在AI领域,大模型的"终身学习"能力一直是业界追求的核心目标:我们期待AI能像人类一样,在不断吸收新知识、新技能的同时,不丢失过往积累的能力。但现实往往不尽如人意:当大模型通过微调更新新数据时,极易出现"灾难性遗忘"(Catastrophic Forgetting),也就是在学习新内容的过程中,彻底丢失之前掌握的知识和技能。这一问题成为阻碍大模型实现持续学习的最大瓶颈,无论是个人化助手的精准适配,还是企业级AI系统的实时知识更新,都受限于此。
近日,Meta FAIR实验室与加州大学伯克利分校的联合团队在arXiv上发表了一篇题为《Continual Learning via Sparse Memory Finetuning》[1]的论文,为这一难题提供了极具创新性的解决方案。该团队提出的"稀疏记忆微调"(Sparse Memory Finetuning)方法,借助记忆层的稀疏性更新特性,让大模型在高效学习新知识的同时,将旧有能力的遗忘率降至11% ,远超当前主流的全微调与LoRA方法。这一突破不仅为大模型持续学习开辟了新路径,更有望推动AI在个性化服务、实时知识更新等场景的规模化应用。
为何大模型学新就忘旧?
要理解这项工作的价值,首先要明确大模型持续学习面临的核心矛盾。现代大语言模型在预训练完成后,参数基本固定,若要学习新知识(如特定领域事实、用户个性化偏好等),通常需要通过微调更新参数。但问题在于,大模型的参数是共享的,同一组参数既承载着预训练阶段学到的通用知识(如语法规则、常识逻辑),又要适配新任务的特定需求。当微调更新参数时,新任务的优化目标会"覆盖"旧有知识的参数配置,导致模型在新任务上表现提升的同时,在原有任务上的性能急剧下降,这就是"灾难性遗忘"。
此前,业界已尝试过多种解决方案,但均存在明显短板。正则化方法(如权重衰减、KL惩罚)通过限制参数更新幅度来保护旧知识,但会牺牲新任务的学习效果;扩展参数方法(如LoRA、适配器)为新任务添加专属参数,虽减少遗忘,但新增参数容量有限,难以承载大量新知识;回放数据方法(Replay)通过持续复习旧数据缓解遗忘,但随着模型经验积累,所需复习的数据量呈指数增长,效率极低且难以规模化。
Meta与伯克利团队的核心洞察是:灾难性遗忘的根源在于"参数共享"导致的更新干扰,若能让模型仅更新与新知识强相关的少量参数,同时冻结承载旧知识的大部分参数,就能在学习与遗忘之间找到平衡。而记忆层(Memory Layers)的稀疏访问特性,恰好为这一思路提供了实现基础。
稀疏记忆微调的工作原理
