VLA等各类模型的快速发展,催生了一系列测试基准的出现。然而,模型能力的增长速度,远超已有benchmark的边界。与之而来反映出的则是具身领域一直存在的问题:缺少测量模型真实能力的“尺子”。
在缺乏统一、可复现、可规模化评测体系的情况下,研发决策开始重新依赖“经验”和“直觉”。而这,正在成为具身智能从研究走向工程落地过程中的最大系统性风险。
(一)难以分辨“好与坏”的阶段
具身领域正在逐渐把“讲的故事”转变成生产力,其间,我们看到了很多有趣的内容:医疗机器人努力让康复变得更加容易;移动操作机器人“完成重复枯燥的劳动” ,让大家看到解放双手的可能;足式机器人的灵活也看到了极端场景落地的希望。
然而,在“完美”动作的背后,或多或少隐藏了一些“行业共识”:
-
专做1-2个场景,当人形机器人把衣服叠的还不错时,可以说基本完成了家用场景的测试; -
测试case少,当四足机械狗能够灵活翻越部分障碍物时,可以说已经能够“救援救灾”了; -
没有边界测试标准,某个基模动辄使用百万级、千万级甚至更大规模的数据优化后,直觉上一定性能很好。
但真实情况却是:
-
测试场景不够规模化,更换了这个房间的布局,人形机器人可能就“惊慌失措”; -
测试要求与标准不统一,“想像空间”较大;
模型的上限究竟在哪里?在完成某个特定动作的同时,是否会丢失执行其它动作的能力?机器人在特定房间内的任务,换成户外或者其它空间是否可以work?
依赖经验的判断很难有效指导后续研发,毕竟“不能管中窥豹,只见一斑”。
(二)具身真正需要的是“全面泛化能力”
如果一台没经过充分测试的机器人去酒店收拾房间、叠被子。稍有不慎,就会出现“杯子打破”、“被子像使用过”的状态。近两年的展会上,出现过很多“过拟合”的动作,可以丝滑到细节和人手操作一致,但换个场景就“手足无措”。
也许这个问题存在于每个行业的早期,但若是当下某家具身公司还没有把重点放到泛化测试与提升上,估计很难有机会进入决赛圈了。行业真正需要的是“见过世面”的机器人,而不是碰到点新情况就“惊慌失措”,各家都需要知道自己模型的上限在哪里。

但若想要做到真正的泛化,就需要同时提升“训练数据的质量和数量”和”测试场景的多样性和规模”。前者保证足够多的学习摄入,后者则保证“上岗前的测试”。
当下,训练数据正在逐渐变得容易获取,目前行业基本收敛为四条路线:仿真生成、真机遥操、UMI和人类视频。根据不同阶段的需求,各个团队都有自己的选择。
而评测,反而比训练更难 scale:因为它必须稳定、可复现、可对比。
(三)无法规模化的真机评测下,仿真成了“唯一解”
在具身智能的评测上,行业已经形成共识:真机评测在结构上不可能规模化。
虽然近两年发布了数个多任务真机评测平台,相比于之前在规模上有一定提升,但任务的多样性、复杂度以及数量还未达到“充分验证模型边界的标准”。

在成本、周期、硬件稳定性与安全风险等关键因素上,真机方案无法支持大规模、并行、可重复的评测流程。随着模型复杂度和任务空间的指数级增长,依赖真机评测不仅效率低下,也难以支撑工程决策。
这也意味着一个事实:仿真不是备选方案,而是具身评测唯一可行的路径。
1)现有的评测,显得“有心无力”
虽然具身领域已经推出了多个仿真 benchmark,但都不能满足“边界测量”的需求。长期停留在“学术级”下的评测,也让各家摸不清彼此的上限。
以目前广泛使用的几类具身仿真 benchmark 为例:
-
LIBERO
-
主要评测:通过一组标准化的操作任务,验证策略在特定 manipulation setting 下是否可行; -
缺点:但任务规模有限,场景变化受控,更多用于算法验证而非能力上限测量。 -
RoboCasa
-
主要评测:聚焦家居环境中的操作任务,在研究阶段极具价值; -
缺点:其资产与场景主要服务于实验设定,对复杂真实世界交互的覆盖有限。 -
BEHAVIOR
-
主要评测:提供了结构化的日常行为任务定义; -
缺点:在物理建模精度、任务规模与运行确定性方面,仍难以支撑工程级评测需求。

