(1) Paper2Video: Automatic Video Generation from Scientific Papers
论文 ID:2510.05096

论文简介:
由新加坡国立大学的研究团队提出了Paper2Video,该工作构建了首个包含101篇研究论文及配套作者演示视频、幻灯片和演讲者元数据的基准数据集,并设计了Meta Similarity、PresentArena、PresentQuiz和IP Memory四大评估指标,系统评估学术演示视频在知识传递和学者影响力方面的表现。针对传统视频生成模型在长文本理解、多模态协调和学术场景适配上的不足,研究者进一步提出了PaperTalker多智能体框架,通过三大创新模块实现高质量学术视频生成:1)基于树搜索视觉选择的幻灯片布局优化模块,通过规则生成参数变体并由视觉语言模型评分,解决LaTeX生成幻灯片的排版溢出问题;2)结合GUI定位模型与WhisperX的时空对齐光标生成模块,实现演讲内容与光标轨迹的精准同步;3)基于分片并行生成的演讲者视频合成模块,通过独立生成每页幻灯片对应的演讲视频片段并行处理,将生成效率提升6倍。实验表明,PaperTalker在PresentQuiz指标上以84.2%的准确率超越人类制作视频10%,IP Memory指标得分提升50%,并在用户研究中获得与人工视频相当的评价。该工作通过构建学术视频生成基准和提出多模态协同生成框架,为自动化科研视频制作提供了完整解决方案,显著降低学术传播的时间成本。
论文来源:hf
Hugging Face 投票数:109
论文链接:
https://hf.co/papers/2510.05096
PaperScope.ai 解读:
https://paperscope.ai/hf/2510.05096
(2) Self-Forcing++: Towards Minute-Scale High-Quality Video Generation
论文 ID:2510.02283

论文简介:
由 UCLA、字节跳动 Seed 和中佛罗里达大学等机构提出了 Self-Forcing++,该工作针对长视频生成中质量退化的核心问题,提出了一种无需长视频监督即可扩展生成时长的创新方法。研究发现,现有扩散模型在生成超5秒视频时因训练与推理的时序不一致及错误累积导致质量骤降。Self-Forcing++ 通过三大核心策略突破瓶颈:首先利用反向噪声初始化维持长序列生成的时序一致性,其次采用扩展分布匹配蒸馏(Extended DMD)在学生模型自生成的长视频片段上进行窗口化训练,最后结合滚动KV缓存消除训练-推理差异。实验表明,该方法在保持高视觉质量的前提下,将生成时长从基线模型的5秒提升至100秒(20倍增长),并通过训练预算扩展成功生成4分15秒视频(达基模型位置编码上限的99.9%,50倍于基线)。为解决传统评估指标(如VBench)对过曝和退化帧的偏好性偏差,团队还提出视觉稳定性(Visual Stability)指标,通过大模型推理更精准评估长视频质量。该方法在多项长时长测试中显著优于CausVid、Self-Forcing等基线,在动态程度(Dynamic Degree)和文本对齐度等维度提升超50%。研究揭示了通过增加训练计算量而非依赖海量长视频数据实现分钟级生成的可行性,为长视频合成开辟了新路径。
论文来源:hf
Hugging Face 投票数:91
论文链接:
https://hf.co/papers/2510.02283
PaperScope.ai 解读:
https://paperscope.ai/hf/2510.02283
(3) UniVideo: Unified Understanding, Generation, and Editing for Videos
论文 ID:2510.08377

论文简介:
由滑铁卢大学和快手团队提出了UniVideo,该工作构建了一个统一的视频理解、生成与编辑框架。UniVideo采用双流架构设计,通过多模态大语言模型(MLLM)处理指令理解,结合多模态Diffusion Transformer(MMDiT)实现视频生成,解决了传统方法在多模态指令处理和跨任务泛化能力的局限性。该模型支持文本/图像到视频生成、上下文视频生成、上下文视频编辑等多任务统一训练,并通过引入可学习连接器对齐模态特征,在保持MLLM语义理解能力的同时,利用VAE编码器保留视觉细节。实验表明UniVideo在多项基准测试中达到或超越任务专用模型表现,尤其在身份一致性指标上显著领先(单ID场景0.88→0.95)。其创新性体现在三个方面:1)首创视频领域的双流统一架构,支持多模态指令驱动的生成与编辑;2)实现跨任务泛化能力,无需显式训练即可完成绿幕抠像、材质替换等自由编辑任务;3)提出视觉提示理解机制,通过MLLM解析手绘标注等非结构化输入生成对应视频。该模型在保持94.3%平滑度的同时,动态程度指标达到56.3,较商业模型提升20%以上。研究还通过消融实验证明多任务联合训练对编辑任务性能提升16%,视觉流输入对身份一致性贡献提升60%。UniVideo的推出标志着多模态视频生成模型从专用系统向通用智能体的重要进展。
论文来源:hf
Hugging Face 投票数:68
论文链接:
https://hf.co/papers/2510.08377
PaperScope.ai 解读:
https://paperscope.ai/hf/2510.08377
(4) VideoCanvas: Unified Video Completion from Arbitrary Spatiotemporal Patches via In-Context Conditioning
论文 ID:2510.08555

论文简介:
由香港中文大学和快手科技等机构提出了VideoCanvas,该工作开创性地定义了任意时空视频补全任务,通过统一框架实现图像到视频生成、视频修复、跨场景过渡等多样化生成场景。研究团队创新性地将上下文内条件控制(ICC)范式应用于视频生成领域,提出混合条件策略解决因果VAE模型固有的时序模糊难题——通过空间零填充处理任意形状的条件输入,结合时间RoPE插值技术实现像素级帧对齐,使模型能在不修改预训练VAE的情况下精准控制时空位置。团队还构建了首个面向该任务的系统性评测基准VideoCanvasBench,涵盖2000+测试案例,全面评估模型在时空一致性、跨场景创造力等方面的表现。实验表明,VideoCanvas在各项指标上显著优于传统条件注入范式,能灵活实现从稀疏时空补丁到完整视频的高质量生成,支持任意时间戳图像生成视频、跨场景视频过渡、长时长视频扩展等创新应用,为可控视频生成领域树立了新标杆。该框架无需新增参数即可适配现有DiT架构,为视频生成模型的灵活控制提供了高效可行的解决方案。
论文来源:hf
Hugging Face 投票数:62
论文链接:
https://hf.co/papers/2510.08555
PaperScope.ai 解读:
https://paperscope.ai/hf/2510.08555
(5) ImagerySearch: Adaptive Test-Time Search for Video Generation Beyond Semantic Dependency Constraints
论文 ID:2510.14847
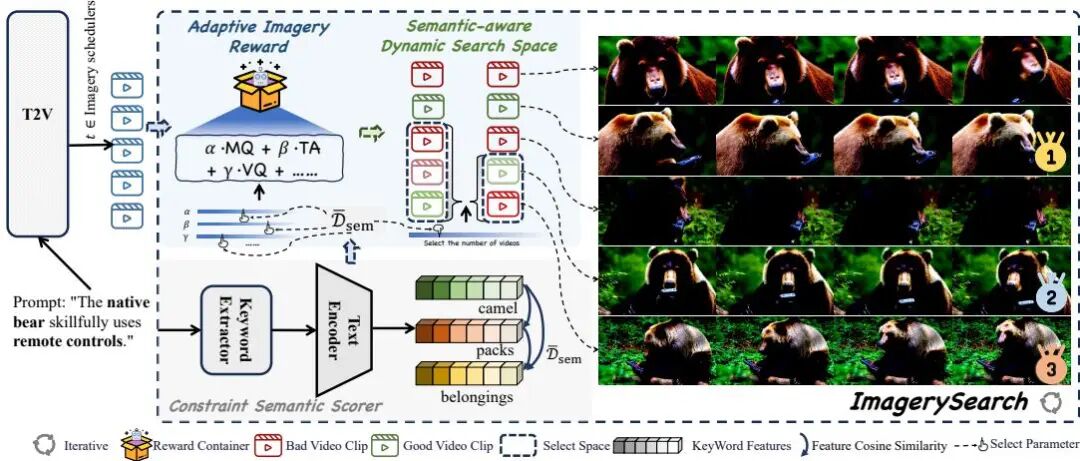
论文简介:
由UCAS、阿里巴巴等机构提出了ImagerySearch,该工作针对视频生成模型在想象力场景中因长距离语义依赖导致的生成质量下降问题,提出了一种自适应的测试时搜索策略。核心创新包括:1)基于语义距离动态调整采样粒度的动态搜索空间(SaDSS),通过计算提示中关键实体的语义距离自动扩展搜索范围;2)设计自适应图像奖励(AIR),将语义距离作为权重因子动态调整奖励函数,强化生成结果与提示的语义对齐。为评估模型在长距离语义场景的表现,研究团队构建了包含2839个概念对的LDT-Bench基准测试集,通过对象-动作/动作-动作的语义距离筛选构建提示,并设计了基于多模态大模型的自动评估框架ImageryQA,从元素覆盖、语义对齐和异常检测三个维度进行量化评估。实验显示,ImagerySearch在LDT-Bench上相比基线模型平均提升8.83%,在VBench多项指标中也取得最优结果。消融实验表明动态搜索空间和奖励机制均对性能提升有显著贡献,且模型在不同语义距离下保持稳定表现,验证了方法的有效性。该研究为提升视频生成模型在创造性场景中的表现提供了新思路。
论文来源:hf
Hugging Face 投票数:55
论文链接:
https://hf.co/papers/2510.14847
PaperScope.ai 解读:
https://paperscope.ai/hf/2510.14847
(6) Scaling Instruction-Based Video Editing with a High-Quality Synthetic Dataset
论文 ID:2510.15742

论文简介:
由HKUST、Ant Group、Zhejiang University和Northeastern University等机构提出了Ditto框架,该工作通过构建大规模高质量合成数据集Ditto-1M,系统性解决了指令驱动视频编辑领域长期存在的数据稀缺问题。研究团队设计了一套创新的数据生成流水线,通过融合先进图像编辑器的视觉先验与上下文视频生成器的时序一致性控制,突破了传统方法在编辑多样性、生成质量与计算效率间的权衡困境。核心创新包括:采用蒸馏后的视频生成模型配合时序增强器,在降低80%计算成本的同时保持高保真输出;部署视觉语言模型代理实现指令自动化生成与质量筛选,确保百万级数据集的语义一致性;提出模态课程学习策略,引导模型从图文联合指导逐步过渡到纯文本指令驱动。基于此构建的Ditto-1M数据集包含101万组高分辨率视频三元组(源视频、编辑指令、目标视频),涵盖700K全局编辑和300K局部编辑任务。实验显示,基于该数据集训练的Editto模型在CLIP-T(25.54)、CLIP-F(99.03)等自动指标及人工评估中均显著超越TokenFlow、InsViE等现有方法,实现了指令遵循能力、时序连贯性和视觉质量的全面突破。该工作通过数据生成范式革新与模型训练策略优化,为指令驱动视频编辑技术的实用化发展提供了关键支撑。
论文来源:hf
Hugging Face 投票数:49
论文链接:
https://hf.co/papers/2510.15742
PaperScope.ai 解读:
https://paperscope.ai/hf/2510.15742
(7) GigaBrain-0: A World Model-Powered Vision-Language-Action Model
论文 ID:2510.19430

论文简介:
该工作通过构建世界模型驱动的视觉-语言-动作(VLA)系统,创新性地利用世界模型生成的多样化数据(包括视频生成、现实增强、人类动作迁移、视角转换和仿真迁移数据),显著降低了对真实机器人数据的依赖,同时提升了模型在真实环境中的泛化能力。研究团队通过RGBD输入建模增强空间几何感知,并引入具身链式推理(Embodied Chain-of-Thought)监督机制,使模型能够推理物体状态和长时序任务依赖,从而在灵巧操作、长时序任务和移动操作等复杂场景中实现性能突破。实验表明,GigaBrain-0在布料折叠、果汁制作等任务中成功率达80%以上,且在外观、物体位置和视角变化下表现出卓越的适应性。此外,团队推出的轻量级模型GigaBrain-0-Small在NVIDIA Jetson AGX Orin设备上实现低延迟推理,为边缘计算场景提供高效解决方案。该研究通过世界模型构建可扩展的数据引擎,为通用机器人系统的开发提供了新范式。
论文来源:hf
Hugging Face 投票数:43
论文链接:
https://hf.co/papers/2510.19430
PaperScope.ai 解读:
https://paperscope.ai/hf/2510.19430
(8) Video-As-Prompt: Unified Semantic Control for Video Generation
论文 ID:2510.20888