该研究的创新点集中在"稀疏记忆微调"方法的设计上,其核心逻辑是"精准定位+稀疏更新",通过三层架构与机制设计,实现新知识学习与旧知识保护的双赢。
1. 记忆层替换传统FFN
研究团队首先对标准Transformer模型进行改造,将模型中间层(如22层Transformer中的第12层)的前馈网络(FFN)替换为记忆层(Memory Layer)。这一记忆层包含一个规模庞大的记忆池(实验中采用100万个记忆槽),每个记忆槽存储特定的知识表征,由键(Keys)和值(Values)组成,类似一个巨大的"知识字典"。
当模型处理输入时,记忆层会通过注意力机制,从100万个记忆槽中筛选出与当前输入最相关的32个(k=32)记忆槽进行访问——这意味着,每个输入仅激活记忆池中极小比例(约0.0032%)的参数。这种稀疏访问特性,使得模型能够将不同知识分散存储在独立的记忆槽中,为后续的精准更新奠定基础。

2. TF-IDF筛选可更新记忆槽
仅依赖记忆层的稀疏访问还不够——若盲目更新所有被激活的记忆槽,仍可能覆盖承载通用知识的记忆槽,导致遗忘。因此,研究团队设计了基于TF-IDF的记忆槽筛选机制,精准定位"仅与新知识相关"的记忆槽进行更新。
具体来说,模型会先统计当前训练批次中每个记忆槽的访问频次(TF,词频),再对比这些记忆槽在背景语料(如预训练数据)中的访问频次(IDF,逆文档频率)。通过TF-IDF评分,筛选出"在当前批次高频访问,但在背景语料中低频访问"的记忆槽——这些记忆槽大概率是专门承载当前新知识的"专属存储单元",而非支撑通用能力的"公共单元"。
模型仅对排名前t个(实验中t=500至10000)的高TF-IDF记忆槽进行微调更新,其余记忆槽(包括承载旧知识的通用记忆槽)保持冻结。这种"精准打击"式的更新,从根源上避免了新知识对旧知识的干扰。

3.适配稀疏更新的训练配置
为了最大化稀疏记忆微调的效果,研究团队还优化了训练细节。在优化器选择上,发现SGD(随机梯度下降)比常用的AdamW更适合稀疏更新。SGD能减少参数更新的波动性,进一步降低遗忘率;在记忆层配置上,采用4个记忆头、1024维值向量的设置,平衡学习容量与计算效率;在数据处理上,通过 paraphrasing(释义)和 Active Reading(主动阅读)生成数据增强样本,确保新知识能被充分学习。
实验设计
为了全面验证稀疏记忆微调的有效性,研究团队设计了两大核心实验场景,覆盖"小数据事实学习"和"大规模文档流学习",并与全微调、LoRA(参数高效微调的主流方法)进行了全方位对比。
1. 实验基础配置
-