这些 benchmark 确实在研究阶段发挥了不可替代的作用,能很好验证某类算法或表示是否成立以及在有限任务集合中比较相对性能。然而,它们并非为以下目标而设计:
-
测量模型在复杂真实世界中的能力边界; -
支持跨团队、跨版本、跨时间的工程级可比评测; -
为下一轮数据生成、模型结构与系统设计提供明确反馈信号;
2)从“验证实验”到“能力测量”,中间缺了一层
目前,学术级 benchmark 普遍存在以下问题:1)任务与场景规模不足,难以覆盖真实世界中长尾、多组合、高耦合的交互情形;2)策略在边界条件下如何失败常常被忽略的;3)各自维护独立的仿真环境、资产规范与任务定义,重复造轮子,结果难以统一对比。
在这样的前提下,评测更像是“验证实验”,而非真正意义上的“能力测量”。当具身智能进入工程化与规模化阶段,这种评测范式已无法回答一个关键问题:
“模型究竟能不能在真实世界中稳定工作?能力边界在哪里?下一步该优化什么?”
3)仿真不再稀缺,工业级的评测系统已迫在眉睫
具身领域真正缺失的,从不是仿真本身,而是一套能够面向工业级决策、统一和可规模化的、确定性的具身评测基础设施。也正是在这个背景下,工业级评测 才从一个“研究附属工具”,转变为具身智能走向成熟阶段的核心基础设施。
(四)NVIDIA和光轮智能联合搭建了一套完整的开源评价体系
近日,CES大会上NVIDIA联合光轮智能正式推出Isaac Lab-Arena。基于Isaac Lab的仿真技术栈与算力底座,NVIDIA这次使得大规模、确定性的仿真成为可能。这家具身领域的“军火供应商”野心逐渐彰显:那就是推动领域的有序化,建立规模化的机器人评测基础设施,迈入评测驱动的时代。
如果把过去的 LIBERO、RoboCasa、BEHAVIOR 看作是一套套精心设计的“考题”,那么 NVIDIA Isaac Lab–Arena 做的事情本质上是:把“出题”这件事本身,升级成了一套可规模化运转的工业级评测体系。
这也是它与传统仿真 benchmark 的根本差异。

1)让任务创建与评测变得更加灵活
在已有的各类学术 benchmark 中,一个任务往往意味着:为某一个机器人、某一个物体、某一个场景单独设计。在研究阶段虽然合理,但代价也非常明显:每增加一个任务,工程成本线性上升,评测体系无法扩展。
Isaac Lab–Arena 则选择了另一条工程路线,不再是“写死的脚本”,而是可组合、可扩展的模块。在 Arena 中,一个可运行的评测环境,是由物体、场景、任务、本体等模块按需组合、即时生成。
更关键的是,Arena 引入了 Affordance(可供性) 这一中间抽象层:任务不再绑定具体资产,而是绑定“可交互语义”。换句话说:
-
“打开门”不再等于“打开某一扇门” -
而是对所有具备 Openable 可供性的对象成立
这一步看似抽象,但它直接决定了评测体系能否跨物体、跨场景、跨本体扩展。
2)从“少数case”,到“多样化任务”的工程化
在传统仿真评测中,任务多样性往往依赖人工“更换”物体和场景。Arena 的核心设计之一,是把任务多样化这件事本身工程化。
在统一评测管线下,同一个任务定义可以系统性地:
-
替换不同对象(microwave → power drill) -
替换不同机器人本体(Franka → 人形机器人) -
替换不同环境结构(厨房 → 工业工位)
而不需要为每一次变化重写评测逻辑,这使得评测从“验证某个动作是否成功”,升级为系统性覆盖一整个任务分布,去观察策略的泛化边界。
这正是学术级 benchmark 很难做到、但工程决策迫切需要的能力。
3)策略无关,不绑定任何特定形态
还有一个经常被忽视、但对工业级评测至关重要的点是:Arena 并不绑定任何特定策略或模型形态。也就是说,Arena被明确设计为一个 policy-agnostic 的评测框架:
-
不关心策略是 VLA、世界模型、RL 还是混合系统; -
只关心:在统一任务分布下,策略的表现如何变化;
配合 Isaac Lab 的并行能力,评测可以在大量环境中同时运行。通过固定的随机种子、控制初始条件,使得不同版本、不同模型的结果可以被稳定对比分析。这一步,把评测从“实验演示”,推向了类似 CI 的工程流程。
4)评测不再是孤立终点,而是数据与训练闭环中的一环
在 Arena 的设计中,评测并不是一个独立的“验收阶段”。官方给出的工作流非常明确:评测可以与示教采集、数据生成、后训练过程形成闭环。
例如:
-
通过遥操采集示教 -
扩展为更大规模的数据 -
用 Arena 评测策略失败模式 -
再将评测信号回流到下一轮数据与训练设计中
在这种模式下,评测的输出不只是一张排行榜,而是可操作的工程信号。
5)统一核心,避免评测生态持续“各自为政”
更重要的是,Isaac Lab–Arena 并不是一个封闭系统。NVIDIA 在设计之初,就将Arena定位为一个开源、可扩展的评测底座,希望不同 benchmark、不同团队,能够在同一核心之上共建评测生态。
(五)喜欢独立开发的NVIDIA,为什么选择了光轮智能?
1)对NVIDIA来说,合作共建从来不是“默认选项”
在 NVIDIA 的工程体系中,“共建”从来不是默认选项。在绝大多数情况下,NVIDIA 要么选择完全自主研发(例如 Isaac Lab,本身就是从底层仿真框架到工具链长期由 NVIDIA 团队独立推进;要么在极少数场景下,与同样处于全球技术金字塔顶端的机构进行深度联合研发(例如在 Newton 物理引擎上,与 Google DeepMind、Disney 等展开合作)。
正因如此,Isaac Lab–Arena 选择引入共建方,本身就是一个极其罕见、且值得被解释的工程信号。

