
新智元报道
新智元报道
【新智元导读】AI新突破!DeepSeek-OCR以像素处理文本,压缩率小于1/10,基准测试领跑。开源一夜4.4k星,Karpathy技痒难耐,展望视觉输入的通用性。
DeepSeek再次让全世界大吃一惊!
他们最新成果DeepSeek-OCR,从根本上改变了游戏规则——
文本并非通用的输入。反而,视觉将取而代之!

此外,在光学文字识别OCR任务上,DeepSeek-OCR模型名副其实,堪称工程学的巅峰之作——
🚀在单卡A100-40G上,可达每秒约2500 Token,跑得飞快。
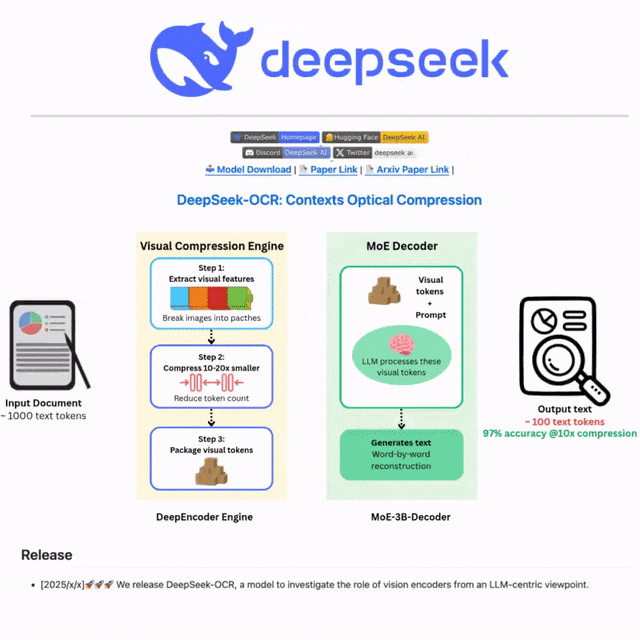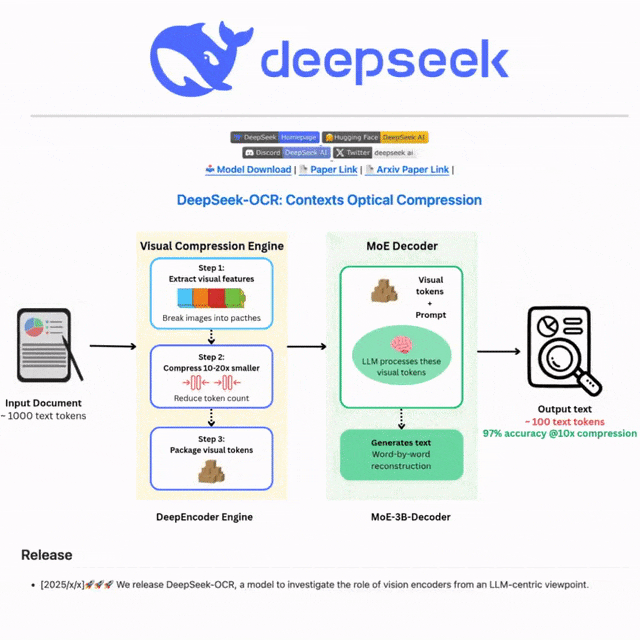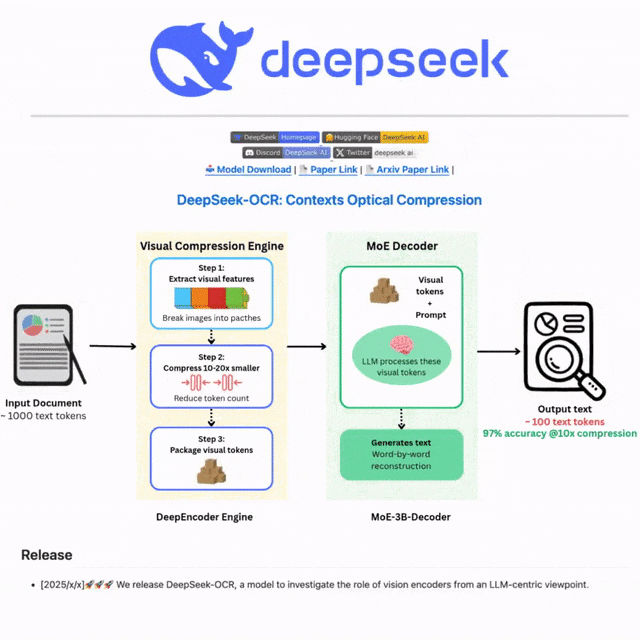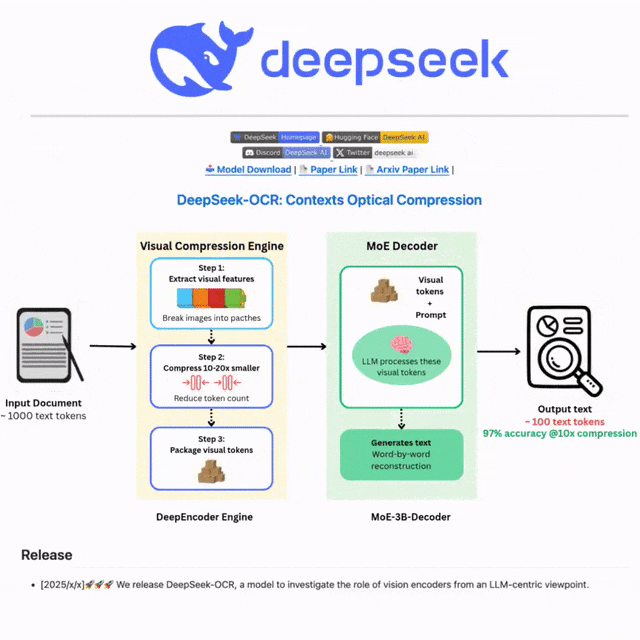
🧠在保持97% OCR准确率的前提下,可将视觉上下文压缩至原来的1/20,常规使用下压缩比也能轻松小于1/10。
📄在OmniDocBench基准测试中,使用更少的视觉Token,即可超越GOT-OCR2.0和MinerU2.0的表现。

