近期,中山大学和拓元智慧团队联合提出Task-Aware View Planning(TAVP)框架,针对当前视觉-语言-动作(VLA)模型在机器人多任务操控中存在的3D感知局限与任务干扰问题,通过融合动态视角规划与任务感知特征提取,显著提升了机器人在复杂场景下的动作预测准确性与任务泛化能力。
相关研究成果在RLBench基准测试的18项操控任务中展现出超越现有固定视角方法的性能。

论文标题:Learning to See and Act: Task-Aware View Planning for Robotic Manipulation 作者:Yongjie Bai, Zhouxia Wang, Yang Liu, Weixing Chen, Ziliang Chen, Mingtong Dai, Yongsen Zheng, Lingbo Liu, Guanbin Li, Liang Lin 项目主页:https://hcplab-sysu.github.io/TAVP
一、研究背景:固定视角与共享编码成机器人多任务操控关键瓶颈

当前主流的机器人VLA模型(如OpenVLA、π0.5等)多依赖单一或固定视角(相机相对机器人的位置不变)观测与共享视觉编码器,在复杂场景中面临两大核心挑战:
3D感知不完整:固定视角易导致目标物体或机械臂末端遮挡,例如“将糖放入橱柜”任务中,前视摄像头仅能捕捉橱柜,肩视摄像头仅能看到机械臂抓取的糖,造成场景理解缺失与动作预测失误; 任务干扰严重:共享编码器在处理视觉与语义差异大的任务(如“拿起苹果”与“打开抽屉”)时,特征会相互纠缠,限制模型在多任务场景下的泛化能力与扩展性。
为解决上述问题,研究团队提出TAVP框架,从“动态感知视角”与“任务专属编码”两大维度重构机器人操控的视觉-动作链路。
二、核心创新:双模块突破技术瓶颈,实现“感知-动作”协同优化

TAVP框架的核心在于两大创新模块——多视角探索策略(MVEP)与任务感知混合专家编码器(TaskMoE),并通过三阶段训练策略实现模块协同优化,具体设计如下:
1.多视角探索策略(MVEP):动态捕捉“关键视角”,解决3D感知遮挡问题
针对固定视角的局限性,MVEP模块通过强化学习训练视角探索策略,能基于场景全局点云主动选择最优的虚拟摄像头位姿并进行重渲染,获取更加丰富的二维图像,核心设计包括:
视角参数化:采用“Look-at模型”将摄像头位姿表示为5维向量(球坐标下的方位角、仰角、距离及上向量方向),确保视角在合理范围内可解释与优化; 高效策略训练:引入“伪环境交互机制”,利用离线专家数据与预训练模型生成参考损失,避免物理环境交互的高时间成本;同时设计三重奖励函数(任务损失差、热力图置信度、视角多样性),引导策略选择覆盖目标物体与机械臂末端的关键视角; 动态重渲染:将最优视角重渲染为2D图像,为后续特征提取提供更完整的场景信息,有效缓解遮挡导致的感知缺失问题。
2.任务感知混合专家编码器(TaskMoE):解耦任务特征,消除多任务干扰

为解决共享编码器的任务干扰问题,TaskMoE模块通过“动态专家路由”与“解耦门控”实现任务专属特征提取:
跨模态专家路由:不依赖单一任务ID,而是融合语言指令与场景视觉信息,通过交叉注意力与FiLM层生成上下文感知特征,动态选择适配当前任务的专家编码器; 解耦门控机制:设置少于任务数量的门控(实验中8个门控对应18项任务),让语义相似任务(如“打开底层抽屉”与“将物品放入底层抽屉”)共享门控以实现参数复用,语义差异任务则使用独立门控,避免特征纠缠; 稀疏激活:每个任务仅激活Top-2专家,在保证特征特异性的同时降低计算成本,提升模型效率。
3. 三阶段训练策略:实现“感知-动作”端到端协同
TAVP采用分阶段训练确保模块协同与性能稳定:
固定视角预训练:使用前视、左肩、顶视三个固定视角训练基础模型,优化热力图定位、机械臂旋转、夹爪状态等损失,为后续模块提供基础参数; MVEP策略优化:冻结基础模型,通过PPO算法训练MVEP,利用伪环境交互与三重奖励函数优化视角选择策略; 全模型微调:固定MVEP,微调TaskMoE与动作预测网络,确保视角探索与动作生成的适配性,最终实现“看到(动态视角)-理解(任务特征)-行动(精准动作)”的闭环。
三、实验验证:18项RLBench任务性能超越,泛化与效率兼顾
研究团队在RLBench基准测试的18项多任务操控场景(涵盖“关罐子”“插钉子”“整理餐具”等)中开展全面实验,验证TAVP的性能优势:
1. 主任务性能:平均成功率超现有基线, occlusion任务提升显著

