
> 本文来自社区投稿,作者:孟祥玉
本篇分享论文《Identity-GRPO: Optimizing Multi-Human Identity-preserving Video Generation via Reinforcement Learning》来自阿里云的团队探讨了如何在多人物视频生成中更好地保持身份一致性的问题,提出的Identity-GRPO算法在这一问题上取得了一定的进展,目前代码及权重已全面开源。

ArXiv 链接:https://arxiv.org/abs/2510.14256 Project Page:https://ali-videoai.github.io/identity_page Github开源代码:https://github.com/alibaba/identity-grpo

引言:多人物定制化视频生成的技术瓶颈
随着Diffusion Transformer架构的发展,高质量视觉内容生成已经取得了显著进展,特别是身份保持视频生成技术——即创造具有一致人类身份的高保真度视频——已成为一个重要研究方向。
然而,当涉及到多人物身份保持视频生成(MH-IPV)任务时,即使是目前最先进的模型如VACE和Phantom也面临着严峻挑战。这些模型必须在满足复杂文本指令的同时,在整个视频序列中维护各个角色的身份一致性。研究者们观察到,现有模型常常会为了整体构图相似性而牺牲个体身份的准确性。比如,在处理类似"两个穿着不同服装的人同步跳舞"这样的提示词时,模型可能会交换角色间的面部特征,导致运动模式连贯但身份严重错位的现象等。
Identity-GRPO:专为多人物身份一致性设计的后训练优化算法
为了解决这一问题,阿里的研究团队提出了一种全新的人类反馈驱动的优化策略——Identity-GRPO,这是首个专门针对多人物身份保持的视频生成场景设计的人类偏好驱动的对齐策略。
核心技术亮点
1. 大规模偏好数据集构建
研究团队构建了一个包含约15,000个标注样本的大规模高质量数据集。该数据集采用了半自动化框架结合人工标注的混合流水线,通过对五个先进视频生成模型的生成视频对进行精细地筛选和标注,从而获得最终的成对的偏好数据。这种方法的优势在于超越了人工标注的限制,同时通过质量控制的过滤方式保持了与人类偏好的严格对齐。
2. 专用奖励模型设计
传统的奖励信号如ArcFace在多人物场景中存在局限性,容易受到非身份相关因素的影响,产生所谓的"复制粘贴"效应(Copy-Paste Issue)。为此,研究人员基于Qwen2.5VL模型,训练了一个能够捕捉成对视频样本间细粒度身份一致性质量差异的专用奖励模型。该模型采用了两阶段训练方法:先在高质量的人工标注数据集上训练初步奖励模型,然后用其对自动标注数据进行一致性过滤,最终在人工标注数据和过滤后的自动标注数据上联合训练获得最优效果。
3. Identity-GRPO在MH-IPV任务上的针对性改进
Group Relative Policy Optimization(GRPO)虽然在复杂推理任务中表现出色,但在应用于MH-IPV任务时面临独特挑战。不同于T2V任务,MH-IPV任务的输入包含多个模态,这引入了显著的方差,使得采样的视频难以支持稳定的GRPO训练。为此,Identity-GRPO引入了多项增强GRPO训练稳定性的策略:
初始噪声差异化:可以扩大生成视频之间的多样性。在MH-IPV中,由于参考图像的约束,仅依靠SDE引入的随机性,很难在同一组视频中创建显著的身份差异。这严重限制了强化学习训练所需的探索空间。因此,在采样过程中,研究团队采用不同的初始化噪声来增强生成视频之间的多样性。 更大批次的视频采样:可以应对多种模态输入的方差问题。在Identity-GRPO中,由于不同模态之间的方差,仅使用少量视频进行单次参数更新可能导致训练不稳定甚至崩溃。所以研究团队在Identity-GRPO的单次参数更新中采样更多数量的视频样本以增强训练稳定性--这类似于在标准训练中使用更大的批次大小。 提示词细化:可以确保提示词准确描述参考图像中的人物特征。在本工作中,研究团队发现不同的基础模型,如VACE和Phantom,对提示词和参考图像的差异表现出不同的敏感程度。因此研究团队采用了Qwen2.5-VL来细化提示词,生成包含参考图像中人物角色的准确描述的提示词以提升训练效果。
实验验证:显著的性能提升
经过广泛的消融研究和系统性评估,Identity-GRPO展现出了令人瞩目的表现:
Identity-Consistency Reward 曲线