基础模型:1.3B参数Transformer模型,所有方法使用相同预训练数据,确保公平对比。 -
记忆层设置:100万个记忆槽,4个记忆头,每个token访问32个记忆槽,替换Transformer中间层(第12层)的FFN。 -
对比方法: -
全微调(Full Finetuning):更新模型所有参数,学习能力强但遗忘严重; -
LoRA:在注意力和FFN层添加低秩适配器,参数高效微调的主流方案。 -
优化器:稀疏记忆微调使用SGD,全微调与LoRA使用AdamW(经实验验证为各自最优配置)。
2. 实验场景与数据集
研究团队设计了两个贴近真实持续学习需求的场景,分别测试模型在不同数据规模下的学习与遗忘表现:
场景一:小数据事实学习(Fact Learning)
模拟"少量新知识实时更新"场景(如用户告知AI个人偏好、特定领域小样本事实)。数据集采用TriviaQA测试集中的1000个事实,将每个事实改写为陈述句,并通过释义生成多个样本填充批次(避免重复样本导致的学习偏差)。评估指标包括:
-
学习效果:TriviaQA事实的F1分数(衡量新知识掌握程度); -
遗忘程度:NaturalQuestions(预训练相关的问答任务)F1分数、GSM8K(数学推理任务)负对数似然(NLL),分数下降越少表示遗忘越少。
场景二:文档流学习(Document QA)
模拟"大规模连续文档学习"场景(如AI实时读取行业报告、新闻资讯更新知识)。数据集采用SimpleQA的维基百科子集,选取100个问题对应的1824个文档片段(按段落拆分),模型逐段学习每个文档片段,通过Active Reading生成增强样本提升学习效果。评估指标与场景一一致,同时增加SimpleQA目标任务的F1分数。
3. 评估方法
-
动态跟踪:在训练过程中(0-10000步),每隔一定步数记录目标任务(新知识)和保留任务(旧知识)的性能,绘制学习-遗忘曲线; -
帕累托分析:通过调整超参数(如学习率、top-t值、LoRA的秩),绘制学习-遗忘帕累托前沿,判断方法的最优权衡能力; -
消融实验:验证TF-IDF筛选、背景语料选择、记忆槽数量等关键组件的作用。
实验结果
实验结果表明,稀疏记忆微调在两大场景中均表现出碾压级优势。在掌握同等新知识的前提下,遗忘率远低于全微调和LoRA,实现了学习与遗忘的帕累托最优。
1. 小数据事实学习遗忘率仅11%
在TriviaQA 1000个事实的学习任务中,三种方法的表现形成鲜明对比:
-
