如您有工作需要分享,欢迎联系:aigc_to_future
作者:Yukang Cao等
解读:AI生成未来
 论文链接:https://arxiv.org/pdf/2507.01953
论文链接:https://arxiv.org/pdf/2507.01953
项目链接:https://yukangcao.github.io/FreeMorph/
亮点直击
本FreeMorph —— 一种无需调参、即可实现图像间方向性和真实过渡的新方法。引入了两个关键创新组件:1)感知引导的球面插值;2)基于步长的变化趋势。该方法融合两个分别来源于输入图像的自注意力模块,使过渡过程可控且一致,尊重两个输入的特征。 设计了一种改进的反向去噪与正向扩散流程,将上述创新组件无缝整合进原始的 DDIM 框架中。 构建了一个新的评估数据集,包含四组不同类型的图像对,按语义和布局相似度分类。FreeMorph 在保持高保真度、生成平滑连贯图像序列方面显著优于现有方法,可在30秒内完成图像变形过程,比 IMPUS 快 50 倍,比DiffMorpher快 10 倍。
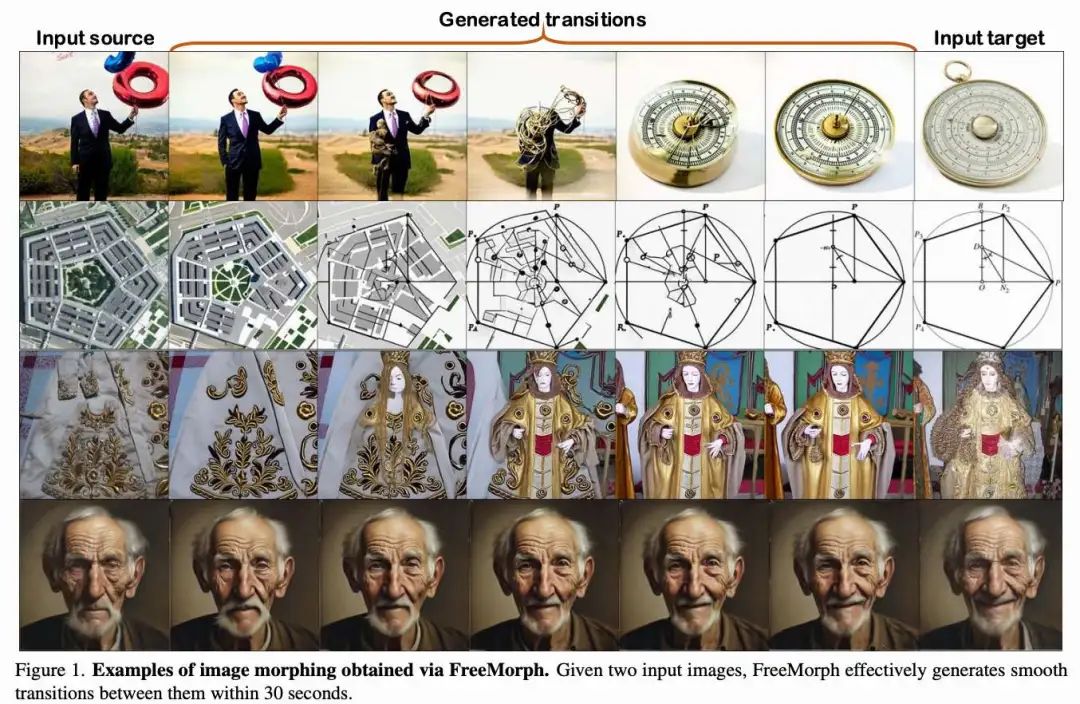

