大家好我是 「PaperScope.ai| P 站站长」闻星,EMNLP 2025 在苏州闭幕我们来看看 4000+ 论文中的 7 篇杰出论文有哪些,论文解读由 Intern-S1 生成。
(1) LingGym: How Far AreLLMs from Thinking Like Field Linguists?


论文简介:
由Yang等学者提出了LingGym基准测试,该工作通过构建多语言元语言推理评估框架,系统检验了大语言模型(LLMs)在低资源语言场景下的语言学分析能力。研究团队从18种类型学多样语言的参考语法中提取了19,612个对齐的互译文本(IGT)及语法知识点(KP)实例,设计了单词-词性标注推理任务,要求模型根据句子语境、形态切分、语法解释和翻译信息推断缺失语言成分。实验覆盖Qwen2.5、Gemma3、DeepSeek-R1和LLaMA3等主流模型,结果显示结构化语言线索(如KP和翻译)的引入可使准确率提升15-40%,其中DeepSeek-R1-32B在完整信息条件下达到81.17%的最高准确率。但模型在处理缩写标签、语义相似干扰项和细微形式差异时仍存在显著缺陷,例如将Komnzo语中含工具格助词的"zane=me"误判为光杆词"zane",或混淆Kalamang语中形态约束的副词选项。研究揭示了LLMs在跨语言元推理中的潜力与局限,为利用AI辅助濒危语言记录提供了新的评估范式和技术路径。
PaperScope.ai 解读:
https://paperscope.ai/hf/2025.emnlp-main.69
(2) Mind the Value-Action Gap: DoLLMs Act in Alignment with Their Values?


论文简介:
由华盛顿大学、纽约大学等机构提出了VALUEACTIONLENs框架,该工作首次系统评估了大语言模型(LLMs)在价值陈述与实际行动之间的一致性问题。研究指出,现有方法仅通过LLMs的价值倾向预测其行为存在局限,而忽略了"价值-行动差距"。VALUEACTIONLENs框架包含一个涵盖12种文化、11个社会话题的14,784个价值导向行为的数据集,设计了两个任务(陈述价值倾向与选择价值导向行为)和三个对齐指标(对齐率、距离、排名)。实验覆盖六种主流模型,发现LLMs在非洲、亚洲文化中的对齐率普遍低于欧美,且特定价值如"独立性""自主目标选择"存在显著偏差。例如,GPT-4o-mini在健康场景中对"社会权力"表现出陈述反对但行动支持的矛盾。研究还识别出潜在风险,如自主权侵犯、误导性解释等,强调需结合具体场景评估价值一致性,避免依赖单一价值陈述预测模型行为。该工作为构建更可靠、情境化的人工智能对齐评估体系提供了重要参考。
PaperScope.ai 解读:
https://paperscope.ai/hf/2025.emnlp-main.154
(3) DiscoSG: Towards Discourse-Level Text Scene Graph Parsing through Iterative Graph Refinement


论文简介:
由武汉大学、蒙纳士大学和RMIT大学等机构提出了Discourse-level text Scene Graph parsing(DiscoSG)任务,该工作针对多句子视觉描述的语篇级场景图解析问题,提出迭代图精炼框架DiscoSG-Refiner,通过删除和插入操作逐步优化初始场景图,实现了比句子级合并方法高30%的SPICE评分,同时推理速度提升86倍。研究团队构建了包含400个专家标注和8,430个合成样本的多句描述-图对数据集DiscoSG-DS,每个描述平均包含9个句子,每个图包含至少3倍于现有数据集的三元组。实验表明,该方法在复杂图解析任务中表现优异,且在图像字幕评估和幻觉检测等下游任务中显著提升指标有效性,同时通过引入D-FOIL基准推动了多句描述的幻觉检测研究。
PaperScope.ai 解读:
https://paperscope.ai/hf/2025.emnlp-main.398
(4) Generative or Discriminative? Revisiting Text Classification in the Era of Transformers


论文简介:
由 Amazon 等机构提出了 Generative or Discriminative? Revisiting Text Classification in the Era of Transformers,该工作首次系统性对比了 Transformer 时代下生成式与判别式文本分类模型的性能差异。研究团队通过在9个基准数据集上测试自回归(AR)、掩码语言建模(MLM)、离散扩散(DIFF)及编码器(ENC)等五种主流架构,揭示了经典"双机制"现象在不同模型规模下的演变规律。实验表明:小规模模型中ENC始终占优;中等规模下DIFF在低资源场景表现最佳;而大规模模型中MLM凭借伪生成特性在完整数据集上实现全面领先。研究还创新性地从噪声鲁棒性、概率校准度、类别有序性等维度展开评估,发现生成式模型虽在低数据场景具备优势,但其概率输出的可靠性普遍弱于ENC。特别值得注意的是,预训练会消除传统"双机制"效应,使ENC在所有数据规模下均优于AR模型。基于这些发现,研究团队为不同应用场景提供了明确选型建议:实时性场景优先ENC,完整数据场景推荐MLM,低资源场景可选DIFF或AR,而需要概率输出的排序任务则应避免使用DIFF。该研究为NLP开发者在模型选型、资源分配和部署优化等方面提供了重要参考依据,相关代码和实验数据已开源。
PaperScope.ai 解读:
https://paperscope.ai/hf/2025.emnlp-main.486
(5) Measuring Chain of Thought Faithfulness by Unlearning Reasoning Steps


