在 ICCV 2025 中看到了 6 篇“腾讯混元”团队相关的论文推荐给大家!
(1) SVG-Head: Hybrid Surface-Volumetric Gaussians for High-Fidelity Head Reconstruction and Real-Time Editing

论文简介:
由清华大学与腾讯混元团队提出的SVG-Head,该工作通过混合表面-体积高斯表示实现了高保真头像重建与实时外观编辑。针对传统方法在几何与外观纠缠建模导致编辑困难的问题,该方法创新性地采用两种高斯分布:表面高斯(surf-GS)通过绑定FLAME网格表面并设计网格感知的UV映射,将头像外观解耦为可实时编辑的显式纹理图像(包含基础纹理与动态表情纹理);体积高斯(vol-GS)则通过自由移动建模非朗伯区域(如头发、嘴唇)的几何细节。技术上,通过约束表面高斯中心在网格表面并固定其旋转方向,结合基于重心坐标的UV映射,确保了纹理图像的清晰度与实时渲染效率;分层优化策略先独立优化表面高斯获取高质量纹理,再联合体积高斯进行互补优化。实验表明,该方法在NeRSemble数据集上实现了与非编辑类方法相当的渲染质量(PSNR 30.3/SSIM 0.931),同时首次为高斯头像赋予了显式纹理编辑能力,相较MeGA等优化驱动方法,可实现毫秒级精细纹理编辑(如皱纹修改),编辑速度提升3个数量级。其混合表示框架为AR/VR场景中的实时虚拟人交互提供了新范式。
论文来源:iccv2025
PaperScope.ai 解读:
https://paperscope.ai/hf/iccv2025.2580
(2) RomanTex: Decoupling 3D-aware Rotary Positional Embedded Multi-Attention Network for Texture Synthesis

论文简介:
由腾讯混元和上海科技大学等机构提出的RomanTex,通过引入3D感知的旋转位置嵌入多注意力网络,实现了高质量纹理合成。该工作创新性地设计了3D-aware RoPE机制,将三维几何信息嵌入多视图扩散模型,有效解决了传统方法存在的多视角不一致问题。通过解耦的多注意力模块设计,模型在保持2D图像多样性的同时,显著提升了背面纹理的语义正确性。此外,几何相关的无分类器引导技术动态平衡了图像与几何条件的约束冲突,尤其在处理非规则几何体时展现出更强的鲁棒性。实验表明,RomanTex在纹理质量、多视图一致性及用户感知偏好等维度均超越现有方法,生成的3D资产纹理在视觉连续性、材质细节表现和几何对齐度方面达到新高度,为AI驱动的3D内容生成提供了突破性解决方案。
论文来源:iccv2025
PaperScope.ai 解读:
https://paperscope.ai/hf/iccv2025.2141
(3) MaterialMVP: Illumination-Invariant Material Generation via Multi-view PBR Diffusion
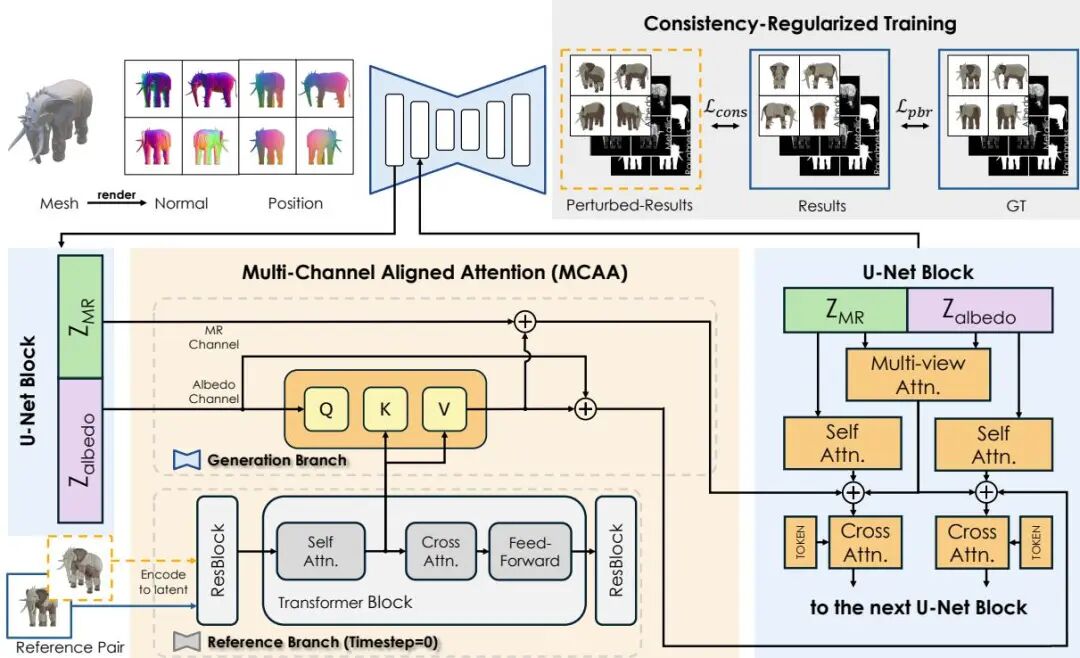
论文简介:
由中山大学深圳校区、腾讯混元、香港科技大学等机构提出了MaterialMVP,该工作通过多视角PBR扩散模型实现光照不变的高质量材质生成。研究者针对多视角材质合成中的关键挑战,创新性地构建了端到端生成框架:首先采用Reference Attention机制从参考图像中提取精细特征,确保纹理生成的细节保留;其次提出Consistency-Regularized Training策略,通过训练时引入视角和光照微变的图像对,强制模型输出一致的光照不变材质,有效解耦材质属性与光照干扰;进一步设计Dual-Channel Material Generation框架,将albedo(漫反射)与metallic-roughness(金属度-粗糙度)通道分离优化,通过Multi-Channel Aligned Attention实现跨通道特征对齐,并引入Learnable Material Embeddings捕捉通道特异性分布。实验表明,该方法在Objaverse数据集上生成的PBR材质在FID、LPIPS等指标上全面超越现有方法,尤其在复杂光照条件下的物理一致性表现突出。生成的材质在环境光照渲染中展现出逼真的反射、粗糙度等物理行为,同时保持了与输入图像的像素级对齐,为3D资产创建提供了高效可靠的解决方案。
论文来源:iccv2025
PaperScope.ai 解读:
https://paperscope.ai/hf/iccv2025.389
(4) Unleashing Vecset Diffusion Model for Fast Shape Generation