对于仿真技术积累雄厚的NVIDIA来说,这次并不是因为缺乏仿真能力,而是因为 Arena 所要解决的问题,已经不再是“一个仿真Solver”的问题。更详细点的描述,是一套工业级评测基础设施的完整工程闭环。
2)Arena 的目标是评测系统的“端到端成立”
Isaac Lab–Arena 并不是为了提供更多可运行的仿真任务,而是构建一套能够被长期复用、扩展、对比的工业级评测底座。这对共建方提出了极其苛刻、且同时成立的工程要求:
-
不只是“能写 solver”,而是能将 solver 与真实世界的物理参数对齐; -
不只是“能做资产”,而是持续产出面向评测的 SimReady 交互级资产; -
不只是“能跑 benchmark”,而是让评测结果真正回流到数据生成与系统迭代。
换句话说,Arena 需要的不是某一个技术模块,而是一个从物理真实到工程使用完全闭合的仿真体系能力。
3)为什么光轮智能是极少数“工程形态匹配”的共建方?
从全球范围来看,真正具备全栈自研仿真能力的团队本就凤毛麟角,而光轮智能正是其中极为独特的一类。其技术体系并非围绕单点能力展开,而是覆盖了完整的仿真工程链路:
-
Solver 层:面向复杂接触、柔性体、失败模式的物理求解能力 -
SimReady Assets 层:以“交互正确性”为目标,而非展示效果 -
Framework 层:支持规模化任务生成、评测与复用 -
Application 层:直接服务于评测、合成数据与训练流程
这意味着,光轮智能并不是在 Arena 中“补充某一个模块”,而是在工程层面,与 Isaac Lab–Arena 的目标形成端到端的能力对齐。即使是在全球范围内,同时具备底层物理仿真能力、工业级资产生产能力,以及系统化应用经验的团队,也极为稀缺。
4)Arena需要更多“真实客户”的验证
在技术之外,还有一个常被忽视、但对 Arena 成败至关重要的现实因素:“评测基础设施最终必须被大量模型团队和机器人公司真实使用”。
NVIDIA 在底层框架与算力层面拥有无可替代的优势,但其工程体系天然更偏底层,与一线客户在具体评测需求、失败模式定义、数据闭环等方面,存在一定距离。

而光轮智能已经长期服务于全球最主要的具身智能与世界模型团队,深度参与过:
-
仿真资产在真实训练与评测中的使用方式 -
评测任务如何系统性暴露策略失败模式 -
哪些评测指标,能够真正指导模型与系统迭代
从工程视角看,光轮智能在 Arena 中承担的角色,更像是将 NVIDIA 的评测框架延伸到真实工业使用场景中的“工程放大器”。
5)一次罕见的封闭式联合开发
据悉,Isaac Lab–Arena 是由 NVIDIA 与光轮智能团队,在 Santa Clara 与 Zurich 进行的数月封闭式联合开发的成果。在这一过程中,光轮智能深度参与了 Arena 的评测层与任务层架构设计及核心实现,而非仅作为使用方或适配方存在。
这也解释了为何 NVIDIA 官方最终将光轮智能列为 Isaac Lab–Arena 的核心共建方--这是一场在工程层面高度互锁的联合设计。
从更高层次看,这次合作并不意味着 NVIDIA 改变了其一贯“自己做”的研发哲学。恰恰相反,它说明了当具身智能进入评测驱动、工程驱动的新阶段时,工业级评测基础设施本身,已经复杂到需要一种单一组织难以独立覆盖的能力组合。
而光轮智能,正是少数在工程形态、能力闭环与产业经验上,能够补齐这一关键拼图的共建方。
(六)RoboFinals 把 Arena 变成“可直接使用的尺子”

