在芯片设计中,片上系统(SoC)通过将CPU、GPU、内存、I/O和模拟组件等集成到单个芯片中而占据主导地位。苹果的M3就是一个典型的例子,它几乎将所有功能都集成到了一块硅片上:

图1:苹果的M3是一个将逻辑、内存、I/O等所有功能集成在一颗芯片上的SoC。
但这种方法已经达到了极限。例如,随着芯片尺寸的增大,良率会下降:
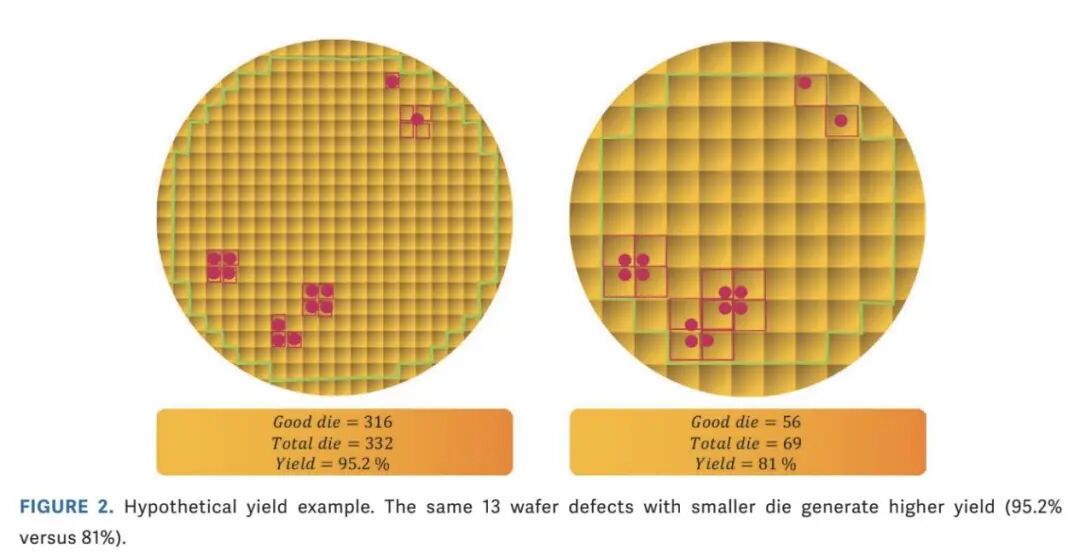
图2:预估良率示例:同样是13个晶圆缺陷,如果裸片尺寸更小,则良率会更高(95.2% vs 81%)。
这是一个虚构的例子,但它表明,虽然两块晶圆的缺陷数量相同(图2中红色标记),但当裸片尺寸较更小时,晶圆可以生产出更多可用的芯片。
物理限制也是一个因素。光罩尺寸限制(即光刻工具一次曝光可以图案化的最大面积)将裸片尺寸限制在800mm²左右,现今许多SoC的目标是突破这一限制。
此外,在3nm等先进工艺节点制造大型裸片的成本高得惊人,只有大批量生产的产品才能负担得起。而且,SoC要求所有组件都使用相同的尖端工艺节点,即使某些模块(例如模拟或射频模块)并不需要先进工艺。既然28nm工艺节点就够了,为什么还要为3nm晶体管付费呢?
半导体行业如何才能继续向前发展?
答案是:Chiplet!
Chiplet是一种小型专用硅片,是一个更大系统的组成部分。
与将计算、I/O、内存控制器和模拟功能集成到一个大型芯片中的传统单芯片SoC不同,Chiplet是将这些功能分解到不同的裸片中。

图3:Chiplet是一种模块化系统,将来自不同供应商和技术节点的不同Chiplet合在一起,而不是将所有功能都集成到一个单芯片片上系统中。
基于Chiplet的设计将多个专用裸片集成到一个封装中,形成一个系统。每个Chiplet都可以采用最适合其功能的工艺节点,例如逻辑电路采用3nm工艺,模拟电路采用28nm工艺,从而最大限度地降低成本,提高性能和功耗效率。
Chiplet系统常被称作“多芯片模块(MCM)”,多个在同一基板上互连的独立裸片(Chiplet)组合在一个封装中。
2.5D中介层和采用混合键合技术的3D堆叠等先进封装技术可以将Chiplet连接起来,实现Chiplet之间的高带宽、低延迟连接。
AMD是首家将Chiplet带入主流生产的公司,深入且详细地提供了一个模块化设计如何在现实中进行应用的案例。
AMD EPYC服务器采用模块化MCM设计。AMD的CPU和I/O裸片组合在一起,可以创建针对不同需求量身定制的SKU——从只有8个内核的入门级产品到拥有192个内核的高性能产品:

图4:第5代AMD EPYC处理器架构。
AMD解释了为什么采用Chiplet方法以及如何对不同的裸片采用不同的工艺技术:
AMD EPYC处理器最具影响力的创新是首次在第二代EPYC处理器中引入了混合多裸片架构。我们认为,随着时间的推移,在单片处理器设计中提高内核密度将变得越来越困难。一个主要的问题是,CPU内核与驱动外部通路连接到内存、I/O设备和可选的第二个处理器的模拟电路采用不同的工艺技术。在设计单芯片处理器时,这两种技术是相互关联的,这可能会阻碍产品快速上市。
是的,采用不同的工艺节点!AMD继续说:
AMD EPYC处理器已创新地将CPU内核和I/O功能分离到不同的裸片中,因而可以按照各自的进度开发这些裸片,并使用适合其功能的工艺技术进行生产。随着工艺技术的进步,CPU裸片的尺寸不断缩小(图5)。如今的“Zen 5”内核采用4nm工艺,“Zen 5c”内核采用3nm工艺,而I/O裸片则沿用上一代的6nm工艺,这样的方法使它们能够应对从最小的内核系统到计算密集型服务器的任务。

图5:AMD创新地将CPU和I/O进行分离,降低了CPU的工艺技术成本。
这种想法并不是刚出现的。戈登·摩尔在1965年的一篇开创性文章中推测,“用更小的功能模块构建大型系统,然后将这些模块单独封装并互连起来,可能成本更低”。
摩尔是对的!
正如AMD EPYC的例子所示,基于Chiplet的系统具有诸多优势。
Chiplet体积小,较小的裸片尺寸可以提高晶圆良率,因为缺陷影响一颗裸片的概率会随着尺寸的减小而降低。在单芯片SoC中,一个缺陷就可能导致整个芯片报废。然而,使用Chiplet技术,可以从每片晶圆上获得更多功能正常的裸片,从而降低每个Chiplet的成本。提高良率是降低单位成本的有效途径。
光罩尺寸限制了单颗裸片的尺寸,使用Chiplet技术,设计人员便可绕过这一限制。例如,AMD的MI300A和MI300X系统通过将多个Chiplet集成到一个封装中,使浮点运算性能(FLOPS)显著提升,其本质是将更大系统拼接在一起,而单个光罩难以处理的如此大的系统。

图6:AMD的MI300A和MI300X系统将多个Chiplet集成到一个封装中,使浮点运算性能(FLOPS)显著提升。
注意,MI300A和MI300X看起来很相似!图6直观地展示了Chiplet的价值以及现有IP的复用。
英伟达也绕过了光罩尺寸的限制,将具有两个“光罩尺寸”的GPU裸片集成到一个GPU中,虽然严格来说这并不是Chiplet:

图7:英伟达将具有两个“光罩尺寸”的GPU裸片集成到一个GPU中。
这是一个模块化的多裸片设计,两个受光罩尺寸限制的裸片通过10 TB/s的互连连接。严格来说它不是Chiplet,但理念是一样的:将系统分割成多个芯片,然后使用高带宽封装将这些芯片重新连接起来。
Nvidia可以构建GB200 NVL4这样的系统,包含四个光罩尺寸的GPU和两个由Arm的Neoverse V2内核驱动的较小Grace CPU:

图8:英伟达的GB200 NVL4系统。
正如我们在AMD EPYC的例子中看到的,Chiplet实现了异构集成,即一种“混合搭配”的工艺技术,这在之前的单芯片SoC设计中是无法实现的。每个Chiplet都可以采用最合适的节点进行制造,而无需强制所有组件都使用最新工艺。
一旦Chiplet经过验证,就成为可复用的设计模块,其概念类似RTL库中的IP模块。例如,一个经过验证的I/O Chiplet可以集成到多个产品线(多个SKU)中,相较从头开始设计新的芯片,可以显著减少设计工作量,并将一次性工程(NRE)成本分摊到多个SKU。当然,每个新产品仍然需要进行系统级的验证和集成。这种方法可以节省大量时间和成本,同时降低设计风险。
需要注意的是,Chiplet的可复用性很大程度上取决于接口标准化和系统兼容性。具有定义明确的标准化接口(例如遵循UCIe规范的Chiplet)的Chiplet可复用性很高。相比之下,自定义接口的Chiplet可能需要在每次集成时都重新进行适配。虽然对于每个新产品仍然需要对供电、散热和信号时序等系统级设计进行验证,但核心功能验证已经完成。
Chiplet最激动人心之处就在于设计复用,这也是AMD扭转颓势的关键原因,取得了远超自身规模的成就。AMD首席技术官Mark Papermaster解释道:
大约十年前,我们开始重新规划CPU路线图。我们重新设计了工程流程,其中的一项措施是采用更模块化的设计方法,即开发可复用组件,然后根据应用的需求进行组合。
AMD和英特尔等行业引领者率先采用了Chiplet技术,Chiplet的设计复用优势也可以降低芯片设计小公司定制芯片的门槛。
利用设计复用,AMD这样的公司能够更快地将产品推向市场。经过验证的Chiplet(例如AMD的CPU内核)可以直接使用,而无需重新设计整个SoC。
正如Cadence所指出的,构建首款基于Chiplet的产品需要艰辛的努力,但后续迭代会受益于此,因为上市时间更短了:

图9:Chiplet设计对成本的影响。
在首次设计中,分离架构需要额外的开销,但后续几代产品的开发成本将显著降低,SKU选择范围也将扩大,如图3(b)所示。
此外,复用还可以将开发成本分摊到多个产品中。一旦构建出高性能Chiplet,就可以嵌入到许多设计中,从而加快开发速度并减少一次性工程费用。
这种模块化方法具有战略灵活性。通过在设计中利用预先验证的Chiplet组装系统(称为后期绑定),芯片设计公司可以将最终的SKU决策推迟到生产前,这些公司无需完全进行重新设计,从而快速响应不断变化的客户需求或应对临时的硬件变化。
如果可以将这些Chiplet卖给其他公司,会怎样呢?
理论上讲,基于Chiplet的系统可以实现更高的良率、更低的成本、更优化的流程、更快的迭代速度以及可扩展的复用性,从而构建出更灵活高效的芯片设计模型。
下面的例子也显示了这些优势。
目前,Chiplet的优势主要惠及大公司,但小公司也渴望未来分得一杯羹!
以Ampere为例。Ampere是一家初创公司,两个月前被软银收购。
Ampere公司的AmpereOne平台采用Chiplet技术,将计算、内存和I/O功能分离,并针对功耗、性能和工艺节点对每一部分进行优化:

图10:AmpereOne对功能进行分解。
这款采用台积电5nm工艺的计算芯片包含192颗定制Arm内核。内存和PCIe控制器被分离到独立的7nm I/O裸片。
这种模块化设计使Ampere能够使用相同的内核芯片构建多种SKU。例如,AmpereOne和AmpereOne M的唯一区别是增加了两个内存芯片,而无需新的计算裸片。采用这种方法,客户无需重新进行设计即可扩展性能和I/O,从而降低时间和成本。
这正是Chiplet的优势所在!
另一个例子是,初创公司d-Matrix完全基于Chiplet架构构建了其Corsair推理平台,每个双卡系统使用16个小裸片。

图11:利用最先进的倒装封装(FCBGA)和专有超高速互连技术(DMX Link),将4个Chiplet以全互连方式集成于一体。
为何选择Chiplet?根据白皮书的描述:
d-Matrix通过使用更小的Chiplet裸片来扩展内存和计算能力,从而提高良率、降低成本并克服光罩尺寸限制。
同样重要的是,d-Matrix可以灵活地混合搭配Chiplet,以跟上不断发展的AI工作任务,而无需重新设计芯片。他们的架构支持小型交互式模型的低延迟推理和大型批处理作业的高吞吐量计算,这些都基于相同的模块化芯片。
深入MI300A,也可以看到Chiplet的优势。

图12:AMD的MI300A。边缘的黑色方块是HBM。中间两列彩色的部分,左列有四个XCD(加速器裸片),右列顶部还有两个,右列下面有三个CCD(CPU裸片)。其他彩色部分是I/O裸片。
MI300A将CPU Chiplet(CCD)与AI加速器Chiplet(XCD)捆绑在一起。这些裸片采用最先进的制造工艺,同时该系统也封装了采用之前的工艺节点制造的I/O裸片(IOD)。
MI300A复用了用于EPYC CPU服务器的CPU Chiplet(Zen 4)。

