昨晚我们刚说到,今天(当地时间12月11号)OpenAI就正式放出了这款被定位为“迄今最强专业知识工作模型”的新系统GPT-5.2[1],已全面向ChatGPT订阅用户开放,在升级0.71.0版本后的Codex平台也同步上线。


从紧急应对谷歌Gemini 3的“红色警报”,到不足一月内从GPT-5.1迭代至5.2,OpenAI这次的升级速度,直接印证了AI行业的激烈竞争,而最终受益的,无疑是需要靠AI提升效率的普通用户和企业。
话不多说,按惯例,我们先来简单介绍一下这次GPT5.2升级在哪里。已经有所了解的同学可以直接看后面的实测部分。
技术升级
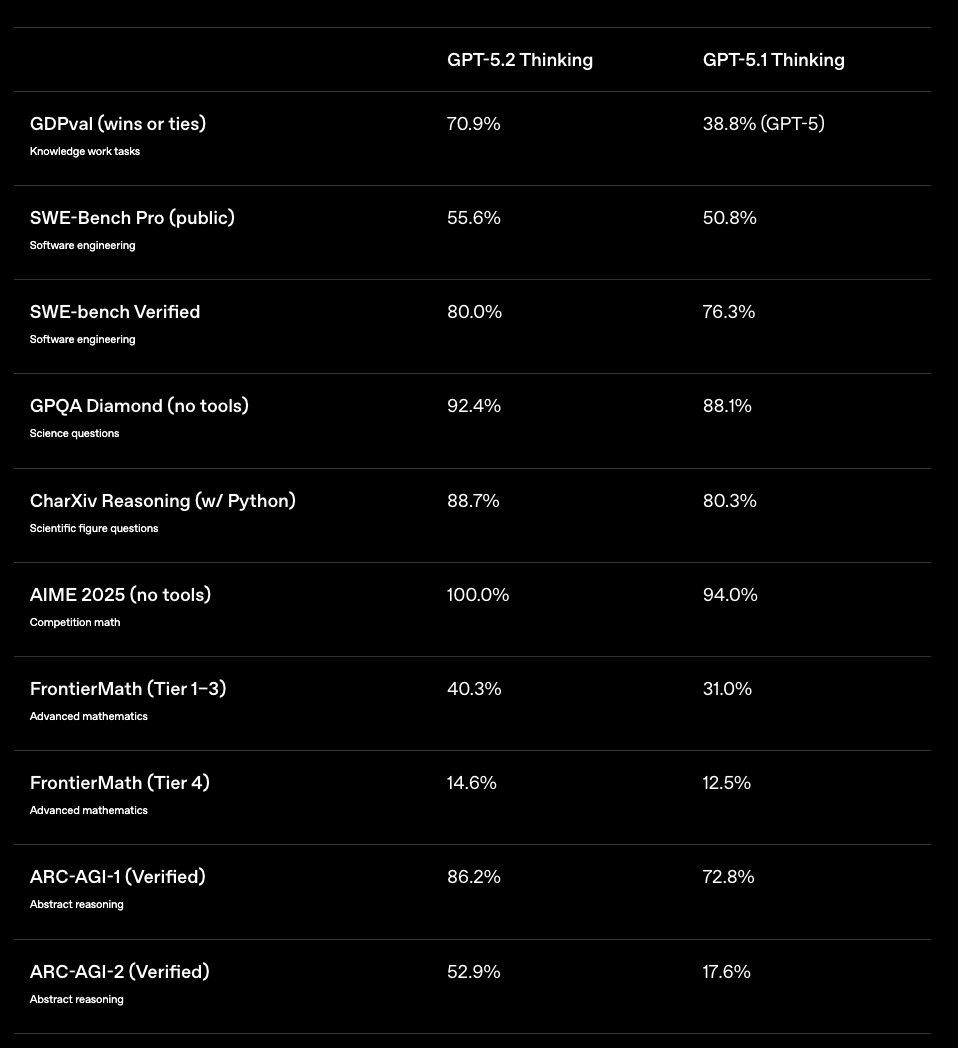
从GPT-5.2官方博客[2]来看,此次升级没有什么新功能引入,提升的是模型的能力,主要体现在测试成绩全面碾压GPT-5.1,多项测试超过了最新的Gemini-3和Claude-Opus-4.5。
在大家最常用的“生产力三件套”上,GPT-5.2的进步肉眼可见:做表格时,它能自动区分不同部门的预算逻辑,像工程、市场、法务的成本项会精准分类,公式关联也很少出错;写PPT时,不仅能生成内容框架,还会根据行业调性匹配版式,比如科技类用数据可视化,教育类用图文结合。

编码能力在覆盖四种编程语言的SWE-Bench Pro测试中达成新SOTA,拿到55.6%的成绩,在验证真实项目的SWE-bench Verified测试里更是飙到80%,前端开发进步也非常明显,早期测试者用它做的3D海洋波浪模拟、假日贺卡生成器,只需要一个简单指令就能跑通,且UI风格更加美观。

长文档处理和视觉理解的提升,解决了很多用户的“痛点”。以前处理20万字以上的报告,AI很容易漏信息,现在GPT-5.2在256k token(约19万字)的“大海捞针”测试中,4根埋针的准确率接近100%,哪怕是分散在不同章节的关联信息,也能整合起来。

科学与数学能力则是小有突破。在研究生级别的GPQA Diamond测试中,Pro版拿到93.2%的正确率,Thinking版紧随其后达92.4%,覆盖物理、化学、生物的专业问题;专家级数学测试FrontierMath中,Thinking版解决了40.3%的难题,有研究团队用它探索统计学习理论的开放问题,它提出的证明思路经过外部专家验证是可行的,这意味着AI不再只是“做题工具”,还能帮科学家打开新思路。

实测
接下来,我们用5个实际场景测试了GPT-5.2的真实表现:纯视觉大海捞针、纯文本大海捞针、考公行测真题、前端与3D渲染器编程、图像标注。
✅ 测试1:超长纯图 PDF 找寻指定内容(成功)
报告中,4针“大海捞针”准确率100%,我们先来测测是否有夸张的成分。
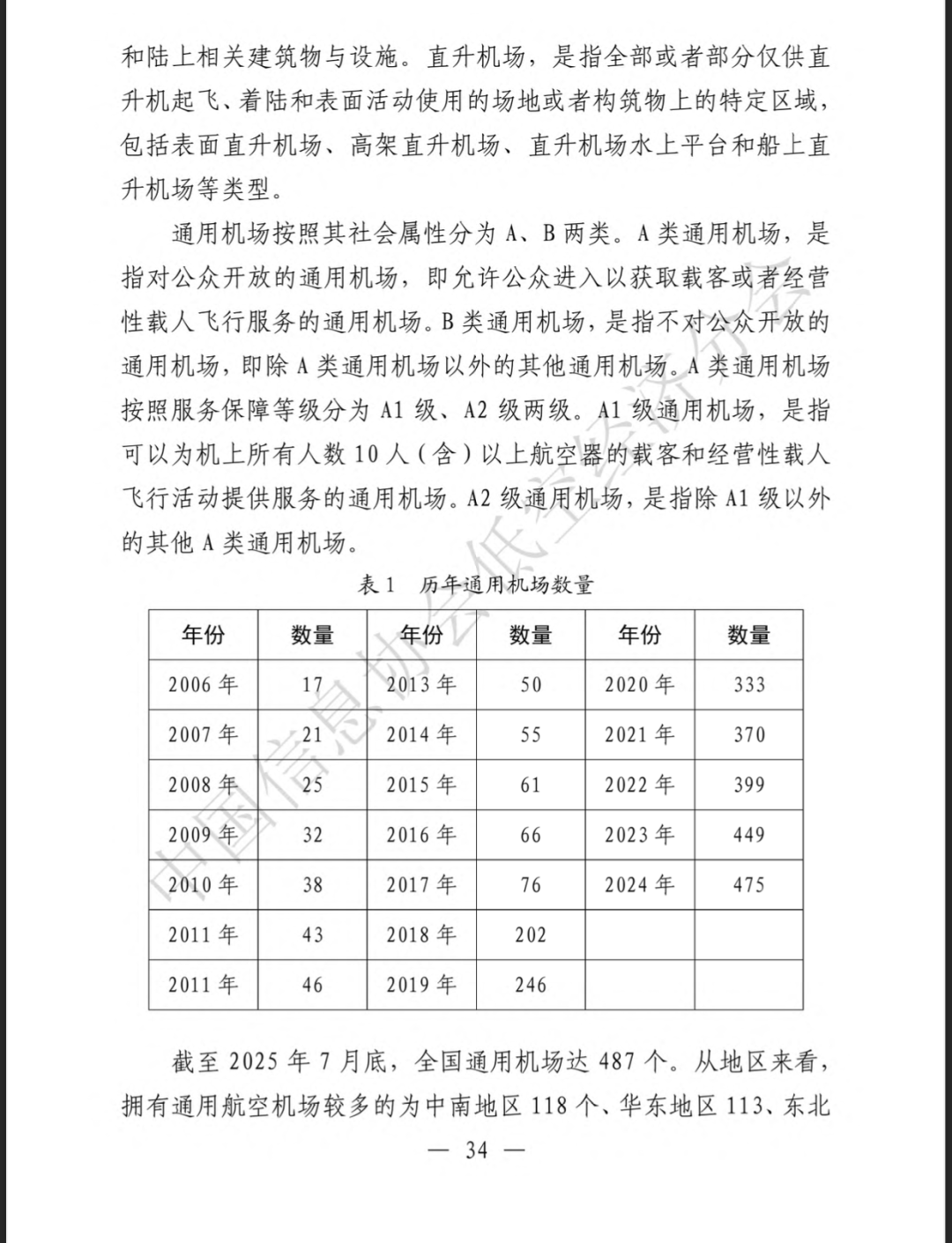
测试背景:选取183页的纯图片型PDF-《低空基础设施发展研究报告(2025)》,要求GPT-5.2 Thinking 定位并提取指定信息。
测试过程:先将PDF上传至ChatGPT,明确指令“历年通用机场数量表在文档中所在的位置”,该表在文档中页码34页。观察模型的检索逻辑和输出结果。

初步结果:模型成功识别了PDF的章节结构,找到了“低空地面保障设施”和“通用机场”部分,并成功判定了PDF页码和文档野蛮,判定为成功。
✅ 测试2:大海捞针测试(成功)
测试背景:模拟真实工作中“从长文档找关键信息”的场景,选用西游记全量文本(约67万字符,cl100k_base方法token数为929,620),在其中插入4处“针”,要求GPT-5.2找出这些句子并注明位置。

测试过程:将txt文本一次性上传,使用不同的提示词查找插针内容和位置,测试GPT-5.2上下文检索、定位及理解的准确性。
关键词检索

文本搜索及定位

具体定位

长文本理解

初步结果:4个插针全部找到,能说明句子前后的上下文关联;按内容定位位置标注精准到章节;按字符定位位置无误差;且能很好的将与全文无关的插入内容理解总结,不受主要内容影响,准确率100%,判定为成功。
✅ 测试3:2025考公真题(成功)
测试背景:选取2025年公务员考试行测中的若干道题,测试GPT-5.2的逻辑分析和数据计算能力。
测试过程:逐题输入题目内容和选项,要求模型先给出答案,再说明解题思路,比如资料分析题需要展示公式推导过程,判断推理题需要拆解逻辑链条。
文字推理

地理常识

物理常识

图形推理

逻辑推理

初步结果:5道题全部答对,给出的解释清晰合理,判定为成功。
✅ 测试4:编程(成功)
测试背景:验证GPT-5.2的编程能力,特别是前端开发和3D渲染能力。
测试过程:通过输入不同的提示词,在GPT Canvas中生成直接可用的App,同时检查文字和代码输出。
机智流官网



3D月相模器
要求生成一个可交互的3D月相模拟页面,支持查看不同日期(如农历初一、十五)的月相形态,可调整观察角度。提示词:
Prompt: Create a single-page app in a single HTML file with the following requirements: - Name: 中国月相模拟器 - Goal: 动态展示月亮的形态 - Features: 可以改变日期和中国城市 - The UI should be calming and realistic.


初步结果:生成的代码无需修改即可在浏览器打开,网页布局合理,内容符合要求,评论交互可正常应用;月相形态与实际吻合(如初一为新月、十五为满月),还额外添加了“月相”、“照明比例”、“月龄”和“本地太阳时的修正”的显示,交互体验超出预期。
除了官网首页新闻标题颜色不合适之外,代码的生成十分流畅,UI也没有采用常见的AI风格,判定为成功。
✅ 测试5:图像标注与Gemini对比

有眼尖的网友发现GPT5.2纯属瞎编,例如把DP接口标为HDMI口。
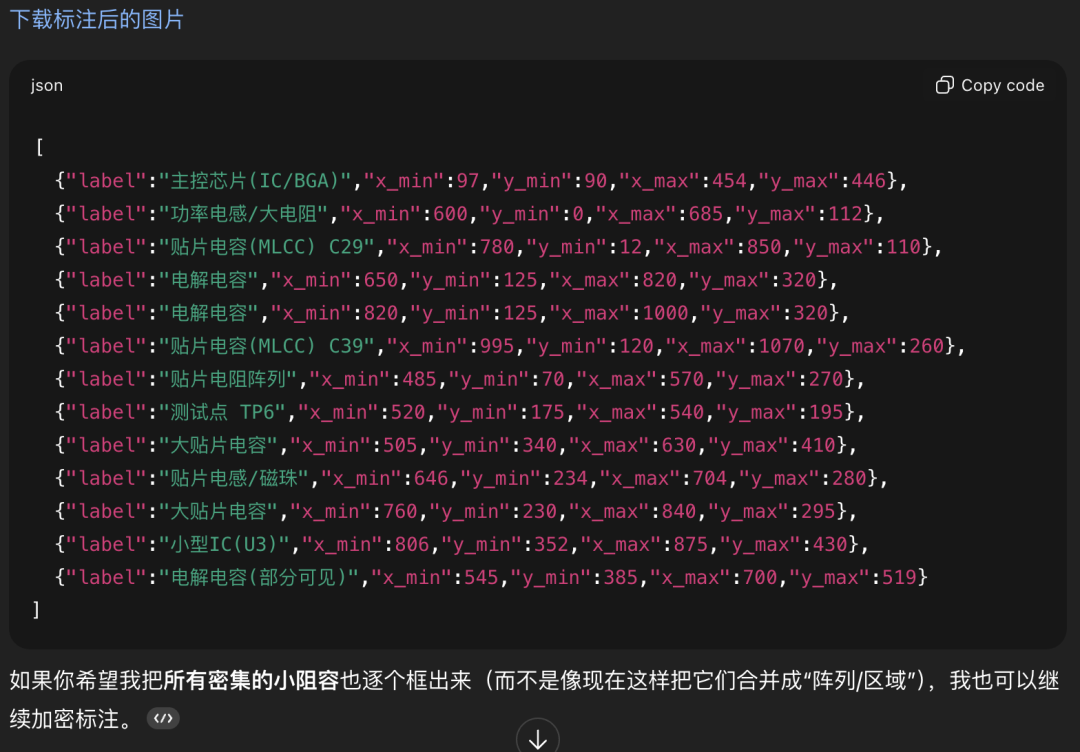
为了验证网上流传的GPT-5.2和Gemini-3的比较,我们从网上找到了一张非俯视水平视角的芯片图,分别要求GPT-5.2和Gemini-3用Boundingbox对元器件进行标注:
GPT-5.2

Gemini-3.0

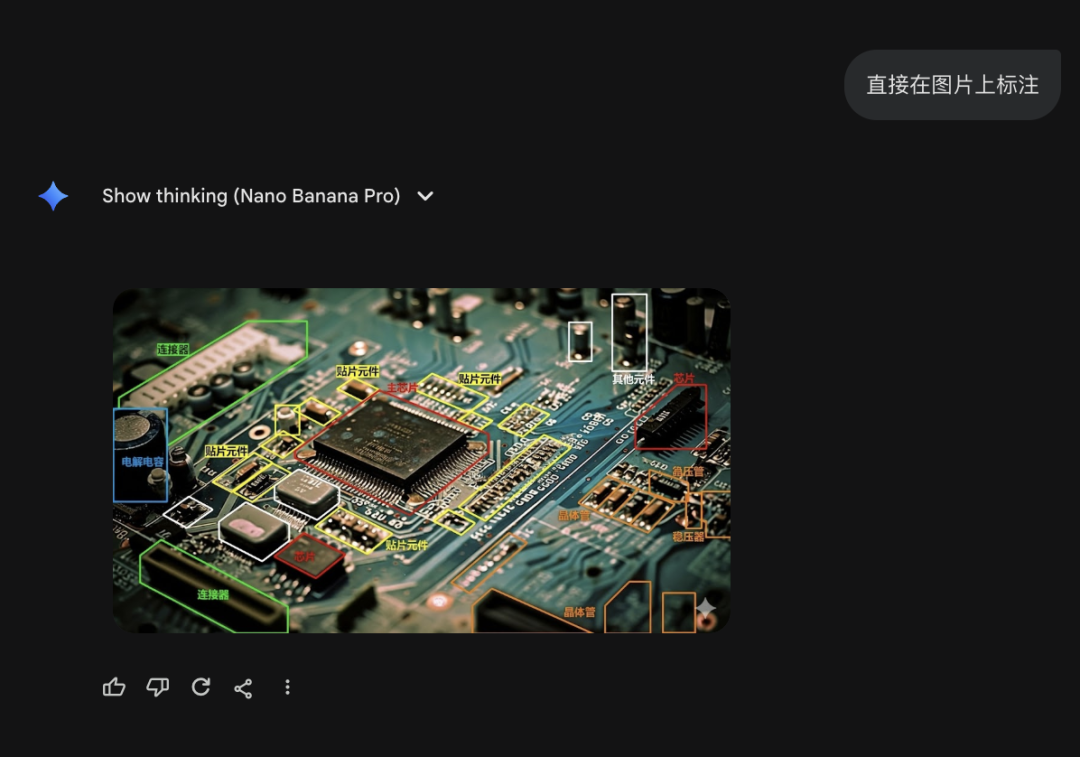
初看起来,似乎Gemini标注的更加符合元器件的轮廓,但实际情况是,当要求以Boundingbox标注时,GPT-5.2和Gemini虽然都返回了矩形框的4个坐标,但如果仔细观察坐标会发现Gemini给出的坐标已经超过原始图片尺寸(860x482)。
当要求Gemini直接在图上绘制边框的时候,Gemini调用的是Nano Banana Pro,给出的结果看似对元器件进行了标注,但坐标和之前给出的没有关系,而且,标注后的图像被修改了(左上白色连接器部分)……

因此仅凭X上的推文没有办法简单的判断模型的强弱,我们还是建议根据自己的需求场景实际测试。
结语
经过几个快速的测试,GPT-5.2的能力提升确实很显著,对于专业AI开发者和深度用户来说,应该能够带来很大的提升。但此次升级,OpenAI没有释放对应的新功能,官网Blog的首页也不是本次更新。不知道是不是OpenAI在憋真正的大招?

对于普通用来说,这次更新可能只是一般的性能升级,不会对使用体验有太大的影响。目前,ChatGPT的Plus、Pro、Business、Enterprise订阅用户可通过Thinking或Pro模式直接使用GPT-5.2,据说明天会开始推广给所有用户。
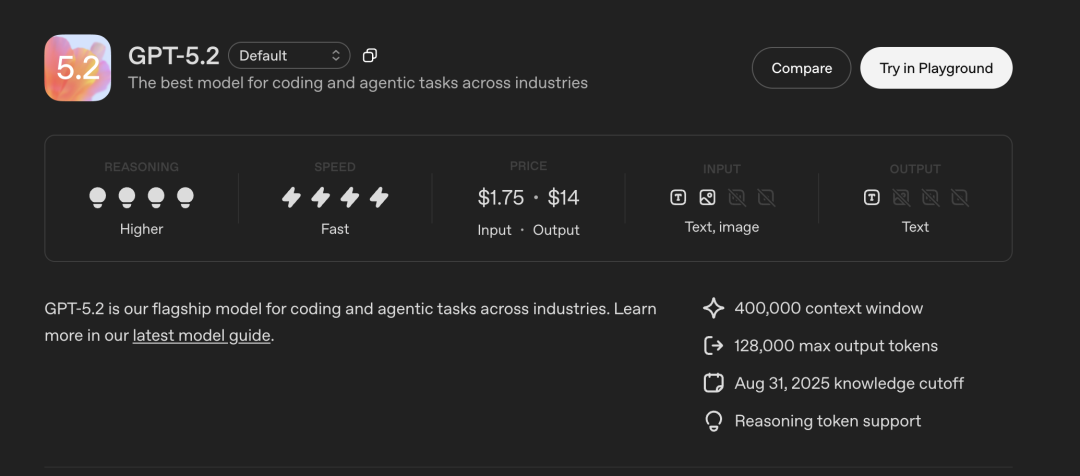
开发者通过API调用时,GPT-5.2的价格略有上升,Thinking版定价为每百万输入token 1.75美元、输出token 14美元,缓存输入可享90%折扣,官方表示虽然单token价格比5.1高,但因效率提升,相同任务的总成本反而更低。
一句话总结,如果你之前就是GPT的付费订阅用户,那么5.2升级会让你觉得订阅不亏;如果你之前是普通用户,那么5.2可能不会让你心动。
GPT-5.2: https://openai.com/index/gpt-5-system-card-update-gpt-5-2/
[2]GPT-5.2官方博客: https://openai.com/index/introducing-gpt-5-2/
-- 完 --










