来源:3D视觉工坊
0. 这篇文章干了啥?
这篇文章提出了HGACNet,一种用于跨模态点云补全的分层图注意力网络,旨在解决因自遮挡和传感器限制导致的点云不完整问题,提升下游任务的可靠性。该框架通过分层编码3D几何特征并与单视图RGB图像的先验信息融合,重建单个对象的完整点云。核心组件包括Hierarchical Graph Attention (HGA)编码器和Multi-Scale Cross-Modal Fusion (MSCF)模块,前者通过基于图注意力的下采样自适应选择关键局部点并逐步细化分层几何特征,后者执行基于注意力的特征对齐,实现细粒度的语义指导。此外,文章还提出了对比损失(C-Loss),以明确对齐跨模态的特征分布,提高在模态差异下的补全保真度。在ShapeNet-ViPC基准和YCB-Complete数据集上的大量实验证实了HGACNet的有效性,展示了其在真实世界机器人操作任务中的优越性能和强大适用性。未来工作计划提高跨模态融合的适应性,并探索无监督训练策略以减少对合成或全标注数据的依赖。
下面一起来阅读一下这项工作~
1. 论文信息
-
论文题目:HGACNet: Hierarchical Graph Attention Network for Cross-Modal Point Cloud Completion -
作者:Yadan Zeng, Jiadong Zhou, Xiaohan Li, I-Ming Chen -
作者机构:Y. Zeng, J. Zhou and I-M. Chen来自Nanyang Technological University, Singapore;X. Li来自Xi’an University of Architecture and Technology, Xi’an, China -
论文链接:https://arxiv.org/pdf/2509.13692
2. 摘要
点云补全对于机器人感知、物体重建以及支持抓取规划、避障和操作等下游任务至关重要。然而,由于自遮挡和传感器限制导致的几何信息不完整,会显著降低下游推理和交互的效果。为应对这些挑战,我们提出了HGACNet,这是一个新颖的框架,通过对三维几何特征进行分层编码,并将其与单视角RGB图像中的图像引导先验信息相融合,来重建单个物体的完整点云。我们方法的核心是分层图注意力(HGA)编码器,它通过基于图注意力的下采样自适应地选择关键局部点,并逐步细化分层几何特征,以更好地捕捉结构连续性和空间关系。为了加强跨模态交互,我们进一步设计了多尺度跨模态融合(MSCF)模块,该模块在分层几何特征和结构化视觉表示之间进行基于注意力的特征对齐,为点云补全提供细粒度的语义引导。此外,我们提出了对比损失(C-Loss),以明确对齐跨模态的特征分布,提高在模态差异下的补全保真度。最后,在ShapeNet-ViPC基准数据集和YCB-Complete数据集上进行的大量实验证实了HGACNet的有效性,展示了其达到了当前最优性能,以及在现实世界机器人操作任务中的强大适用性。

3. 效果展示
图 5. 在 ShapeNet-ViPC 数据集上的定性比较。每一行展示一个样本,包括 RGB 图像、部分输入,以及来自 XMFNet、EGIINet 和我们的 HGACNet 的补全结果,最后是真实值。HGACNet 比基线方法重建出更逼真、更详细的形状,尤其是在薄且结构复杂的区域表现出色。关键细节被放大以便比较。
 图 6. 在 YCB-Complete 数据集上的定性比较。HGACNet 通过生成更完整、更详细的重建结果,优于 XMF 和 EGIINet。突出显示的区域展示了其在处理噪声、遮挡和未见物体方面的优势。
图 6. 在 YCB-Complete 数据集上的定性比较。HGACNet 通过生成更完整、更详细的重建结果,优于 XMF 和 EGIINet。突出显示的区域展示了其在处理噪声、遮挡和未见物体方面的优势。
4. 主要贡献
-
我们提出了HGACNet,这是一个分层的跨模态框架,它将分层图注意力编码与多尺度跨模态融合相结合,有效利用点云几何信息和图像先验知识实现高保真补全。 -
我们设计了一个HGA编码器,它能自适应地选择关键局部点并细化几何特征,以保留结构连续性和细粒度细节。 -
我们开发了一个MSCF模块,它能够实现几何表示和视觉表示之间的实例级对齐,并辅以我们提出的C-Loss来减少模态差异,提高重建精度。
5. 基本原理是啥?