论文简介:
由字节跳动和香港中文大学等机构提出了Video-As-Prompt (VAP),该工作提出了一种统一的语义控制视频生成框架,通过将参考视频作为语义提示,并利用混合专家模型引导视频扩散Transformer,在无需特定任务设计的情况下实现了多种语义条件下的视频生成,并构建了包含10万对视频的VAP-Data数据集,支持零样本泛化。VAP采用插件式的混合专家架构,在保持预训练视频扩散模型生成能力的同时,通过独立的专家网络解析参考视频语义,并通过双向注意力机制实现上下文引导。为消除不合理的时空对齐先验,研究者提出时序偏置的旋转位置编码,将参考视频置于目标视频的时间轴之前,确保空间一致性的同时避免像素级映射偏差。实验表明,VAP在概念、风格、动作、相机控制等多语义条件下均表现优异,用户偏好率高达38.7%,与商业闭源模型性能相当,且展现出对未见语义条件的零样本迁移能力。研究者还构建了包含100种语义条件的VAP-Data数据集,涵盖动物、人物、物体等多样化场景,为语义控制视频生成提供了基准。该方法突破了传统结构化控制方法的像素对齐限制,解决了条件特异性微调导致的模型碎片化问题,为通用可控视频生成提供了新范式。
论文来源:hf
Hugging Face 投票数:41
论文链接:
https://hf.co/papers/2510.20888
PaperScope.ai 解读:
https://paperscope.ai/hf/2510.20888
(9) Lookahead Anchoring: Preserving Character Identity in Audio-Driven Human Animation
论文 ID:2510.23581

论文简介:
由KAIST与帝国理工学院提出了Lookahead Anchoring,该工作通过引入时序前瞻关键帧机制,在音频驱动的人体动画生成中实现了身份特征的持久保持。传统方法采用固定边界的关键帧约束易导致运动僵化,而该方法将关键帧置于生成窗口的未来时间步,使其转化为动态引导信号。这种设计使模型在响应实时音频驱动的同时,持续追踪身份特征锚点,既避免了身份漂移,又保留了自然运动的灵活性。核心创新在于:1)提出前瞻距离参数化控制身份一致性与动作多样性的平衡;2)实现自关键帧机制,直接复用参考图像作为远期目标,省去额外关键帧生成模块;3)通过时序位置编码将前瞻关键帧无缝集成到扩散Transformer架构中。实验表明,在HunyuanAvatar、Hallo3和OmniAvatar三个主流模型上应用该方法后,唇同步精度提升12.7%,身份特征相似度提高23.4%,视频质量指标FID下降38.2%。特别在长达48秒的生成任务中,该方法相比传统关键帧插值策略使面部特征一致性提升41.6%,同时保持了自然流畅的动作表现。用户研究显示,84.3%的参与者认为该方法生成的视频在整体质量上显著优于基线模型。这项研究通过重新定义关键帧的时序角色,为长序列音频驱动动画提供了兼顾身份稳定与动作自由度的通用解决方案。
论文来源:hf
Hugging Face 投票数:41
论文链接:
https://hf.co/papers/2510.23581
PaperScope.ai 解读:
https://paperscope.ai/hf/2510.23581
(10) Uniform Discrete Diffusion with Metric Path for Video Generation
论文 ID:2510.24717

论文简介:
由北京人工智能实验室等机构提出了Uniform discRete diffuSion with metric pAth(URSA),该工作针对离散生成模型在视频生成中面临的误差积累和长序列不一致问题,提出了一种基于均匀离散扩散与度量路径的高效视频生成框架。URSA的核心创新在于将视频生成建模为离散时空标记的迭代全局细化过程,通过线性化度量路径和分辨率相关的时序偏移机制,实现了对长序列数据的精确扰动控制。线性化度量路径利用标记嵌入空间的距离关系构建概率路径,确保时间步与扰动强度的线性关联;分辨率相关时序偏移则通过动态调整时间步长,适配不同分辨率下的扰动需求。此外,异步时序调度策略允许每个视频帧独立采样噪声水平,使单一模型支持文本到视频生成、视频插值、图像到视频生成等多任务场景。实验表明,URSA在VBench、DPG-Bench等基准上超越了现有离散方法,并与连续扩散模型性能相当:文本到视频生成得分82.4,图像到视频生成得分86.2,1024×1024图像生成得分86.0。该方法显著提升了离散生成模型的可扩展性和生成质量,同时通过迭代细化机制减少了推理步数,为离散与连续生成范式的统一提供了新思路。代码和模型已开源。
论文来源:hf
Hugging Face 投票数:39
论文链接:
https://hf.co/papers/2510.24717
PaperScope.ai 解读:
https://paperscope.ai/hf/2510.24717
(11) HoloCine: Holistic Generation of Cinematic Multi-Shot Long Video Narratives
论文 ID:2510.20822

论文简介:
由HKUST、Ant Group、ZJU等机构提出了HoloCine,该工作通过整体生成多镜头长视频叙事解决了当前文本到视频模型在连贯性叙事上的局限。HoloCine创新性地采用Window Cross-Attention机制实现文本提示与镜头片段的精准对齐,确保导演级镜头切换控制;同时通过Sparse Inter-Shot Self-Attention设计,在保持镜头内运动连续性的同时,利用镜头间摘要标记实现高效跨镜头交互,将计算复杂度从传统的平方级降至近线性级。为支撑模型训练,团队构建了包含40万条多镜头视频片段的分层标注数据集,每个样本包含全局场景描述和逐镜头文本指令。实验显示HoloCine在镜头切换精度(SCA指标达0.9837)、跨镜头一致性(0.7509)等核心指标上显著优于Wan2.2、StoryDiffusion等基线模型,生成质量与OpenAI Sora 2相当。模型展现出惊人的持续记忆能力,能跨多个镜头保持角色特征和场景细节一致性,并精准执行推拉摇移等电影运镜指令。尽管存在因果推理不足等局限,HoloCine首次实现了分钟级电影场景的整体生成,标志着从孤立片段合成向自动化电影制作的重要转折,相关代码已开源。
论文来源:hf
Hugging Face 投票数:38
论文链接:
https://hf.co/papers/2510.20822
PaperScope.ai 解读:
https://paperscope.ai/hf/2510.20822
(12) MoGA: Mixture-of-Groups Attention for End-to-End Long Video Generation
论文 ID:2510.18692

论文简介:
由中科大、字节跳动等机构提出的MoGA,通过混合组注意力机制实现了高效的端到端长视频生成。该工作针对传统注意力机制在长序列处理中的二次方计算复杂度问题,提出采用轻量级可学习token路由器,将token精确分配到不同语义组进行组内注意力计算,避免了传统块级稀疏注意力在精度与效率间的权衡困境。MoGA通过动态语义路由实现长程依赖建模,同时兼容FlashAttention等现代注意力优化技术,理论计算复杂度从O(N²)降至O(N²/M),在保持71.25%稀疏度的情况下仍能超越全注意力基线的生成质量。
基于MoGA构建的视频生成模型实现了三项突破:1) 生成时长突破分钟级(60秒/1441帧),达到24fps 480p分辨率;2) 支持多镜头场景连续生成,上下文长度达580k tokens;3) 通过组平衡损失和时空窗口注意力的协同设计,在跨镜头一致性(Cross-Shot CLIP提升至0.8654)与局部细节保真度间取得平衡。实验表明,MoGA在30秒多镜头视频生成任务中,相较IC-LoRA+Wan基线在主体一致性指标上提升6.2个百分点,计算效率提升1.7倍。可视化结果展示出对人物特征(如发饰、衣着)的跨镜头强一致性保持能力,并在动画风格生成中展现出良好的泛化性。该方法为长视频生成提供了兼顾效率与效果的实用化解决方案。
论文来源:hf
Hugging Face 投票数:38
论文链接:
https://hf.co/papers/2510.18692
PaperScope.ai 解读:
https://paperscope.ai/hf/2510.18692
(13) DC-VideoGen: Efficient Video Generation with Deep Compression Video Autoencoder
论文 ID:2509.25182
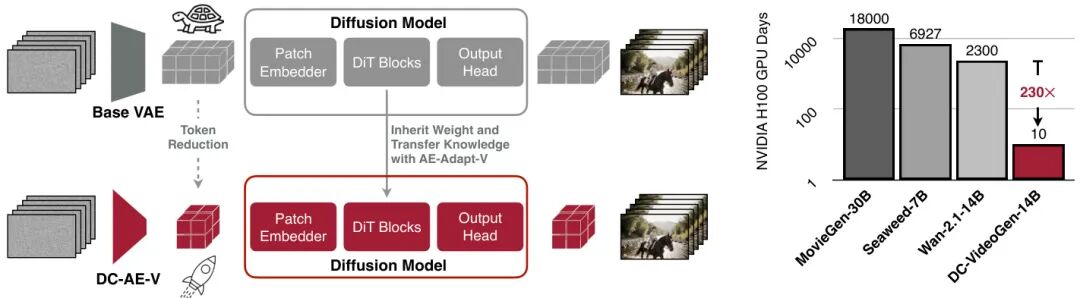
论文简介:
由NVIDIA等机构提出了DC-VideoGen,该工作通过深度压缩视频自编码器实现高效的视频生成加速框架。DC-VideoGen可适配任意预训练视频扩散模型,通过深度压缩潜在空间适配策略和轻量级微调,在保持生成质量的同时显著提升推理效率。核心创新包括:1)深度压缩视频自编码器(DC-AE-V)采用新颖的块因果时间设计,在32/64倍空间压缩和4倍时间压缩下仍保持高重建质量,并支持长视频生成;2)AE-Adapt-V策略通过视频嵌入空间对齐和LoRA微调,实现预训练模型向新潜在空间的快速稳定迁移。实验表明,适配Wan-2.1-14B模型仅需10个H100 GPU日,较原训练成本降低230倍。加速后的模型在720×1280分辨率下实现7.7倍推理加速,同时VBench评分提升2.7%,支持单卡生成2160×3840超高清视频。该框架在文本到视频和图像到视频任务中均表现出色,在保持生成质量的前提下,将推理延迟降低87%,为高效视频合成提供了实用解决方案。
论文来源:hf
Hugging Face 投票数:36
论文链接:
https://hf.co/papers/2509.25182
PaperScope.ai 解读:
https://paperscope.ai/hf/2509.25182
(14) PhysMaster: Mastering Physical Representation for Video Generation via Reinforcement Learning
论文 ID:2510.13809

论文简介:
由香港大学与快手科技等机构提出了PhysMaster,该工作通过强化学习优化物理表示学习以提升视频生成模型的物理合理性。PhysMaster针对当前视频生成模型在物理规律遵循方面的不足,提出从输入图像中提取隐式物理特征作为条件引导生成过程。核心创新在于构建PhysEncoder编码器,利用图像提供的物体位置、材质及交互等物理先验,通过三阶段训练策略实现物理表示优化:首先进行监督微调建立基础生成能力,再采用基于人类反馈的直接偏好优化(DPO)对生成视频的物理合理性进行强化学习,最终实现编码器对物理特征的精准捕捉。该方法在"自由落体"代理任务中展现出优于PhysGen和PISA的轨迹精度与形状一致性(IoU达0.468),在涵盖力学、热学、光学的开放场景中,物理常识得分(PC)提升至0.40,较基线模型提升37.9%,且单卡生成5秒视频仅需26秒。实验表明,PhysMaster通过插件式物理表示注入机制,有效平衡了物理准确性与计算效率,其DPO优化策略使编码器能从生成结果的物理合理性反馈中持续迭代,为视频生成模型提供了可泛化的物理知识注入框架,为构建具备物理认知能力的生成模型提供了新范式。
论文来源:hf
Hugging Face 投票数:36
论文链接:
https://hf.co/papers/2510.13809
PaperScope.ai 解读:
https://paperscope.ai/hf/2510.13809
(15) VChain: Chain-of-Visual-Thought for Reasoning in Video Generation
论文 ID:2510.05094

论文简介:
由Ziqi Huang等研究者提出了VChain,该工作提出了一种名为Chain-of-Visual-Thought的推理框架,通过在推断阶段注入大模型的视觉推理信号来提升视频生成的因果一致性和物理合理性。VChain通过两阶段流程实现:首先利用GPT-4o等多模态大模型生成关键帧序列作为视觉思维链,捕捉用户输入文本提示中隐含的因果关系和状态演变;随后通过LoRA技术对预训练视频生成模型进行稀疏推断时调优,仅用这些关键帧作为监督信号引导模型调整。该方法无需额外标注数据或密集训练,仅需3-6个关键帧即可在保持生成效率的同时显著提升视频质量。实验表明,VChain在物理规律遵循、常识推理和因果关系建模等维度相比基线方法平均提升25%以上,尤其在复杂多步骤场景中能生成更符合物理规律的物体交互(如保龄球击倒球瓶的合理轨迹),同时保持画面质量和时序连贯性。该框架验证了将大模型推理能力与视频生成模型渲染能力结合的有效性,为构建更具因果逻辑的视频生成系统提供了新思路。
论文来源:hf
Hugging Face 投票数:36
论文链接:
https://hf.co/papers/2510.05094
PaperScope.ai 解读:
https://paperscope.ai/hf/2510.05094
(16) MATRIX: Mask Track Alignment for Interaction-aware Video Generation
论文 ID:2510.07310

