
如何让 AI 像人类一样从对世界的观察和互动中自然地学会理解世界?在今年的国际计算机视觉大会(ICCV 2025)上,来自浙江大学、香港中文大学、上海交通大学和上海人工智能实验室的研究人员联合提出了第一人称联合预测智能体 EgoAgent。受人类认知学习机制和 “共同编码理论(Common Coding Theory)” 启发,EgoAgent 首次成功地让模型在统一的潜空间中同时学习视觉表征(Visual representation)、人体行动(Human action)和世界预测 (World state prediction)三大核心任务,打破了传统 AI 中 “感知”、“控制” 和 “预测” 分离的壁垒。这种联合学习方式能让模型在三项任务间自然形成协同效应,并成功迁移到具身操作等任务之中。

论文题目:EgoAgent: A Joint Predictive Agent Model in Egocentric Worlds
接收会议:ICCV 2025
项目主页:https://egoagent.github.io
论文链接:https://arxiv.org/abs/2502.05857
代码地址:https://github.com/zju3dv/EgoAgent
灵感来源:模拟人类的具身认知过程与感知 - 动作的统一表征
想象你是怎么打篮球的?你需要从第一人称视角去感知球的位置,同时迅速准备好起跳或拦截的动作,并不断预判不同动作对球场局势的影响。而每做出一个动作又会反过来改变环境,触发新一轮的感知 - 行动 - 预测循环。这一循环在人类的成长早期就开始了,婴儿通过在真实世界中不断地观察与交互,形成一个高度耦合的视觉 - 动作系统。这一系统比语言系统更早 “上线”—— 人类在会说话之前,就已经能通过感知和行动来理解和改变周围环境。然而,在 AI 领域,对这一系统的学习却落后于语言模型的发展。
在认知科学中,这一系统的形成机制被称为具身认知(Embodied Cognition)与共同编码理论(Common Coding Theory):感知与行动不是相互独立的过程,而是在共享的表征空间中协同工作、相互强化。EgoAgent 正是受到这一机制的启发。它旨在模拟这种人类大脑、身体和环境之间持续的互动,使得 AI 能够像人类一样学习 —— 不是仅仅通过观看图片,而是通过亲身经历世界,去预测未来、采取行动,并理解行动如何改变环境。

技术揭秘:EgoAgent 如何实现 “1+1+1 > 3”?
以往的 AI 模型往往将 “感知 - 行动 - 预测” 循环拆解为三个独立任务,分别训练,从而割裂了它们之间的内在联系。EgoAgent 则在大规模的第一人称视角视频与同步采集的三维人体运动数据上,实现了三项任务的联合学习。
为此,研究团队设计了一个名为 JEAP(Joint Embedding-Action-Prediction)的核心架构。该架构基于联合嵌入预测架构世界模型(JEPA World Model)进行扩展,对其中的 teacher–student 框架进行了创新改造:在保留 JEPA 自监督预测条件表征的能力基础上,进一步引入对世界状态和三维人体动作的多模态自回归预测,使模型能够在一个统一的 Transformer 框架内,同时学习三项任务。JEAP 的核心设计包括:

“状态 - 动作” 交错式联合预测: EgoAgent 将第一人称视频帧和三维人体动作交替编码为一串统一的 “状态 - 动作 - 状态 - 动作” 序列 ,并通过 Transformer 的因果自注意力机制进行建模。这种设计使得模型能够在时间维度上同时捕捉两种关系:感知如何驱动动作,以及动作如何影响未来世界。
“预言家” 与 “观察者” 的协作机制: EgoAgent 内部包含两个分支:预测器(Predictor)从过去的 “状态 - 动作” 序列中预测未来的世界状态和人体动作;而观察器(Observer)则仅对未来帧进行编码,生成目标表征,用于监督预测器的学习。类似于 teacher–student 框架,观察器的参数通过指数滑动平均(EMA)从预测器更新。这一机制不仅拓展了传统学习框架在时间序列上的自监督学习能力,使模型能够在时间维度上对未来进行预测与对齐;同时也保留了在静态图像上的自监督学习能力:在同一时刻,观察器与预测器可分别编码不同增强方式下生成的图像特征并进行对比学习,进一步强化视觉表征的一致性与稳定性。
此外,EgoAgent 还在两个分支中引入了 Query Tokens 作为可学习的提示词,用于在共享的潜空间中调度不同任务的注意力。这些 query tokens 可以主动 “提问” 模型的潜在空间,从而分别抽取与视觉表征或动作生成相关的特征,并在反向传播中解耦各任务的梯度流,避免不同任务之间的相互干扰。
与以往一些依赖像素重建的方法不同,EgoAgent 在连续语义嵌入空间中进行学习。这一点非常重要,因为人类对世界的预测并不是像素级的还原,而是基于抽象概念和高层语义进行推理。这种方法使 EgoAgent 的学习方式更接近人类的认知方式,并提升了模型在未来状态预测方面的性能。
EgoAgent 的能力展示与实验分析
EgoAgent 在三项关键任务上均取得了优异表现,而现有模型通常仅能在其中一至两项任务上实现有效学习。