论文简介:
由腾讯混元、港中文MMLab等机构提出了FlashVDM框架,该工作通过系统性优化Vecset Diffusion Model(VDM)的扩散采样和VAE解码流程,实现了3D形状生成速度的跨越式提升。针对扩散模型采样速度瓶颈,研究者提出Progressive Flow Distillation方法,通过分阶段的引导蒸馏、一致性损失优化和对抗微调,在仅需5步推理的情况下保持生成质量;针对VAE解码的立方复杂度问题,创新性地引入自适应键值选择(Adaptive KV Selection)减少注意力计算量,结合分层体积解码(Hierarchical Volume Decoding)利用形状表面稀疏性降低查询次数,并通过轻量化网络设计进一步压缩计算量。实验表明,该方法在Hunyuan3D-2模型上实现45倍解码加速和32倍端到端加速,将高分辨率3D形状生成时间压缩至1秒内,同时保持与原模型相当的重建和生成质量。这项工作首次将大规模3D生成模型推入毫秒级交互应用范畴,为实时3D内容创作开辟了新可能。
论文来源:iccv2025
PaperScope.ai 解读:
https://paperscope.ai/hf/iccv2025.61
(5) SparseMM: Head Sparsity Emerges from Visual Concept Responses in MLLMs

论文简介:
由清华大学和腾讯混元团队提出的SparseMM,揭示了多模态大语言模型(MLLMs)中注意力头的视觉相关性呈现显著稀疏性现象——仅有不足5%的注意力头实际参与视觉理解过程。该研究通过OCR任务建立文本输出与图像区域的精确对应,量化各注意力头的视觉响应得分,发现视觉相关头在模型架构和注意力范式中均呈现跨模型的普遍性。基于这一发现,团队设计了动态分配KV缓存预算的优化框架SparseMM:通过局部窗口缓存、均匀基线缓存和视觉得分优先缓存的三重分配机制,优先保障视觉语义关键头的计算资源,同时对非视觉头进行针对性压缩。实验显示,在DocVQA等多模态基准测试中,SparseMM在仅保留5-10%缓存预算时仍能维持与完整模型相当的性能,相较SnapKV等基线方法减少50%内存占用的同时实现1.38倍推理加速。该方法在LLaVA-NeXT和Qwen2-VL等主流架构中均验证有效,为资源受限场景下的多模态模型部署提供了新范式。
论文来源:iccv2025
PaperScope.ai 解读:
https://paperscope.ai/hf/iccv2025.2414
(6) Stable-Sim2Real: Exploring Simulation of Real-Captured 3D Data with Two-Stage Depth Diffusion

论文简介:
由香港中文大学深圳、FNii深圳、腾讯混元3D等机构提出了Stable-Sim2Real,该工作基于两阶段深度扩散模型探索数据驱动的3D数据模拟新路径。针对现有方法依赖物理先验导致泛化性不足的问题,研究者提出通过生成深度残差实现从合成数据到真实数据的隐式映射。核心创新在于:1)Stage-I通过微调Stable Diffusion生成深度残差,将合成深度与残差叠加获得初步真实深度;2)引入3D判别器识别生成结果中的局部失真区域;3)Stage-II扩散模型在保留Stage-I生成结果的基础上,通过加权损失函数重点优化失真区域。实验表明,该方法在3D重建和理解任务中显著优于Cycle-GAN、Pix2Pix等基线,少样本学习下mIoU提升达3.9%,Chamfer距离降低34%。研究者还构建了包含3D重建、分类、分割的综合评估基准,通过模拟数据预训练模型在真实数据上的泛化能力验证方法有效性。消融实验证明残差生成、损失重加权等设计的关键作用,可视化结果展示其在几何细节恢复上的优势。该工作为数据驱动的3D仿真提供了可扩展的新范式。
论文来源:iccv2025
PaperScope.ai 解读:
https://paperscope.ai/hf/iccv2025.1030