图中的(a) 和 (b) 分别显示了 Identity-GRPO 在 VACE-1.3B 和 Phantom-1.3B 上的身份一致性奖励值的曲线。两者都表现出明显的上升趋势。说明了Identity-GRPO基于多个模型均可以取得一致的性能提升。
定量实验结果

在身份一致性指标上,Identity-GRPO 相比基准方法VACE提升了最高18.9%; Identity-GRPO 相比Phantom模型提升了6.5% 的性能; 除此之外,在论文中展示的偏好准确性基准测试中,提出的身份一致性奖励模型达到了0.890 的准确率,明显优于传统方法ArcFace,它的准确率仅有0.772。
可视化结果对比
前两组视频展示了Phantom-1.3B与Phantom-1.3B+Identity-GRPO的对比,最后两组视频则是VACE-1.3B与VACE-1.3B+Identity-GRPO的对比。 在每一组中,第一段视频展示了基线模型的结果,第二段视频则展示了由Identity-GRPO优化后的生成结果。在这些情况下,基线模型生成视频中的人物明显与参考图像不匹配,而Identity-GRPO则始终保持着较高的身份一致性。

消融实验
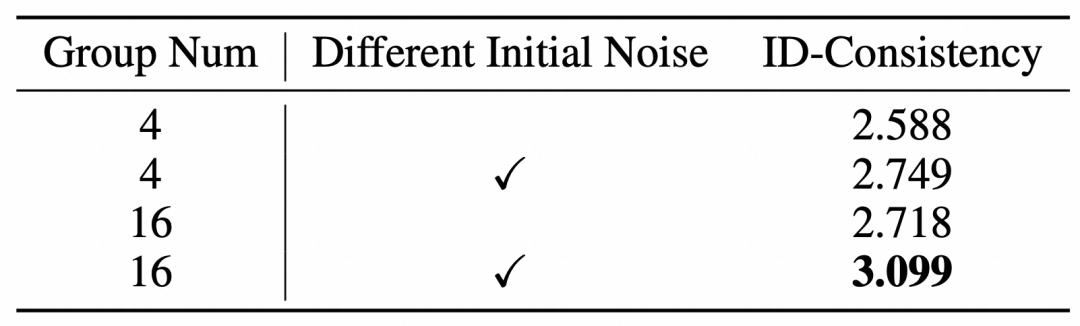
由于MH-IPV任务中的多模态输入条件,在每次参数更新中使用更大批次的视频以及多样化的初始噪声对于实现稳定的Identity-GRPO训练至关重要。如表格所示,当视频数量不足时,GRPO训练会变得不稳定,在采样一组视频时使用相同的初始化噪声会限制GRPO的探索空间,从而都会阻碍身份一致性奖励分数的提升。
技术创新价值
这项研究的贡献主要体现在三个方面:
数据集资源:提供了首个面向多人物身份保持视频生成的高质量人类偏好标注数据集 方法论创新:设计了多人物身份一致性奖励模型,并系统研究了针对MH-IPV任务的GRPO训练配置 实践指导意义:为复杂多人物生成任务中强化学习与一致性视频生成的整合提供了新的见解
小结
Identity-GRPO工作是多人物身份保持视频生成领域的一个积极探索。通过在现有技术基础上的优化,为解决这类问题提供了一条可行的思路。这项研究为后续相关工作积累了有价值的经验。期待看到更多研究者在这个有趣的方向上进行深入的探索和改进。
参考文献:
Identity-GRPO: Optimizing Multi-Human Identity-preserving Video Generation via Reinforcement Learning VACE: All-in-One Video Creation and Editing Phantom: Subject-Consistent Video Generation via Cross-Modal Alignment
研究团队的工作:
Tora: Trajectory-oriented Diffusion Transformer for Video Generation[1] Tora2: Motion and Appearance Customized Diffusion Transformer for Multi-Entity Video Generation[2] AnimateAnything: Fine Grained Open Domain Image Animation with Motion Guidance[3]
Tora: Trajectory-oriented Diffusion Transformer for Video Generation:https://arxiv.org/abs/2407.21705
[2]Tora2: Motion and Appearance Customized Diffusion Transformer for Multi-Entity Video Generation:https://arxiv.org/abs/2507.05963
[3]AnimateAnything: Fine Grained Open Domain Image Animation with Motion Guidance:https://arxiv.org/abs/2311.12886