在 Isaac Lab–Arena 提供统一评测框架之后,光轮智能并未止步于“框架共建”,而是进一步回答了一个更工程化的问题:
如果 Arena 是评测的操作系统,那么工业界真正需要的,是一套可以“即插即用”的评测基准。
基于这一目标,光轮智能在 Arena 之上构建并推出了 RoboFinals ——一个面向真实工程决策的工业级仿真评测平台。

1)250+ 评测任务,数量之外更是系统性覆盖
作为 Isaac Lab–Arena 的首个深度用户,光轮智能基于统一评测底座,开源了超过 250 个可直接运行的评测任务,其中包括 LW-RoboCasa-Tasks 与 LW-LIBERO-Tasks 两大任务集,覆盖家居与工业等核心应用场景。
与传统 benchmark 不同,这些任务并非孤立示例,而是在同一评测框架下形成可对比、可扩展的任务簇。其设计目标并不是“展示成功动作”,而是系统性暴露策略在不同条件下的失败模式与能力边界。
2)一把真正可用的“工业级尺子”,需要三层同时成立
从工程视角看,RoboFinals 之所以能够作为工业级评测基准成立,是因为它在同一体系内同时覆盖了三层关键维度:
本体层(Embodiment)
-
支持人形机器人、机械臂等多类主流本体,在统一评测协议下进行跨本体对比,避免“换平台就重测”。
场景层(Scene)
-
从家居到工业,再到更复杂的真实环境结构,支持由简单到高难度的场景梯度,而非单一理想化环境。
任务层(Task)
-
覆盖操控(manipulation)、locomotion、移动操作等核心能力维度,直接对应当前主流本体构型的真实使用需求。
这三层的统一,使评测不再是“某一个 demo 的表现”,而成为对模型能力结构的系统性测量。
3)已进入主流模型团队的真实评测流程

目前,RoboFinals 已被多家领先的世界模型与具身模型团队采用,作为内部评测基准使用,其中包括 通义千问 等主流模型体系。这意味着,RoboFinals 的角色并不是“发布榜单”,而是嵌入到模型研发流程中,持续提供评测信号。
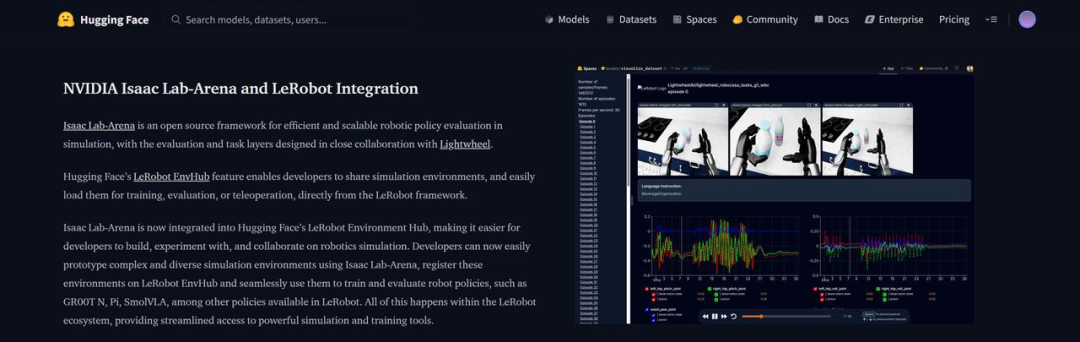
4)从工具到基础设施:接入 Hugging Face LeRobot 生态
值得注意的是,Isaac Lab–Arena 及其上构建的评测任务,已被纳入 Hugging Face 的 LeRobot 生态。这意味着,RoboFinals 中构建的 250+ 评测任务,可以被全球 1300 万 Hugging Face 开发者 直接调用。
这一点的意义,并不在于“曝光度”,而在于一个更本质的变化:
评测开始从“研究附属工具”,演化为“可被广泛复用的公共基础设施”。
(六)写在最后
评测不是终点,而是起点。
随着具身产品逐渐迈向能力和泛化迭代的阶段,具身测试已经不仅仅是一个验收的“环节”。充分的场景暴露,是落地与工程化不可或缺的,也在不断反哺着算法的优化方向、数据链路的搭建。
Isaac Lab-Arena系列工具的出现,正是具身领域从初期逐渐迈向成熟的标志。
谁在创造真的价值,谁在裸泳?相信很快就会有答案。具身领域,也必将迈入评测驱动的时代。


![2025年中国信号继电器行业发展现状及未来前景展望:工业自动化与新能源领域强力驱动,带动信号继电器规模增至89.69亿元[图]](https://xtechcon-static.oss-cn-chengdu.aliyuncs.com/xtimes/xtimes/images/2025-12-18/694352b0bd801.jpeg)