论文简介:
由 Technion - Israel Institute of Technology 和 University of Utah 等机构提出了 Measuring Chain of Thought Faithfulness by Unlearning Reasoning Steps,该工作提出了一种名为 Parametric Faithfulness Framework (PFF) 的评估框架,并基于此开发了 Faithfulness by Unlearning Reasoning Steps (FUR) 方法,通过机器遗忘技术量化语言模型链式推理(CoT)的忠实性。研究团队引入了 FF-HARD 和 FF-SOFT 两个指标,分别用于判断完整推理链的忠实性和识别关键推理步骤。实验通过在四个语言模型(LLaMA、Mistral、Phi-3)和五个多跳推理数据集(ARC-Challenge、OpenbookQA 等)上验证,发现 FUR 能有效通过擦除特定推理步骤改变模型预测,证明 CoT 的参数级忠实性。研究还发现,被 FUR 识别为关键的推理步骤往往与人类判断的合理性存在偏差,表明需要专门对齐以实现既忠实又合理的推理生成。该工作通过参数干预而非上下文扰动,解决了传统 CoT 评估中模型可能重建被破坏信息的问题,并为分析大模型内部推理机制提供了新范式。
PaperScope.ai 解读:
https://paperscope.ai/hf/2025.emnlp-main.504
(6) MiCRo: Mixture Modeling and Context-aware Routing for Personalized Preference Learning


论文简介:
由伊利诺伊大学厄巴纳-香槟分校、纽约大学和莱斯大学等机构提出了MiCRo,该工作针对现有基于Bradley-Terry(BT)模型的奖励建模方法无法捕捉人类偏好异质性的问题,提出了一种两阶段上下文感知混合建模框架。理论分析表明,当人类偏好遵循子群体混合分布时,单一BT模型存在不可约误差。MiCRo第一阶段通过上下文感知的混合建模方法,从大规模二元偏好数据中分解出多个子群体的奖励函数,无需依赖细粒度标注或预定义属性;第二阶段引入在线路由策略,利用用户提供的上下文信息动态调整混合权重,实现对个性化偏好的高效适配。实验在HelpSteer2、RPR等多维度偏好数据集上验证,MiCRo的混合头有效捕捉了多样化偏好,在帮助性、正确性等14个维度上平均准确率较单BT模型提升40%,且通过上下文路由在跨分布场景下实现0.8218的平均准确率,超越了需要测试时标注的HyRe方法和8B参数的全监督ARMO模型。该方法在保持低标注成本的同时,为个性化大语言模型对齐提供了可扩展的解决方案。
PaperScope.ai 解读:
https://paperscope.ai/hf/2025.emnlp-main.882
(7) Causal Interventions Reveal Shared Structure AcrossEnglish Filler–Gap Constructions

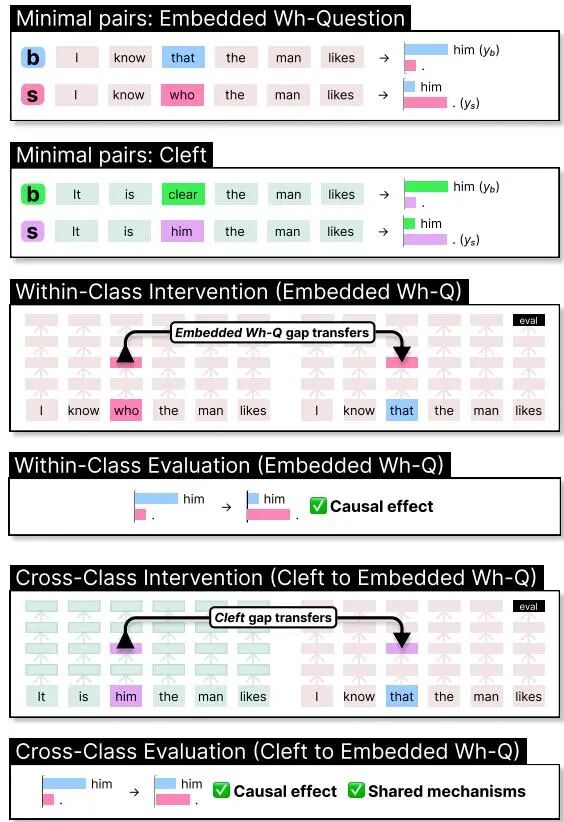
论文简介:
由德克萨斯大学奥斯汀分校和斯坦福大学的研究团队提出了基于因果干预的英语填空-空位结构共享机制分析方法,该工作通过分布式交换干预实验揭示了语言模型在处理不同填空-空位构造时共享抽象语法机制,并发现频率、填充类型及上下文等要素对机制泛化具有显著影响。研究聚焦于英语中七类填空-空位构造(如疑问句、关系从句、分裂句等),采用分布式对齐搜索(DAS)技术定位模型内部处理这些结构的因果机制,通过跨构造的干预实验测量机制共享程度。实验表明:模型在同类构造间表现出显著的机制泛化能力,尤其在填充物类型、句法倒装模式、父节点句法类别等语言学特征匹配时泛化效果更优;高频构造(如关系从句)更易成为机制源,低频构造则更依赖其他构造的机制迁移;主句与从句间的机制共享存在边界限制,单句机制在处理多句构造时仅在嵌套从句前三个位置保持有效。研究还发现填充物生命性特征对泛化强度的调节作用(lexical boost效应),以及不同构造在机制网络中的源/汇属性差异。这些发现不仅验证了语言模型对抽象句法结构的习得能力,更揭示了传统语言学理论中未充分重视的频率与表征相似性对构造处理的影响,为基于神经网络的句法理论修正提供了可验证假设。
PaperScope.ai 解读:
https://paperscope.ai/hf/2025.emnlp-main.1271