第一视角世界状态预测:给定过往的第一人称视角图片和三维人类动作,EgoAgent 能够准确预测未来的世界状态特征。模型的预测结果可通过检索验证其真实性 —— 若 EgoAgent 预测的未来世界状态能在由所有视频帧构成的图库中成功检索到对应的真实状态时,即可视为一次成功的预测)。在性能方面,EgoAgent 大幅超越了现有的第一视角视觉表征模型 。例如,3 亿参数的 EgoAgent 较最新的第一视角视觉表征模型 DoRA(ICLR 2024) 在 Top1 准确率上提升了 12.86% ,在 mAP 指标上提升了 13.05% 。这表明 EgoAgent 不局限于基于图像语义相似性进行未来状态预测,更能理解世界的时序演化以及动作与环境间的因果关系。进一步扩展至 10 亿参数规模后,EgoAgent 的性能实现了持续提升。

三维人体动作预测:EgoAgent 能够根据第一人称视角观察和历史动作序列,生成连贯且逼真的未来三维人体运动。在定量评估中,EgoAgent 在三维动作预测任务上取得了领先的性能,相比 Diffusion Policy 以及专用的人体运动预测模型,在 MPJPE(平均每关节位置误差)上达到最低误差,在 MPJVE(平均每关节速度误差)指标上也表现出高度竞争力。值得注意的是,EgoAgent 在预测视频中不可见的人体关节时同样保持了较高的准确度,展现出其在潜空间中对人体运动结构的优秀建模能力。
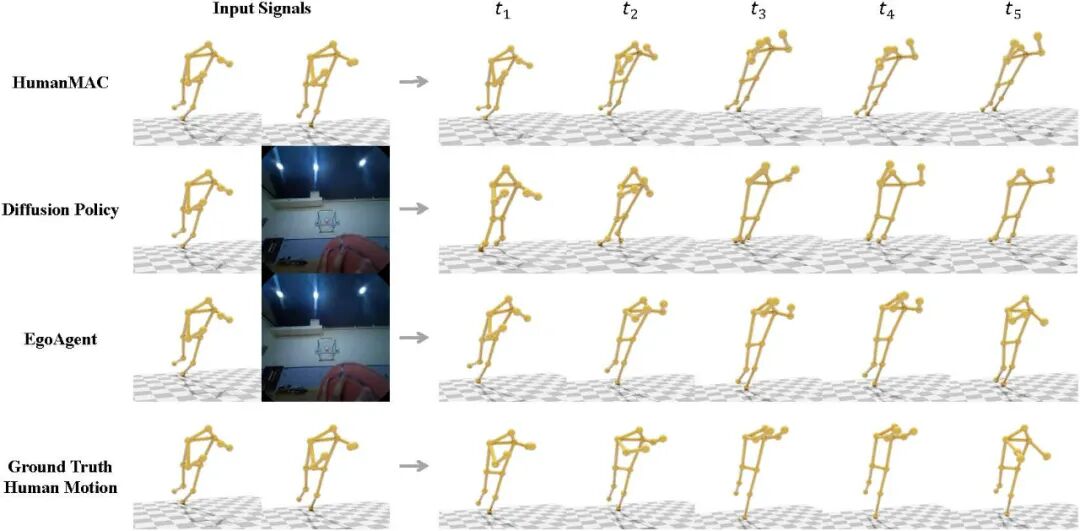
视觉表征:EgoAgent 从第一人称视频中学习到了鲁棒而通用的视觉表征,在基础的图像分类和具身操作任务中均表现出良好的迁移能力。在 ImageNet-1K 上,EgoAgent-1B 的 Top-1 准确率比 DoRA 提高了 1.32%,表明感知、预测与行动的联合学习有助于获得更具判别力的视觉特征。进一步地,在 TriFinger 机器人操作模拟器中,EgoAgent 使用 100 段演示数据,通过 3 层 MLP 微调,在 “抓取方块” 和 “移动方块” 两项任务中均取得最高成功率,分别超越 DoRA 3.32% 和 3.9%。这说明将人体动作预测融入视觉学习,有助于模型获得更具可操作性的表征,从而在具身任务中展现出更强的泛化与控制能力。

消融实验:为了验证各任务间的相互作用,研究团队对 EgoAgent 进行了系统的消融实验。结果表明,视觉表征、动作预测与世界预测三项任务相互支撑、缺一不可。当去掉其中任意一项任务时,其余任务的性能都会下降。相反,当三项任务在统一框架下联合优化时,模型在各项评估指标上均获得最优结果。这一现象表明,多任务的联合学习能够形成正向反馈机制:视觉任务提供感知语义,动作任务引导动态建模,而世界预测任务通过时间连续性约束整体的潜在空间。这种任务间的协同优化,使 EgoAgent 能够更稳定地捕捉感知 - 行动之间的关联,在整体表现上超越单任务模型。进一步的消融结果表明,在语义特征空间中进行学习的模型,在世界预测的准确性和视觉表征的有效性方面均显著优于基于像素级重建的潜空间建模。

未来:AI 的 “第一人称” 进阶
EgoAgent 不仅仅是一个强大的模型,它代表了一种新的 AI 学习范式:让模型像人类一样,在充满动态和交互的第一人称视角下,同时学习视觉表征、运动控制和世界模型。它的应用前景极其广阔:
机器人: 有望提升机器人的场景感知和操作能力,在复杂环境中精准预判物体动态和自身动作对环境的影响,实现更自然的交互和协作。
AR/VR: 基于第一人称视角的学习机制,可能帮助系统更好地理解用户的动作语义与环境动态,增强体验的沉浸感。
智能眼镜:这类模型有潜力在连续视觉流中识别用户意图或环境变化,全天候分析动作和环境的潜在危险并提供辅助性决策支持。

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com