1. HGACNet整体框架
HGACNet是一种跨模态点云补全框架,其目标是根据部分点云 和对应的单视图RGB图像 ,准确预测出完整的点云 。该框架主要由分层图注意力(HGA)编码器和多尺度跨模态融合(MSCF)模块两个核心组件构成。HGA编码器对3D几何特征进行分层编码,Swin Transformer提取图像特征,MSCF模块将分层的点云特征与图像特征融合,同时使用对比损失(C-Loss)增强跨模态一致性,最后通过解码器重建出完整的点云。
2. 分层编码器(Hierarchical Encoder)
- 使用HGA进行点云编码
-
GD模块:该模块通过将原始点云特征转换为丰富的结构化表示来编码局部几何结构。对于输入点云 ,首先使用共享多层感知机(MLP)生成点特征 ,然后为每个点 构建局部图,连接其 个最近邻点,计算点 与其邻居 之间的边特征 ,其中 和 分别是 和 的特征, 是可学习函数。接着使用基于图的卷积管道处理编码后的边,包括2D卷积层扩展局部感受野、组归一化(GroupNorm)稳定训练、LeakyReLU激活引入非线性,最后通过最大池化聚合局部邻域信息,得到紧凑的特征嵌入。 -
GAD模块:采用基于图注意力的下采样策略自适应地选择关键点并保留结构细节。该模块根据注意力权重为每个节点分配重要性得分 ,其中 是可学习的评分函数,选择得分最高的点形成下采样后的点云。此过程分层进行,先将点集减少到512个节点,再减少到128个节点。为增强空间感知,将位置编码纳入所选特征,即 ,其中 是正弦编码函数, 表示通道级拼接。最后,将不同层次得到的特征通过独立的特征投影模块投影到统一的潜在空间,得到保留细粒度几何细节的局部特征集 和捕获高层语义结构的全局特征集 。
- 使用Swin Transformer进行图像编码
使用预训练且冻结的Swin Transformer作为图像编码器,因其能够在保留局部空间结构的同时建模长距离依赖关系。Swin Transformer的分层设计与点云编码器自然对齐,通过基于窗口的自注意力和移位窗口机制捕获多尺度视觉特征,有助于在跨模态融合过程中实现2D全局上下文与3D结构信息的有效对齐。
3. 多尺度跨模态融合(Multi-scale Cross-Modal Fusion)
- 跨模态交叉注意力融合
设计了一种分层跨模态融合策略,联合利用多尺度的几何和视觉特征。将HGA编码器提取的全局点云特征 和局部点云特征 以及Swin Transformer提取的图像特征 通过线性变换投影到统一的潜在空间,即 , , ,其中 是可学习的变换函数。然后进行多种注意力操作:在 和 内应用自注意力建模模态内依赖关系,得到 和 ;在 和 之间进行交叉注意力,使全局和局部特征相互细化,得到 ;在点云特征 与视觉特征 之间进行跨模态注意力,分别生成 和 。每个注意力操作定义为 , ,其中 、 和 是从各自特征集投影得到的查询、键和值。最后将融合后的特征集 拼接后传递给解码器进行点云重建。
- 用于跨模态对齐的对比学习
提出C-Loss来对齐点云和图像的全局特征表示。对于一批点云的全局特征 和对应的图像全局特征 ,使用基于InfoNCE的公式鼓励每个点云特征与其配对的图像特征尽可能相似,同时与批次中的其他样本不同:
其中 表示特征向量之间的余弦相似度, 是温度缩放因子。
4. 解码器(Decoder)
采用与XMFNet类似的解码器架构,将融合后的特征直接传递给解码器以预测完整的点云。解码器估计出一组密集的点来近似缺失区域,然后使用最远点采样(FPS)将其与输入的部分点云的子采样版本拼接,确保网络既能保留观察到的几何形状,又能推断出结构,保证全局完整性和局部细节。推荐课程:。