论文简介:
由KAIST AI等机构提出了MATRIX,该工作揭示了视频扩散Transformer(DiTs)在视频生成过程中如何表示多实例或主客体交互,并通过Semantic Grounding Alignment(SGA)和Semantic Propagation Alignment(SPA)损失增强模型的交互感知能力。研究团队构建了包含1.1万段视频的MATRIX-11K数据集,该数据集包含交互感知的字幕和多实例掩码轨迹。通过系统分析发现,DiTs的语义绑定(包括通过视频到文本注意力实现的语义定位,以及通过视频到视频注意力实现的语义传播)集中在少数交互主导层,且成功生成的视频在这些层中表现出更强的注意力对齐。受此启发,MATRIX框架通过轻量级LoRA适配器对这些交互主导层进行微调,利用SGA损失对齐名词/动词标记与实例区域,SPA损失保持跨帧实例轨迹的一致性。实验表明,该方法在InterGenEval评估协议(包含关键交互语义对齐、语义定位完整性等指标)上显著提升交互保真度,同时减少身份漂移和幻觉现象。消融实验验证了层选择策略和两种对齐损失的互补性,最终在保持视频质量的同时实现更精准的多实例交互生成。
论文来源:hf
Hugging Face 投票数:35
论文链接:
https://hf.co/papers/2510.07310
PaperScope.ai 解读:
https://paperscope.ai/hf/2510.07310
(17) Code2Video: A Code-centric Paradigm for Educational Video Generation
论文 ID:2510.01174

论文简介:
由新加坡国立大学Show Lab等机构提出了Code2Video,该工作提出了一种基于可执行Python代码的教育视频生成框架,通过Planner-Coder-Critic三代理协作实现时空结构可控的代码驱动生成。核心贡献包括:1)首创代码驱动的教育视频生成范式,将逻辑指令转化为可复现的Manim代码;2)设计具备并行代码生成、范围引导修复的Coder模块,以及基于视觉锚点提示的Critic模块;3)构建包含13个学科领域456个视频的MMMC基准,提出TeachQuiz等多维评估指标,实验证明该方法在知识传递效率上较直接代码生成提升40%,生成视频质量接近人类专家作品。
该框架通过Planner将学习主题分解为带视觉资产的分镜脚本,Coder基于并行合成和范围引导修复生成可执行代码,Critic利用6×6网格视觉锚点提示优化布局。在MMMC基准测试中,Code2Video在元素布局、逻辑流等美学维度得分较像素级扩散模型提升50%以上,TeachQuiz知识传递指标较直接代码生成提升40%。消融实验表明,规划模块对知识传递效果影响最大(下降41.5分),视觉锚点和外部数据库分别贡献10.9和26.8分提升。与人类制作的3Blue1Brown视频相比,该方法在保持时空连贯性的同时,生成效率提升30倍以上,为教育视频自动化生成提供了可扩展的解决方案。
论文来源:hf
Hugging Face 投票数:33
论文链接:
https://hf.co/papers/2510.01174
PaperScope.ai 解读:
https://paperscope.ai/hf/2510.01174
(18) VFXMaster: Unlocking Dynamic Visual Effect Generation via In-Context Learning
论文 ID:2510.25772
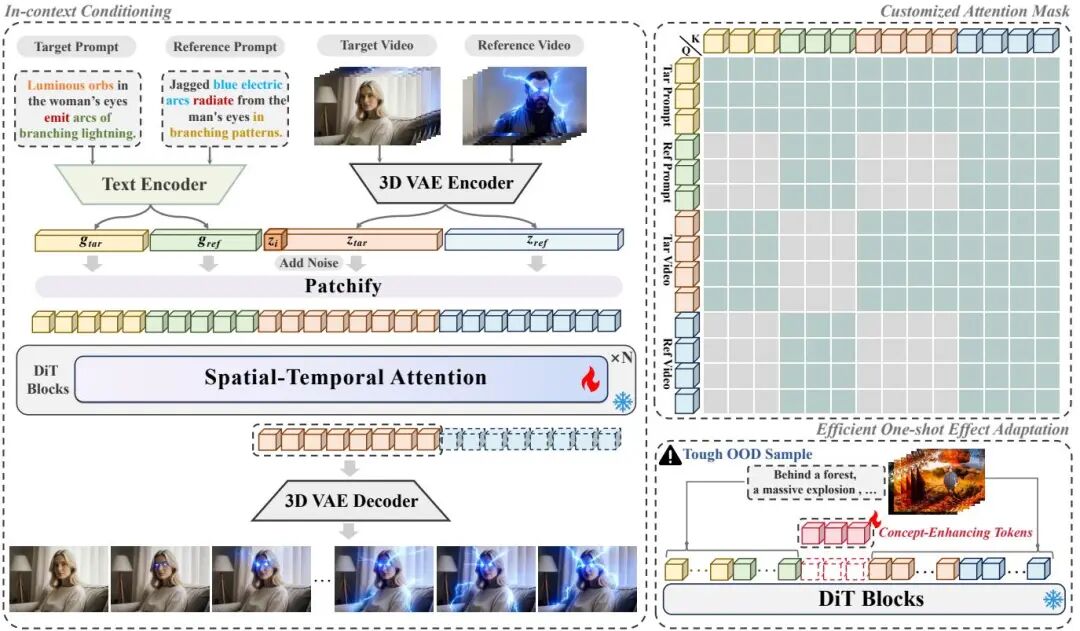
论文简介:
由大连理工大学、快手、ZMO AI和牛津大学等机构提出了VFXMaster,该工作首次构建了基于上下文学习的统一视觉特效生成框架,通过参考视频引导模型实现动态效果的精准迁移与泛化。针对传统特效生成依赖单一LoRA模型导致的扩展性不足问题,研究者设计了上下文条件策略,将参考视频与目标图像组成输入对,利用共享的3D VAE和文本编码器将二者映射到统一潜在空间,并通过时空注意力机制实现效果特征的跨域传递。核心创新点包括:1)提出上下文注意力掩码机制,通过语义相似性动态调控信息流,在避免内容泄露的同时精准提取特效属性;2)开发单样本适应模块,引入可学习的概念增强令牌,通过数据增强和受限注意力实现对未知特效的快速特征捕捉。实验部分构建了包含200类特效的10k视频数据集,并设计了包含效果一致性、保真度和内容泄露度的综合评估指标VFX-Cons。结果表明,该方法在领域内任务上较SOTA方案FVD指标平均提升24.4%,动态程度评分提升19.4%,在领域外测试中通过单样本微调使效果保真度从0.47提升至0.70。研究还验证了数据规模与泛化能力的正相关性,10k数据训练模型在OOD测试中FVD值较2k数据版本降低42.3%。该工作为影视、游戏等领域的高效特效创作提供了新范式,相关代码、模型和数据集将开源。
论文来源:hf
Hugging Face 投票数:32
论文链接:
https://hf.co/papers/2510.25772
PaperScope.ai 解读:
https://paperscope.ai/hf/2510.25772
(19) Ovi: Twin Backbone Cross-Modal Fusion for Audio-Video Generation
论文 ID:2510.01284
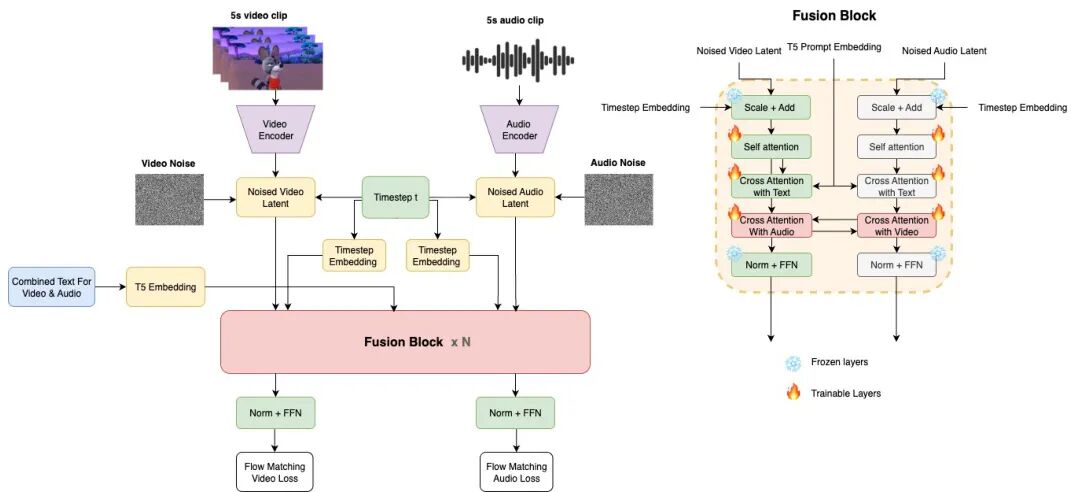
论文简介:
由Character AI和耶鲁大学提出的Ovi,构建了一种统一的音频-视频生成框架,通过双DiT模块的块级跨模态融合实现自然同步生成。该工作采用对称双主干架构,将音频塔初始化为与视频模型相同的架构并训练于大规模音频数据,使其既能生成真实语音又能处理多样化音效。核心创新在于通过缩放RoPE嵌入对齐时序分辨率差异,并在每个transformer块中插入双向交叉注意力机制,使音频与视频在生成过程中实时交换时间信息与语义特征。训练策略包含三个阶段:音频预训练(12秒语音数据)、音频微调(5秒音效数据)和跨模态融合训练(联合优化自注意力与交叉注意力模块)。实验显示,Ovi在音频-视频同步性、音质和画质上均显著优于JavisDiT和UniVerse-1等基线模型,尤其在跨模态注意力可视化中展现出精准的声源定位能力。该方法通过单阶段生成流程消除传统流水线的后对齐需求,为多模态生成提供了可扩展的对称架构范式。
论文来源:hf
Hugging Face 投票数:31
论文链接:
https://hf.co/papers/2510.01284
PaperScope.ai 解读:
https://paperscope.ai/hf/2510.01284
(20) CVD-STORM: Cross-View Video Diffusion with Spatial-Temporal Reconstruction Model for Autonomous Driving
论文 ID:2510.07944

论文简介:
由商汤科技和香港科技大学提出了CVD-STORM,该工作提出了一种结合时空重建的跨视图视频扩散模型,通过引入高斯溅射解码器的STORM-VAE,在生成多视角驾驶视频的同时实现4D场景重建。核心贡献包括:1)STORM-VAE通过联合训练图像重建与4D高斯溅射任务,将空间-时序信息编码至潜在表示,显著提升扩散模型的生成质量与收敛速度;2)CVD-STORM采用单阶段训练策略,通过共享STORM-VAE的潜在空间,在20秒长序列生成中实现FID 3.8/FVD 14.0的SOTA指标;3)高斯溅射解码器直接输出动态场景的绝对深度信息,解决传统方法依赖相对深度或额外标注的问题。实验表明,该方法在nuScenes数据集上较UniMLVG提升34.48% FID和61.21% FVD,同时通过零样本深度估计验证了4D重建的有效性,为自动驾驶场景理解提供兼具视觉保真度与几何准确性的生成式世界模型。
论文来源:hf
Hugging Face 投票数:24
论文链接:
https://hf.co/papers/2510.07944
PaperScope.ai 解读:
https://paperscope.ai/hf/2510.07944
(21) MotionRAG: Motion Retrieval-Augmented Image-to-Video Generation
论文 ID:2509.26391
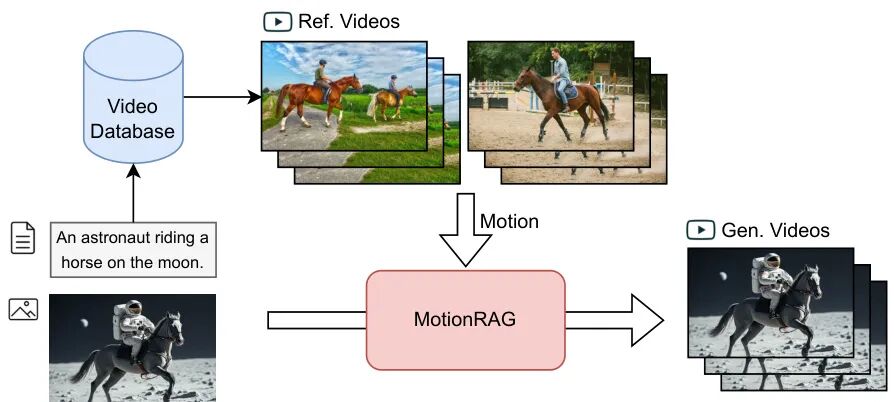
论文简介:
由南京大学和上海人工智能实验室等机构提出了MotionRAG,该工作提出了一种检索增强的图像到视频生成框架,通过上下文感知的运动适应(CAMA)技术显著提升了生成视频的运动真实性。研究团队针对现有扩散模型在建模复杂运动时的物理约束、物体交互和领域特异性动态等挑战,创新性地构建了包含三个核心组件的解决方案:基于视频编码器和专用重采样器的检索管道,通过因果Transformer实现的上下文学习运动适应机制,以及基于注意力的运动注入适配器。该方法通过文本检索获取相关参考视频,利用VideoMAE提取高阶语义运动特征,并通过逆序排列的示例序列训练因果Transformer实现跨领域运动适配,在保持输入图像外观特征的同时注入动态运动模式。实验表明,MotionRAG在多个基准测试中显著提升现有模型(如CogVideoX、Dynamicrafter和SVD)的运动质量指标,Action评分最高提升5.9分,FVD指标降低22%,且仅增加0.01-0.06分钟的推理时间。其模块化设计支持零样本域迁移能力,通过更换检索数据库即可适配专业领域(如教学视频),无需任何参数更新。该研究通过引入检索增强机制,突破了传统端到端训练的局限,为视频生成系统提供了可扩展的运动先验利用范式,为实现更逼真的视频生成提供了新思路。
论文来源:hf
Hugging Face 投票数:21
论文链接:
https://hf.co/papers/2509.26391
PaperScope.ai 解读:
https://paperscope.ai/hf/2509.26391
(22) PickStyle: Video-to-Video Style Transfer with Context-Style Adapters
论文 ID:2510.07546

