorDemo
会议Poster:October 21, 15:00–17:00, Exhibit Hall I, Hawaii (欢迎前往现场与作者交流)