图13:Chiplet复用及模块化的优点。
AMD的Sam Naffgizer解释道:
“将GPU分解成Chiplet后,我们可以对计算部分采用最先进的工艺技术,而对芯片的其余部分采用更适合缓存和I/O的技术。”以MI300为例,所有计算部分都采用台积电的N5工艺,这是目前最先进的工艺,也是英伟达顶级GPU采用的工艺。但N5工艺并不能给I/O功能和系统缓存带来好处,AMD为它们选择了成本更低的N6工艺。这两种功能可以构建在同一个Chiplet上。
对上面图中彩色的两列进行旋转,如下图所示,其中包含XCD(加速器Chiplet)、CCD(CPU Chiplet)和IOD(I/O裸片)。

图14:将图12中彩色的两列旋转。
专有Chiplet并非唯一选择。
在制造Chiplet时,也可以获得IP授权。下面是一些使用Arm技术进行Chiplet设计的Fabless设计公司的示例。
亚马逊的Graviton3处理器是超大规模公司使用Chiplet的一个例子。亚马逊的计算Chiplet并非专有,而是使用了Arm的IP:

图15:亚马逊的Graviton3处理器使用Arm的Neoverse V1内核。
据SemiAnalysis称,Graviton3处理器的内核是一个64核计算裸片,采用最先进的工艺节点,并使用Arm的Neoverse V1内核。它的周围有6个I/O Chiplet:4个DDR5内存控制器和2个PCIe 5.0控制器,都采用低成本的成熟工艺制造。

图16:亚马逊的Graviton3处理器是一个大的计算Chiplet,周围是I/O Chiplet。
亚马逊将I/O移至单独的Chiplet,而不是将所有组件都塞到一个芯片上,因此处理器可以保持较低的温度并降低功耗——功耗约为100W,远低于大多数竞争对手的CPU功耗。
SemiAnalysis称,亚马逊并没有从头开始设计处理器内核,而是采用了Arm的现有Neoverse V1。
Neoverse V1 CPU可提供先进的单核性能,适用于为要求严苛的高性能计算(HPC)、云端HPC以及人工智能/机器学习任务。
利用Arm IP,亚马逊可以专注在能够带来显著优势的领域——例如系统如何分解Chiplet、这些组件如何封装以及整个系统如何设计、构建和部署。
据The Next Platform报道,AWS的下一代Graviton 4延续了Chiplet架构:

图17:第一代到第四代Graviton。
但是,就像其他任何事情一样,采用Chiplet分离式设计也需要做出取舍。
Chiplet解决了单片SoC存在的许多问题,但同时也带来了新的问题。将系统分解为多个裸片会给供电、通信和封装带来新的挑战。每个裸片边界都成为一个新的接口,需要进行设计、验证和维护。
Chiplet之间的互连会增加延迟和功耗。裸片外部的连接比内部导线速度更慢,能效更低。以前只需通过短距离金属层传输的信号,现在必须穿过封装基板或中介层,增加了延迟和能耗。
下面的例子很好地显示了连接Chiplet的不同方式。

图18:Chiplet的不同连接方式。
片外通信比片内互连耗电量大得多。我们将在以后的文章中深入探讨先进封装技术,即Chiplet的连接。
在基于Chiplet的系统中,供电也变得更加复杂。每个裸片的电压、电流和瞬态特性可能各不相同,尤其是在采用不同的工艺技术或对于计算、存储或I/O等不同功能的Chiplet。
在单片SoC中,电源通过统一的金属堆栈传输,从而实现紧凑、低阻抗的供电。但在分离的系统中,电源必须经过凸点、微凸点和/或中介层,路径变长,会引起电压损耗并降低电压精度,使供电噪声更大、效率更低,因此需要精心的封装协同设计。
散热也变得更加复杂。
这些Chiplet通常执行不同的任务,采用不同的工艺节点,产生的热也不均匀。这会导致发热点分散,而不是平滑的热梯度,从而难以有效冷却系统。