5. 损失函数(Loss Function)
-
使用带 范数的Chamfer距离(L2CD)和C-Loss两个关键损失函数。L2CD定义为: 用于惩罚预测点云和真实点云之间的逐点差异,确保双向对齐。 -
最终损失函数为: 其中 和 平衡CD和C-Loss的影响。在实验中,设置 和 ,以在重建精度和跨模态一致性之间取得良好的平衡。



6. 实验结果
文章围绕HGACNet在点云补全任务上开展了多项实验,以验证其有效性和优越性,具体实验结果如下:
1. ShapeNet-ViPC数据集实验结果
- 定量对比
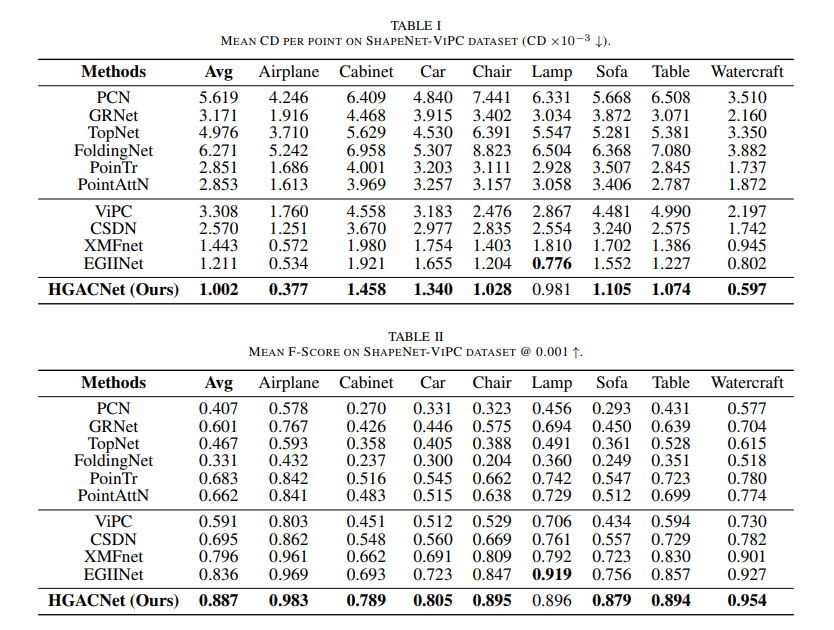
在L2-CD和F1-score指标上与现有跨模态点云补全方法对比,HGACNet平均L2-CD比EGIINet降低17%,比XMFNet降低31%;F1-score表现也更优,如平均达到0.887,远高于其他对比方法。
- 定性对比
与XMFNet和EGIINet相比,HGACNet能重建更精细的结构细节,如飞机尾翼、橱柜抽屉等,其他方法常产生不完整或扭曲形状。
2. 消融实验结果
- 局部特征提取
移除局部特征提取模块后性能明显下降,尤其在重建精细结构方面,表明局部信号对捕捉详细几何形状和提高预测完整性有重要作用。
- MSCF模块
用简单特征拼接策略替代MSCF模块,各类别性能显著下降,如飞机L2-CD增加67%,汽车增加21%,验证了基于注意力的特征交互对捕捉跨模態对应关系和提高结构完整性的必要性。
- C-Loss
移除C-Loss后性能持续下降,在复杂形状物体上更明显,说明C-Loss能有效减少模态差距,促进特征对应,使补全更准确连贯。
- 图像输入
排除图像输入后性能显著下降,表明图像先验能显著增强模型对部分扫描的补全能力,尤其在复杂或细长结构类别上。
3. YCB-Complete数据集实验结果
- 定量结果
HGACNet在已知和未知类别上均优于XMFNet和EGIINet,在已知类别上表现更突出,虽未知类别CD值较高,但仍有较强泛化能力,无需微调就超过先前方法。
- 定性结果
HGACNet能实现更准确完整的重建,在精细结构和物体边界处理上表现出色,在未见类别上能更好保留全局形状。


7. 总结 & 未来工作
总结
我们提出了HGACNet,这是一个用于点云补全的分层跨模态框架,它将点云中的几何结构与图像中的视觉先验信息相结合。所提出的HGA编码器使用基于图注意力的下采样方法来自适应地选择具有代表性的关键点,从而捕捉全局上下文和局部几何细节。为了实现有效的跨模态对齐,MSCF模块应用交叉注意力机制来融合图像和点云特征,而所提出的C损失函数则通过缩小模态间的特征差距进一步增强了一致性。
在ShapeNet-ViPC基准测试上进行的大量实验表明,HGACNet达到了当前的最优性能,验证了其分层编码和多尺度融合策略的有效性。消融实验证实了每个核心组件的贡献,包括特征提取、跨模态融合和对比学习。
为了评估其在现实世界中的适用性,我们构建了基于YCB-Video数据集的YCB-Complete基准测试,该测试包含传感器噪声和遮挡问题。HGACNet在这些条件下仍保持了较强的性能,凸显了其在诸如物体抓取、姿态估计和场景交互等机器人任务中的潜力。
未来展望
在未来的工作中,我们计划提高跨模态融合的适应性,以更好地处理各种不同的场景,并探索无监督训练策略,以减少对合成数据或全标注数据的依赖。