到底效果多惊艳?
一整页密密麻麻的文本,被压成仅仅100个视觉Token,在 OmniDocBench上实现最多60倍压缩!
DeepSeek-OCR简直把文字变成了像素点,就像把一本100页的书压缩成一张照片,AI依然能读懂它。

参数少、压缩率高、速度快、涵盖100种语言……DeepSeek-OCR全都要。
不仅理论价值大,实用性还很高强,好评如潮:




Github开源项目DeepSeek-OCR,一夜收获4.4k星🌟:

DeepSeek-OCR用事实证明,实体页面(如缩微胶片、书籍)才是训练AI模型的更优数据源——而非低质量的互联网文本。
「骨子里的计算机视觉研究者」、特斯拉前AI总监、OpenAI创始团队成员Karpathy,难掩欣喜,力挺DeepSeek新模型。

Karpathy相当喜欢。
但更有趣的部分在于,对于大语言模型来说,像素输入是否优于文本输入?在输入端,文本Token会不会是一种既浪费又糟糕透顶的方式?
DeepSeek-OCR在动摇「文本作为AI的核心地位」,而视觉或将再次成为主流!
Karpathy自称「骨子里搞计算机视觉」,只是暂时混迹在自然语言处理圈,自然对上述问题尤其感兴趣。

