大家好我是 「PaperScope.ai | P 站站长」闻星,10 月有 945 篇论文提交到 Hugging Face Daily Paper,本文我们来看看「Code」方向的部分论文。
JanusCoder: Towards a Foundational Visual-Programmatic Interface for Code Intelligence
论文 ID:2510.23538
论文简介:
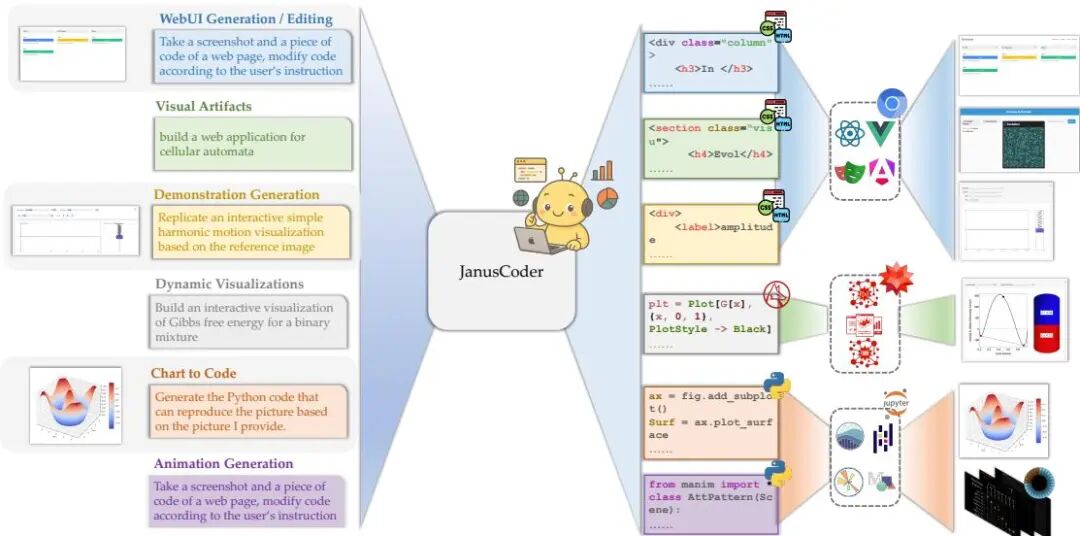
由香港大学、上海人工智能实验室、南京大学、卡内基梅隆大学等机构提出了JanusCoder,该工作构建了首个面向代码智能的视觉-程序统一接口,通过创新性数据合成工具包和跨模态协同机制,在文本驱动与视觉驱动的代码生成任务上均达到领先水平,7B至14B参数模型性能接近甚至超越商业模型。研究团队开发了包含多策略合成引擎的数据生成工具包,通过指导性演化、上下文重构、逆向指令生成和双向翻译等策略,构建了包含80万样本的JanusCode-800K多模态数据集,覆盖Python可视化、WebUI、科学计算、动画生成等12类任务。基于该数据集训练的JanusCoder系列模型,采用Qwen3和InternVL3.5作为文本与视觉基座,通过跨域知识迁移实现文本指令到代码、视觉输入到代码、混合模态到代码的统一生成能力。在PandasPlotBench、ArtifactsBench等7个基准测试中,JanusCoder-14B在文本驱动任务中错误率低于10%,视觉相似度达67%,任务完成度86%;JanusCoderV-7B在图表转代码任务中关键指标超越GPT-4o达7.6个百分点,在网页生成任务中代码结构相似度提升13.2%。研究还提出动态定理可视化基准测试DTVBench,通过Manim和Wolfram引擎评估模型生成数学动画的能力,JanusCoder系列在代码质量与视觉保真度上均显著优于现有模型。实验表明,跨模态数据协同可使动画生成任务性能提升18.7%,奖励模型筛选机制对视觉内容质量提升贡献达23.4%。该工作为多模态代码智能研究提供了完整的数据、模型与评估体系,其开源代码和模型权重已通过GitHub发布。
论文来源:hf
Hugging Face 投票数:90
论文链接:
https://hf.co/papers/2510.23538
PaperScope.ai 解读:
https://paperscope.ai/hf/2510.23538
Diff-XYZ: A Benchmark for Evaluating Diff Understanding
论文 ID:2510.12487

论文简介:
由 JetBrains Research 等机构提出了 Diff-XYZ,该工作构建了一个用于评估代码差异(diff)理解能力的轻量级基准测试。研究者设计了 Apply(应用补丁)、Anti-Apply(逆向还原)和 Diff Generation(差异生成)三个监督任务,通过真实代码提交数据构建了包含1000个实例的测试集,每个实例包含旧代码、新代码和对应的 diff 三元组。实验表明 diff 格式的选择对模型性能有显著影响:Claude 4 Sonnet 和 GPT-4.1 等闭源模型在统一 diff 格式下表现最佳,而开源模型需达到7B参数量级才能接近商用模型水平。研究还对比了 udiff、udiff-h、udiff-l 和 search-replace 四种格式,发现 search-replace 格式在 Diff Generation 任务中表现突出,但 udiff 类格式在 Apply/Anti-Apply 任务中更可靠。特别值得注意的是,移除行号的 udiff-h 格式反而导致性能显著下降,揭示了格式设计中潜在的分布偏移问题。该基准测试为优化代码编辑模型和 diff 格式设计提供了可复现的评估框架,数据集已开源至 HuggingFace 平台。
论文来源:hf
Hugging Face 投票数:8
论文链接:
https://hf.co/papers/2510.12487
PaperScope.ai 解读:
https://paperscope.ai/hf/2510.12487
Regression Language Models for Code
论文 ID:2509.26476

论文简介:
由Cornell University和Google等机构提出了Regression Language Models (RLMs),该工作提出了一种统一的代码到指标预测方法,通过基于文本的回归语言模型直接从代码文本中预测执行结果的数值指标(如内存占用、GPU内核延迟、神经网络准确性等)。研究发现,基于T5Gemma初始化的3亿参数RLM在APPS数据集上实现超过0.9的Spearman秩相关系数,并在CodeNet的17种编程语言中取得平均0.5以上的预测性能。在神经架构搜索(NAS)任务中,RLM通过处理ONNX图表示,在5个经典设计空间中取得平均0.46的Kendall-Tau系数,超越图神经网络方法。模型通过统一的文本输入格式和解码器输出设计,实现了跨编程语言、编译层级和硬件平台的多目标预测能力(如同时预测不同硬件上的延迟)。消融实验表明,语言模型预训练和合成数据预训练显著提升收敛速度,解码器输出的数字标记化设计优于传统回归头,且更大的编码器参数量(如6亿参数)可进一步提升性能。该工作为代码性能预测、硬件-软件协同设计和编译器优化提供了通用解决方案,验证了语言模型在代码回归任务中的有效性。
