摘要
开发可靠的感知机器学习(ML)模型对于自动驾驶车辆的安全运行至关重要。然而,获取足够的真实世界数据用于测试和训练这些模型并非易事。需求驱动能够将深度学习(DL)模型集成到复杂系统中,例如高自动化车辆,这类系统要求在安全关键场景下具备可靠性能。
感知模型的性能需依据运行设计域(ODD)内预先定义的数据需求进行评估,运行设计域明确了安全运行的条件。要开发在安全关键型应用中性能可靠的感知模型,训练数据集需与特定运行设计域的系统级需求保持一致。但构建完全满足这些需求的数据集面临挑战,系统在不安全场景下可能无法正常运行,这一点在自动化和自主系统中尤为重要。
研究聚焦于系统虽按设计运行,但由于设计局限、环境因素或系统对复杂场景的解读问题,安全性可能受到影响的情况。因此,为降低风险,全面的运行设计域分析必不可少,需确保数据中既包含安全关键案例,也涵盖非关键案例。然而,若不研究特定风险,无法覆盖所有场景,因为这类情况可能导致模型做出不确定的预测。
为评估模型性能,需依据系统需求中规定的目标值,对记录数据(有时需额外标注)进行评估。机器学习模型的性能会受到两类因素影响:一是系统性影响,如模型无法处理分布外样本、极端案例或域偏移;二是随机性影响。这两类与数据相关的缺口都可能导致模型在潜在安全关键场景下表现不佳。
本文重点研究模型存在认知不确定性的缺口,将其定义为数据集覆盖缺口。为解决这些缺口,提出一种混合训练方法:生成合成样本以针对性填补已识别的缺口,并将其迭代增强到真实数据中。这种系统性方法旨在提升感知模型在局部数据空间区域的性能,同时改善整体性能和泛化能力,确保满足真实世界应用的安全需求。
1、可能的贡献
由于架构设计欠佳,模型的学习能力与训练数据所呈现的功能输入 - 输出行为可能不匹配。这种不匹配被定义为模型不确定性。该不确定性可能导致过拟合、欠拟合或归纳偏差,进而造成模型在运行设计域内的性能局限。此类缺口具有系统性,可归为认知不确定性。通过对深度感知模型及其训练和测试数据集进行系统性分析,能够识别功能相关问题。
第二类是数据相关缺口,源于训练数据与真实世界环境的差异。数据缺口的产生原因有二:(1)数据采集问题,通过噪声或模糊引入随机不确定性;(2)数据范围、代表性、完整性或多样性存在局限,例如引发认知不确定性。
研究采用自上而下与自下而上相结合的迭代方法,从需求出发,对模型进行分析并评估其性能。这种方法可将安全层面的自上而下因素与模型和数据集分析层面的自下而上因素相结合。其中,自上而下方法借鉴了研究,为自动驾驶系统构建了系统性的数据驱动工程循环,相关内容可参见图1。

图1、用于迭代识别和缓解数据相关缺陷并调整需求的拟议工作流周期。我们的方法旨在构建一个模型优化和数据改进的迭代周期,以实现更完善的数据集设计,其中包括对机器学习(数据)需求的调整
2、关于数据集覆盖缺口的全面探讨
数据集覆盖缺口存在于局部数据区域,这些区域中某些特征(如场景或特征类别)的表示不足。此类缺口可能导致数据点缺失、类别分布不均衡或变化有限,使模型无法学习到可靠预测所需的全部模式。
因此,在存在这类缺口的数据集上训练的模型,可能在训练过程中表现良好,但在真实世界场景中,遇到未见过或表示不足的模式时就会难以应对。填补这些缺口对于构建能在不同条件下良好泛化的模型至关重要。
2.1 数据集覆盖缺口的定义
数据集缺口可能导致模型产生偏差,阻碍模型泛化,使模型在新数据上(尤其是安全关键型应用中的新数据)出现高错误率。数据增强、合成数据生成和目标导向数据采集等策略可缓解这些问题。
理解覆盖缺口需要掌握机器学习相关知识,其可表示为一个包含n0个值的元组,表 1 以自动驾驶中的行人检测为例进行了说明。

表1、自动驾驶行人检测的运行设计域变量示例及有效范围
我们采用概率方法对p(y|x,Θ)进行建模,而非在输入和输出之间建立确定性映射。这种概率框架对于捕捉预测不确定性至关重要,尤其适用于自动驾驶这类安全关键型应用。
将运行设计域融入该框架后,我们认为输入x和输出y均会受到其影响。