全微调:TriviaQA F1分数达到较高水平,但NaturalQuestions F1分数暴跌89%,GSM8K NLL大幅上升,几乎完全丢失预训练的问答和推理能力; -
LoRA:遗忘程度优于全微调,但NaturalQuestions F1仍下降71%,且新知识学习效果略逊于全微调; -
稀疏记忆微调:TriviaQA F1分数与全微调相当(甚至更高),而NaturalQuestions F1仅下降11%,GSM8K NLL基本保持稳定,实现了"学新不忘旧"。

2. 文档流学习
在1824个文档片段的连续学习任务中,由于数据多样性更高,全微调和LoRA的遗忘程度有所缓解,但仍远不及稀疏记忆微调:
-
全微调与LoRA:SimpleQA目标任务F1分数达到预期,但NaturalQuestions F1下降仍超过50%,GSM8K推理性能明显下滑; -
稀疏记忆微调:在SimpleQA上达到与基线相当的F1分数,而NaturalQuestions F1下降不足15%,GSM8K NLL保持在较低水平,即使在大规模连续学习中仍能稳定保留旧有能力。

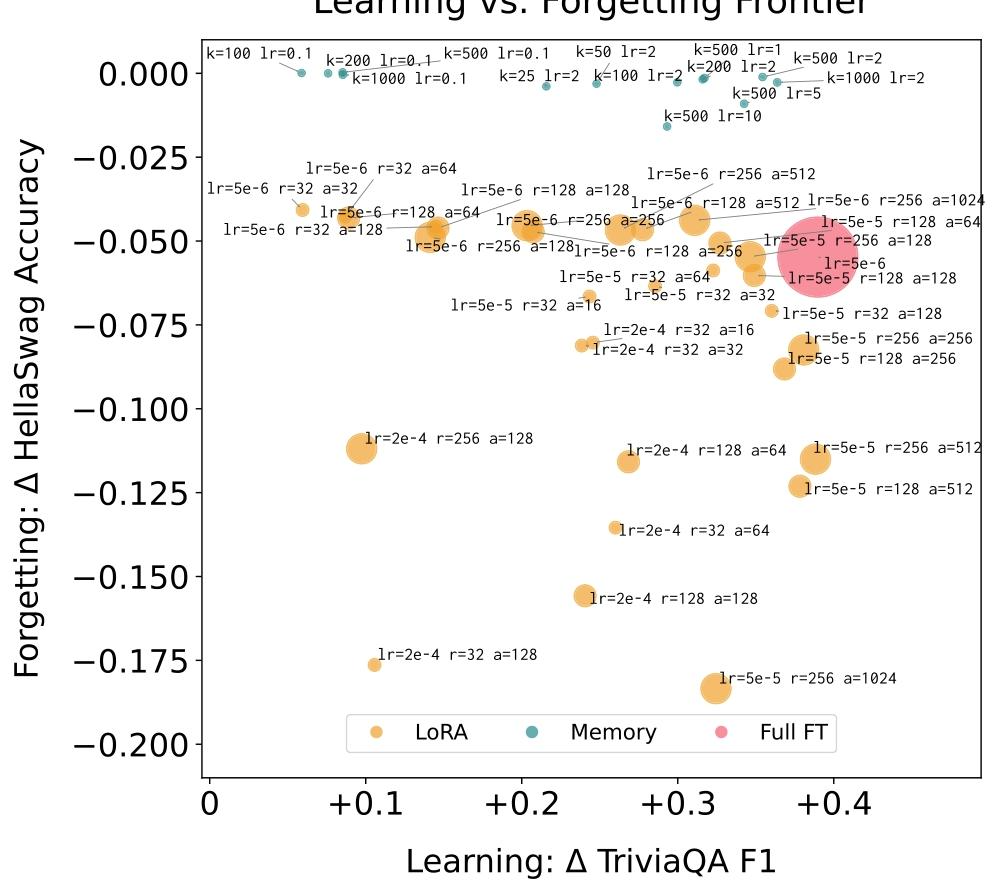
3. 帕累托前沿分析
为了进一步验证稀疏记忆微调的优势,研究团队通过超参数扫掠(如调整学习率、top-t值、LoRA的秩和alpha值),绘制了学习-遗忘的帕累托前沿,即"在给定学习效果下,遗忘程度最低;在给定遗忘程度下,学习效果最高"的最优曲线。
结果显示,稀疏记忆微调的所有数据点均位于帕累托前沿之上,而全微调和LoRA的点均在前沿之下。这意味着,无论如何调整超参数,全微调和LoRA都无法在"学习效果"和"遗忘程度"上同时超越稀疏记忆微调,证明了该方法在持续学习权衡中的绝对优势。
4. 消融实验
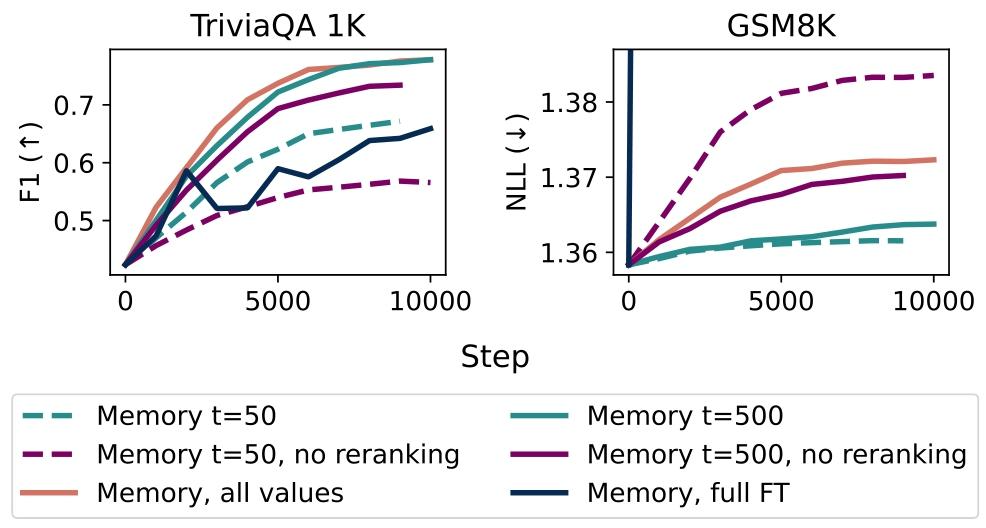
研究团队还通过消融实验,验证了稀疏记忆微调核心组件的作用:
TF-IDF筛选的必要性:对比"TF-IDF筛选top-t记忆槽"与"仅按访问频次(TF)筛选",发现后者虽然学习效果相当,但遗忘率显著更高(尤其当t较小时)。原因是TF仅考虑当前批次的访问频次,可能会更新承载通用知识的记忆槽,而TF-IDF通过与背景语料对比,能精准避开这些通用记忆槽。
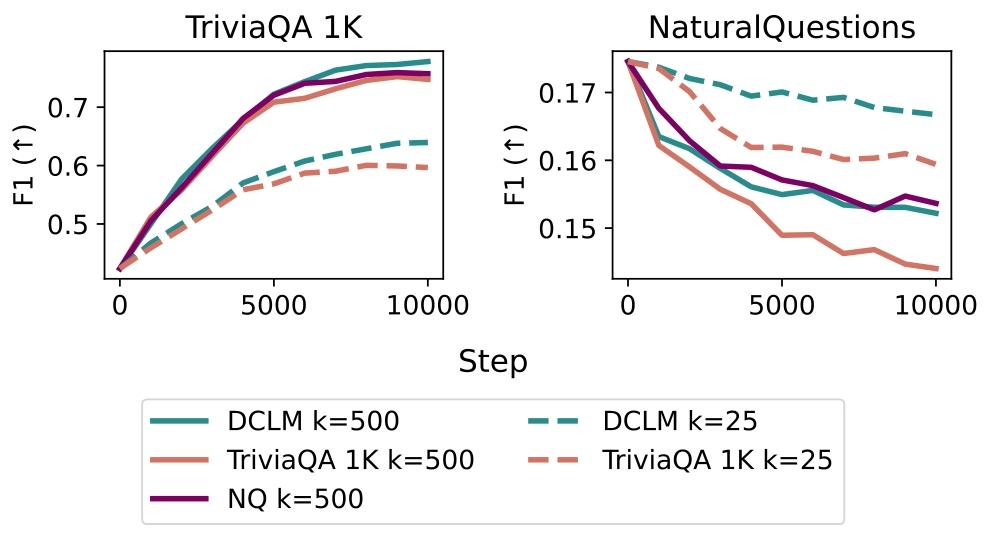
背景语料的影响:对比不同背景语料(预训练数据DCLM、目标任务数据TriviaQA、保留任务数据NaturalQuestions)发现,使用预训练数据作为背景语料时,遗忘率最低;使用目标任务数据作为背景语料时,由于无法保护预训练知识,遗忘率显著上升;使用保留任务数据作为背景语料时,表现与预训练数据接近,进一步验证了TF-IDF筛选的精准性。
