
作者丨机器之心
编辑丨具身智能之心
本文只做学术分享,如有侵权,联系删文
而 ReconVLA 获得 AAAI Outstanding Paper Awards,释放了一个清晰而重要的信号:让智能体在真实世界中「看、想、做」的能力,已经成为人工智能研究的核心问题之一。
1月30日(周五)晚19:30,我们很荣幸能邀请到AAAI 2026最佳论文ReconVLA的第一作者宋文轩,做客“具身智能之心”直播间。
本次直播将聚焦一个核心议题:抛开参数堆砌,回归操作任务的本质。
这是具身智能(Embodied Intelligence / Vision-Language-Action)方向历史上,首次获得 AI 顶级会议 Best Paper 的研究工作。这是一次真正意义上的 community-level 认可:不仅是对某一个模型、某一项指标的认可,更是对具身智能作为通用智能核心范式之一的肯定。

-
论文标题:ReconVLA: Reconstructive Vision-Language-Action Model as Effective Robot Perceiver
-
论文地址:https://arxiv.org/abs/2508.10333
-
论文代码:https://github.com/Chowzy069/Reconvla
VLA 模型关键瓶颈:机器人真「看准」了吗?

近年来,Vision-Language-Action(VLA)模型在多任务学习与长时序操作中取得了显著进展。然而,我们在大量实验中发现,一个基础但被长期忽视的问题严重制约了其性能上限:视觉注意力难以稳定、精准地聚焦于任务相关目标。
以指令「将蓝色积木放到粉色积木上」为例,模型需要在复杂背景中持续锁定「蓝色积木」和「粉色积木」。但现实中,许多 VLA 模型的视觉注意力呈现为近似均匀分布,不同于人类行为专注于目标物体,VLA 模型容易被无关物体或背景干扰,从而导致抓取或放置失败。
已有工作主要通过以下方式尝试缓解这一问题:
-
显式裁剪或检测目标区域(Explicit Grounding)
-
预测目标边界框作为中间输出(COT Grounding)
然而,这些方法并未从根本上改变模型自身的视觉表征与注意力分配机制,提升效果有限。
ReconVLA:重建式隐式视觉定位的新范式
为解决上述瓶颈,我们提出 ReconVLA,一种重建式(Reconstructive)Vision-Language-Action 模型。其核心思想是:
不要求模型显式输出「看哪里」,而是通过「能否重建目标区域」,来约束模型必须学会精准关注关键物体。
在 ReconVLA 中,动作预测不再是唯一目标。在生成动作表征的同时,模型还需要完成一项辅助任务:
重建当前时刻所「凝视」的目标区域 ----- 我们称之为 Gaze Region。
这一重建过程由轻量级扩散变换器(Diffusion Transformer)完成,并在潜在空间中进行高保真复原。由于要最小化重建误差,模型被迫在其内部视觉表示中编码关于目标物体的精细语义与结构信息,从而在注意力层面实现隐式而稳定的对齐。
这一机制更接近人类的视觉凝视行为,而非依赖外部检测器或符号化坐标监督。

方法概览
ReconVLA 的整体框架由两个协同分支组成:
1. 动作预测分支: 模型以多视角图像、自然语言指令与机器人本体状态为输入,生成动作 token,直接驱动机器人执行操作。
2. 视觉重建分支: 利用冻结的视觉 tokenizer,将指令关注的目标区域(Gaze region)编码为高保真潜在 token。主干网络额外输出同维度的重建 token,并以此作为条件,引导扩散去噪过程逐步复原目标区域的视觉表示。
重建损失在像素与潜在空间层面为模型提供了隐式监督,使视觉表征与动作决策在训练过程中紧密耦合。

大规模重建预训练
为赋予 ReconVLA 稳定的视觉重建与泛化能力,我们构建了一个大规模机器人预训练数据集:
-
数据规模:超过 10 万条交互轨迹,约 200 万张图像。
-
数据来源:BridgeData V2、LIBERO、CALVIN 等开源机器人数据集。
-
自动化标注:利用微调后的 Grounding DINO 或 Yolo 等方式,从原始图像中自动生成指令对应的目标物体区域(Gaze region),用于重建监督。
该预训练过程不依赖动作标签,却显著提升了模型在视觉重建、隐式 Grounding 以及跨场景泛化方面的能力,并为未来扩展至互联网级视频数据奠定了一定基础。
实验结果

在 CALVIN 仿真基准上,ReconVLA 在长时序任务中显著优于现有方法:
-
ABC→D 泛化任务:平均完成长度达到 3.95,全面领先同期所有对比方法。
-
ABCD→D 长程任务:平均完成长度为 4.23,完整任务成功率达 70.5%。
值得一提的是,在 CALVIN 极具挑战的长程任务「stack block」上我们的方法成功率达到 79.5%,远高于 Baseline 的 59.3%,这说明我们的局部重建作为隐式监督的方法可以在复杂长程任务中实现更灵活的运动规划。
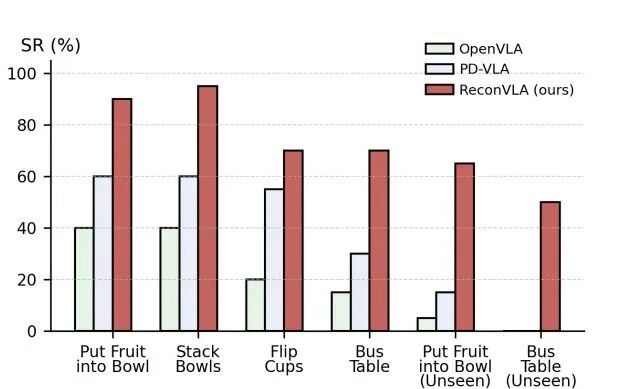
在真实机器人实验中,我们基于 AgileX PiPer 六自由度机械臂,测试了叠碗、放水果、翻杯与清理餐桌等任务。ReconVLA 在所有任务上均显著优于 OpenVLA 与 PD-VLA,并在未见物体条件下仍保持 40% 以上的成功率,展现出强大的视觉泛化能力。

对比于 Explicit Grounding 和 COT Grounding,ReconVLA 在 CALVIN 上获得了远高于前两者的成功率,由此可分析出:
仅用精细化的目标区域作为模型隐式监督可以实现更加精确的注意力,更高的任务成功率以及更简单的模型夹构。

而消融实验表明:
1. 全图重建仍然由于仅有动作监督的基线,因为全图重建提升了模型的全局感知和理解能力。但由于视觉冗余使得在未知环境下难以展现更好的效果。
2. 重建目标区域(Gaze region)具有显著效果,这个机制使得模型专注于目标物体,避免被无关背景干扰。
3. 大规模预训练显著提升了模型在视觉重建,隐式 Grounding 及跨场景泛化的能力。
总结
ReconVLA 的核心贡献并非引入更复杂的结构,而是重新审视了一个基础问题:机器人是否真正理解了它正在注视的世界。
通过重建式隐式监督,我们为 VLA 模型提供了一种更自然、更高效的视觉对齐机制,使机器人在复杂环境中做到「看得准、动得稳」。
我们期待这一工作能够推动具身智能从经验驱动的系统设计,迈向更加扎实、可扩展的通用智能研究范式。






![2025年全球及中国服务器PCB行业产业链、发展背景、市场规模及未来趋势分析:行业规模迅速扩张,核心增量集中于AI服务器领域[图]](https://xtechcon-static.oss-cn-chengdu.aliyuncs.com/xtimes/xtimes/images/2026-02-03/69814903db082.jpeg)