论文来源:hf
Hugging Face 投票数:16
论文链接:
https://hf.co/papers/2509.26476
PaperScope.ai 解读:
https://paperscope.ai/hf/2509.26476
ReCode: Unify Plan and Action for Universal Granularity Control
论文 ID:2510.23564

论文简介:
由 DeepWisdom、香港科技大学(广州)、中国人民大学、浙江大学和蒙特利尔大学等机构提出了 ReCode,该工作通过递归代码生成统一规划与行动,实现决策粒度的灵活控制。现有大语言模型代理框架因严格区分高阶规划与低阶行动,导致决策适应性受限。ReCode 将计划与行动统一为代码表示,将高层计划视为抽象占位函数,通过递归机制将其分解为细粒度子函数直至可执行的原始动作,从而消除规划与行动的边界。该方法在推理阶段显著提升任务性能(平均提升20.9%),在训练阶段通过生成多粒度层级数据实现数据效率优化(仅需ReAct 1/3数据量即可超越其性能)。实验在ALFWorld、WebShop、ScienceWorld三大复杂环境中验证,ReCode在推理成本降低78.9%的同时,对未见任务的泛化能力显著增强。其递归结构天然生成的决策树数据,为模型学习层级化推理提供了完整认知过程监督信号,为构建具备动态粒度控制能力的智能代理提供了新范式。
论文来源:hf
Hugging Face 投票数:115
论文链接:
https://hf.co/papers/2510.23564
PaperScope.ai 解读:
https://paperscope.ai/hf/2510.23564
LongCodeZip: Compress Long Context for Code Language Models
论文 ID:2510.00446

论文简介:
由上海交通大学、斯坦福大学和重庆大学等机构提出了LongCodeZip,该工作针对代码大模型在长上下文场景下的处理瓶颈,提出了一种双阶段代码压缩框架。通过结合函数级粗粒度选择与块级细粒度压缩,该方法利用困惑度评估代码段与任务指令的相关性,在保留关键语义信息的同时实现高达5.6倍的压缩比,显著提升代码生成任务的效率与性能。
LongCodeZip采用两阶段策略:首先通过困惑度排序筛选与任务指令最相关的函数级代码块,再基于自适应预算分配和0/1背包算法对保留函数进行细粒度块级压缩。实验表明,该方法在代码补全、摘要生成和代码问答任务中均优于LLMLingua等基线方法。在保持任务性能的前提下,其压缩后的上下文长度仅为原始输入的18%,且支持跨模型泛化,使用0.5B参数的轻量模型即可实现有效压缩。该框架的创新性在于首次针对代码结构特性设计压缩策略,通过困惑度引导的分块机制捕捉代码语义边界,同时通过动态预算分配平衡不同函数的重要性。实验证实其在降低API调用成本和生成延迟方面具有显著优势,为大模型处理大规模代码库提供了高效解决方案。
论文来源:hf
Hugging Face 投票数:107
论文链接:
https://hf.co/papers/2510.00446
PaperScope.ai 解读:
https://paperscope.ai/hf/2510.00446
A Survey of Vibe Coding with Large Language Models
论文 ID:2510.12399
论文简介:
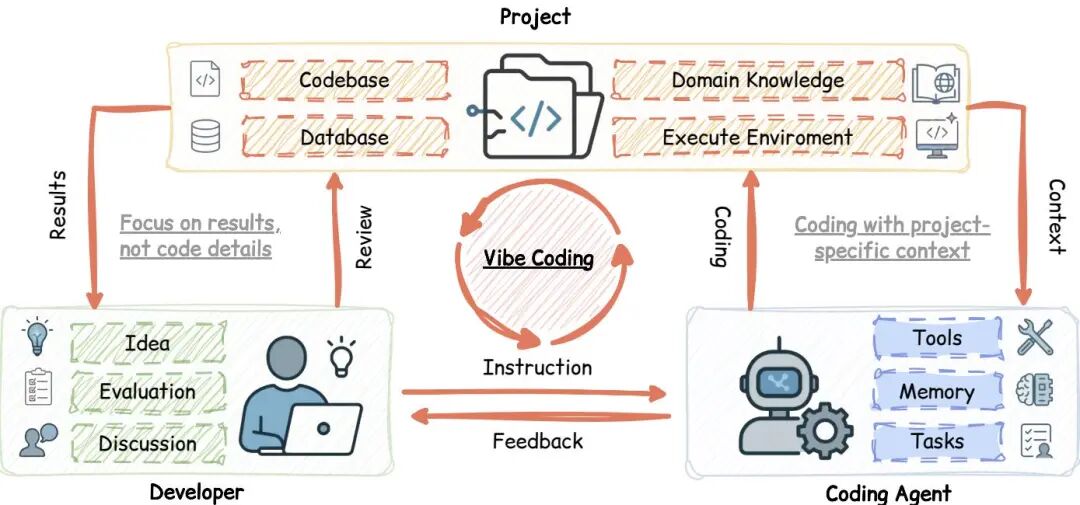
由中科院计算技术研究所、杜克大学等机构提出了Vibe Coding理论体系,该工作首次系统性构建了基于大语言模型的新型软件开发范式的理论框架与实践指南。论文通过分析1000余篇相关研究,从LLM代码生成基础、编码代理架构、开发环境构建到反馈机制设计四个维度展开深度综述,提出将Vibe Coding形式化为开发者(H)、软件项目(P)与编码代理(A)动态交互的Constrained MDP模型,揭示了三者间通过指令-反馈循环实现上下文感知编码与结果导向评审的协作本质。研究创新性地将Vibe Coding实践归纳为无约束自动化、迭代对话协作、规划驱动、测试驱动及上下文增强等五类开发模型,并发现其成功关键不仅在于代理能力,更依赖系统化的上下文工程、开发环境构建及人机协作模式设计。论文系统梳理了LLM代码生成数据基础(Stack、CodeParrot等数据集)、预训练技术(掩码语言建模、自回归建模、结构感知目标等)及后训练策略(指令微调、强化学习、参数高效微调),并深入剖析了代理系统的任务分解策略(链式思维、树状思维)、记忆机制(短时记忆管理、长时记忆存储)、工具调用范式(代码化动作执行)及多代理协作架构。研究指出Vibe Coding面临的技术挑战包括基础设施优化、安全机制构建及人机协同设计,并强调开发流程重构、代码可靠性保障及人类因素研究对推动该领域发展的关键作用。该工作为AI增强软件工程提供了概念基础与技术路线图,对构建人机协同的智能开发范式具有重要指导意义。
论文来源:hf
Hugging Face 投票数:47
论文链接:
https://hf.co/papers/2510.12399
PaperScope.ai 解读:
https://paperscope.ai/hf/2510.12399
CoDA: Coding LM via Diffusion Adaptation
论文 ID:2510.03270

论文简介:
由 Salesforce AI Research 等机构提出了 CoDA,该工作开发了一款1.7B参数的轻量级扩散语言模型(DLM),通过高效的TPU训练流程实现代码生成任务的突破。CoDA 基于 Qwen3-1.7B 架构,创新性地将大规模扩散预训练与代码专项中期训练、指令微调相结合,采用渐进式掩码策略(包含不可掩码前缀、截断后缀和块掩码)提升模型对提示依赖、变长输入和代码填充任务的适应性。在 Humaneval 和 MBPP 基准测试中,CoDA-1.7B-Instruct 的 pass@1 得分达到54.3% 和47.2%,超越同类规模扩散模型并逼近7B参数量级的 Dream-7B-Instruct,同时推理延迟降低39.64%。研究团队开源了模型权重、评估工具链和TPU训练框架,首次验证了1.7B参数扩散模型在代码生成领域的可行性,为轻量化扩散模型研究提供了完整的技术路径。实验表明,通过置信度引导采样策略,CoDA 在512步扩散过程中即可实现性能饱和,为实际部署中的效率优化提供了关键依据。
论文来源:hf
Hugging Face 投票数:42
论文链接:
https://hf.co/papers/2510.03270
PaperScope.ai 解读:
https://paperscope.ai/hf/2510.03270
PIPer: On-Device Environment Setup via Online Reinforcement Learning
论文 ID:2509.25455
论文简介:
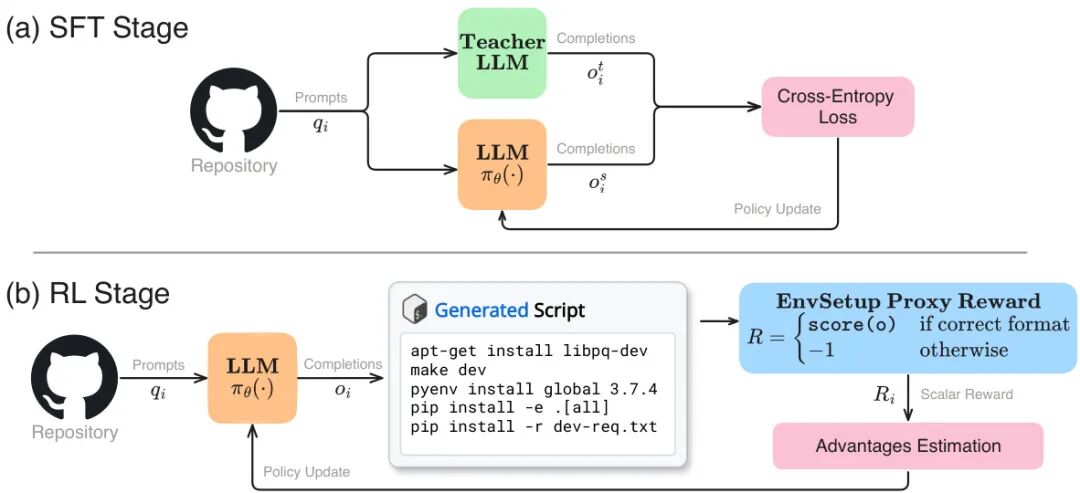
由JetBrains Research等机构提出了PIPer,该工作针对软件工程中环境配置的挑战,提出结合监督微调(SFT)与在线强化学习(RLVR)的轻量级解决方案。研究者通过分析GPT-4o在EnvBench生成的脚本,发现模型主要存在依赖冲突、可选依赖缺失等11类错误,进而设计了基于LLM-as-a-Judge的可验证奖励函数。该方法先通过SFT蒸馏Qwen3-32B生成的优质脚本,再采用Reinforce++算法进行RL训练,使8B参数的Qwen3-8B模型在EnvBench上达到与32B模型相当的性能(pass@5=27 vs 29),且推理成本降低14倍。实验表明,PIPer在Repo2Run数据集上超越Qwen3-32B(103 vs 71),但多轮交互的Terminal-Bench表现仍存差距。该研究首次验证了在线RL在环境配置任务的有效性,通过设备端模型实现了与商业大模型相当的性能,其代码和模型已开源。
论文来源:hf
Hugging Face 投票数:35
论文链接:
https://hf.co/papers/2509.25455
PaperScope.ai 解读:
https://paperscope.ai/hf/2509.25455
BigCodeArena: Unveiling More Reliable Human Preferences in Code Generation via Execution
论文 ID:2510.08697

论文简介:
由Monash University、CSIRO's Data61、Purdue University等机构提出了BigCodeArena,该工作构建了一个基于实时执行反馈的代码生成评估平台,通过动态执行和交互式调试机制,显著提升了人类对LLM生成代码质量判断的可靠性。平台部署5个月收集了14K多轮对话数据,涵盖10种编程语言和8种执行环境,其中4.7K样本包含多轮人类偏好标注。研究发现执行反馈使奖励模型在代码评估一致性上平均提升5.6%,Proprietary模型如GPT-5、Claude-3.5-Sonnet在AutoCodeArena基准中保持领先优势。平台创新性地支持React、PyGame等交互式环境评估,揭示了不同模型在Web开发、科学计算等场景的能力差异,同时开源了BigCodeReward和AutoCodeArena两个基准,前者用于评估奖励模型与人类偏好的对齐度,后者通过LLM-as-a-Judge实现自动化代码评估。实验表明执行结果(如UI截图)使92%的奖励模型评估准确率提升,其中GPT-4o-mini在图表生成任务中准确率提升达21.3%。该工作通过Execution-Aware Evaluation范式,为代码生成领域建立了可持续追踪前沿模型进展的开放评估体系。
论文来源:hf
Hugging Face 投票数:33
论文链接:
https://hf.co/papers/2510.08697
PaperScope.ai 解读:
https://paperscope.ai/hf/2510.08697
Code2Video: A Code-centric Paradigm for Educational Video Generation
论文 ID:2510.01174

论文简介:
由新加坡国立大学Show Lab等机构提出了Code2Video,该工作提出了一种基于可执行Python代码的教育视频生成框架,通过Planner-Coder-Critic三代理协作实现时空结构可控的代码驱动生成。核心贡献包括:1)首创代码驱动的教育视频生成范式,将逻辑指令转化为可复现的Manim代码;2)设计具备并行代码生成、范围引导修复的Coder模块,以及基于视觉锚点提示的Critic模块;3)构建包含13个学科领域456个视频的MMMC基准,提出TeachQuiz等多维评估指标,实验证明该方法在知识传递效率上较直接代码生成提升40%,生成视频质量接近人类专家作品。
该框架通过Planner将学习主题分解为带视觉资产的分镜脚本,Coder基于并行合成和范围引导修复生成可执行代码,Critic利用6×6网格视觉锚点提示优化布局。在MMMC基准测试中,Code2Video在元素布局、逻辑流等美学维度得分较像素级扩散模型提升50%以上,TeachQuiz知识传递指标较直接代码生成提升40%。消融实验表明,规划模块对知识传递效果影响最大(下降41.5分),视觉锚点和外部数据库分别贡献10.9和26.8分提升。与人类制作的3Blue1Brown视频相比,该方法在保持时空连贯性的同时,生成效率提升30倍以上,为教育视频自动化生成提供了可扩展的解决方案。
论文来源:hf
Hugging Face 投票数:33
论文链接:
https://hf.co/papers/2510.01174
PaperScope.ai 解读:
https://paperscope.ai/hf/2510.01174
(10) QueST: Incentivizing LLMs to Generate Difficult Problems
论文 ID:2510.17715

论文简介:
由苏黎世大学和微软研究院提出的QueST框架,通过结合难度感知图采样和难度感知拒绝微调技术,首次实现了直接训练LLM生成具有挑战性的编程问题。该方法通过构建包含100K个高难度编程问题的合成数据集,显著提升了小型模型在代码推理任务上的表现。实验表明,基于Qwen3-8B-Base训练的QueST-8B模型在LiveCodeBench上达到65.2分,接近DeepSeek-R1-671B的65.6分,同时在USACO基准上也实现了49.9%的准确率。研究创新性地通过模型响应的一致性评估问题难度,并采用难度感知的图采样策略优化生成器。生成的合成数据既可用于蒸馏训练(如用Qwen3-235B-A22B的长链式推理响应指导学生模型),也可用于强化学习场景。与OpenCodeReasoning等现有方法相比,QueST生成的数据在保持更短响应长度的同时实现了更高的任务难度和模型性能提升,验证了规模化生成高难度问题的有效性。该成果为解决大模型训练中人工标注数据稀缺问题提供了新范式,推动了代码推理任务的前沿发展。
论文来源:hf
Hugging Face 投票数:31
论文链接:
https://hf.co/papers/2510.17715
PaperScope.ai 解读:
https://paperscope.ai/hf/2510.17715
Vibe Checker: Aligning Code Evaluation with Human Preference
论文 ID:2510.07315
论文简介:
由加州大学洛杉矶分校、谷歌、微软等机构提出了Vibe Checker,该工作针对代码生成领域中现有评估方法过度依赖功能性正确性(pass@k指标)而忽视非功能性用户偏好的问题,提出了一套可验证的代码指令分类法VeriCode,并构建了包含功能性测试和指令遵循能力评估的Vibe Checker测试平台。研究发现:1)非功能性指令会导致功能性正确性显著下降,添加5条指令时平均功能回归率达5.85%-6.61%;2)模型难以同时满足多指令约束,5条指令时任务级指令遵循率仅40%-45%;3)交互模式影响表现,单轮生成更保功能,多轮编辑更易遵循指令;4)用户偏好与功能正确性和指令遵循的组合呈现强相关(最优加权系数达0.5-0.7),其中现实编程场景更看重指令遵循,算法题场景更关注功能正确性。该工作通过系统性实验证明,代码质量评估需同时考量功能性与非功能性维度,为开发更贴近真实需求的代码生成模型提供了新的评估框架和优化方向。
论文来源:hf
Hugging Face 投票数:30
论文链接:
https://hf.co/papers/2510.07315
PaperScope.ai 解读:
https://paperscope.ai/hf/2510.07315
TokDrift: When LLM Speaks in Subwords but Code Speaks in Grammar
论文 ID:2510.14972
论文简介:
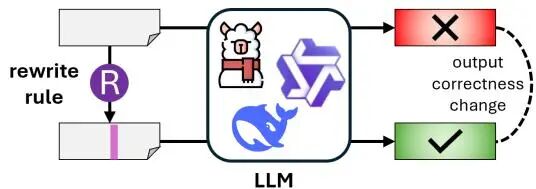
由多伦多大学等机构提出了TokDrift,该工作研究了大语言模型(LLM)在代码理解与生成中因子词分词器(如BPE)与编程语言语法不匹配导致的"分词漂移"问题。研究发现,LLM常用的基于统计的子词分词策略会将语义相同的代码切分为不同的子词序列(如添加空格或修改标识符命名风格),这种表面格式变化会导致模型预测结果显著波动。作者构建了TokDrift框架,通过语义保持的代码重写规则(如驼峰命名转蛇形命名、插入运算符空格等)生成测试用例,系统评估了9个主流代码LLM模型在bug修复、代码摘要和代码翻译任务上的表现。实验显示,即使是最先进的300亿参数模型(如Qwen2.5-Coder-32B-Instruct),其预测结果仍有6.09%的概率因分词变化而改变,某些规则(如添加运算符空格)甚至导致8.27%的准确率下降。通过层间隐藏状态分析发现,这种敏感性源于早期嵌入层未能对齐语法词法边界,而模型规模增大虽能部分缓解但未根本解决该问题。研究强调了开发语法感知分词器的必要性,并开源了评估框架与数据集以推动领域发展。
论文来源:hf
Hugging Face 投票数:29
论文链接:
https://hf.co/papers/2510.14972
PaperScope.ai 解读:
https://paperscope.ai/hf/2510.14972
Sparser Block-Sparse Attention via Token Permutation
论文 ID:2510.21270
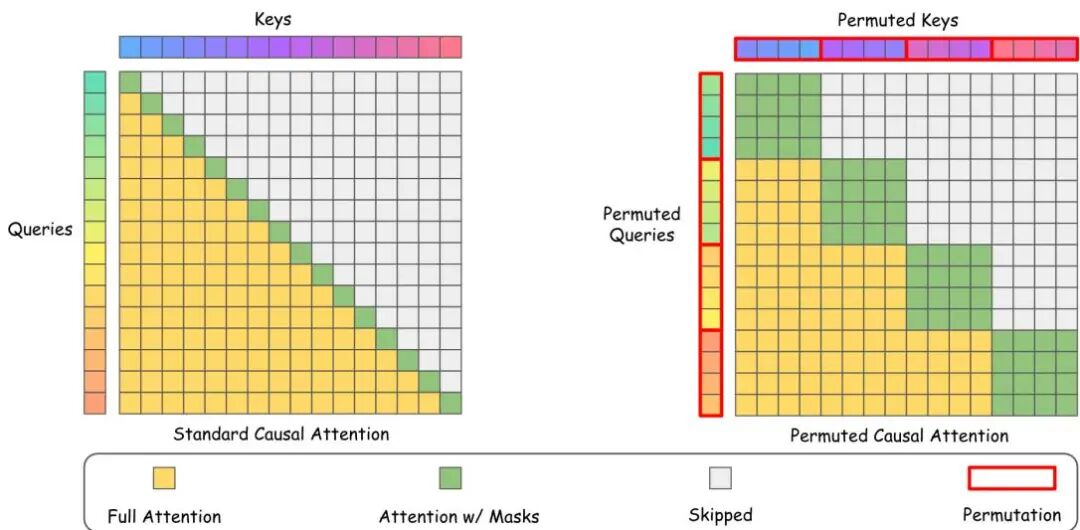
论文简介:
由复旦大学、中国联通、字节跳动等机构提出了Sparser Block-Sparse Attention via Token Permutation,该工作针对大语言模型(LLM)自注意力机制的二次复杂度瓶颈,提出Permuted Block-Sparse Attention(PBS-Attn)方法。通过利用注意力机制的排列不变性,该方法采用分段排列策略在保持因果性的前提下重构注意力矩阵,将查询和键序列进行块内重排序,使重要键值token在块内聚集,从而提升块级稀疏性。核心创新包括:1)提出分段排列策略,在保持段间因果关系的同时实现段内token重排;2)设计查询感知的键排列算法,通过最后一块查询估计键值重要性并排序;3)开发定制化permutedFlashAttention内核,实现高效稀疏计算。实验表明,PBS-Attn在LongBench和LongBenchv2等真实长文本数据集上,性能接近全注意力基线,同时在256K序列长度下实现2.75倍端到端推理加速。与Minference、FlexPrefill等主流稀疏注意力方法相比,PBS-Attn在保持更高准确率的同时,显著提升计算效率,为长上下文LLM部署提供了实用化解决方案。
论文来源:hf
Hugging Face 投票数:23
论文链接:
https://hf.co/papers/2510.21270
PaperScope.ai 解读:
https://paperscope.ai/hf/2510.21270
Agent Data Protocol: Unifying Datasets for Diverse, Effective Fine-tuning of LLM Agents
论文 ID:2510.24702
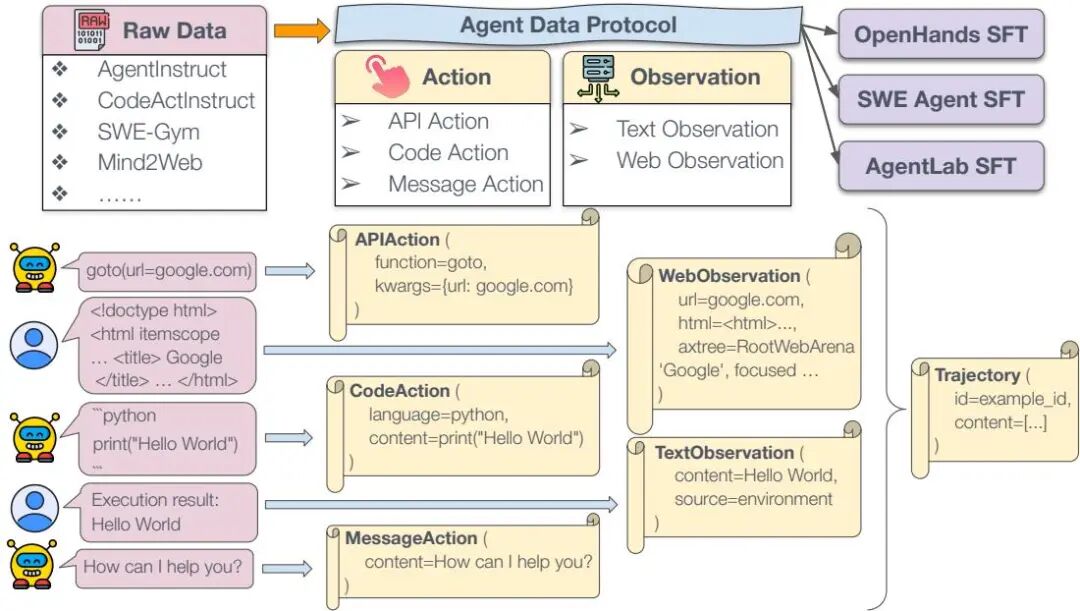
论文简介:
由卡内基梅隆大学等机构提出了Agent Data Protocol(ADP),该工作通过设计轻量级统一数据表示语言,有效解决了代理数据集碎片化问题。ADP采用Pydantic模式实现,将异构数据源中的API调用、代码执行、自然语言交互等动作类型,以及文本/Web环境观测数据标准化为Trajectory对象,包含交替排列的动作-观测序列和元数据字典。研究团队构建了覆盖编码、软件工程、工具调用和网页浏览等13个现有数据集的转换流水线,生成了包含130万条轨迹的ADP Dataset V1。实验表明,基于ADP训练的代理模型在SWE-Bench、WebArena等基准测试中平均提升20%性能,7B/14B/32B参数模型均达到或接近SOTA水平,其中Qwen-2.5-7B在SWE-Bench上从0.4%提升至20.2%。研究还发现跨任务数据混合训练能显著提升泛化能力,比单一数据集微调平均高出15.7%。通过建立原始数据→ADP→SFT的转换框架,ADP将数据集与代理框架间的转换复杂度从O(D×A)降至O(D+A),使新数据集接入成本降低90%以上。该成果通过开源代码和数据推动了代理模型训练的标准化,为多模态扩展和社区协作奠定了基础。
论文来源:hf
Hugging Face 投票数:22
论文链接:
https://hf.co/papers/2510.24702
PaperScope.ai 解读:
https://paperscope.ai/hf/2510.24702
OSWorld-MCP: Benchmarking MCP Tool Invocation In Computer-Use Agents
论文 ID:2510.24563
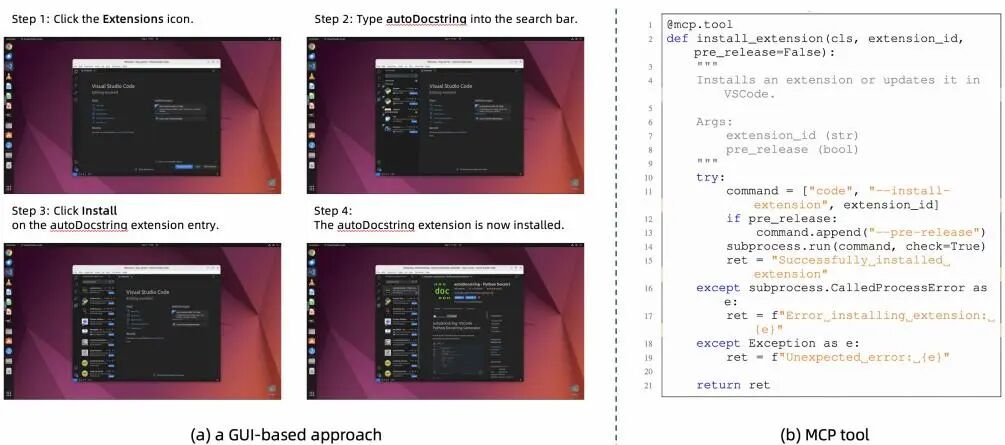
论文简介:
由阿里巴巴、北京大学等机构提出了OSWorld-MCP,该工作首次构建了全面评估多模态代理在计算机使用场景中工具调用、GUI操作和决策能力的公平基准。研究团队针对现有评估体系忽视工具调用能力的问题,通过整合158个覆盖VS Code、LibreOffice等7类常见应用的高质量MCP工具,结合自动化代码生成与人工验证,在真实操作系统环境中构建了包含361个任务的评估体系。实验显示MCP工具显著提升任务成功率(如OpenAI o3在15步任务中准确率从8.3%提升至20.4%),但当前模型工具调用率普遍偏低(最高仅36.3%),揭示了工具组合使用能力的不足。研究还引入工具调用率(TIR)和平均完成步骤(ACS)等新指标,发现工具调用率与任务准确率呈正相关,但工具组合复杂度增加时效率显著下降。该基准为多模态代理的工具使用能力评估建立了新标准,代码、环境和数据已开源。
论文来源:hf
Hugging Face 投票数:22
论文链接:
https://hf.co/papers/2510.24563
PaperScope.ai 解读:
https://paperscope.ai/hf/2510.24563
Scaling Code-Assisted Chain-of-Thoughts and Instructions for Model Reasoning
论文 ID:2510.04081
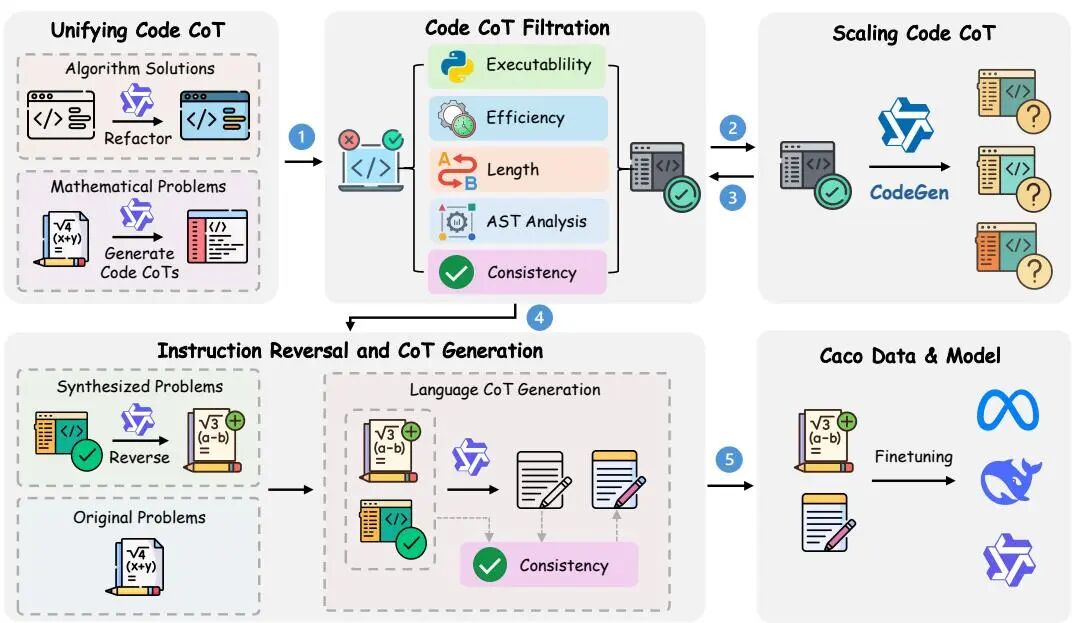
论文简介:
由 OpenDataLab、上海人工智能实验室、上海交通大学和苏州大学等机构提出了 Caco(Code-Assisted Chain-of-Thought),该工作通过代码驱动的自动化数据增强框架,解决了大规模语言模型(LLM)在复杂推理任务中面临的生成不可控、质量不足和推理路径多样性有限等问题。Caco 创新性地将代码执行验证与指令数据生成结合,首先通过统一数学和编程问题的代码格式训练代码生成模型 CodeGen,再利用该模型生成海量候选代码推理链,最后通过执行验证和规则过滤确保逻辑正确性与结构多样性,同时反向生成自然语言指令和对应的链式思维(CoT)数据,形成双向对齐的高质量推理训练集。实验表明,基于 Caco-1.3M 数据集训练的模型在数学推理基准测试中表现优异,例如在 GSM8K 和 MATH 数据集上分别达到 92.6% 和 82.4% 的准确率,显著超越现有方法。进一步分析显示,Caco 的代码验证机制和指令多样性显著提升了模型在未见任务上的泛化能力。该工作为构建可扩展、可验证的推理系统提供了新范式,同时验证了代码驱动方法在提升模型逻辑一致性与任务适应性方面的潜力。
论文来源:hf
Hugging Face 投票数:21
论文链接:
https://hf.co/papers/2510.04081
PaperScope.ai 解读:
https://paperscope.ai/hf/2510.04081
VisCoder2: Building Multi-Language Visualization Coding Agents
论文 ID:2510.23642
论文简介:
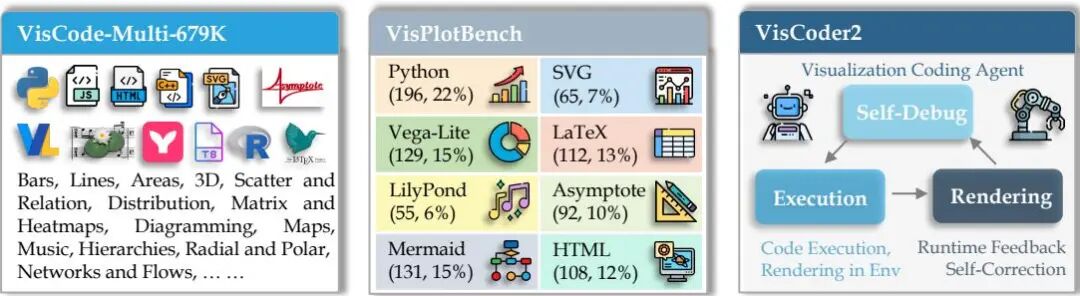
由滑铁卢大学、卡内基梅隆大学等机构提出了VisCoder2,该工作构建了多语言可视化编码代理,通过多轮执行、渲染和自调试机制显著提升了代码生成的可靠性。研究团队发布了三大核心资源:VisCode-Multi-679K数据集包含12种编程语言的679K条可执行可视化代码及多轮修正对话;VisPlotBench基准覆盖8种语言、13种图表类型和116种子类型,支持初始生成与多轮调试评估;VisCoder2模型家族基于该数据集训练,在32B参数规模下实现82.4%的执行通过率,接近GPT-4.1水平。实验表明,该模型在符号型语言(如LaTeX、LilyPond)中表现突出,自调试机制使执行可靠性平均提升近10个百分点。数据集融合了开源代码库、合成数据和多轮对话数据,通过Jupyter运行验证确保代码可执行性,指令生成结合了数据语义与视觉设计要素。VisPlotBench采用标准化的执行-渲染-评分流程,评估指标包括执行通过率、任务符合度和视觉相似度,支持最多三轮的调试循环。研究揭示了多语言覆盖和迭代修正对可视化编码代理的关键作用,为构建跨语言、可交互的智能可视化工具奠定了基础。
论文来源:hf
Hugging Face 投票数:20
论文链接:
https://hf.co/papers/2510.23642
PaperScope.ai 解读:
https://paperscope.ai/hf/2510.23642
CodePlot-CoT: Mathematical Visual Reasoning by Thinking with Code-Driven Images
论文 ID:2510.11718
论文简介:
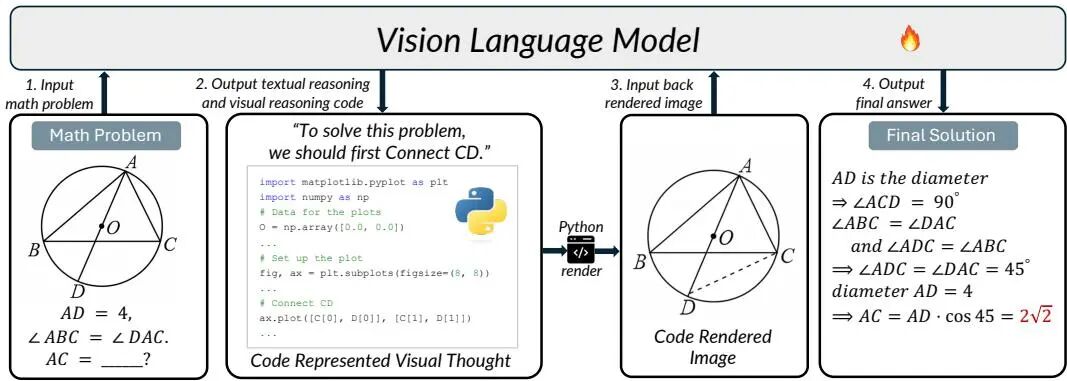
由HKU、Meituan和CUHK等机构提出了CodePlot-CoT,该工作提出了一种代码驱动的思维链范式,通过将数学视觉推理转化为可执行绘图代码生成任务,显著提升了视觉辅助数学问题的解决能力。研究团队构建了首个大规模双语数学视觉推理数据集Math-VR(含178K样本),并开发了MatplotCode图像-代码转换器,实现了数学图形到精确绘图代码的高保真转换。CodePlot-CoT模型通过交替生成文本推理和可执行代码(如绘制辅助线、函数图像等),将生成的代码渲染为中间视觉证据回输给推理链,有效解决了传统像素级图像生成在几何约束下的精度不足问题。实验表明,该方法在Math-VR基准测试中相较基线模型提升达21%,在几何、代数等多领域表现出显著优势。研究还通过对比实验验证了代码驱动范式比直接图像生成更具可控性和推理准确性,同时开源了数据集、代码和预训练模型,为多模态数学推理研究提供了关键基础设施。
论文来源:hf
Hugging Face 投票数:13
论文链接:
https://hf.co/papers/2510.11718
PaperScope.ai 解读:
https://paperscope.ai/hf/2510.11718
Executable Knowledge Graphs for Replicating AI Research
论文 ID:2510.17795

论文简介:
由浙江大学、蚂蚁集团等机构提出了Executable Knowledge Graphs(XKG),该工作构建了一种模块化可扩展的知识库,通过自动整合科学文献中的技术见解、代码片段和领域知识,解决了现有方法在生成可执行代码时面临的背景知识不足、检索增强生成(RAG)局限性及缺乏结构化知识表示的问题。XKG采用层次化多关系图结构,包含论文节点(Paper Node)、技术节点(Technique Node)和代码节点(Code Node),通过结构边(Structural Edge)和实现边(Implementation Edge)连接技术概念与可执行代码,实现了从论文到代码的细粒度关联。研究团队通过自动化流程构建了包含42篇论文、59万token的XKG,并在PaperBench基准测试中验证了其有效性:当集成到BasicAgent、IterativeAgent和PaperCoder三种代理框架时,使用o3-mini作为评估模型,XKG使平均复制得分提升6.68%-10.90%,其中PaperCoder框架下性能提升最为显著。实验表明,代码节点的质量对复制效果起关键作用,而知识过滤机制确保了技术节点的可执行性。该方法为AI研究复制提供了通用解决方案,但受限于现有论文的代码可用性,对完全创新性工作效果有限。
论文来源:hf
Hugging Face 投票数:12
论文链接:
https://hf.co/papers/2510.17795
PaperScope.ai 解读:
https://paperscope.ai/hf/2510.17795
ReLook: Vision-Grounded RL with a Multimodal LLM Critic for Agentic Web Coding
论文 ID:2510.11498
论文简介:
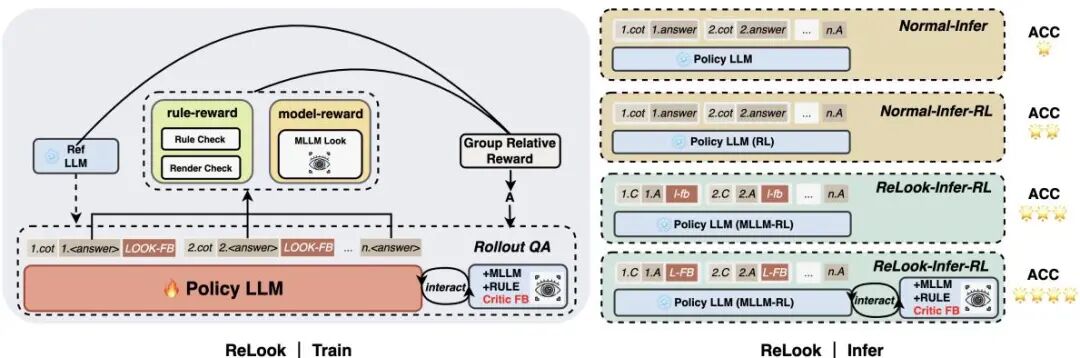
由腾讯等机构提出了ReLook,该工作提出了一种视觉感知的强化学习框架,通过引入多模态大语言模型(MLLM)作为批评者,构建了生成-诊断-优化闭环,解决前端代码生成中视觉一致性缺失的问题。传统LLM在算法代码生成上表现优异,但在前端开发中面临布局偏移、交互失效和视觉不一致三大挑战。ReLook在训练阶段将MLLM作为视觉批评者,通过屏幕截图评估代码质量并提供可执行的视觉反馈;采用强制优化策略确保迭代轨迹单调改进,避免行为崩溃;推理阶段解耦批评者实现轻量级自编辑,保持低延迟。实验表明,ReLook在ArtifactsBench、FullStack-Bench和WebBench三大基准测试中均显著超越基线模型,验证了视觉奖励信号和训练-推理解耦的有效性。其核心创新在于:1)构建了MLLM驱动的视觉奖励系统,解决前端代码像素级评估难题;2)设计强制优化机制确保迭代稳定性;3)实现批评者解耦推理,在保持性能的同时将推理速度提升6倍。该框架为视觉感知的代码生成提供了新范式,为多模态智能体开发提供了重要参考。
论文来源:hf
Hugging Face 投票数:10
论文链接:
https://hf.co/papers/2510.11498
PaperScope.ai 解读:
https://paperscope.ai/hf/2510.11498
(26) TensorBLEU: Vectorized GPU-based BLEU Score Implementation for Per-Sentence In-Training Evaluation
论文 ID:2510.05485
论文简介:
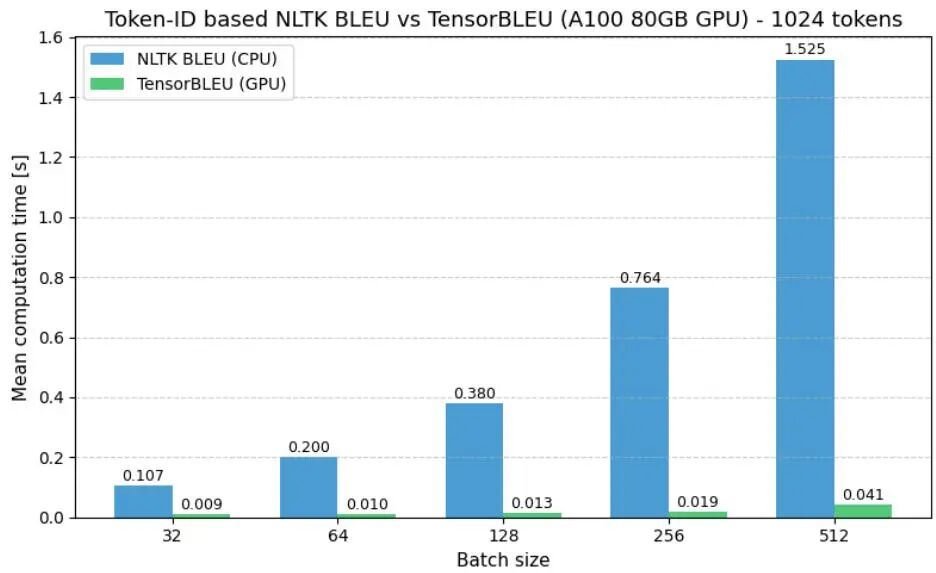
由Reactive AI等机构提出了TensorBLEU,该工作针对大规模语言模型训练中BLEU指标计算效率低下的问题,设计了一种全向量化的GPU加速实现方案。传统BLEU计算依赖CPU串行处理,难以满足强化学习等场景下对逐句奖励信号的实时需求,而SacreBLEU等文本级实现又存在解码开销。TensorBLEU通过三项核心技术突破性能瓶颈:1)利用PyTorch的unfold方法并行提取所有句子的n-gram;2)采用torch.unique动态构建批处理专用词典,将内存占用从词汇表规模降至实际出现的n-gram数量级;3)通过偏移量机制实现批量计数,单次bincount操作完成全部句子的n-gram统计。实验显示,在NVIDIA T4消费级GPU上实现13倍加速,A100数据中心级GPU上加速达40倍,使1024-token序列的评估时间从764ms降至19ms。该方法特别适用于强化学习中的密集奖励计算场景,同时通过定义"Token-ID BLEU"与标准化文本评估工具SacreBLEU形成互补。论文开源了RxLM框架下的实现代码,为大规模语言模型的训练优化提供了关键基础设施。
论文来源:hf
Hugging Face 投票数:7
论文链接:
https://hf.co/papers/2510.05485
PaperScope.ai 解读:
https://paperscope.ai/hf/2510.05485
(27) Code4MeV2: a Research-oriented Code-completion Platform
论文 ID:2510.03755
论文简介:
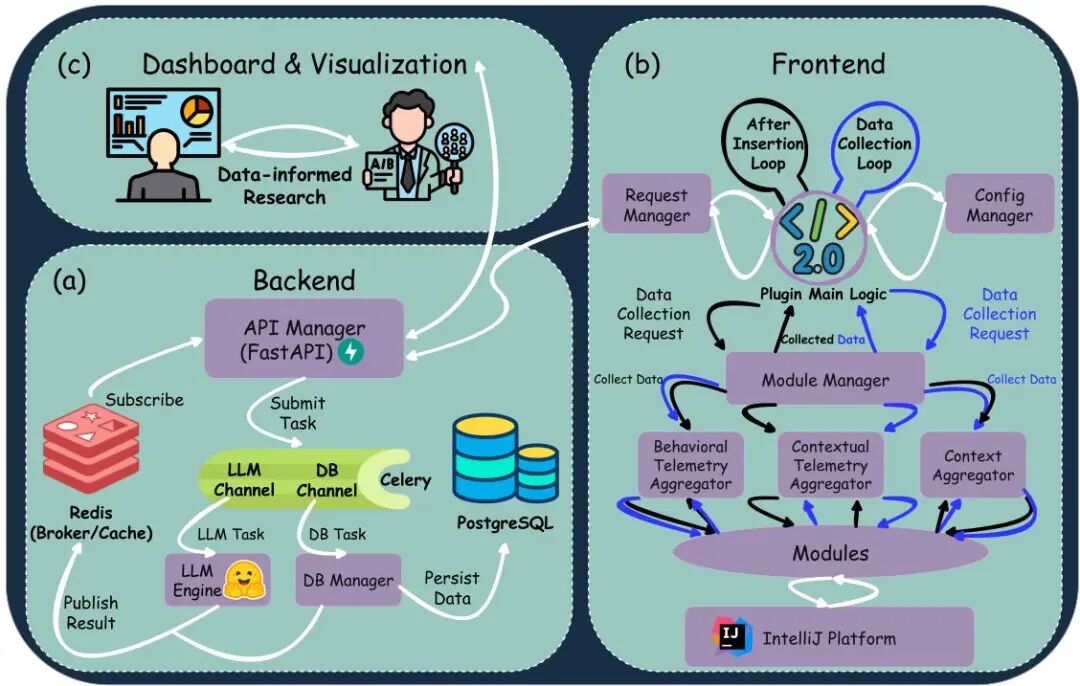