图2、从数据准备到部署的典型机器学习流程
2.2 预期功能安全与触发条件
识别数据集缺口的一种方法是考察预期运行设计域内训练分布与目标分布之间的差异,图像分类器尤为如此。设分类器fΘ : X 7→ Y,对于给定图像x ∈ X,其可预测类别y ∈ Y = {1,...,C}的概率fΘ(y|x),其中x和y遵循分布p(x, y),Θ表示模型参数。
在此,我们重点关注模型在语义连贯数据子组(例如 “城市环境中的红色汽车”)上的表现,通过对潜在变量o进行条件设定,用p(x,y|o)表示这种子组关系。
运行设计域具有组合性,即O = O_0×...×O{nO - 1},其中每个Oi都是一个语义维度。每个oin O应的数据空间xtrig ∈ Xtrig ⊂ X,当超过某个阈值δtrig时,模型Θ
容易产生错误,表达式如下:
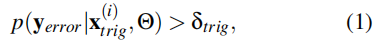
其中xtrig (i) ∈ Xtrig与第i个触发条件相关联,yerror表示错误预测。尽管有些条件可能超出运行设计域,但我们假设子空间Xtrig能通过p(x|otrig)得到充分表示,因此将分析范围限定在otrig ∈ O,进而形成子空间X|Otrig (i)。这使得在运行设计域场景下进行系统性测试成为可能。
超出o范围的触发条件可能需要监控和备用机制。这类条件带来的风险可通过故障概率、关键性、可控性和严重性的联合分布进行评估。正如指出的,自动驾驶感知系统通常有最低性能目标。
要获得可靠的性能评估结果,需满足以下两点:(1)确保评估数据的有效性;(2)明确模型存在性能缺口的情况。性能s的总不确定性Ss可表示为:
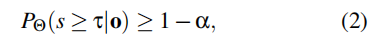
当公式 2 不成立时,表明在特定运行设计域条件下可能存在性能问题。由于难以获取pΘ(s|o)的精确值,我们用参数化分布pΘ(s|o)对其进行近似。
采用贝叶斯参数估计方法,可通过以下公式推断真实概率pΘ(s|o):
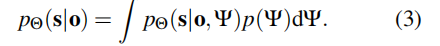
这种概率方法有助于将不确定性分为以下两类:(1)数据缺口,由数据不足导致;(2)模型相关缺口,源于模型自身局限。
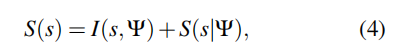
数据集覆盖缺口可能影响的关键性能指标之一是模型风险。因此,我们可以通过引入多粒度级别的缺口,研究 2.2 节中提出的概率模型,并探究这些缺口如何影响模型风险。
条件概率p(x|y,o)描述了类别y和子组o下图像x的分布,可用于识别视觉缺口(例如 “森林(oj)中的红色(oi)汽车(y)”)。同样,子组o内类别y的可能性p(y|o)可凸显类别不平衡或偏差,进而提示潜在的分类错误。
将联合分布p(x,y,o) 分解为这些组成部分(图 4),有助于识别子组级别的缺口:(po)可揭示缺失或表示不足的子组;子组内的类别级缺口可通过p(y|o)识别,该概率能发现特定子组中的类别不平衡,从而导致有偏差的预测;此外,还可识别图像级缺口,因为p(x|y,o)能凸显类别 - 子组对中有限的视觉多样性。

图3、利用合成数据识别覆盖缺口的验证循环。该循环通过创建测试数据集来评估模型缺陷并满足需求

图4、模型训练过程中出现的数据相关缺口示意图。该图聚焦于图像数据的语义连贯子组及类别分布中存在的缺口
子组o的风险RfΘ (o)反映了该子组内所有数据点的平均损失。通过概率量,可将其重写为:
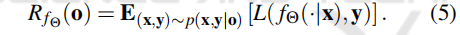

虽然po直接反映子组覆盖情况,但子组概率po与模型风险的关系可表示为:

该公式表明,风险既取决于给定类别y和子组o时观测到图像x的概率(即p(x|y,o),也取决于子组内的类别分布p(y|o)。这凸显了子组内的图像分布和类别分布均会对风险产生影响。
所有子组的总预期风险是每个子组风险的加权和,权重由子组概率决定,表达式如下:
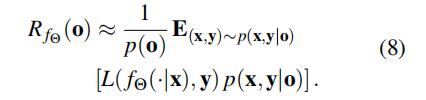
通常情况下,po值较低会导致RfΘ (o)值较高,这意味着即使低概率子组中出现较小错误,也可能显著提高整体风险。
3、结合真实数据与合成数据训练深度感知模型
为解决数据稀缺、成本高昂和标注耗时等问题,合成数据生成已成为训练深度感知模型的关键手段。这种方法可提供丰富多样的样本,提升模型的可靠性和泛化能力,尤其适用于自动驾驶和监控等安全关键型应用。
合成数据集还能复现真实世界场景,加快模型在新环境下的训练速度。合成数据生成涵盖多种方法:
1. 3D 引擎(如虚幻引擎、Unity)可创建照片级真实感数据集,例如 SYNTHIA、VirtualKitti和 VirtualKitti V2;
2. 视频游戏捕捉技术利用游戏图像生成数据集,如 DITM和 VIPER;
3. 生成式人工智能采用生成对抗网络(GANs)、扩散模型和无监督学习等技术合成高质量图像。
依据特定标准评估模型性能,利用最先进的合成数据识别覆盖缺口。在第二阶段,通过同一流程生成新的训练样本,迭代填补这些缺口,并根据新获得的见解优化数据和性能需求。这种方法在受控的、需求驱动的真实数据集与合成数据集生成及训练方面树立了新的标杆。
4、缓解措施
4.1 系统性识别性能缺陷
依据预先定义的需求验证感知模型,以识别性能缺陷,这是当前的研究热点。随着 ISO 21448(SOTIF)正式发布,该领域的研究预计会进一步发展。
以往研究表明,为安全关键型应用开发可靠的感知模型,需要数据集捕捉运行设计域内特定任务和场景相关的安全特征。数据集覆盖缺口往往会导致机器学习模型在功能上存在缺陷,尤其是在关键场景下。因此,系统性地识别并解决这些缺口至关重要)。
可通过生成或采样缺失的数据样本来改善模型在特定场景下的性能。本节将概述该概念的两个主要阶段,如图 3 和图 5 所示。
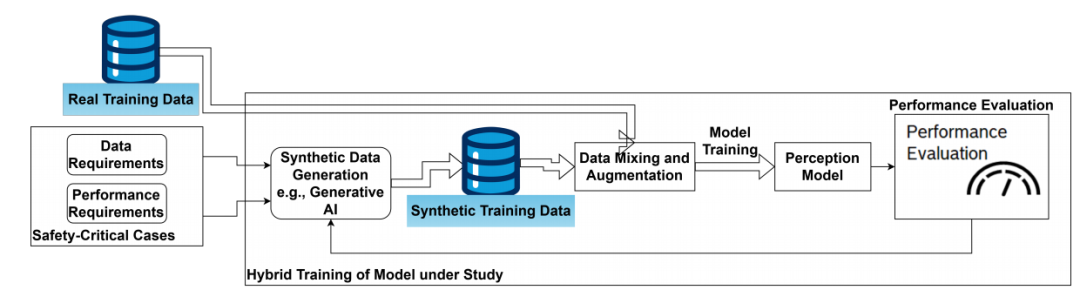
图5、我们提出的需求驱动型混合训练方法。该方法是一个迭代过程,它利用图 3 的见解来识别缺口、生成合成样本,并通过增强训练数据以提升模型性能
给定一个预训练感知模型和初始训练数据集,首先构建与运行设计域一致的测试数据集,以评估模型在运行设计域内的性能。通过减少测试案例数量同时保持覆盖范围,可提高评估效率。这种方法通过仅选择性地增加安全关键组合的数量,缓解了组合爆炸问题。
进一步,利用敏感性分析和不确定性度量,在不同粒度级别上分析特征子组的缺陷,从而精准定位训练数据覆盖中的认知不确定性缺口。
现成的数据集通常无法满足这一需求。因此,提出了一种合成样本生成流程,用于发现分类模型的稀有数据子组。我们对该方法进行调整,以需求驱动的方式迭代生成合成数据集,确保其与运行设计域保持一致,从而对模型进行全面测试。
4.2 针对性数据生成以缓解缺口
主动学习是一种有效的方法,可用于结合真实数据和合成数据训练检测器。它通过采样系统性地填补第一部分中识别出的真实世界数据集缺口,提高检测器在关键数据区域的性能。
我们计划研究真实数据与合成数据之间在外观缺口(如颜色失真、运动模糊)和元数据差异(如环境条件、物体位置)方面的影响,以及潜在的标签和分布差异,从而实现合成数据向真实世界训练数据集的可靠增强,并解决已识别的缺口。
通过采用最先进的合成数据生成技术,首先创建符合预定义安全需求的测试数据集,进而探究机器学习感知模型在模型和数据相关方面可能存在的缺口,这些缺口可能导致性能缺陷,尤其在安全关键场景中。
5、结论
本文提出了一种基于需求驱动的方法,用于系统性地探究机器学习感知模型在模型和数据相关方面的缺口,这些缺口可能导致性能缺陷,尤其在安全关键场景中。
本文借助软件翻译,如有不当之处请参照原文
下载请扫二维码: