
作者丨Jiahui Zhang等
编辑丨具身智能之心
本文只做学术分享,如有侵权,联系删文
更多干货,欢迎加入国内首个具身智能全栈学习社区:具身智能之心知识星球(戳我),这里包含所有你想要的。
Teaser
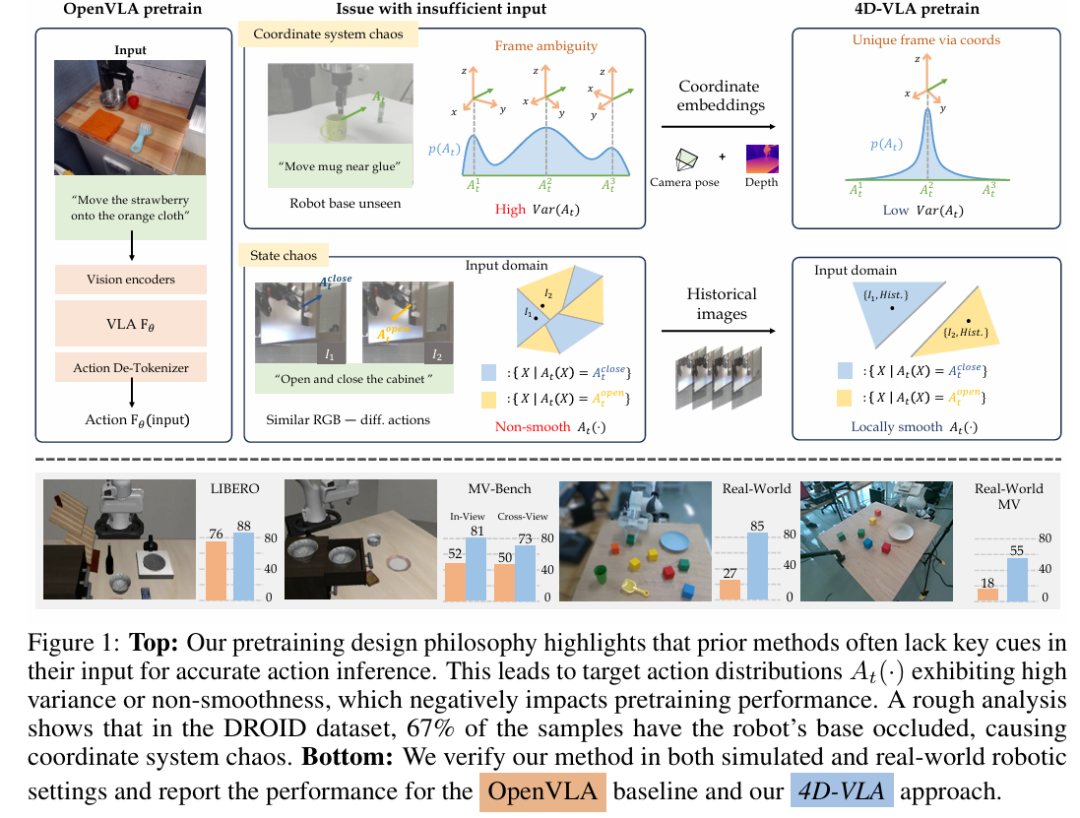
在 VLA pretrain 中,单帧 RGB + 文本的传统输入往往缺失关键时空线索,导致坐标系混乱与状态模糊——即同一观测下可能对应多种动作分布,显著拉低预训练效率。为破解这一瓶颈,我们提出 4D-VLA:通过将3D 空间 + 历史帧融入预训练输入,从而抑制混乱分布,提升模型在复杂场景中的performance。
Insight
如何从多源机器人数据中高效提取可迁移的运动知识,仍是制约通用操作策略的关键瓶颈。当前公开的 DROID、LIBERO 等大规模数据集为数据驱动控制提供了可能,但输入信息的不完整与不一致严重削弱了预训练的效果。
现有范式的局限
以 OpenVLA 为代表的主流方法,仅使用单帧 RGB 图像 + 文本指令作为条件来拟合动作分布 。这种极简输入导致目标分布呈现两类混乱:
坐标系混乱(Coordinate System Chaos) ─ 当图像未能完整覆盖机器人本体时,难以推断其精确位姿,动作需在多个候选坐标系间选择,分布方差急剧上升。论文统计显示,在 DROID 数据集中约 67 % 的样本存在此问题。 状态混乱(State Chaos) ─ 单帧视图缺乏时间线索,视觉上相似的观测可能对应完全不同的动作,如对称轨迹或柜门微小开合等,导致 局部不连续、难以拟合。
这种 高方差 / 非平滑 的目标分布直接拖慢模型收敛,并在跨场景泛化时暴露明显短板。
坐标系混乱(Coordinate System Chaos)——为何单帧 RGB 会拖垮预训练?
在现有 VLM-式预训练中,动作 默认以机器人自身坐标系为基准输出。然而,当输入仅是一张 RGB 图像时,模型往往看不到机械臂底座,也就无法推断“原点”在何处;于是同一张图像可能兼容多套坐标系,导致:
动作参照系冲突
对于人类来说,“向前移动 5 cm”总是以底座为原点; 对模型而言,底座方位不可见, 既可能属于坐标系 (镜头左侧)也可能属于 (镜头右侧)。
在大规模数据中,这类“Coordinate System Chaos”样本占比可达 67 %(DROID 统计); 相同视觉观测 被映射到多种候选动作 ,让条件分布 呈现多峰、离散特征。
在最小化 NLL 或回归损失时,不同坐标假设给出的梯度方向往往相反,网络学习到的只是加权平均的错误动作; 结果是收敛速度下降,跨场景泛化更差——如附录实验所示,坐标扰动越大,纯 RGB 模型成功率陡降,而加入 3D 坐标的模型保持稳定。
解决思路
4D-VLA 通过 深度图 + 相机外参 将每个像素反投影到世界坐标,显式嵌入学习式 3D 位置编码,确保视觉 token 与机器人坐标对齐,从而缓解坐标系歧义,收敛动作分布方差,并带来更快、更稳的预训练。
坐标系混乱影响分析
为了定量评估“坐标系混乱”对 VLA 模型的破坏性,我们设计了一个受控实验,分两步进行:
人为注入混乱:从 LIBERO-SPATIAL 中挑选若干轨迹,对每条轨迹渲染 30 个不同视角。随后在机器人坐标系上施加随机平移 与旋转 ,模拟预训练数据中常见的“看不见底座”情形。 对比训练:分别用 纯 RGB(无 3D 信息)和 RGB-D + 3D 坐标编码 两种输入重新训练模型,检验 3D 线索能否抵御混乱带来的性能退化。
混乱注入细节
对动作标签 与相机外参 施加同样的坐标变换:
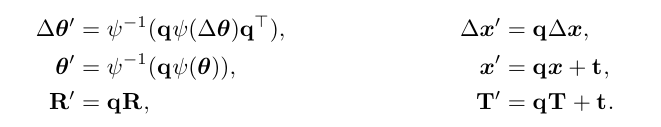
其中 为欧拉角到旋转矩阵的映射。 混乱等级: Level 0:不添加旋转; Level 1‒3:在 z 轴随机旋转 ,并在 内随机平移。
实验结果
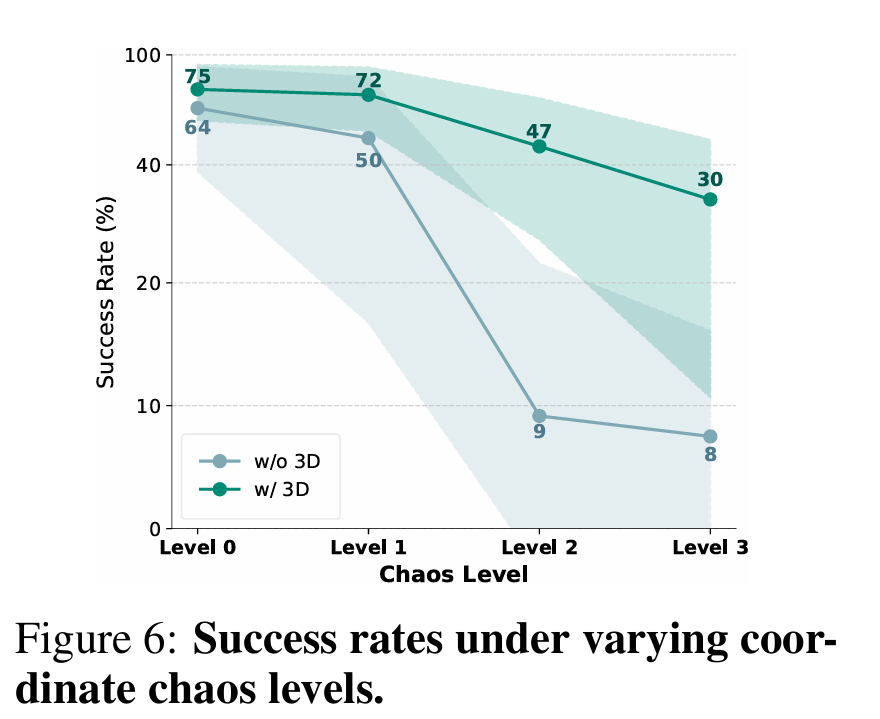
如 Fig. 6 所示,未加入混乱时两种模型成功率都在 64 % – 75 % 左右,而 3D 模型略优;随着混乱加剧:
无 3D 的纯 RGB 模型性能几乎随旋转角度呈断崖式下降,Level 3 仅剩 8 % 成功率。 加入 3D 坐标编码 后,模型在最极端的 90° 旋转下仍保持 30 %,且整体方差显著收敛,验证了 3D 线索能有效校准跨视角坐标系。
结论
坐标系漂移会导致动作标签在训练阶段相互冲突,严重拖慢模型学习;而通过 深度 + 位姿 生成的 3D 空间 token 能将视觉与机器人坐标对齐,大幅缓解性能退化。这一发现印证了 4D-VLA 在多视角、跨场景场合下的稳健优势,为后续大规模预训练提供了理论与实验依据。
Method
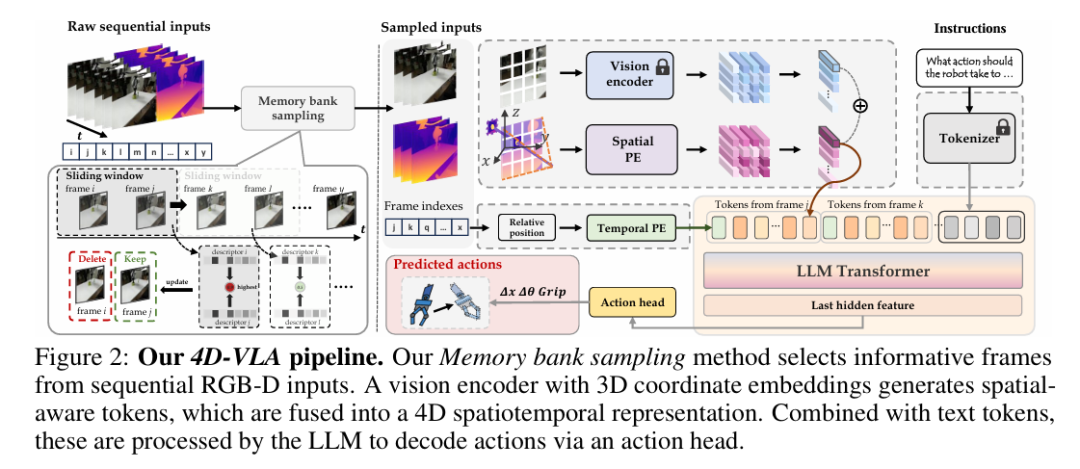
Spatial-Aware Visual Tokens
❝解决“坐标系混乱”关键一步:把每个视觉 patch 映射到统一 3D 坐标,并与语义特征对齐。
特征提取
深度反投影
对下采样后的深度 结合相机内外参 计算世界坐标:
3D 位置嵌入
我们将可学习的位置信息嵌入用于编码 3D 坐标,并与原始视觉特征图按元素相加,得到更具空间表达力的空间视觉特征。随后,这些特征经 InternVL中的 MLP,生成空间视觉 token
4D Representation with Multi-Frame Encoding
❝在时间维度补充上下文,缓解“状态模糊”。

滑动窗口:取时间窗 (如 20 帧)的序列 。
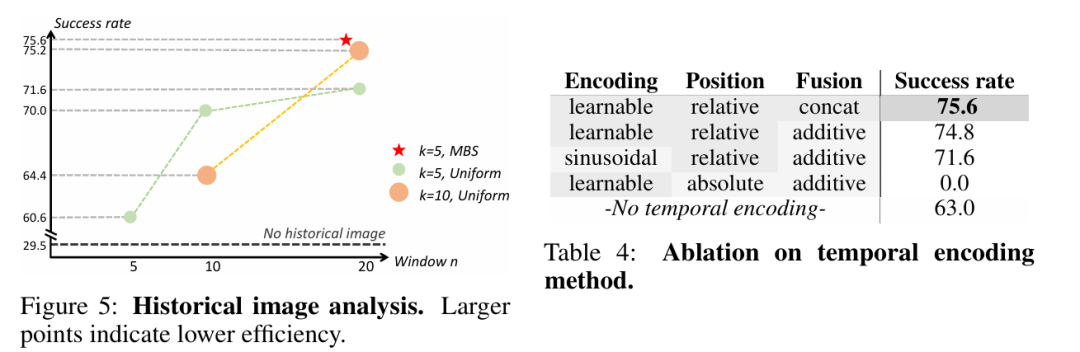
Memory Bank Sampling (MBS)
设记忆池 ,最大容量 。 相似度函数 —— 默认对视觉描述符做余弦相似度。
保持时间顺序; 恢复为 ; 最新帧 必定留存。
直接把 追加到 末尾;结束。
动机:在固定容量 的记忆池(Memory Bank)中,始终保留 最新帧 并尽量去除与其余帧冗余度最高的旧帧;同时保持时间顺序不被打乱。
步骤:
初始化
处理新帧
**返回更新后的 **。
先把 追加到 尾端,使 。
仅计算相邻帧对的相似度:
找到相似度最大的相邻帧对 。
删除其中较早的一帧 (即对的左侧),从而:
若
否则
时间位置编码
由于采样间隔非均匀,引入可学习 相对时间 token。
每帧构成一对 ,再与指令 token 联合:
3.4 损失函数
Experiments
Pretrian
数据集与评估环境
我们首先在 DROID 真实机器人数据集上进行预训练。DROID 共收集了 76 000 条人类示范轨迹,累计约 350 小时 交互,覆盖 564 个室内外场景与 86 项操控任务。每条轨迹同时提供两路第三人称视角和一路腕部视角的 RGB-D 流,能够充分呈现多视角、多物体、多任务的真实分布。
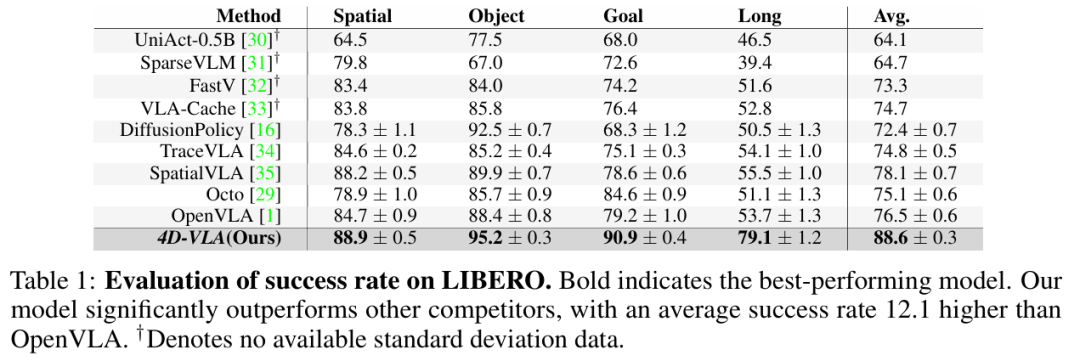
下游评测采用 LIBERO 仿真套件,其包含四类任务集 —— SPATIAL、OBJECT、GOAL 以及针对长程推理的 LONG。在标准配置下,LIBERO-90 为短程场景提供 90 个子任务,LIBERO-LONG 则额外给出 10 个长程子任务;总计 130 个子任务,每个子任务各有 50 条由主摄和腕摄录制的演示轨迹,专门用于考察知识迁移与终身学习能力。
预训练流程
数据预处理 所有 RGB-D 帧被统一缩放至 448 × 252。我们对每条轨迹按时间均匀下采样到 100 步动作,并去除静止帧与超过 600 动作的异常长序列。动作用末端执行器的 “当前-目标” 差分表征,平移量乘 15,旋转(欧拉角)乘 5 做数值归一化。
模型 主干采用 InternVL-4B。时间窗口设为 20 帧,并通过 Memory Bank Sampling 动态选取 5 帧历史 + 当前帧 进入网络。RGB-D 特征首先经原始视觉编码器提取;随后把基于相机外参反投影得到的 3D 坐标送入一个可学习的 3D 位置编码 模块,与语义特征逐元素相加;融合后的特征再通过一个下采样率为 4 的 MLP,其权重继承自 InternVL 预训练模型。
稀疏深度处理 DROID 中深度存在空洞,因而我们先对每个视觉 patch 取平均深度;若该 patch 超过 90 % 像素无效,则跳过 3D 位置编码,相当于一次随机 dropout,同时起到数据增广作用。
训练细节 实验中 冻结视觉编码器,其余参数全部微调;方向损失权重 。学习率采用余弦退火,初始值 2e-5;批量大小 512, 1 epoch(约 20 k 步) 。全部训练在 8 张 NVIDIA A6000 (96 GB) GPU 上用时约 96 小时。推理阶段启用 FlashAttention 并使用 bf16 精度,显存占用约 8 GB。
LIBERO evaluation
MV-Bench evaluation
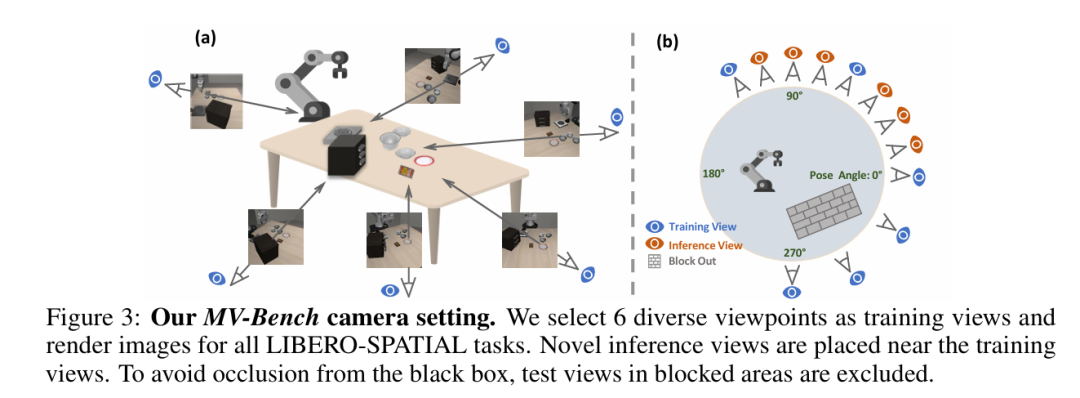
基准动机与数据构建
为系统评估机器人视觉-语言-动作模型对多视角输入的理解与泛化能力,我们基于 LIBERO-SPATIAL 重新渲染并推出 MV-Bench:对每条轨迹在机器人前方 270° 视场内均匀采样 6 个训练视角与 6 个测试视角。评测分为两种设置 — In-View:训练与测试使用同一组视角;Cross-View:测试只在未见过的 6 个新视角进行。为避免底座被遮挡,我们剔除了黑箱遮挡区域内的角度,最终相机布置如 Fig. 3 所示。
评估协议
动作成功率(task success rate)作为唯一指标。 所有方法均在 LIBERO 短程任务上微调,再按照 In-View / Cross-View 两套视角做闭环控制测试。 4D-VLA 的微调设置与主实验保持一致(时间窗 20、MBS 取 5 帧等),保证公平对比。
主要结果
| 4D-VLA | |||
|---|---|---|---|
| In-View | 81.0 % | +28.8 pp | |
| Cross-View | 73.8 % | +23.3 pp |
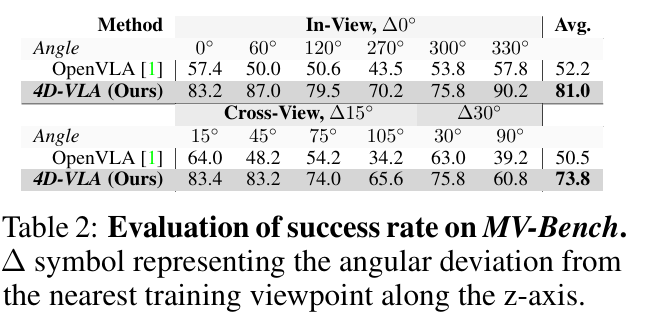
详细角度拆分见论文 Tab. 2:在 0°、60°、120°、270°、300°、330° 六个训练视角下,4D-VLA 的成功率均超过 70 %,最高达 90.2 %;而在 15°–105° 等 全部未见视角 上仍保持 60.8 %–83.4 % 的稳定表现,全面压制基线。
结果分析
时空提示带来视角不变性
通过 3D 坐标对齐与历史帧记忆,模型可在不同相机坐标系间共享统一世界坐标,从而显著缓解视角切换带来的图像-动作映射漂移。
跨视角泛化优于现有方法
在 Cross-View 设置中仍能保持 73.8 % 成功率,说明 4D-VLA 学到的策略不依赖于特定成像角度,而是聚焦于物体间的真实空间关系。
MV-Bench 证明 4D-VLA 不仅能在已见视角下高效执行任务,更能稳健迁移到完全未见的新视角,充分验证了其空间感知与视角泛化能力。
Real-world evaluation
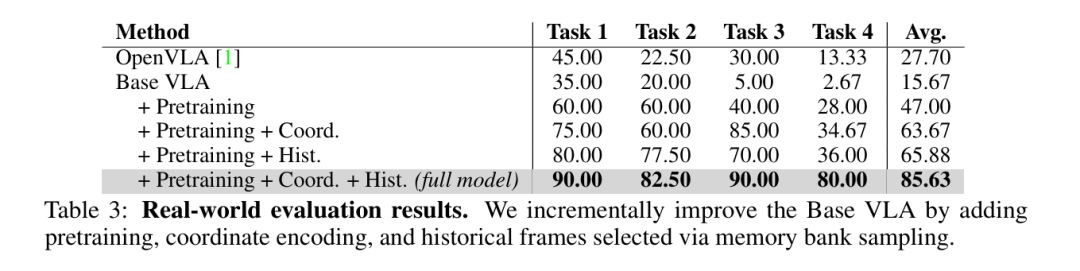
我们在真实 Franka 机械臂平台上构建了 4 个具身操控任务,全面考察模型的空间推理、泛化以及指令理解能力(参见 Fig. 4):
空间泛化(Spatial Generalization)
机器人需将黄色方块从训练时未出现的位置放入指定托盘,检验其对全新空间布局的适应性。
抗干扰鲁棒性(Robustness to Distractors)
在存在大量杂物的背景下,将两个绿色方块放入托盘,评估模型抵抗视觉干扰的能力。
精确堆叠(Precise Placement)
要求将黄色方块精准叠放在红色方块之上,强调厘米级动作预测准确度。
结构化指令执行(Instruction Following)
机器人需按 颜色顺序 执行多步抓放(如 “红 → 绿 → 蓝”),考察其对序列化语言指令的遵循程度。
评测指标
任务 1 & 3:以成功率(成功次数 / 总次数)计分。 任务 2:每正确放置一个绿色方块得 1 分(每轮最多 2 分),满分 40 分,最终得分除以 40 归一化。 任务 4:共有 5 组颜色顺序,每组 5 次试验;每正确放置一个方块得 1 分(每轮最多 3 分),满分 75 分,最终得分 / 75。
实验设置
我们以 InternVL-结果与分析
Base VLA(无预训练)在全部任务上都落后于 OpenVLA,说明仅靠单帧 RGB 难以完成精确操控。 加入 3D 坐标编码的预训练 后,即使下游仍用单帧 RGB,性能大幅反超,验证了我们 4D 预训练在空间对齐上的优势。说明确实是再与训练层次起到了作用,模型预训练的更好了。 在短程任务(任务 1、3)中,坐标编码 尤其提升了精确堆叠表现,证明物体-坐标对齐对厘米级操作至关重要。 在长程多步任务(任务 2、4)中,模型常能完成第一步却失败于第二步,暴露出时间上下文缺失的问题;MBS 引入历史帧后显著改善这一现象,帮助模型维持多步推理链。 整体而言,当上游预训练输入(坐标感知、时序结构)与下游任务匹配 时,知识迁移效果最佳;即便下游只用单帧 RGB,模型仍保持强列的空间可解释性和跨任务泛化性。
通过 3D 坐标显式对齐与 MBS 时间补全,4D-VLA 在真实机器人环境中实现了更高精度与更强鲁棒性,为大规模多摄、跨场景应用奠定基础。
Ablation

Multi-view real-world evaluation
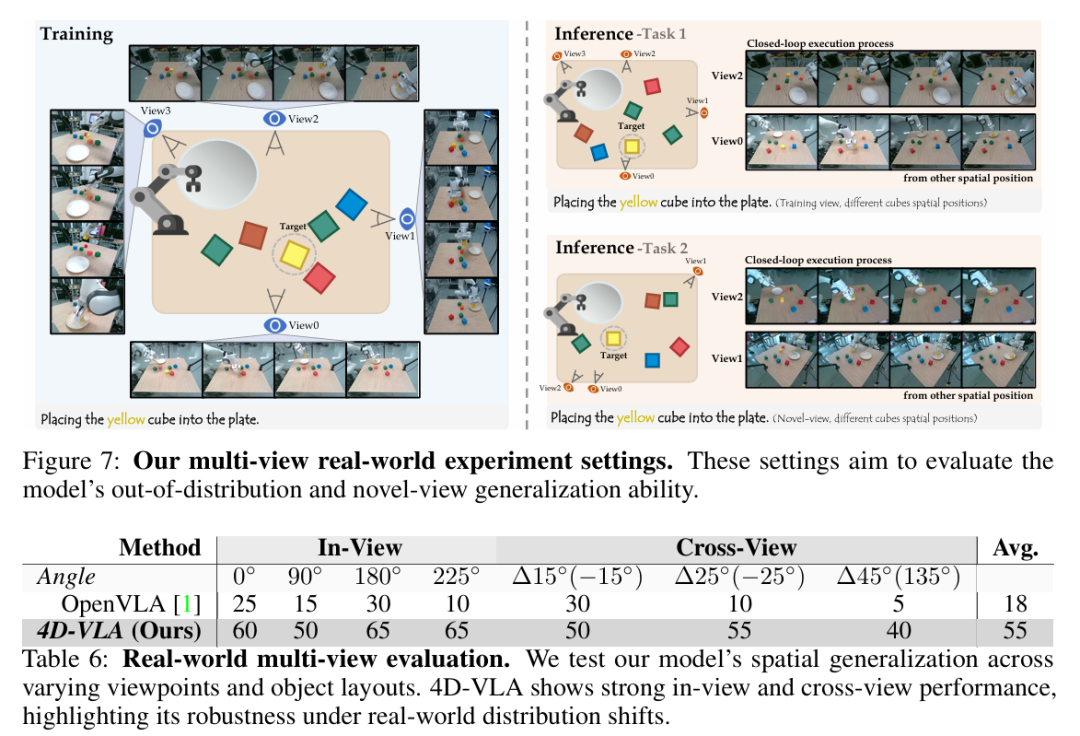
为进一步验证 4D-VLA 在真实多摄像头场景下的泛化能力,我们搭建了一个四摄像头固定阵列,对同一操作过程从 0°、90°、180°、225° 等不同朝向同步采集演示,并设计两项更具挑战的任务:
Task 1 – 分布外泛化(Out-of-distribution Generalization)
机器人需在 背景杂物、托盘位置、干扰物体均与训练阶段不同的情况下,将黄色方块放入盘中,考察对物体布局与背景变化的鲁棒性。
Task 2 – 新视角泛化(Novel-view Generalization)
训练仍使用 4 视角数据,但推理阶段仅输入 额外第 5 个从未见过的摄像头视角,评估模型对视角变化的稳健性。
每个视角-任务组合录制 50 条;所有模型统一训练 20 epoch,并在 20 轮随机化测试中以成功率计分。
结果分析
视角内稳健性
在训练时见过的 0°、90°、180°、225° 四个视角上,4D-VLA 的成功率始终保持在 60 %–65 % 区间;相比之下,OpenVLA 的成绩只在 10 %–30 % 之间波动。这表明一旦引入显式 3D 坐标对齐,模型对 物体位置和背景扰动 的敏感度大幅降低,能够在相同摄像机视角下稳定重复操作。
跨视角泛化能力
当摄像机绕工作台额外旋转 ±15°、±25°、±45°(训练阶段从未出现)时,4D-VLA 仍能维持 40 %–55 % 的成功率,而 OpenVLA 迅速跌至 5 %–30 %。这说明 4D-VLA 学到了与视角无关的 世界坐标系表征,能够在陌生相机坐标中快速重建目标相对位置并生成正确动作。
性能随角度的衰减特征
4D-VLA 的成功率随视角偏移呈 平滑下降;即使在最极端的 ±45°,性能只比 In-View 低约 15 pp。相对而言,OpenVLA 曲线陡峭且不稳定,进一步凸显 坐标编码 + 历史帧记忆 对高角度视差的缓冲作用。
现象分析
坐标对齐 使得模型能在不同摄像机坐标中共享统一世界坐标系,确保视觉特征与动作标签一致。 历史帧记忆 提供时序上下文,帮助模型在新视角下快速定位目标并规划多步动作。 即使在最极端的 ±45° 视差下,4D-VLA 也仅出现小幅性能回落,而 OpenVLA 成功率剧烈震荡。
参考
[1]4D-VLA: Spatiotemporal Vision-Language-Action Pretraining with Cross-Scene Calibration