由Delft University of Technology等机构提出了Code4Me V2,该工作设计了一个面向研究的开源代码补全平台。针对现有商业AI代码工具数据不透明、学术研究受限的问题,Code4Me V2通过模块化架构实现细粒度数据采集与实验控制,支持人机交互研究与大规模数据分析。其核心贡献包括:1) 客户端-服务器架构分离界面与计算,降低IDE负载;2) 可扩展的模块化数据采集系统,支持自定义行为追踪;3) 内置分析平台提供实时指标计算与AB测试功能;4) 达到工业级响应速度(平均186ms延迟),支持多模型协同工作。通过专家评估与用户实验验证,该平台在保持实用性的同时,显著降低研究成本,为AI辅助编程领域提供可复现的实验基础设施,推动学术界对开发者行为与模型交互的深度研究。
论文来源:hf
Hugging Face 投票数:7
论文链接:
https://hf.co/papers/2510.03755
PaperScope.ai 解读:
https://paperscope.ai/hf/2510.03755
(28) CWM: An Open-Weights LLM for Research on Code Generation with World Models
论文 ID:2510.02387

论文简介:
由Meta FAIR CodeGen Team提出了CWM,一个320亿参数的开源大语言模型,旨在推进代码生成与世界模型的研究。CWM在Python解释器和代理Docker环境的观察-行动轨迹上进行大规模训练,并通过多任务推理强化学习提升性能。该模型提供了强大的测试平台,探索世界模型如何通过推理和规划改进代码生成。CWM在SWE-bench Verified、LiveCodeBench等基准测试中表现出色,支持代码执行模拟和复杂推理,并已开源模型权重和中间检查点,推动相关研究发展。CWM采用密集解码器架构,上下文窗口达131k tokens,通过预训练、中期训练(引入Python执行轨迹和ForagerAgent数据)及强化学习优化,实现代码理解与生成能力的突破。其世界模型训练方法显著提升了代码生成的准确性和可解释性,为未来研究提供了重要基础。
论文来源:hf
Hugging Face 投票数:7
论文链接:
https://hf.co/papers/2510.02387
PaperScope.ai 解读:
https://paperscope.ai/hf/2510.02387
(29) FinSight: Towards Real-World Financial Deep Research
论文 ID:2510.16844
论文简介:
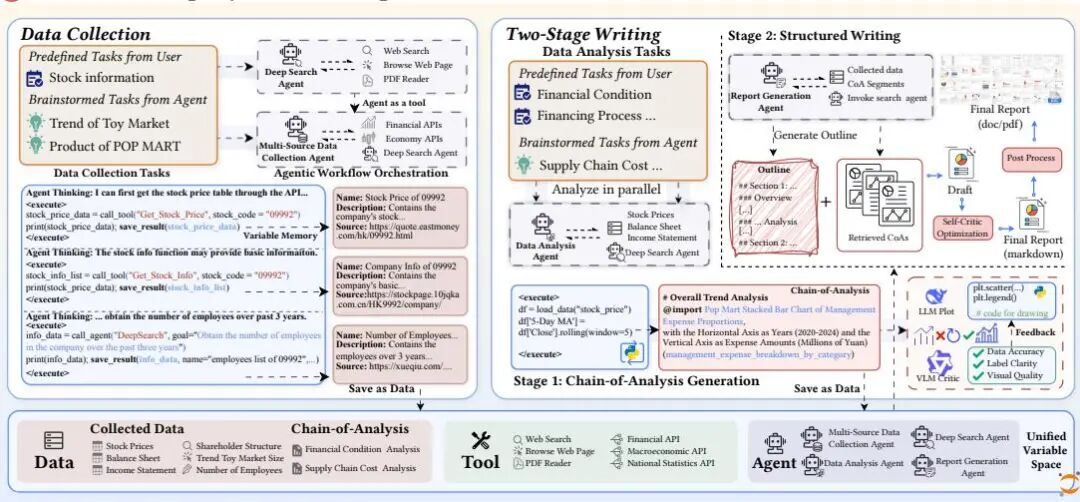
由中国人民大学高瓴人工智能学院与北京人工智能研究院提出了FinSight,该工作构建了一个面向真实世界金融深度研究的多智能体框架。核心创新包括:1)Code Agent with Variable Memory(CAVM)架构,将外部数据、工具和智能体统一为可编程变量空间,通过代码操作实现灵活的数据采集、分析与报告生成;2)迭代视觉增强机制,利用视觉语言模型对代码生成的图表进行多轮反馈优化,解决自动化可视化质量不足的问题;3)两阶段写作框架,先生成精炼的分析链(Chain-of-Analysis),再扩展为结构化、图文关联的长篇报告,确保分析深度与呈现一致性。实验表明,FinSight在公司与行业级任务中显著超越现有系统,在事实准确性、分析深度和呈现质量三个维度均表现突出,生成的报告在20页以上且图表超过20个,接近人类专家水平。其关键技术突破在于通过代码驱动的智能体协作实现金融数据的动态处理,并通过视觉反馈闭环提升图表专业度,为自动化金融研究提供了新范式。
论文来源:hf
Hugging Face 投票数:7
论文链接:
https://hf.co/papers/2510.16844
PaperScope.ai 解读:
https://paperscope.ai/hf/2510.16844
(30) Code Aesthetics with Agentic Reward Feedback
论文 ID:2510.23272
论文简介:
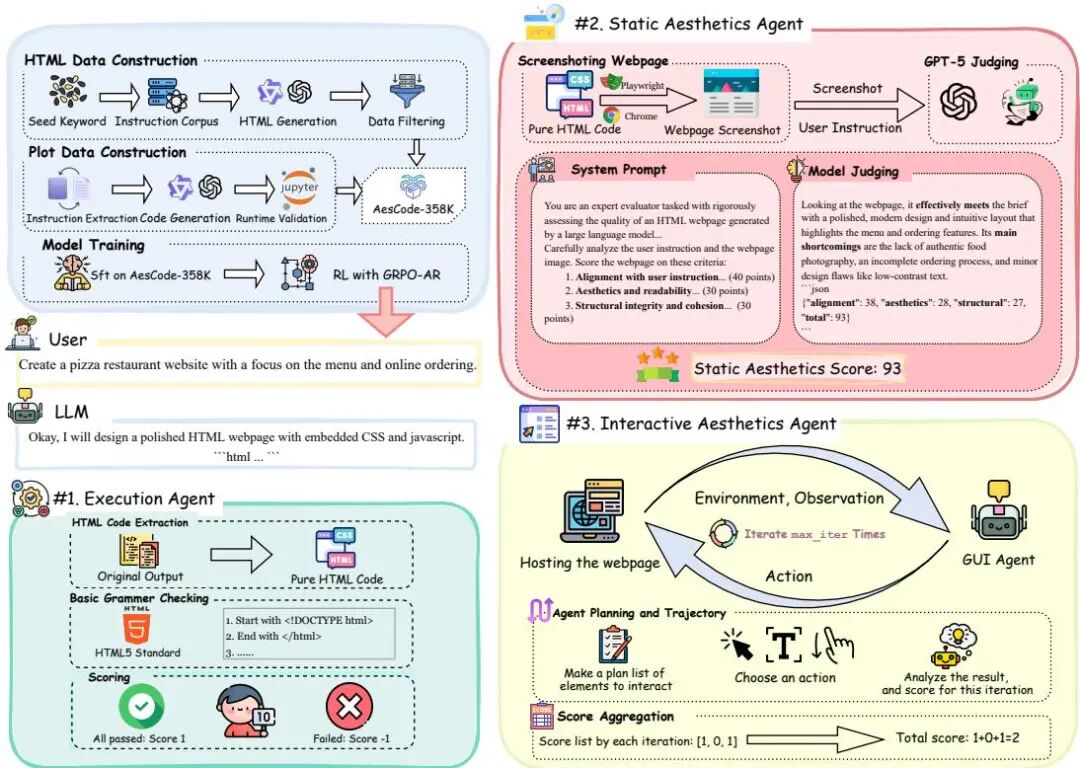
由Microsoft Research Asia、上海交通大学和北京大学等机构提出了Code Aesthetics with Agentic Reward Feedback,该工作提出了代码美学的概念,并通过多智能体奖励反馈系统提升大模型生成代码的视觉美感和交互体验。研究团队构建了包含35.8万条数据的AesCode-358K指令微调数据集,覆盖Python可视化和网页设计两大领域;开发了OpenDesign评估基准,通过静态视觉评分和动态交互评分双维度评估网页设计质量。核心创新点在于设计了包含执行代理、静态美学代理和交互美学代理的三重奖励系统,通过GRPO-AR算法将多模态反馈信号整合到强化学习中,实现功能正确性与美学价值的协同优化。实验表明,40亿参数的AesCoder-4B模型在OpenDesign和PandasPlotBench基准上超越GPT-4o和GPT-4.1,与480-685亿参数开源模型性能相当。特别在网页设计任务中,模型生成的HTML代码在视觉布局、色彩搭配和交互流畅性方面均显著提升,为解决大模型在视觉导向型编程任务中的美学缺失问题提供了新范式。
论文来源:hf
Hugging Face 投票数:7
论文链接:
https://hf.co/papers/2510.23272
PaperScope.ai 解读:
https://paperscope.ai/hf/2510.23272