效果展示



总结速览
解决的问题
不同语义或布局的图像难以变形:传统图像变形方法在处理语义差异大或布局不同的图像时效果不佳,难以生成自然、平滑的过渡图像。
现有基于扩散模型的方法依赖微调,成本高:如 IMPUS 和 DiffMorpher 等方法需要对每对图像进行微调训练,耗时长(约 30 分钟),效率低,限制了其实用性。
无需调参方法存在质量挑战:
非方向性过渡:传统球面插值方法在多步去噪过程中容易产生过渡不一致的问题。 身份信息丢失:预训练扩散模型中的偏差会导致生成图像无法保持输入图像的身份特征。 缺乏变化趋势建模:扩散模型本身缺乏表示图像变化方向的机制,难以实现一致性过渡。
提出的方案
为解决上述问题,提出了 FreeMorph —— 首个无需调参即可实现高质量图像变形的方法,包含两个关键创新模块:
感知引导的球面插值(Guidance-aware Spherical Interpolation):
修改扩散模型中的自注意力模块,引入输入图像的显式引导信息; 聚合来自两个输入图像的 Key 和 Value 特征,确保过渡方向明确; 引入先验驱动的自注意力机制,保留输入图像的身份特征,缓解身份丢失问题。
基于步长的变化趋势建模(Step-oriented Variation Trend):
在每一步生成过程中,融合两个输入图像的自注意力模块; 建模逐步变化趋势,实现可控且一致的图像过渡,尊重两个输入的语义和布局特征。
改进的去噪与扩散流程:
将上述两个模块无缝集成进 DDIM 框架中,提升生成质量与效率。
应用的技术
扩散模型(Diffusion Models):以 DDIM 为基础的生成框架; 自注意力机制(Self-attention):用于引导图像特征的融合与身份保持; 球面插值(Spherical Interpolation):在潜在空间中实现图像特征的平滑过渡; 先验驱动注意力(Prior-guided Attention):增强模型对输入图像身份的建模能力; 无需微调(Tuning-free):避免对每对图像进行单独训练,提升效率与泛化能力。
达到的效果
高保真图像变形:生成图像在视觉质量、身份保持、语义一致性等方面显著优于现有方法。
显著提升效率:
比 IMPUS 快 50倍; 比 DiffMorpher 快 10倍; 每次图像变形仅需 30秒,无需训练或调参。
适应性强:能够处理语义或布局相似与差异较大的图像对,适用于多种实际场景。
建立新SOTA:在多个评估数据集上实现了当前图像变形领域的最先进性能(state-of-the-art)。
方法论
给定两张独立的输入图像 和 ,本文的目标是在无需调参的前提下,生成一系列中间图像 ,实现从一张图像平滑过渡到另一张图像的过程。本文实验中设置 。如下算法 1 所示,本文的流程以预训练的扩散模型为基础,并在多步去噪过程中引入来自输入图像的引导信息。

在接下来的内容中,首先介绍支撑本文方法的预备知识。随后,详细描述 FreeMorph 框架。该框架包含三个主要组成部分:
感知引导的球面插值,包括本文提出的球面特征聚合和先验驱动的自注意力机制;
基于步长的变化趋势,用于实现可控且一致的图像变形;
改进的正向扩散与反向去噪过程。
预备知识
去噪扩散隐式模型(DDIM)。去噪扩散隐式模型(DDIM)是一种在大规模文本-图像数据集上训练的模型,旨在从带噪输入中重建图像。训练完成后,它建立了一个从初始噪声状态 到图像 的确定性映射,本文称之为反向去噪步骤:
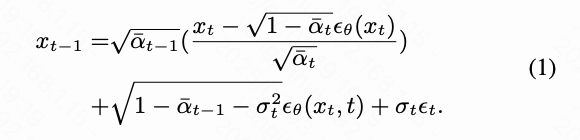 相反,通过对上述公式进行反转,本文可以推导出正向扩散过程,该过程逐步向图像中添加噪声以预测其噪声状态:
相反,通过对上述公式进行反转,本文可以推导出正向扩散过程,该过程逐步向图像中添加噪声以预测其噪声状态:
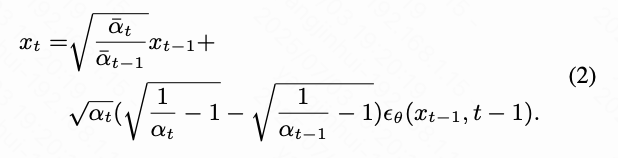 隐空间扩散模型(LDM)。在 DDIM 的基础上,隐空间扩散模型(LDM)是一种改进的扩散模型变体,能够在图像质量与去噪效率之间实现有效平衡。具体而言,LDM 利用预训练的变分自编码器(VAE)将图像映射到隐空间中,并在该空间内训练扩散模型。此外,LDM 通过引入自注意力模块、交叉注意力层和残差块来增强 UNet 架构,以在图像生成过程中整合文本提示作为条件输入。LDM 中 UNet 的注意力机制可表示为:
隐空间扩散模型(LDM)。在 DDIM 的基础上,隐空间扩散模型(LDM)是一种改进的扩散模型变体,能够在图像质量与去噪效率之间实现有效平衡。具体而言,LDM 利用预训练的变分自编码器(VAE)将图像映射到隐空间中,并在该空间内训练扩散模型。此外,LDM 通过引入自注意力模块、交叉注意力层和残差块来增强 UNet 架构,以在图像生成过程中整合文本提示作为条件输入。LDM 中 UNet 的注意力机制可表示为:
 其中, 表示来自空间数据的查询特征, 和 分别是从空间数据(用于自注意力)或文本嵌入(用于交叉注意力)中提取的键和值特征。LDM 中的噪声估计器随后被扩展为 ,其中 表示文本嵌入。
其中, 表示来自空间数据的查询特征, 和 分别是从空间数据(用于自注意力)或文本嵌入(用于交叉注意力)中提取的键和值特征。LDM 中的噪声估计器随后被扩展为 ,其中 表示文本嵌入。
本文的方法基于由 StabilityAI 开发的预训练 LDM —— Stable Diffusion 模型,并使用视觉-语言模型(VLM)LLaVA 为输入图像生成描述。
感知引导的球面插值
现有的图像变形方法通常为每个输入图像训练低秩适配(LoRA)模块,以增强语义理解并实现平滑过渡。然而,这种方法效率低下、耗时较长,并且在处理语义或布局差异较大的图像时效果不佳。本文提出了一种基于预训练 Stable Diffusion 模型的无需调参的图像变形方法。通过利用 DDIM(如公式 2)在图像反演与插值方面的能力,可以考虑将输入图像()转换为潜在特征(),并应用球面插值,这似乎是一个简单直接的解决方案:

其中 表示中间图像的索引,。回顾本文在论文中设置 。然而,直接将这些插值后的潜在特征 反演生成图像通常会导致过渡不连贯和身份丢失的问题(见下图 2)。这一问题产生的原因是:(1) 多步去噪过程高度非线性,导致图像序列不连续;(2) 缺乏显式的引导来控制去噪过程,导致模型继承了预训练扩散模型中的偏差。

球面特征聚合。借鉴以往的图像编辑技术的启发,本文观察到,使用 作为初始化,并将注意力机制中的键和值特征( 和 ,如公式 3 所述)替换为来自右侧图像 的特征,可以在很大程度上增强图像过渡的平滑性和身份保持,尽管仍可能存在一些瑕疵(见上图 2)。受此发现启发,并考虑到查询特征()在很大程度上反映了图像的整体布局,本文提出首先融合来自左右图像()的特征,为多步去噪过程提供显式引导。具体而言,在去噪步骤 中,本文首先将输入图像的潜在表示 和 输入到预训练的 UNet 中以获得键和值特征。随后,本文用输入图像中提取的 和 替换原始的键和值,并计算它们的平均值以修改注意力机制:

其中 、、 是通过将 输入到预训练的 UNet 中获得的。注意,、 和 是基于公式 3 得出的。
先验驱动的自注意力机制。虽然本文的特征融合技术在图像变形中显著提升了身份保持,但本文发现,在正向扩散和反向去噪阶段统一使用该方法,可能会导致图像序列变化极小,无法准确表现输入图像(见下图 6)。这一结果是预期中的,因为潜在噪声在反向去噪过程中会产生较大影响,如下图 3 所示。因此,应用本文在公式 5 中描述的特征融合方法时,会引入模糊性,因为来自输入图像的一致且强约束导致每个潜在噪声 显得相似,从而限制了过渡效果的表现力。


为了解决这一问题,本文进一步提出了一种先验驱动的自注意力机制,该机制优先利用球面插值得到的潜在特征,以确保潜在噪声中的平滑过渡,同时强调输入图像以在后续阶段保持身份信息。具体而言,在反向去噪阶段,本文使用公式 5 中描述的方法,而在正向扩散步骤中,本文通过修改自注意力模块,采用如下不同的注意力机制:
 详见下文关于该设计的消融实验。
详见下文关于该设计的消融实验。
面向步骤的变化趋势
在获得具有方向性且准确反映输入身份的图像序列后,接下来的挑战是实现从左图像 到右图像 的一致且渐进的过渡。这个问题源于缺乏一种能够捕捉从 到 变化的“变化趋势”。为此,本文提出了一种面向步骤的变化趋势,该趋势逐步改变输入图像( 和 )之间的影响力:

其中 , 表示图像的总数量,包括 张生成图像和 2 张输入图像。
正向扩散与反向去噪过程
高频高斯噪声注入。 如前所述,FreeMorph 在正向扩散和反向去噪阶段融合了左图像和右图像的特征。然而,本文观察到这有时会对生成过程施加过于严格的约束。为缓解这一问题并提供更大的灵活性,本文提出在正向扩散步骤之后,将高斯噪声注入到潜在向量 的高频域中: 这里, 和 分别表示逆快速傅里叶变换和快速傅里叶变换。 表示一个随机采样的噪声向量, 是一个与 同尺寸的二值高通滤波器mask。
这里, 和 分别表示逆快速傅里叶变换和快速傅里叶变换。 表示一个随机采样的噪声向量, 是一个与 同尺寸的二值高通滤波器mask。
整体流程。 为了增强图像变形过程的效果,本文发现,在所有去噪步骤中持续应用引导感知球面插值或面向步骤的变化趋势会产生次优结果。为了解决这个问题,本文为正向扩散和反向去噪过程开发了一种优化的方法。本文在上面算法 1 中提供了所提出的 FreeMorph 的整体算法概览。具体如下:
正向扩散: 前 步使用标准的自注意力机制。从 到 ,应用公式 6 中的特征融合技术。剩余步骤中,采用面向步骤的变化趋势。
反向去噪: 前 步使用面向步骤的变化趋势,接下来的步骤(在 到 之间)使用公式 5 中的特征融合方法。最后的步骤使用原始的自注意力机制,以生成更高保真度的图像。
这里,、、 和 是超参数, 是总的步骤数。
实验
本文在多种场景下评估了 FreeMorph 的性能,将其与最先进的图像变形技术进行比较,并通过消融实验突出本文提出组件的有效性。
实现细节。 本文使用公开可用的 Stable Diffusion 模型版本 2.1。正向扩散和反向去噪过程均采用 步的 DDIM 计划。在 NVIDIA A100 GPU 上,本文的方法生成一个变形序列的时间不到 30 秒。按照 Stable Diffusion 的设置,本文使用 的图像分辨率。本文将无分类器引导(CFG)参数设置为 7.5,以引入文本条件特征。超参数设置如下:,,,。
评估数据集。 DiffMorpher 引入了 MorphBench,其中包含 24 对动画和 66 对图像,主要是具有相似语义或布局的图像。为补充该数据集并减轻潜在偏差,本文引入了 Morph4Data,这是一组新策划的评估数据集,包含四个类别:
Class-A:包含 25 对图像,具有相似布局但语义不同,来源于 Wang 和 Golland;
Class-B:包含具有相似布局和语义的图像对,包括来自 CelebA-HQ 的 11 对人脸和 10 对不同类型的汽车;
Class-C:包含 15 对从 ImageNet-1K 随机采样的图像对,无语义或布局相似性;
Class-D:包含 15 对从网络上随机采样的狗和猫图像。
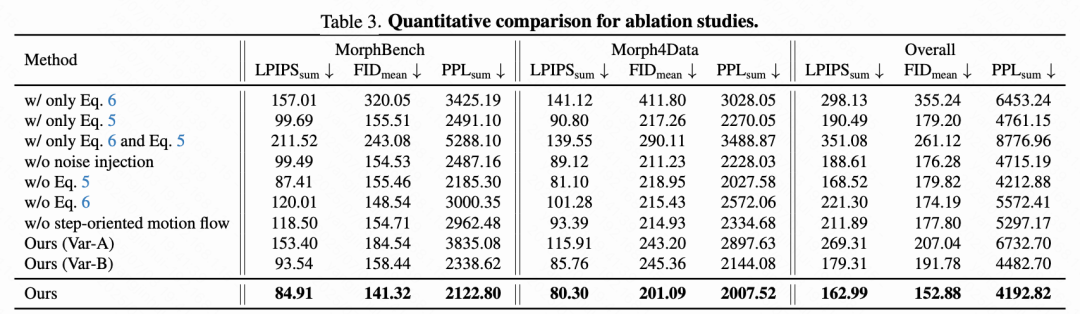
定量评估
按照 IMPUS 和 DiffMorpher 的方法,本文使用以下指标进行了定量比较:
Frechet Inception Distance (FID),用于评估输入图像与生成图像分布之间的相似性;
Perceptual Path Length (PPL),计算相邻图像之间的 PPL 损失之和;
Learned Perceptual Image Patch Similarity (LPIPS),本文也对相邻图像之间的值求和,以评估生成过渡的平滑性和连贯性。
结果详见下表 1,显示本文的方法在两个数据集上均表现出更高的保真度、平滑性和直接性。

用户研究 为了通过引入人类偏好增强本文的对比分析,进行了用户研究。招募了30名志愿者,包括动画师、AI专家和年龄在20至35岁之间的游戏爱好者,来选择他们偏好的结果。每位参与者被展示了50对随机的对比结果。这些结果展示在下表2中,表明本文提出方法的主观有效性。需要注意的是,slerp 表示仅应用球面插值的方法。

定性评估*
定性结果。 在上图1和上图4中,展示了由 FreeMorph 生成的广泛结果,这些结果持续展示了其生成高质量和平滑过渡的能力。FreeMorph 在多种场景中表现出色,能够处理语义和布局不同的图像,以及具有相似特征的图像。FreeMorph 还能够有效处理细微变化,例如颜色不同的蛋糕和表情不同的人物。
定性对比。 在下图5中提供了与现有图像变形方法的定性对比。一个有效的图像变形结果应当展现从源图像(左)到目标图像(右)的渐进过渡,同时保留原始身份。基于这一标准,可以得出以下几点观察:
在处理语义和布局差异较大的图像时,IMPUS 表现出身份丢失和不平滑的过渡。例如,在图5的第二个例子中,IMPUS 展现出 (i) 身份丢失,即第三张生成图像偏离了原始身份,以及 (ii) 第三张和第四张生成图像之间的突变过渡。
尽管 DiffMorpher 相较于 IMPUS 实现了更平滑的过渡,其结果常常表现出模糊和整体质量较低的问题(见图5第一个例子);
本文还评估了一个基线方法“Slerp”,该方法仅应用球面插值和 DDIM 过程。可视化结果表明该基线方法存在以下问题:(i) 由于缺乏显式引导,难以准确解释输入图像,(ii) 图像质量不佳,(iii) 过渡突兀。
相比之下,本文方法始终表现出更优的性能,特点是更平滑的过渡和更高的图像质量。

进一步分析
引导感知球面插值分析。 在上图6中,本文进行消融实验以评估所提出的球面特征聚合(公式 5)和先验驱动的自注意力机制(公式 6)的效果。结果表明,仅使用其中任何一个组件都会导致次优结果。具体来说:
球面特征聚合对于实现方向性过渡至关重要,其中 的特征逐渐减弱;
先验驱动的自注意力机制对于在生成图像中保持身份至关重要。
这两个组件的结合使得 FreeMorph 能够在有效保持身份的同时生成平滑过渡。通过对比图6中最后两行,本文展示了面向步骤的变化趋势以及特别设计的反向与正向过程的重要性。
反向与正向过程分析。 在下图7中,本文将本文的方法与两个变体进行比较:(i) “Ours (Var-A)”,省略原始注意力机制,(ii) “Ours (Var-B)”,在反向与正向过程中交换引导感知球面插值与面向步骤变化趋势的应用步骤。将这些变体与本文的最终设计进行比较表明:
(i) 原始注意力机制对于实现高保真结果至关重要;
(ii) 本文最终设计中反向与正向过程的特定配置实现了最优性能。

面向步骤的变化趋势分析。 在图8中,本文首先禁用所提出的面向步骤变化趋势以评估其影响。本文观察到,在没有该组件的情况下,模型倾向于产生突变而非平滑的过渡。此外,最终生成的图像表现为与目标图像 存在差异的高对比度颜色。相比之下,面向步骤的变化趋势使本文的方法能够实现更平滑的过渡,并生成更接近目标图像的最终结果。
高频噪声注入分析。 本文随后禁用高频噪声注入,并在图8中展示相应的消融研究。结果表明,引入所提出的高频噪声注入增强了模型的灵活性,并有助于实现更平滑的过渡。
结论
FreeMorph,一种无需调参的新型流程,能够在30秒内生成两个输入图像之间的平滑高质量过渡。具体而言,本文通过修改自注意力模块来引入来自输入图像的显式引导。这是通过两个新组件实现的:球面特征聚合和先验驱动的自注意力机制。此外,本文引入了面向步骤的变化趋势,以确保与两个输入图像一致的方向性过渡。本文还设计了改进的正向扩散和反向去噪过程,以将本文提出的模块集成到原始的 DDIM 框架中。大量实验表明,FreeMorph 在各种场景中提供了高保真度的结果,显著优于现有的图像变形技术。
参考文献
[1] FreeMorph: Tuning-Free Generalized Image Morphing with Diffusion Model
致谢
如果您觉得这篇文章对你有帮助或启发,请不吝点赞、在看、转发,让更多人受益。同时,欢迎给个星标⭐,以便第一时间收到我的最新推送。每一个互动都是对我最大的鼓励。让我们携手并进,共同探索未知,见证一个充满希望和伟大的未来!
技术交流
加入「AI生成未来社区」群聊,一起交流讨论,涉及 图像生成、视频生成、3D生成、具身智能等多个不同方向,备注不同方向邀请入群!可添加小助手备注方向加群!