论文简介:
由Pickford AI、多伦多大学和Vector Institute等机构提出了PickStyle,该工作针对视频到视频风格迁移任务,通过上下文-风格适配器和新型扩散模型架构,在缺乏配对视频数据的情况下实现高保真风格转换。研究团队通过插入低秩适配器到预训练视频扩散模型的自注意力层,使模型能够高效学习运动-风格迁移的特殊化能力,同时保持视频内容与风格的强对齐。为解决静态图像监督与动态视频的域差距问题,团队利用GPT-4o生成的多风格图像对(包含Unity3D动画的Anime/Pixar/Claymation风格,以及OmniConsistency数据集的LEGO/Rick&Morty等风格),通过模拟相机运动(缩放/平移)构建合成视频训练集。创新性提出的上下文-风格分类器无关指导(CS-CFG)机制,将文本(风格)与视频(内容)条件进行独立引导,在去噪过程中分别强化风格一致性与内容保真度。实验表明,PickStyle在保持原始视频运动特征的同时,实现了跨九种风格的连贯转换,其CSD风格对齐得分达到0.37(较基线提升2.2倍),R Precision@3达91%,在DreamSim内容相似度和UMTScore指标上也显著优于Control-A-Video、Rerender等现有方案。该方法通过部分噪声初始化策略平衡风格强度与内容保真,在H100 GPU上单秒视频生成耗时仅3.2秒,为动画制作和视频内容创作提供了高效解决方案。
论文来源:hf
Hugging Face 投票数:21
论文链接:
https://hf.co/papers/2510.07546
PaperScope.ai 解读:
https://paperscope.ai/hf/2510.07546
(23) UniMMVSR: A Unified Multi-Modal Framework for Cascaded Video Super-Resolution
论文 ID:2510.08143

论文简介:
由清华大学、华中科技大学和快手科技等机构提出了UniMMVSR,该工作首次构建了支持多模态条件输入的级联视频超分辨率统一框架。针对现有视频超分辨率方法局限于文本到视频任务、无法有效利用多模态生成条件的问题,UniMMVSR创新性地将文本、参考图像和视频等混合条件注入潜空间扩散模型,在保持计算效率的同时实现了对多模态引导信息的精准利用。研究团队通过token拼接策略融合视觉参考信息,设计了独立的位置编码机制以应对低分辨率视频与参考条件的空间错位,并开发了基于SDEdit的降质管道模拟基础模型生成特性。实验表明,该方法在文本到视频生成、多ID图像引导生成和文本引导视频编辑三大任务中均取得最优性能,生成的4K视频在细节质量、主体一致性及条件符合度等指标上全面超越现有方法。特别值得注意的是,其统一训练框架展现出跨任务数据迁移能力,通过高质量文本到视频数据的复用,显著降低了复杂多模态任务的数据采集成本,为超高清可控视频生成提供了全新范式。
论文来源:hf
Hugging Face 投票数:20
论文链接:
https://hf.co/papers/2510.08143
PaperScope.ai 解读:
https://paperscope.ai/hf/2510.08143
(24) VISTA: A Test-Time Self-Improving Video Generation Agent
论文 ID:2510.15831

论文简介:
由Google和新加坡国立大学等机构提出了VISTA,该工作通过多代理系统实现测试时自我改进的视频生成优化。VISTA创新性地将用户文本提示分解为结构化时间计划,利用成对锦标赛机制从生成视频中筛选最优结果,并通过视觉、音频、上下文三维度代理进行多模态批评,最终由推理代理整合反馈迭代优化提示词。实验显示,该方法在单场景和多场景视频生成任务中,相较于Sora、Veo 3等SOTA模型,通过5轮迭代优化使人类偏好度提升66.4%,自动评估胜率提升达60%。其核心优势在于:(1)首创多维度代理协同的视频优化框架,突破传统方法仅聚焦单一模态的局限;(2)设计可配置的评估指标体系,实现模型驱动的自主视频质量判断;(3)提出基于推理的提示词优化策略,避免盲目修改导致的语义漂移。消融实验证实各模块贡献:结构化规划提升初始化质量,锦标赛选择稳定迭代效果,双法官机制平衡批评深度,推理代理实现精准优化。在计算成本方面,每轮迭代消耗约0.7M tokens和28个视频生成量,展现出良好的扩展潜力。该研究为提升视频生成与用户意图对齐度提供了新范式,推动文本到视频生成向更可控、更智能的方向发展。
论文来源:hf
Hugging Face 投票数:19
论文链接:
https://hf.co/papers/2510.15831
PaperScope.ai 解读:
https://paperscope.ai/hf/2510.15831
(25) LongCat-Video Technical Report
论文 ID:2510.22200

论文简介:
由Meituan LongCat Team等机构提出了LongCat-Video,该工作基于Diffusion Transformer框架构建了支持文本到视频、图像到视频和视频延续的统一生成模型,通过预训练实现分钟级高质量长视频生成,并采用多奖励RLHF训练策略达到与最新闭源模型相当的性能。LongCat-Video作为迈向世界模型的重要尝试,其核心贡献包含四个维度:首先通过条件帧数量差异实现多任务统一架构,将文本到视频(零帧条件)、图像到视频(单帧条件)和视频延续(多帧条件)整合于单一模型;其次通过视频延续预训练确保生成质量与时空一致性,在分钟级长视频生成中避免色彩偏移和质量衰减;再者创新性采用时空轴粗到细生成策略(480p/15fps初生成+720p/30fps精修)结合块稀疏注意力机制,使高分辨率视频生成效率提升12.3倍;最后通过多奖励GRPO训练引入视觉质量、运动质量和文本对齐三重评估体系,既避免单一奖励的优化偏差又实现性能突破。该模型参数规模达136亿,配套开源的Block Sparse Attention模块和LoRA精修方案,为视频生成领域提供了兼具学术研究价值和工业应用潜力的技术范式。
论文来源:hf
Hugging Face 投票数:19
论文链接:
https://hf.co/papers/2510.22200
PaperScope.ai 解读:
https://paperscope.ai/hf/2510.22200
(26) VR-Thinker: Boosting Video Reward Models through Thinking-with-Image Reasoning
论文 ID:2510.10518
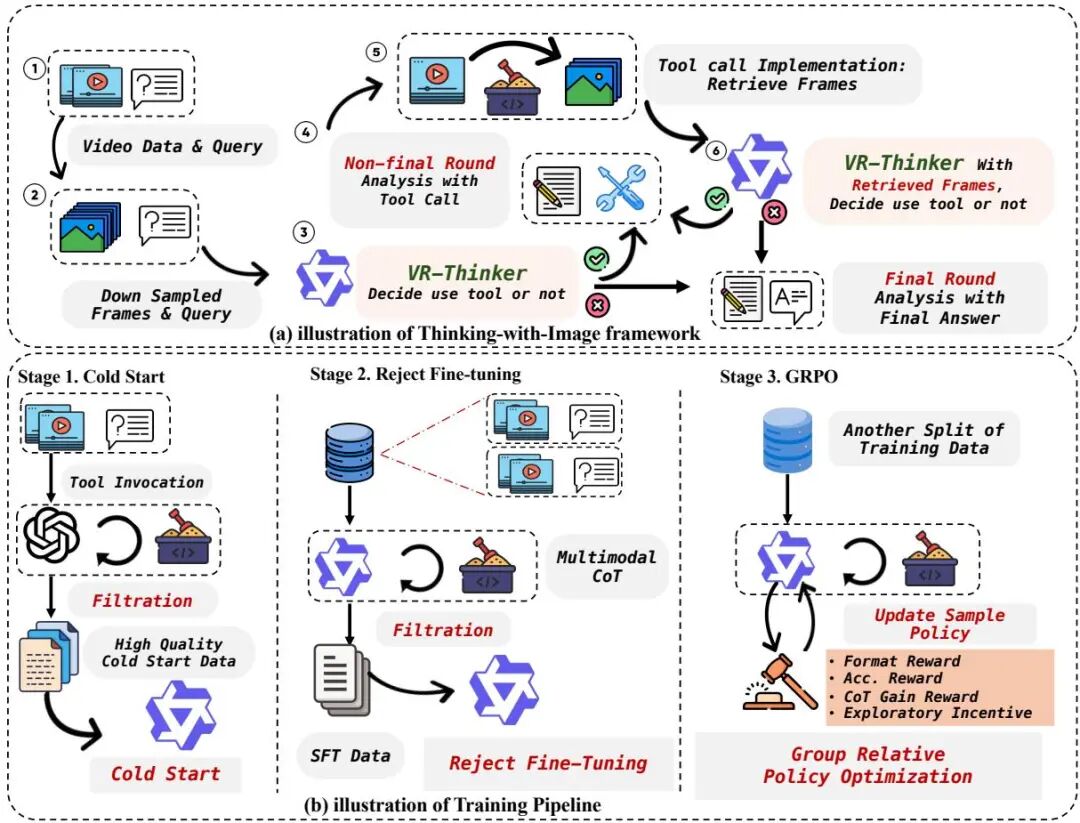
论文简介:
由CUHK MMLab、快手Kling团队和南京大学等机构提出的VR-Thinker,通过引入"思考-图像"推理框架革新视频奖励模型。该工作针对现有视频奖励模型面临的两大核心挑战:视觉输入占用过多上下文导致帧数受限、初始视觉信息固化引发推理遗忘,创新性地为模型赋予帧选择等视觉推理能力,并构建可配置的视觉记忆窗口。通过动态调用视觉信息与文本推理的协同机制,模型在保持上下文稳定性的同时突破帧数限制,显著提升长视频场景下的推理保真度。
研究团队设计了三阶段训练策略:首先利用高质量思维链数据进行冷启动,建立基础推理框架;接着通过拒绝采样微调筛选高置信度样本强化推理质量;最终采用组相对策略优化(GRPO)构建规则奖励体系,结合维度级判断与整体偏好双重约束,引导模型实现深度多模态推理。实验表明,7B参数量的VR-Thinker在VideoGen Reward、GenAI-Bench和MJ-Bench-Video基准测试中分别取得80.5%、82.3%和75.6%的准确率,较现有最优模型提升11.4个百分点。特别在长视频和复杂提示场景下,模型准确率下降幅度较基线模型减少50%以上,验证了视觉推理机制在处理高难度视频理解任务时的优越性。该研究为多模态奖励模型的可解释性发展提供了新范式,为视频生成模型的人类偏好对齐奠定了技术基础。
论文来源:hf
Hugging Face 投票数:17
论文链接:
https://hf.co/papers/2510.10518
PaperScope.ai 解读:
https://paperscope.ai/hf/2510.10518
(27) InstructX: Towards Unified Visual Editing with MLLM Guidance
论文 ID:2510.08485

论文简介:
由字节跳动等机构提出了InstructX,该工作提出了一种基于多模态大语言模型(MLLM)指导的统一视觉编辑框架。通过系统研究MLLM与扩散模型的集成方式,发现将MLLM作为理解模块并通过可学习查询与扩散模型连接,配合LoRA微调和轻量级MLP适配器的架构设计,在特征对齐和编辑性能上表现最优。研究证实图像编辑数据训练可激发模型零样本视频编辑能力,通过混合图像/视频数据训练实现了单模型统一处理图像与视频编辑任务。创新性地引入模态特异性可学习查询机制,在保持统一架构的同时有效区分图像与视频特征。此外,构建了包含140个高质量实例的视频编辑基准VIE-Bench,覆盖8类指令编辑任务。实验表明该方法在图像编辑任务上超越SeedEdit、GPT-4o等SOTA开源方案,在视频编辑任务中达到接近Runway、Kling等闭源系统的性能,尤其在风格迁移、混合编辑等复杂任务中表现突出,同时支持更广泛的编辑类型。该工作为视觉编辑领域提供了重要的架构设计指导和数据构建范式,推动了多模态理解与生成的深度融合。
论文来源:hf
Hugging Face 投票数:16
论文链接:
https://hf.co/papers/2510.08485
PaperScope.ai 解读:
https://paperscope.ai/hf/2510.08485
(28) UltraGen: High-Resolution Video Generation with Hierarchical Attention
论文 ID:2510.18775

论文简介:
由上海交通大学和浙江大学等机构提出了UltraGen,该工作通过分层双分支注意力架构实现了高效的原生高分辨率视频生成。现有扩散Transformer模型因自注意力机制的二次计算复杂度,在高分辨率视频生成中面临质量下降和计算成本激增的瓶颈。UltraGen创新性地将全局与局部注意力解耦,全局分支通过空间压缩机制捕获视频整体语义,局部分支采用跨窗口分层注意力增强区域细节,同时通过时间感知融合策略动态平衡两者贡献。核心贡献包括:1)空间压缩全局建模,通过帧级卷积压缩空间信息,在低分辨率下执行全局注意力后用3D卷积恢复时空一致性,显著降低计算开销;2)分层跨窗口局部注意力,通过相邻层窗口的错位划分和域感知LoRA适配,在保持线性复杂度的同时实现跨窗口信息交互;3)首次实现4K原生视频生成,对比Wan和HunyuanVideo等SOTA模型,在1080P和4K分辨率下均取得FVD、LPIPS等指标的显著提升,推理速度最高提升4.78倍。实验表明该方法在保持语义连贯性的同时,生成视频的细节清晰度和运动流畅度均优于传统超分两阶段方案,为高分辨率视频生成提供了可扩展的高效解决方案。
论文来源:hf
Hugging Face 投票数:16
论文链接:
https://hf.co/papers/2510.18775
PaperScope.ai 解读:
https://paperscope.ai/hf/2510.18775
(29) Stable Video Infinity: Infinite-Length Video Generation with Error Recycling
论文 ID:2510.09212

论文简介:
由EPFL等机构提出了Stable Video Infinity(SVI),该工作通过创新的错误回收机制突破了视频生成的时长限制,首次实现无限长度视频生成。SVI针对现有扩散模型在长视频生成中面临的错误累积问题,提出错误回收微调(Error-Recycling Fine-Tuning)技术,通过构建闭合循环系统将模型自身生成的错误转化为训练信号。具体而言,研究团队发现传统训练与推理阶段存在假设鸿沟:训练时假设输入无误差,而推理时却依赖自生成的错误输出。为解决这一矛盾,SVI通过三个关键步骤实现错误纠正:首先向清洁输入注入历史错误模拟漂移轨迹,其次通过单步双向积分近似预测并计算误差,最后将误差动态存入时间步离散化的重放缓存供后续采样。这种机制使模型能够主动识别并修正自身错误,实现从秒级到无限长度的视频生成,同时保持时间一致性、场景过渡合理性和多模态控制能力。实验部分,团队构建了包含一致生成、创意生成和条件生成的三大基准测试,SVI在超长视频(250秒)生成中相比Wan 2.1等基线模型,主体一致性提升17%,背景一致性提升13%,且动态程度保持稳定。特别在创意生成任务中,SVI首次实现基于文本流的场景过渡控制,推动了端到端视频创作的发展。该方法还展现出强大的扩展性,通过微调即可适配音频驱动对话和骨架驱动舞蹈等条件生成任务,在300秒对话视频生成中FVD指标降低至390,显著优于MultiTalk等专业模型。SVI的零推理成本和小样本微调特性,为无限长度视频生成开辟了新路径。
论文来源:hf
Hugging Face 投票数:14
论文链接:
https://hf.co/papers/2510.09212
PaperScope.ai 解读:
https://paperscope.ai/hf/2510.09212
(30) Presenting a Paper is an Art: Self-Improvement Aesthetic Agents for Academic Presentations
论文 ID:2510.05571
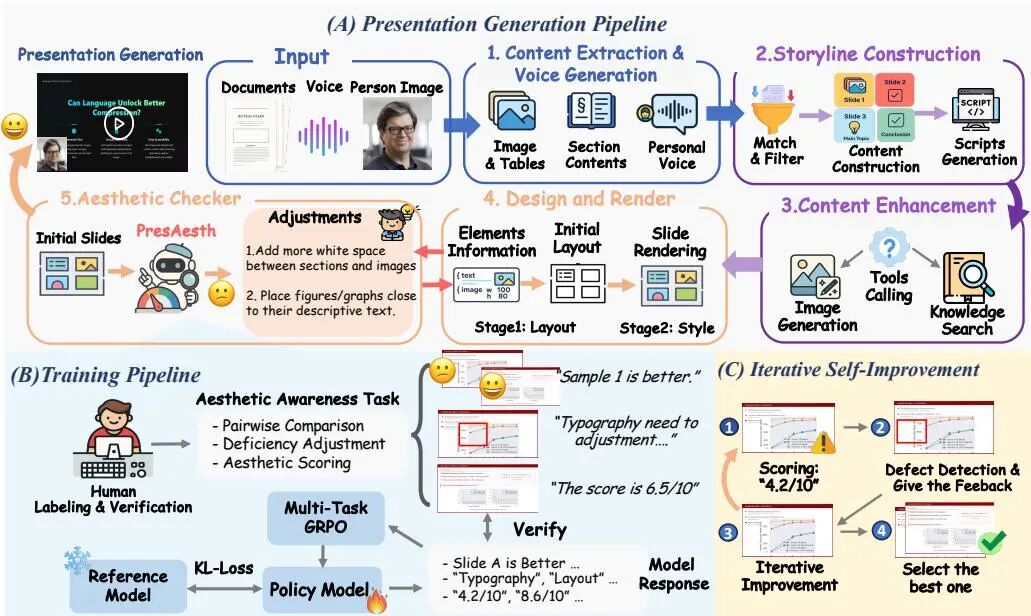
论文简介:
由加州大学圣巴巴拉分校等机构提出了EvoPresent,该工作构建了一个自我改进的多智能体框架,通过叙事连贯性、美学感知设计和虚拟角色驱动的逼真展示,实现了学术报告生成的自动化与质量提升。核心贡献包括:1)PresAesth多任务强化学习模型,通过评分、缺陷调整和对比反馈三重任务,在有限美学数据下实现可靠的美学感知与推理;2)EvoPresent框架整合四个智能体(故事线构建、学术内容扩展、设计渲染、美学检查),通过迭代优化生成高质量多模态学术报告;3)EvoPresent基准测试集涵盖650篇顶会论文资源和2000组美学对比幻灯片,支持生成质量与美学感知的联合评估;4)实验表明多任务强化学习在美学感知任务中泛化能力更强,高质量反馈对智能体迭代优化至关重要,且内容构建与视觉设计存在固有权衡。该框架在叙事连贯性、视觉美学和内容传达效果上均超越现有方法,为学术成果的高效传播提供了新范式。
论文来源:hf
Hugging Face 投票数:13
论文链接:
https://hf.co/papers/2510.05571
PaperScope.ai 解读:
https://paperscope.ai/hf/2510.05571
(31) ConsistEdit: Highly Consistent and Precise Training-free Visual Editing
论文 ID:2510.17803

论文简介:
由香港科技大学、清华大学等机构提出了ConsistEdit,该工作针对多模态扩散Transformer(MM-DiT)架构设计了新型注意力控制方法,解决了现有训练免费编辑方法在保持编辑强度与一致性之间的矛盾。研究发现MM-DiT的注意力机制具有视觉信息关键性、全层语义保留性和结构可控性三大特性,据此提出仅对视觉token进行注意力控制、掩码引导的前注意力融合、以及对Q/K/V进行差异化操作三大核心策略。该方法实现了编辑区域结构一致性(如纹理/光照保持)与非编辑区域内容完整性的双重保障,支持渐进式一致性强度调节,并首次实现在所有推理步骤和注意力层自动编辑而无需人工参数调整。实验表明其在图像/视频编辑任务中均达到SOTA性能,尤其在多轮编辑、多区域编辑和时序一致性控制方面表现突出,可扩展至SD3、FLUX、CogVideoX等主流MM-DiT模型,在结构保持型编辑(颜色/材质修改)和结构变化型编辑(对象增删)中均显著优于DiTCtrl、FireFlow等现有方案,为生成模型编辑提供了兼具鲁棒性与可控性的新范式。
论文来源:hf
Hugging Face 投票数:12
论文链接:
https://hf.co/papers/2510.17803
PaperScope.ai 解读:
https://paperscope.ai/hf/2510.17803
(32) Taming Text-to-Sounding Video Generation via Advanced Modality Condition and Interaction
论文 ID:2510.03117

论文简介:
由中国人民大学与苹果公司等机构提出了Taming Text-to-Sounding Video Generation via Advanced Modality Condition and Interaction,该工作针对文本驱动的音视频同步生成任务中的模态干扰和跨模态交互两大核心挑战,提出了创新解决方案。研究团队首先构建了分层视觉引导字幕生成框架(HVGC),通过三阶段流程(视觉描述生成、音频标签提取、纯音频字幕生成)为双塔架构的视频和音频分支提供解耦的模态专有文本条件,有效避免了传统共享文本导致的条件冲突问题。在此基础上,团队设计了BridgeDiT双塔扩散Transformer架构,其核心是双向交叉注意力(DCA)融合机制,通过视频到音频和音频到视频的对称特征交互,在早期到中期网络层实现时空特征的深度对齐。实验表明,该方法在AVSync15、VGGSound-SS和Landscape三个基准数据集上均取得SOTA结果,其中FVD指标较基线提升15.3%,AV-Align同步指标提升28.7%。消融实验进一步验证了HVGC框架在消除模态干扰方面的有效性,以及DCA机制相比全注意力、加性融合等替代方案在时序同步上的显著优势。用户研究显示该方法在视频质量、音频质量、文本对齐等五个维度均获得最高评分,证明了其生成内容的综合质量优势。该研究为多模态生成领域提供了重要的方法论启示,其开源代码和模型将推动音视频同步生成技术的进一步发展。
论文来源:hf
Hugging Face 投票数:11
论文链接:
https://hf.co/papers/2510.03117
PaperScope.ai 解读:
https://paperscope.ai/hf/2510.03117
(33) RAPO++: Cross-Stage Prompt Optimization for Text-to-Video Generation via Data Alignment and Test-Time Scaling
论文 ID:2510.20206
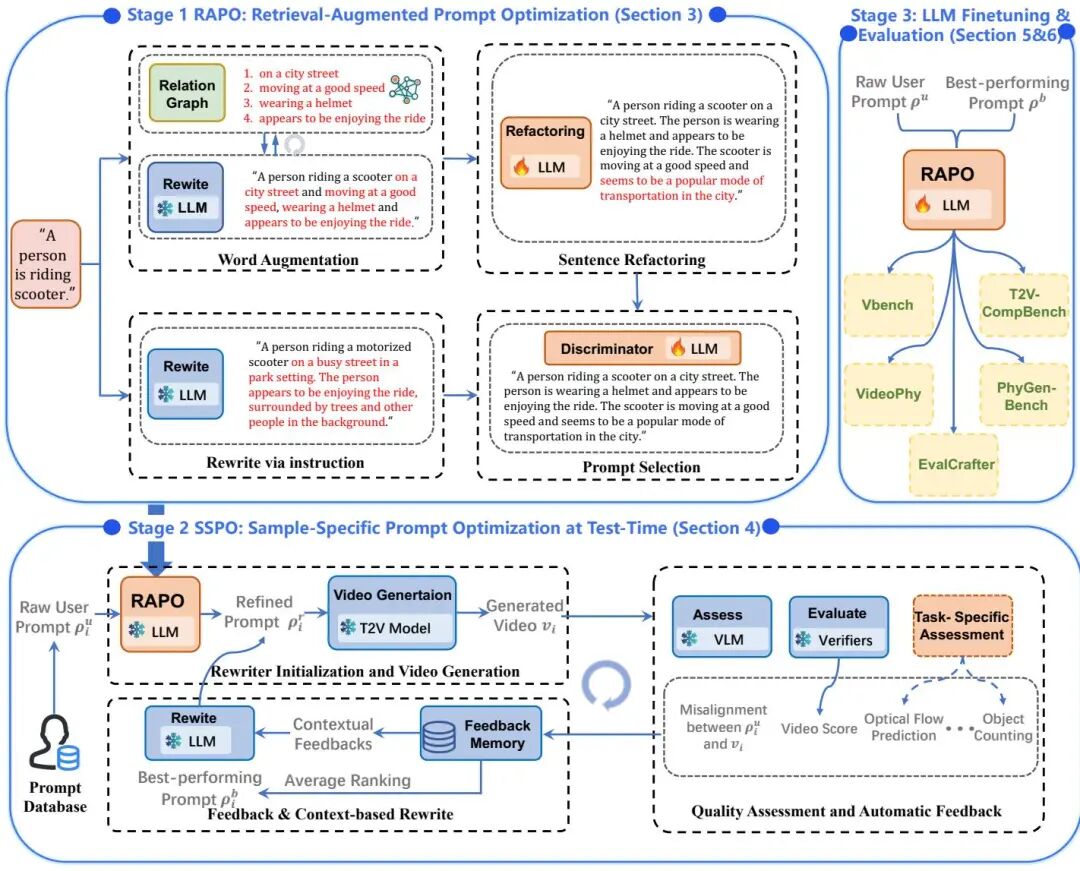
论文简介:
由Bingjie Gao等研究者提出了RAPO++,该工作提出了一种跨阶段提示优化框架,通过训练数据对齐的提示重构、测试时迭代扩展以及大语言模型微调,在不修改生成模型的基础上显著提升文本到视频生成质量。第一阶段RAPO通过关系图检索语义相关修饰符并重构提示,使其匹配训练数据分布;第二阶段SSPO利用多源反馈(语义对齐、时空一致性、光流等)构建闭合优化循环,通过记忆库存储反馈信息指导提示迭代优化;第三阶段利用优化后的提示对语言模型进行指令微调,提升其生成高质量提示的泛化能力。在LaVie、Latte等五个主流模型及VBench等五个基准测试中,RAPO++在语义对齐、时空稳定性、物理合理性等维度均显著超越现有方法,例如在VBench上较基线提升超15%。该方法通过训练数据引导的语义增强与测试时动态优化相结合,实现了模型无关、计算高效的提示优化范式,为文本到视频生成的提示工程提供了新基准。
论文来源:hf
Hugging Face 投票数:11
论文链接:
https://hf.co/papers/2510.20206
PaperScope.ai 解读:
https://paperscope.ai/hf/2510.20206
(34) ChronoEdit: Towards Temporal Reasoning for Image Editing and World Simulation
论文 ID:2510.04290

论文简介:
由NVIDIA和多伦多大学等机构提出了ChronoEdit,该工作通过将图像编辑任务转化为视频生成问题,利用预训练视频生成模型的时序一致性先验,有效解决了编辑过程中物理一致性缺失的关键难题。研究者创新性地将输入图像与编辑结果视为视频首尾帧,通过引入时间推理阶段,在去噪过程中联合推理token生成合理的编辑轨迹,从而约束解空间为符合物理规律的变换。该方法在PBench-Edit新基准测试中展现出显著优势,其14B参数模型在动作保真度、身份保持和视觉一致性等维度均超越现有开源模型,接近商业系统水平。值得注意的是,研究团队提出的两阶段推理策略通过前10步引入推理token进行轨迹规划,后续步骤转为单帧优化,在保持4.53高分的同时将计算成本降低4.9秒。此外,基于DMD蒸馏技术开发的ChronoEdit-Turbo版本在5秒内完成编辑,速度提升6倍的同时仍保持4.13的竞争力得分。实验表明,该方法在移除、替换等复杂空间操作任务中分别取得4.57和4.66的突破性表现,较此前最佳开源模型提升1.63和2.51分,其可视化推理轨迹更展现出对物理交互过程的深度理解。
论文来源:hf
Hugging Face 投票数:11
论文链接:
https://hf.co/papers/2510.04290
PaperScope.ai 解读:
https://paperscope.ai/hf/2510.04290
(35) MUG-V 10B: High-efficiency Training Pipeline for Large Video Generation Models
论文 ID:2510.17519

论文简介:
由Shopee团队提出的MUG-V 10B,通过优化数据处理、模型架构、训练策略和基础设施四个核心环节,构建了高效的视频生成模型训练框架。该工作创新性地设计了高压缩比的VideoVAE(实现8×8×8时空压缩),提出最小编码原则避免信息密度失衡;开发了100亿参数Diffusion Transformer,采用全注意力机制与三维RoPE编码,并通过参数扩展策略实现从小模型到大模型的平滑过渡。训练策略上采用多阶段课程学习(从图像到低分辨率视频再到高分辨率视频),结合人类偏好优化(KTO+DPO算法)提升生成质量。基础设施层面基于Megatron-Core实现近线性多节点扩展,通过混合并行策略、动态数据采样和内核融合技术优化计算效率。实验显示,MUG-V 10B在VBench I2V榜单位列第三,电商场景人类评估通过率达81.55%,显著优于HunyuanVideo和Wan 2.1。该框架在保持训练效率的同时,通过开源完整代码栈(含训练/推理管道)降低了视频生成技术的应用门槛,为行业提供了首个基于Megatron-Core的高效视频生成训练方案。
论文来源:hf
Hugging Face 投票数:9
论文链接:
https://hf.co/papers/2510.17519
PaperScope.ai 解读:
https://paperscope.ai/hf/2510.17519
(36) Rethinking Driving World Model as Synthetic Data Generator for Perception Tasks
论文 ID:2510.19195

论文简介:
由北京大学、小米等机构提出了Dream4Drive,该工作重新评估了驾驶世界模型作为感知任务合成数据生成器的有效性,通过引入3D感知的场景编辑框架和大规模3D资产数据集DriveObj3D,解决了现有方法在公平性评估和几何一致性上的不足。研究发现,当训练轮次相同时,现有合成数据方法相比纯真实数据并无显著优势,而Dream4Drive通过分解输入视频为3D感知引导图、渲染3D资产并微调扩散模型生成多视角视频,在仅添加2%合成数据的情况下,检测和跟踪性能在不同训练轮次中均显著超越现有方法。核心创新包括:1)提出3D感知视频编辑机制,通过深度、法线、边缘等密集引导图实现几何一致的实例级编辑;2)构建包含典型驾驶场景类别的DriveObj3D资产库,支持多样化视频合成;3)设计多条件融合适配器,将引导图特征注入扩散模型生成逼真多视角视频。实验表明,在nuScenes数据集上,Dream4Drive以420个合成样本实现mAP提升1.6%,NDS提升0.9%,且在高分辨率下性能增益更显著。该工作为自动驾驶合成数据生成提供了新的评估范式和实用框架,验证了高质量合成数据对下游任务的真正价值。
论文来源:hf
Hugging Face 投票数:9
论文链接:
https://hf.co/papers/2510.19195
PaperScope.ai 解读:
https://paperscope.ai/hf/2510.19195
(37) Large Scale Diffusion Distillation via Score-Regularized Continuous-Time Consistency
论文 ID:2510.08431

论文简介:
由清华大学与NVIDIA等机构提出了Large Scale Diffusion Distillation via Score-Regularized Continuous-Time Consistency,该工作首次将连续时间一致性蒸馏扩展到大规模文本到图像和视频生成任务。研究者通过开发兼容FlashAttention-2的JVP内核,实现了对百亿参数模型的训练,并揭示了传统连续时间一致性模型(sCM)在细粒度生成中的质量缺陷。针对sCM的误差累积问题,团队提出score-regularized连续时间一致性模型(rCM),创新性地将score蒸馏作为长期跳跃正则化项,通过反向散度优化弥补sCM的前向散度局限。该方法在Cosmos-Predict2和Wan2.1等14B参数模型上验证,仅需1-4步采样即可生成媲美教师模型的高质量内容,相比传统蒸馏方法提升15-50倍推理速度。实验表明rCM在GenEval和VBench等基准测试中超越当前最优方法DMD2,在保持生成多样性的同时显著提升文本渲染和时序一致性,为大规模扩散模型蒸馏提供了兼具理论严谨性与工程可行性的解决方案。
论文来源:hf
Hugging Face 投票数:8
论文链接:
https://hf.co/papers/2510.08431
PaperScope.ai 解读:
https://paperscope.ai/hf/2510.08431
(38) OmniNWM: Omniscient Driving Navigation World Models
论文 ID:2510.18313

论文简介:
由上海交通大学、宁波东方理工大学等机构提出了OmniNWM,该工作提出了一种全知驾驶导航世界模型,统一了状态、动作和奖励三个核心维度,实现了全景多模态生成、精确动作控制和基于占据栅格的密集奖励。OmniNWM通过联合生成全景RGB、语义、深度和3D占据栅格视频,采用灵活的强制策略实现超长序列生成(321帧),显著超越现有方法的241帧限制。其归一化的全景Plücker射线图表示将轨迹编码为像素级控制信号,实现了精确的全景相机控制,控制精度接近真值水平(旋转误差1.42×10⁻²)。通过生成的3D占据栅格直接定义基于规则的密集奖励,支持闭环导航评估,奖励函数在碰撞、边界和速度维度实现精准行为评判。实验显示该模型在生成质量(FID 5.45/FVD 23.63)、深度预测(Abs.Rel. 0.23)和占据栅格预测(IoU 33.3)等指标上全面领先,零样本泛化能力覆盖不同数据集和多相机配置,为自动驾驶提供了统一的生成、控制与评估框架。
论文来源:hf
Hugging Face 投票数:8
论文链接:
https://hf.co/papers/2510.18313
PaperScope.ai 解读:
https://paperscope.ai/hf/2510.18313
(39) LikePhys: Evaluating Intuitive Physics Understanding in Video Diffusion Models via Likelihood Preference
论文 ID:2510.11512

论文简介:
由牛津大学、MBZUAI、芝加哥大学等机构提出了LikePhys,该工作提出一种训练无关的视频扩散模型物理理解评估方法,通过构建物理有效与无效视频对,利用扩散模型去噪目标作为似然代理,以似然偏好差异量化模型对物理规律的掌握程度。研究者构建了包含12个物理场景的基准测试集,覆盖刚体动力学、连续介质力学、流体力学和光学效应四大领域,每个场景通过Blender渲染保持视觉一致性的有效-无效视频对。通过计算Plausibility Preference Error(PPE)指标,发现该指标与人类对物理合理性的判断具有强相关性(Kendall's τ=0.44),且与现有基于视觉语言模型的评估方法相比,能更有效剥离视觉外观干扰。实验评估了12个主流视频扩散模型,发现基于Diffusion Transformer架构的模型(如Hunyuan T2V、CogVideoX)平均PPE显著低于传统3D UNet架构模型(如AnimateDiff),表明模型容量和训练数据规模提升有助于物理理解能力增强。分析显示模型在流体力学场景(如河流流动)中表现最差(平均PPE超70%),而在光学效应场景(如阴影变化)中表现最佳(平均PPE约40%),揭示了当前模型在处理非线性、多尺度动态时的局限性。研究还发现增加生成帧数可提升物理推理能力,而分类器引导强度对物理理解影响较小,为模型优化提供了关键洞见。
论文来源:hf
Hugging Face 投票数:6
论文链接:
https://hf.co/papers/2510.11512
PaperScope.ai 解读:
https://paperscope.ai/hf/2510.11512
(40) RealDPO: Real or Not Real, that is the Preference
论文 ID:2510.14955
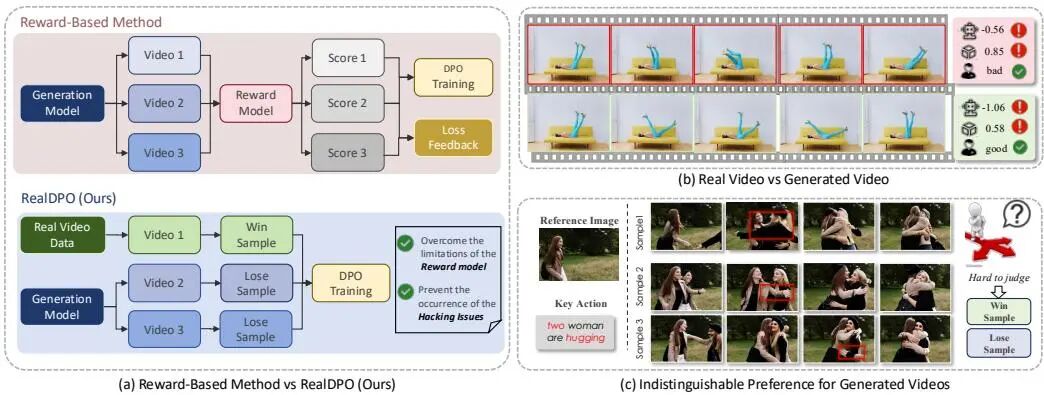
论文简介:
由上海人工智能实验室、南洋理工大学、电子科技大学等机构提出了RealDPO,该工作针对视频生成模型在复杂动作合成中的运动不自然问题,提出基于真实数据偏好学习的对齐范式。通过将真实视频作为正样本引入直接偏好优化(DPO),结合定制化损失函数和新型数据集RealAction-5K,显著提升了生成视频的动作真实感与文本一致性。传统方法依赖的奖励模型存在reward hacking、可扩展性差等问题,而RealDPO通过对比真实视频与模型生成的负样本,构建了无需外部奖励函数的自纠正机制。实验表明,该方法在动作质量、视觉对齐等维度超越现有SFT及偏好优化技术,在用户研究和多模态大模型评估中均取得最优表现。RealAction-5K数据集以"少而精"为原则,通过LLM过滤、人工校验等流程构建了5K高质量人类日常活动视频,为偏好学习提供精准监督信号。该工作突破了奖励模型的局限性,为视频生成的偏好对齐提供了更高效的技术路径。
论文来源:hf
Hugging Face 投票数:6
论文链接:
https://hf.co/papers/2510.14955
PaperScope.ai 解读:
https://paperscope.ai/hf/2510.14955
(41) WristWorld: Generating Wrist-Views via 4D World Models for Robotic Manipulation
论文 ID:2510.07313

论文简介:
由北京大学、香港科技大学等机构提出了WristWorld,该工作提出首个4D生成世界模型,通过两阶段框架实现从锚点视图到手腕视角视频的生成。针对机器人操作数据集中手腕视角数据稀缺的问题,研究者设计了包含重建阶段和生成阶段的解决方案:重建阶段通过扩展视觉几何模型VGGT并引入空间投影一致性损失(SPC Loss),实现无监督条件下的手腕姿态估计和4D点云重建;生成阶段则采用扩散模型,结合CLIP编码的语义特征和重建的投影条件图,生成时空一致的手腕视角视频。实验表明,该方法在Droid、Calvin和Franka Panda数据集上均取得最优视频生成质量(FVD指标提升421.10),在Calvin基准上使任务完成长度提升3.81%,填补了42.4%的视角性能差距。研究还验证了其作为插件模块扩展单视角世界模型的能力,通过后处理方式为现有模型注入多视角能力,为机器人操作数据增强提供了可扩展的解决方案。
论文来源:hf
Hugging Face 投票数:6
论文链接:
https://hf.co/papers/2510.07313
PaperScope.ai 解读:
https://paperscope.ai/hf/2510.07313
(42) LightCache: Memory-Efficient, Training-Free Acceleration for Video Generation
论文 ID:2510.05367