稀疏更新的底层逻辑
通过实验分析,研究团队还揭示了稀疏记忆微调的几个关键发现,为后续持续学习研究提供了重要启示:
-
核心记忆集的存在:每个事实的知识仅存储在100-500个记忆槽中(称为"核心记忆集"),远少于批次访问的1k-100k个记忆槽。这一发现验证了"知识的稀疏存储"特性,也解释了为何仅更新少量记忆槽就能掌握新知识。
-
记忆槽与实体边界对齐:定性分析发现,被更新的高TF-IDF记忆槽,往往与文本中的实体边界(如人名、地名、事件名)对齐。这意味着模型会将实体相关的知识集中存储在特定记忆槽中,进一步提升了稀疏更新的精准性。
-
超参数的鲁棒性:稀疏记忆微调对超参数(如top-t值、学习率)的敏感度较低,即使t从50调整到1000,仍能保持较好的学习-遗忘权衡。这一特性降低了实际应用中的调参成本,提升了方法的实用性。
总结
Meta与伯克利团队的这项工作,通过"记忆层架构+TF-IDF稀疏筛选"的创新组合,成功破解了大模型持续学习中的灾难性遗忘难题,其核心贡献不仅在于提出了一种高效的微调方法,更在于验证了"稀疏参数更新"是实现持续学习的关键路径。
与现有方法相比,稀疏记忆微调的优势十分显著:无需回放旧数据(数据高效)、不新增大量参数(计算高效)、学习效果与全微调相当(学习能力强)、遗忘率仅为11%(稳定性高)。这些特性使其能够适配多种持续学习场景,例如:
-
个性化AI助手:实时学习用户偏好,不丢失通用对话与推理能力; -
行业知识更新:持续吸收行业报告、政策文件,保持专业知识时效性; -
边缘设备AI:在计算资源有限的情况下,高效更新局部知识。
研究团队表示,未来将探索更复杂的记忆槽筛选机制(如输入依赖的动态t值调整)、扩展到更大规模模型(如10B以上参数)、适配更广泛的任务类型(如代码生成、多模态理解)。此外,如何将稀疏记忆微调与检索增强生成(RAG)结合,实现"参数内记忆+外部检索"的双重知识更新,也将是重要的研究方向。
在大模型参数规模趋于饱和的今天,通过架构创新实现参数的"精准利用",可能比单纯增加参数规模更能解决核心问题。
> 本文由 Intern-S1 等 AI 生成,机智流编辑部校对
《Continual Learning via Sparse Memory Finetuning》: https://arxiv.org/abs/2510.15103v1
-- 完 --