对比RVT2、ARP、ARP+等固定视角基线模型,TAVP在18项任务中平均成功率达到86.6%;在易受遮挡的任务中表现尤为突出。
2. 消融实验:核心模块不可或缺
通过消融实验验证各模块的必要性,如下表所示:
移除TaskMoE后,平均成功率降至85.6%,证明任务感知编码对多任务泛化的重要性; 用随机视角替代MVEP后,平均成功率骤降至8.9%,凸显动态视角规划是性能提升的关键。

3.泛化与效率分析:zero-shot能力提升,推理成本可控

zero-shot泛化:在未训练的“打开抽屉”任务中,TAVP成功率达12.0%,而无TaskMoE的模型成功率为0,证明TaskMoE能将已知任务知识迁移到新任务; 效率平衡:尽管动态视角重渲染增加了计算成本,但TAVP平均推理时间仅0.436秒,较ARP+(0.394秒)仅增加10.7%,通过采样加速与摄像头缓存实现性能与效率的平衡。
4.真实世界鲁棒性测试:诸多场景超越基准模型
在“采摘葡萄”的鲁棒性测试中,严重遮挡被确认为导致系统失败的主要原因。我们在每类实验中报告了10 trails的成功率。

实验结果显示,TAVP方法的整体适应能力显著优于DP方法。在已见场景下,两者表现接近;但当面对未知背景、物体,TAVP的成功率远高于DP。
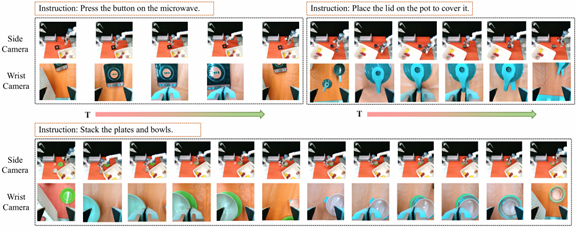
此外,研究团队在真实机器人平台(Dobot Nova2)上验证了TAVP的实用性,在“堆叠碗碟”“抓取葡萄”“按压按钮”等多项任务中均实现稳定执行,显著超越Diffusion Policy,进一步证明其在真实场景的适配性。下表展示了其中5项任务与DP比较的定量结果,在每类任务中报告了10 trails的成功率。下图展示了部分真实机器人执行过程的可视化结果,表现出一定的鲁棒性和泛化性。

四、研究意义与未来方向
TAVP框架的提出为机器人多任务操控提供了新范式:通过动态视角规划突破3D感知局限,通过任务感知编码消除多任务干扰,首次实现“任务引导视角选择”与“视角适配动作预测”的协同优化。该成果不仅在RLBench基准测试中刷新性能,更为家庭服务机器人、工业协作机器人等复杂场景应用提供了技术支撑。
研究团队表示,未来将进一步优化两方面:一是降低反光/透明物体对全局点云重建的影响,提升真实场景鲁棒性;二是探索多传感器融合(如触觉、力觉),进一步扩展机器人操控的任务边界。目前,研究团队已开源项目与视觉结果,为机器人学习领域提供可复用的技术工具。