论文简介:
由Yang Xiao等学者提出了LightCache,该工作针对视频生成任务中扩散模型推理阶段的高内存占用与低效问题,提出了一种无需训练的加速框架。研究者通过将推理过程细分为编码、去噪和解码三个阶段,发现缓存机制虽能加速计算却会导致内存激增,尤其在去噪和解码阶段更为显著。为此,团队设计了三阶段协同优化策略:1)异步缓存交换机制,将缓存特征图迁移至CPU内存并实现GPU-CPU异步传输,平衡通信与计算开销;2)特征分块策略,动态调整去噪阶段特征图的空间维度,在保持生成质量前提下降低显存占用;3)解码切片技术,将视频帧分批解码以突破单次解码的内存瓶颈。实验表明,LightCache在AnimateDiff-Lightning和Stable-Video-Diffusion-Img2vid-XT模型上分别实现1.59倍和2.86倍加速,同时减少8.0GB和1.4GB显存消耗,且生成质量(LPIPS/PSNR/SSIM指标)与基线模型保持一致。该方法在保持扩散模型生成性能的同时,有效解决了视频生成任务中显存占用与推理速度的矛盾,为大规模视频生成应用提供了高效的部署方案。
论文来源:hf
Hugging Face 投票数:6
论文链接:
https://hf.co/papers/2510.05367
PaperScope.ai 解读:
https://paperscope.ai/hf/2510.05367
(43) Character Mixing for Video Generation
论文 ID:2510.05093

论文简介:
由 Mohamed bin Zayed University of Artificial Intelligence 等机构提出了 Character Mixing for Video Generation,该工作通过 Cross-Character Embedding(CCE)和 Cross-Character Augmentation(CCA)技术,首次实现了跨风格、跨宇宙角色的自然视频互动生成。研究聚焦于文本到视频生成中的角色交互难题,针对角色不共存(不同作品角色无共现数据)和风格混淆(卡通与真人风格混合导致失真)两大挑战,提出通过结构化角色-动作标注解耦身份与场景信息,并利用合成数据增强训练。团队构建了包含 81 小时视频(52,000 个片段)的多领域数据集,覆盖《咱们裸熊》《猫和老鼠》等卡通及《憨豆先生》《小谢尔顿》等真人剧集,每个片段均标注角色名称与风格标签。CCE 模块通过 GPT-4o 生成带角色标识的动态描述文本,结合 LoRA 微调 Wan2.1-T2V 模型,实现身份与行为逻辑的跨模态学习;CCA 模块则通过 SAM2 分割与背景合成技术,生成跨风格混合数据,有效缓解风格漂移问题。实验表明,该方法在身份保留(Identity-P 提升 15%)、行为一致性(Motion-P 提升 20%)及风格控制(Style-P 提升 12%)等维度显著优于 VideoBooth、DreamVideo 等基线模型,尤其在跨风格多角色互动场景中展现出更强的场景协调性。研究还建立了首个支持风格一致性评估的多角色视频生成基准,为生成式叙事提供了新的技术路径。
论文来源:hf
Hugging Face 投票数:6
论文链接:
https://hf.co/papers/2510.05093
PaperScope.ai 解读:
https://paperscope.ai/hf/2510.05093
(44) DialectGen: Benchmarking and Improving Dialect Robustness in Multimodal Generation
论文 ID:2510.14949

论文简介:
由加州大学洛杉矶分校等机构提出了DialectGen,该工作构建了一个大规模多模态方言鲁棒性评测基准,揭示了当前生成模型在处理方言文本输入时存在显著性能下降问题,并提出了一种通用的编码器优化策略提升方言兼容性。研究团队针对六种常见英语方言构建了包含4200对语义等价方言-标准英语提示词的数据集,通过严格的人工验证确保方言表达的准确性与非歧义性。实验评估了17种主流文生图/文生视频模型,发现使用单个方言词汇时模型性能下降幅度达到32.26%至48.17%,其中印度英语和奇卡诺英语受影响最为显著。研究测试的微调和提示词重写等缓解方法效果有限,且可能损害标准英语表现。针对这一问题,团队设计了包含方言学习损失、多义词控制损失和KL正则化损失的三阶段编码器优化框架,在保持标准英语性能的同时,使Stable Diffusion 1.5等模型在五种方言上的表现提升34.4%达到与标准英语相当的水平。该工作为提升多模态生成模型的方言兼容性提供了首个系统性解决方案,相关数据和代码已开源。
论文来源:hf
Hugging Face 投票数:5
论文链接:
https://hf.co/papers/2510.14949
PaperScope.ai 解读:
https://paperscope.ai/hf/2510.14949
(45) What If : Understanding Motion Through Sparse Interactions
论文 ID:2510.12777

论文简介:
由LMU Munich和MCML等机构提出了Flow Poke Transformer(FPT),该工作通过稀疏交互(pokes)直接预测局部运动分布,实现对场景动态的多模态建模。FPT采用Transformer架构,将每个poke和查询点视为独立token,通过自注意力机制处理稀疏序列,并通过交叉注意力融合图像特征。模型输出高斯混合模型(GMM)参数,直接表征运动的多模态分布及不确定性,支持在25ms内完成单次预测,吞吐量达每秒160k次,适用于实时场景。
FPT的核心创新在于:1)多模态分布预测,通过全协方差矩阵建模实现运动方向不确定性表征;2)稀疏运动建模,聚焦关键交互点提升效率;3)泛化能力,基于3.8M WebVid视频预训练,可迁移至人脸/物体等特定领域;4)显式不确定性建模,预测误差与不确定性呈现0.64 Pearson相关性。实验表明,FPT在人脸运动生成任务中EPE达7.64(InstantDrag为9.24),在合成数据集上微调后articulated object运动估计EPE低至3.57(DragAPart为9.69),移动部分分割mIoU达0.572(DragAPart为0.273)。该方法通过KL散度量化运动依赖关系,直接支持移动部分分割等下游任务,为物理交互理解提供了高效、可解释的解决方案。
论文来源:hf
Hugging Face 投票数:5
论文链接:
https://hf.co/papers/2510.12777
PaperScope.ai 解读:
https://paperscope.ai/hf/2510.12777
(46) Rethinking Visual Intelligence: Insights from Video Pretraining
论文 ID:2510.24448
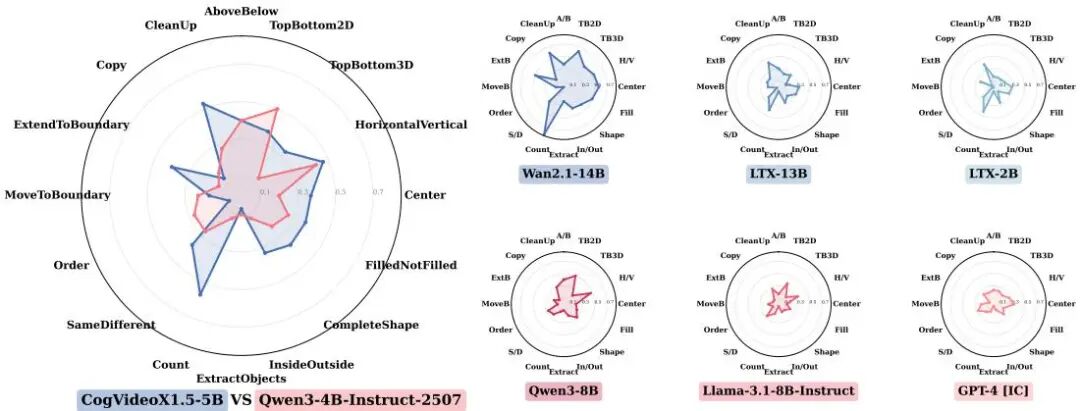
论文简介:
由伯尔尼大学计算机视觉组与EPFL VITA实验室等机构提出了基于视频预训练的视觉智能研究该工作通过对比视频扩散模型(VDMs)与大型语言模型(LLMs)在视觉任务上的适应能力揭示了视频预训练对提升视觉基础模型性能的关键作用研究者将图像到图像的任务转换为视频序列形式利用VDMs在时空数据上预训练获得的归纳偏置通过LoRA模块进行参数高效微调在ARC-AGIConceptARC视觉游戏路径规划和细胞自动机等多类任务中VDMs展现出显著更高的数据效率在仅2-5个示例的ARC任务中CogVideoX1.5-5B达到16.75%的双尝试准确率优于同规模LLMs在数独迷宫等结构化任务中VDMs的准确率提升幅度达2-10倍在细胞自动机预测任务中对复杂空间模式的捕捉能力也明显优于LLMs实验表明视频预训练赋予的时空结构先验使VDMs在需要空间推理和动态建模的任务中具有独特优势为构建兼具生成能力和问题解决能力的视觉基础模型提供了新路径该研究通过统一的任务适配框架和严格控制的对比实验验证了模态对齐预训练对视觉智能发展的重要性
论文来源:hf
Hugging Face 投票数:5
论文链接:
https://hf.co/papers/2510.24448
PaperScope.ai 解读:
https://paperscope.ai/hf/2510.24448
(47) BindWeave: Subject-Consistent Video Generation via Cross-Modal Integration
论文 ID:2510.00438

论文简介:
由中科大与字节跳动等机构提出了BindWeave,该工作针对现有视频生成模型在复杂多主体场景中身份一致性不足的问题,提出了一种基于跨模态整合的主体一致性视频生成框架。核心创新在于构建了MLLM-DiT结构,通过预训练多模态大语言模型对文本指令与参考图像进行深度语义解析,将空间关系、时间逻辑和主体交互解耦为角色、属性及交互特征,并生成主体感知的隐藏状态作为扩散Transformer的条件输入。具体实现中,通过统一的多模态序列输入,使MLLM完成实体绑定与关系建模,结合CLIP图像特征与VAE细节特征形成多层级条件引导,在扩散过程中同步注入高层语义、身份锚点和低层外观细节。在OpenS2V基准测试中,该方法在身份一致性(NexusScore)、自然度(NaturalScore)和文本相关性(GmeScore)等指标上全面超越现有开源模型与商业产品,尤其在多主体复杂交互场景中展现出显著优势,有效解决了身份混淆、动作错位和属性融合等问题,为定制化视频生成提供了兼具保真度与可控性的新范式。
论文来源:hf
Hugging Face 投票数:4
论文链接:
https://hf.co/papers/2510.00438
PaperScope.ai 解读:
https://paperscope.ai/hf/2510.00438
(48) Track, Inpaint, Resplat: Subject-driven 3D and 4D Generation with Progressive Texture Infilling
论文 ID:2510.23605

论文简介:
由多伦多大学、Vector Institute和Snap Inc.等机构提出了Track, Inpaint, Resplat (TIRE),该工作通过渐进式纹理填充实现主题驱动的3D/4D生成,显著提升了多视角内容的身份一致性。当前3D/4D生成方法在文本或单图像引导下难以保持主体身份跨视角的一致性,TIRE通过三阶段流水线解决这一挑战:首先利用视频跟踪技术定位需要填充的未见区域,随后采用定制化2D修复模型进行分层纹理填充,最后将修复后的多视角观测结果一致地反投影回3D空间。该方法创新性地结合2D视频跟踪与修复技术,通过逆向跟踪生成更精准的填充掩码,并通过渐进式修复策略从近视角到远视角逐步优化身份一致性。实验表明,TIRE在DreamBooth-Dynamic基准数据集上显著优于L4GM、TRELLIS等最新方法,不仅在身份保留指标上提升15.7%,几何质量也得到增强。该工作为个性化3D/4D内容生成提供了新范式,其与现有生成模型的互补性为行业应用开辟了新路径。
论文来源:hf
Hugging Face 投票数:4
论文链接:
https://hf.co/papers/2510.23605
PaperScope.ai 解读:
https://paperscope.ai/hf/2510.23605
(49) Ponimator: Unfolding Interactive Pose for Versatile Human-human Interaction Animation
论文 ID:2510.14976

论文简介:
由伊利诺伊大学厄巴纳-香槟分校和Snap Inc.等机构提出的Ponimator,通过构建基于近距交互姿态的简单框架,实现了多功能人类互动动画生成。该工作利用动作捕捉数据中的交互姿态先验,采用两个条件扩散模型:姿态动画师利用时间先验从交互姿态生成动态序列,姿态生成器则通过空间先验从单姿态、文本或组合输入合成交互姿态。该方法支持图像驱动互动动画、反应动画和文本到交互合成等任务,成功将高质量动捕数据中的互动知识迁移至开放世界场景。实验表明,其姿态先验具有通用性,在跨数据集和跨场景应用中展现出有效性与鲁棒性。论文核心贡献包括:1) 提出基于交互姿态动力学先验的动画框架;2) 验证了先验在开放世界图像中的可迁移性;3) 实现多模态输入的交互姿态生成与动画合成,为虚拟交互内容创作提供了新思路。
论文来源:hf
Hugging Face 投票数:3
论文链接:
https://hf.co/papers/2510.14976
PaperScope.ai 解读:
https://paperscope.ai/hf/2510.14976
(50) Bridging Text and Video Generation: A Survey
论文 ID:2510.04999