上下滑动查看
或许,大语言模型的所有输入都只应该是图像,这才更有道理。就算你手头是纯文本输入,可能也最好先把它渲染成图像再喂给模型:
更高的信息压缩率 => 更短的上下文窗口,更高的效率。
信息流的通用性显著增强 => 不再局限于文本,还可以处理粗体、彩色文本乃至任意图像。
输入现在可以轻松地、默认地采用双向注意力机制处理,而不再是自回归注意力——这可要强大得多。
干掉(输入端的)分词器tokenizer!!
特别是最后一点,Karpathy忍了很久了,早就多次吐槽分词器太烂了——
分词器丑陋、独立,并非端到端的环节。
它「引入」了Unicode和字节编码的所有糟粕,背负着沉重的历史包袱,还带来了安全/越狱风险(比如连续字节问题)。
它让两个肉眼看起来一模一样的字符,在网络内部却变成了两个风马牛不相及的 Token。
一个微笑的表情符号😄,,而不是一个带有像素、承载着丰富信息、能从中进行迁移学习的真实笑脸。
总之,Karpathy认为,分词器「恶行累累」,这次必须赶走分词器。

此外,他展望了视觉成为通用输入的前景:
OCR只是「视觉到文本」众多落地应用中的一种。而「文本到文本」的任务也可以被改造为「视觉到文本」的任务,反之则不行。
所以,或许用户输入的消息是图像,但解码器(即「智能助理」的响应)依然是文本。
至于,到底如何真实地输出像素或者说你是否真想这么做,就远没那么明朗了。
现在,Karpathy表示,他要拼命忍住,不去搞一个只用图像输入的「nanochat」的支线任务。

有网友问:
首先,为什么图像能轻易获得双向注意力,而文本却不能?
另外,虽然图像没有像文本那样的「Token化」过程,但我们把输入图像切割成一个个图像块(patches)时,难道得到的不是类似,甚至可能更不理想的结果吗?

对此,Karpathy表示,原则上可以,只不过为了追求效率,文本(的生成)通常采用简单的自回归方式进行训练。
可以设想存在一个中间训练阶段,利用双向注意力机制,微调条件信息,比如那些我们不需要去预测或生成的代表用户消息的Token。
原则上,你可以对整个上下文窗口进行双向编码,而目的仅仅是为了预测下一个 Token。但这么做的代价就是无法并行化训练。
至于第二个问题,他认为,严格来说与「像素 vs. Token」无关。其核心更在于,像素通常是被编码的(encoded),而 Token则是被解码的(decoded)。
至于,Karpathy的「nanochat支线任务论」,网友并不认可:
DeepSeekOCR证明这不仅关乎压缩——更是语义的蒸馏。
分词器时代意味着识字,像素时代则关乎感知。
Nanochat不该是支线任务,它是「光学认知」的开端。

帖子下面,网友恳求Karpathy:快搞个只用图像输入的「nanochat」吧!




Karpathy的前老板、「好兄弟」马斯克给出了更科幻的猜想:
长期来看,AI模型超过99%的输入和输出将是光子。

马斯克让Grok估计了一下已知宇宙的光子总量:
1=估算可观测宇宙中的光子总数是一项复杂的工作,但我们可以基于几个主要组成部分得出一个大致数字:宇宙微波背景辐射(CMB)产生的光子、星光光子,以及其他一些微弱来源。
……
宇宙微波背景辐射(CMB)占据主导地位,使得可观测宇宙中的光子总数约为1.5×10⁸⁹个 。这个数字是一个粗略估算,具体数值取决于可观测宇宙的精确体积以及其他微小来源的贡献,但整体上与宇宙学计算结果相符。
1.5×10⁸⁹!没有其他东西能达到这种规模。这就是马斯克的逻辑。
毕竟,人类就是通用「光学计算系统」——眼睛来认识世界的:


论文地址:https://github.com/deepseek-ai/DeepSeek-OCR/blob/main/DeepSeek_OCR_paper.pdf
论文一作Haoran Wei,此前也是GitHub 7.9k星爆火项目GOT-OCR2.0,即「General OCR Theory: Towards OCR-2.0 via a Unified End-to-end Model」的一作。