图19:多GPU系统的热分布图:(a)使用Compact-2.5D方法的布局方案(b)采用无中继器非流水线化芯粒间互连的TAP-2.5D解决方案(c)采用“加油站”式互连的解决方案。
裸片的放置位置会影响热点分布。
散热问题变得更加复杂,尤其是在采用3D堆叠技术时。
只有当封装将多个Chiplet连成一个完整的系统时,它们才能正常工作。这就需要采用先进的技术:2.5D中介层、硅桥、3D堆叠和混合键合。这会增加封装的成本,降低良率及可靠性。
系统性能越来越依赖于先进的封装技术,封装的重要性前所未有!
对封装的重视影响着半导体价值链。代工厂、OSAT和EDA供应商不再是辅助角色,而是变成战略合作伙伴。Chiplet系统的设计、验证和组装需要新的工具、更紧密的协作以及端到端的集成。想设计基于Chiplet的系统?当然可以,但您的EDA工具必须支持这种设计!
测试装置也必须相应进行调整!对已知合格的裸片进行测试至关重要,因为任何一颗不合格的裸片都可能危及整个系统。集成前的全面验证对于控制成本也必不可少。
安全模型也必须相应发展!在Chiplet中,每一颗裸片都有被攻击的危险。如果第三方裸片的供应链比较复杂,会怎样?是否存在后门?Chiplet市场概念尚处于早期阶段,但随着第三方裸片的使用越来越多,安全问题值得关注。
物理和电气接口的标准化还不够。为了使Chiplet真正模块化,还需要通用的软件和固件层。Chiplet必须公开其功能,能够被系统发现,并能可靠地进行互操作。随着生态系统的成熟,可复用的固件和预集成软件栈与硬件本身一样重要。
在封装时,Chiplet确实增加了系统级复杂性。
AMD这样的大设计公司早就涉足并实现了Chiplet,其中的技术涉及构建定制互连(例如AMD的Infinity Fabric)。但半导体行业的长期目标是建立一个生态系统,让任何芯片设计人员都能从Chiplet中获益。
标准的制定使Chiplet之间能够进行互操作。芯片设计人员可以从不同的供应商那里进行采购,加快了开发速度。如果没有标准,Chiplet仍将然被限制在孤立的系统中;有了标准,Chiplet就能真正变成“乐高积木”——可复用、可互换且可扩展。
通用Chiplet互连高速协议(UCIe)就是使Chiplet之间实现互操作性的开放标准,类似PCIe之于扩展卡,支持从低成本有机基板到2.5D中介层和硅桥的各种封装,既适用于预算有限的设计,也适用于高性能设计。
UCIe涵盖完整的裸片-裸片堆栈:物理层(信号如何在裸片间传输)、协议层(数据如何传输)和软件模型(Chiplet是如何被发现、管理和编程的)。
UCIe使Chiplet的连接标准化,为真正的Chiplet市场打开了大门。如果没有共享接口,Chiplet将被限制在各公司自己的生态系统中。有了通用标准,各公司知道其产品能够在更多的系统中工作,就可以专注于构建最好的计算、内存或I/O芯片。对系统设计人员而言,这意味着更大的灵活性、更快的开发速度和更多的选择。
这种转变也重塑了供应链。设计公司无需自行开发所有Chiplet,而是可以从各个专业公司那里购买。这种模块化方法能够加速开发并促进第三方创新。
长远愿景是建立Chiplet市场:经过验证、可互操作的裸片模块可以像乐高积木一样拿来即用,随时可以组装,相当于硅片形式的IP块。
但仅仅依靠标准还无法实现这一愿景,市场还需要值得信赖的第三方来定义共享架构,强制执行合规性,并协调从硬件到软件的整个技术栈产品。
Arm的Chiplet System Architecture提供了一种将芯片分解并连接其组件的标准化方法,不仅涉及Chiplet之间的通信方式,还涵盖它们如何在硬件、软件和系统设计中进行集成。UCIe负责处理Chiplet之间的物理连接,而Arm的方法则侧重于它们如何作为一个系统协同工作。
Chiplet代表着芯片设计和制造的未来——“分解式设计”时代。
设计人员无需将所有功能都集成到单个芯片上,而是将系统分解成更小的模块,每个模块都完成特定的任务,通常采用最适合的制造工艺。
随着标准的普及以及Arm等大公司的加入,我们可能会看到真正的Chiplet市场出现——来自众多厂商的组件可以像积木一样轻松组合起来。
未来几年,Chiplet的构建、交付和销售方式的变化令人期待。
参考英文原文:
Chiplets and the Future of System Design
https://www.chipstrat.com/p/chiplets-and-the-future-of-system