论文简介:
由SRM Institute of Science and Technology等机构提出了Bridging Text and Video Generation: A Survey,该工作系统回顾了文本到视频生成模型的发展,从早期的GAN和VAE到当前的扩散-Transformer架构,分析了各模型的内部机制、解决的局限性及架构转变的原因,并详细介绍了常用数据集、训练配置、评估指标及未来方向。研究指出,文本到视频生成技术在教育、营销、娱乐等领域具有变革潜力,但仍面临对齐、长程一致性及计算效率等挑战。论文梳理了从MoCoGAN、VideoGPT到LaVie、CogVideoX等代表性模型的技术演进,强调扩散模型在生成质量与时序一致性上的优势。针对数据集,重点分析了WebVid-10M、UCF-101、HowTo100M等12个关键数据集的规模与特性,并总结了各模型的GPU配置、学习率、优化器等训练参数。评估方面,对比了Inception Score、FVD、CLIP-SIM等指标在MSRVTT、Kinetics-600等基准上的表现,同时指出传统指标在捕捉人类感知层面的不足,提出VBench等多维度评估框架。未来方向包括基于游戏引擎的合成数据生成、优化模型架构以提升长视频生成能力、增强物理交互真实性,以及拓展教育、文化保护等应用场景。研究强调,通过数据增强、跨模态融合与计算效率优化,文本到视频技术有望实现更高质量、更长时序的生成效果,并推动多行业内容创作革新。
论文来源:hf
Hugging Face 投票数:3
论文链接:
https://hf.co/papers/2510.04999
PaperScope.ai 解读:
https://paperscope.ai/hf/2510.04999
(51) SCas4D: Structural Cascaded Optimization for Boosting Persistent 4D Novel View Synthesis
论文 ID:2510.06694

论文简介:
由伊利诺伊大学厄巴纳-香槟分校等机构提出了SCas4D,该工作提出了一种结构级联优化框架,通过挖掘3D高斯泼溅(3DGS)的内在结构模式,实现动态场景的高效建模。核心贡献在于:1)利用现实世界变形的层次化特性,通过从粗到细的多级变形优化策略,将训练迭代次数从2000次降至100次,实现20倍加速;2)设计包含旋转、平移和缩放的多层变形函数,通过K-means聚类构建3层级联结构,兼顾效率与细节捕捉;3)首次展示3DGS方法在自监督可动对象分割上的潜力,仅通过运动模式即可实现精准分割。
该方法在FastParticle和Panoptic数据集上验证,100次迭代即可达到与现有方法2000次迭代相当的渲染质量(PSNR提升0.7-8.4dB),同时2D中位轨迹误差降低70%。其核心创新在于:1)将高斯点按运动模式分层聚类,先优化整体形变再细化局部调整;2)引入显式变形参数化(旋转四元数+平移向量+缩放矩阵);3)通过变形函数嵌套实现跨层级形变传递。实验表明,该方法在保持点级跟踪精度的同时,首次实现了无需语义标注的可动部件分割,为动态场景理解提供了新思路。项目代码与可视化结果已开源。
论文来源:hf
Hugging Face 投票数:2
论文链接:
https://hf.co/papers/2510.06694
PaperScope.ai 解读:
https://paperscope.ai/hf/2510.06694
(52) How Confident are Video Models? Empowering Video Models to Express their Uncertainty
论文 ID:2510.02571

论文简介:
由普林斯顿大学等机构提出了How Confident are Video Models? Empowering Video Models to Express their Uncertainty,该工作首次探索视频生成模型的不确定性量化问题,提出包含三个核心组件的框架:基于稳健秩相关估计的视频模型校准评估指标、通过潜在空间建模分解aleatoric与epistemic不确定性的黑盒UQ方法S-QUBED、以及包含4万视频的UQ基准数据集。研究通过在潜在空间条件生成任务,将模糊任务规范导致的不确定性与知识缺失导致的不确定性解耦,利用Von-Mises Fisher分布建模潜在提示分布,通过蒙特卡洛采样近似计算两种不确定性分量。实验表明S-QUBED的总不确定性估计与任务准确率呈显著负相关(Panda-70M数据集99%置信水平),在低aleatoric/epistemic不确定性样本中分别实现94.5%/98.3%和92.3%/91.7%的秩相关显著性,验证了方法的有效性。该研究为视频生成模型的可信性评估提供了首个系统性解决方案,其开源数据集和方法将推动生成式AI在安全敏感场景的应用发展。
论文来源:hf
Hugging Face 投票数:2
论文链接:
https://hf.co/papers/2510.02571
PaperScope.ai 解读:
https://paperscope.ai/hf/2510.02571
(53) Drive&Gen: Co-Evaluating End-to-End Driving and Video Generation Models
论文 ID:2510.06209

论文简介:
由Google Research、Waymo、UC Berkeley等机构提出了Drive&Gen框架,该工作通过协同评估端到端驾驶模型与视频生成模型,解决了自动驾驶领域两大关键技术的核心挑战。研究团队创新性地提出行为置换检验(BPT)指标,利用端到端规划器的轨迹响应差异量化生成视频的真实性,突破了传统FVD等分布匹配指标无法反映动态交互真实性的局限。实验表明,该方法在保持69.62%的BPT通过率(理论上限95%)的同时,揭示了场景布局信息(bounding box和road map)对规划器性能的关键作用(移除后ADE@5s从0.8594激增至1.1216)。通过精准控制光照(太阳方位角编码)、天气等操作设计域(ODD)参数,研究系统性分析了规划器在雨夜等极端条件下的性能衰减(雨天ADE@5s增加2.3%),并验证了合成数据增强的有效性——在真实数据基础上加入百万级合成视频微调后,规划器在5秒预测上的平均位移误差从0.7548降至0.7333,雨夜场景性能提升尤为显著(夜间的5秒误差降低3.7%)。这项工作不仅建立了生成模型与驾驶模型的双向评估体系,更展示了可控视频生成技术在降低路测成本、提升自动驾驶泛化能力方面的巨大潜力,为构建更安全可靠的自动驾驶系统提供了新范式。
论文来源:hf
Hugging Face 投票数:2
论文链接:
https://hf.co/papers/2510.06209
PaperScope.ai 解读:
https://paperscope.ai/hf/2510.06209
(54) Point Prompting: Counterfactual Tracking with Video Diffusion Models
论文 ID:2510.11715

论文简介:
由密歇根大学和康奈尔大学提出了Point Prompting,该工作通过视觉提示策略实现视频扩散模型的零样本点跟踪。研究发现,预训练视频生成模型能够通过在初始帧添加彩色标记点并进行扩散再生,将标记沿时间轴传播形成轨迹,从而完成对运动点的追踪。核心创新在于采用负提示机制,以未编辑初始帧作为引导,确保生成视频中异常标记的可见性。实验表明,该方法在TAPVid基准测试中显著超越现有零样本跟踪方法,其物体持久性能力甚至接近自监督模型水平。研究还提出颜色再平衡和迭代细化等优化策略,通过抑制背景干扰色和局部区域重生成提升跟踪精度。值得注意的是,该方法无需额外训练,直接复用Wan2.1等现成视频生成模型即可实现,验证了生成模型在运动分析任务中的潜力,为视频生成与跟踪任务的统一提供了新思路。
论文来源:hf
Hugging Face 投票数:2
论文链接:
https://hf.co/papers/2510.11715
PaperScope.ai 解读:
https://paperscope.ai/hf/2510.11715
(55) MultiCOIN: Multi-Modal COntrollable Video INbetweening
论文 ID:2510.08561

论文简介:
由西蒙弗雷泽大学和Adobe Research提出了MultiCOIN,该工作针对视频中间帧生成任务引入了多模态可控框架,支持深度变化、运动轨迹、文本提示和目标区域等多样化控制方式。通过采用Diffusion Transformer(DiT)生成模型,将多模态控制信号统一映射为点表示作为视频/噪声输入,创新性地设计内容与运动双分支编码结构,并配合阶段式训练策略,实现了复杂运动场景下兼具灵活性与精准性的视频插帧效果。实验表明,该方法在DAVIS和UCF数据集上相较基线模型Framer,运动轨迹对齐误差降低50%以上,同时保持了高质量视频生成能力,为用户提供了从粗粒度运动引导到细粒度区域控制的完整解决方案,推动了可控视频生成技术的发展。
论文来源:hf
Hugging Face 投票数:1
论文链接:
https://hf.co/papers/2510.08561
PaperScope.ai 解读:
https://paperscope.ai/hf/2510.08561
(56) DriveGen3D: Boosting Feed-Forward Driving Scene Generation with Efficient Video Diffusion
论文 ID:2510.15264

论文简介:
由GigaAI、浙江大学、清华大学等机构提出了DriveGen3D,该工作提出了一种高效生成动态3D驾驶场景的框架,通过整合加速视频扩散模型与实时3D重建模块,解决了现有方法在长时序视频生成与大规模场景重建中的效率瓶颈。DriveGen3D包含两个核心组件:FastDrive-DiT采用扩散步缓存和量化注意力机制,在保持视觉质量的前提下实现超过2倍的视频生成加速,支持424×800分辨率、12FPS的长时驾驶视频生成;FastRecon3D基于时间感知高斯溅射技术,通过多帧上下文融合实现动态场景的快速3D重建,在生成视频输入下达到SSIM 0.811和PSNR 22.84的重建精度。实验表明,该框架将端到端生成时间缩短至6分钟内,相较传统优化方法提升80%效率,同时通过多模态条件控制(文本与鸟瞰图布局)实现高可控性场景生成。该方法在nuScenes数据集上验证了视频生成与3D重建的同步性能优势,为自动驾驶仿真与动态环境建模提供了新的技术路径。
论文来源:hf
Hugging Face 投票数:1
论文链接:
https://hf.co/papers/2510.15264
PaperScope.ai 解读:
https://paperscope.ai/hf/2510.15264
(57) Stable Cinemetrics : Structured Taxonomy and Evaluation for Professional Video Generation
论文 ID:2509.26555
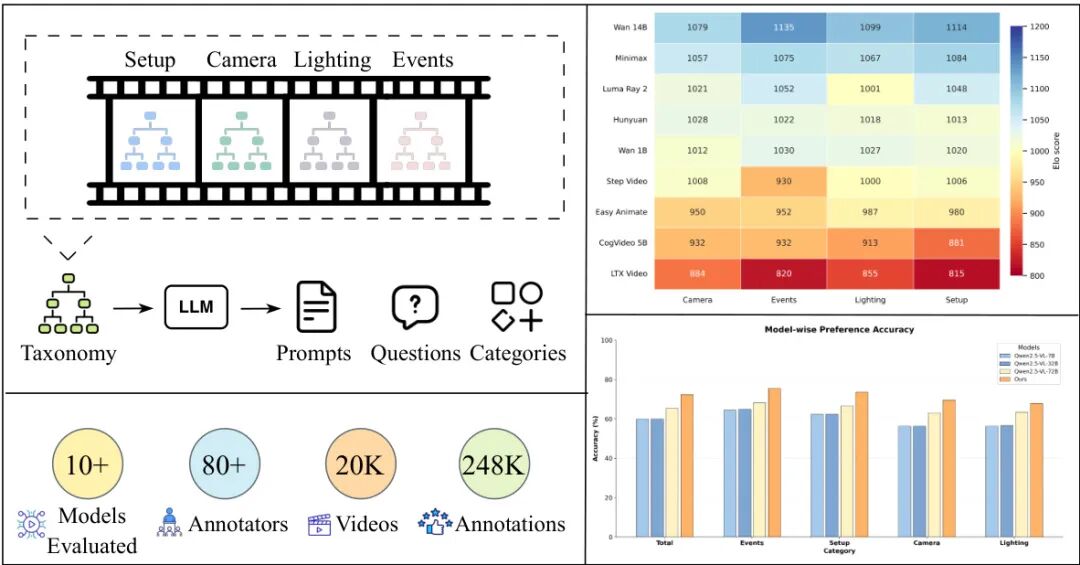
论文简介:
由 Stability AI、亚利桑那州立大学和 Google DeepMind 等机构提出了 Stable Cinemetrics,该工作提出了一种结构化的评估框架,将电影制作控制形式化为四个解耦的层次化分类法:Setup、Event、Lighting 和 Camera,共包含 76 个细粒度控制节点。这些分类法基于行业实践定义了专业视频生成所需的核心控制维度,并构建了对齐专业用例的提示词基准,开发了自动化的问题生成流程以支持对每个控制维度的独立评估。研究团队通过涵盖 10+ 模型和 2 万条视频的大规模人类评估发现,即使是当前最强模型(如 WAN-14B 和 Minimax)在 Event 和 Camera 相关控制上仍存在显著不足。为实现可扩展评估,团队训练了一个与专家标注对齐的视觉语言模型(VLM),其在二元偏好任务中达到 72.36% 的准确率,较零样本基线提升约 20%。该工作首次将专业视频生成置于生成式视频模型的研究框架内,通过控制导向的分类法、结构化评估流程和详细分析为未来研究指明方向,同时开发的 VLM 为新模型的持续评估提供了可扩展工具。研究揭示了当前文本到视频模型在专业级控制上的主要瓶颈,特别是在时序事件一致性、灯光定位精度和镜头语言表达等方面,强调了定制化微调对实现工业应用的必要性。
论文来源:hf
Hugging Face 投票数:0
论文链接:
https://hf.co/papers/2509.26555
PaperScope.ai 解读:
https://paperscope.ai/hf/2509.26555
论文解读由 Intern-S1 生成!