项目地址:https://github.com/Ucas-HaoranWei/GOT-OCR2.0

论文地址:https://arxiv.org/abs/2409.01704

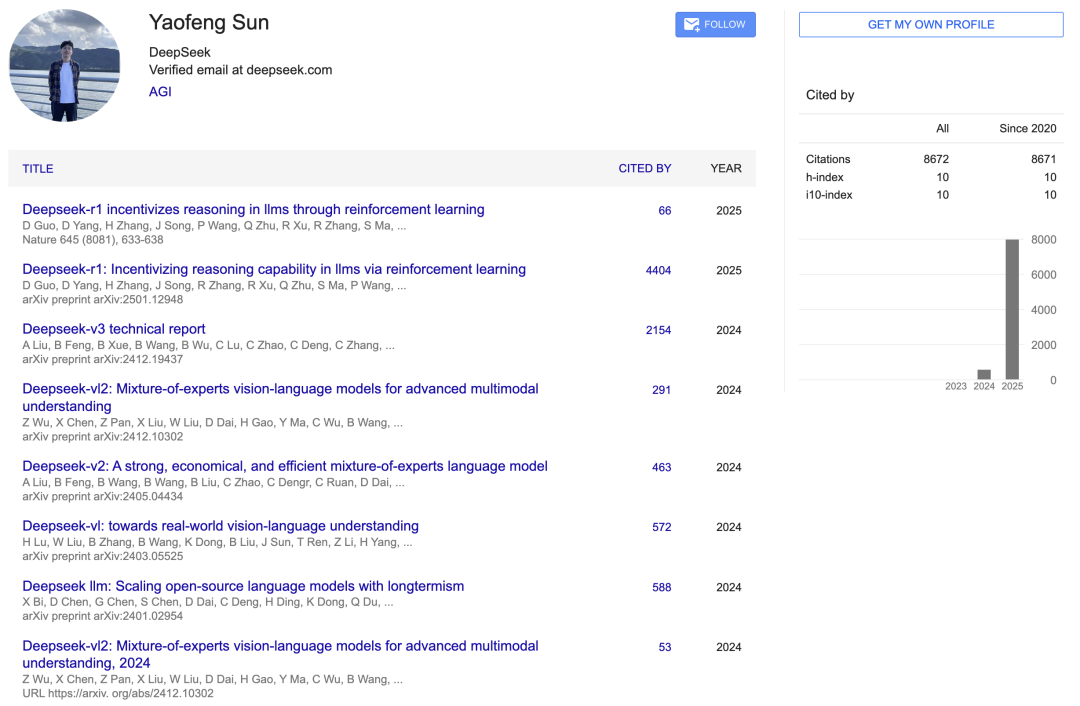
Yaofeng Sun是DeepSeek的软件工程师,于2023年加入幻方AI/DeepSeek。

谷歌学术显示,他参与了DeepSeek-r1、DeepSeek-v3、DeepSeek-vl2、DeepSeek-v2、DeepSeek-vl、DeepSeek LLM等模型的研究。
据悉,他本科毕业于北京大学图灵班(Turing Class)计算机科学专业。
他代表北京大学参赛,获得ACM-ICPC 亚洲区域赛金牌(2017–2019),获奖赛区包括:EC 总决赛 2017、青岛 2017、西安 2017、上海 2019、南京 2019。
之前,他获得全国信息学奥林匹克竞赛(NOI)金牌(2015、2016)。

Yukun Li也是高产的AI从业者——
2020年至今,引用数已过9千;参与过DeepSeek-v3、DeepSeek-vl2、DeepSeek-v2、DeepSeek-Coder、DeepSeek-MoE、DeepSeek LLM等项目研究。

我们一起见证他们带来的AI新突破,一起见证开源AI的崛起!










