【科技纵览】2月4日,权威评测机构SuperCLUE正式发布《2025年年度中文大模型基准测评报告》。本次评估共纳入23个来自全球的主流大模型,在数学推理、科学推理、代码生成等六大核心能力维度展开全面比拼。
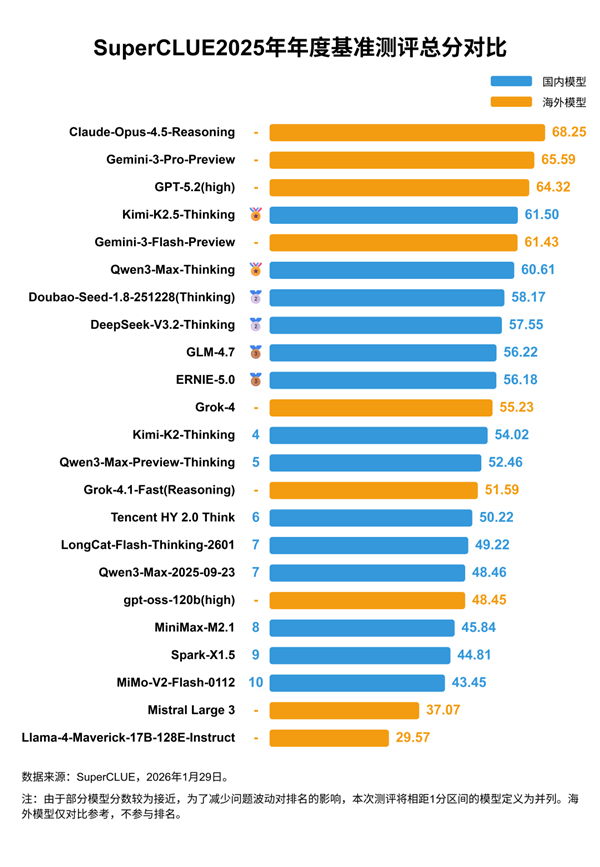
测评结果显示,海外闭源模型仍稳居综合排名前列。其中,Anthropic推出的Claude-Opus-4.5-Reasoning以68.25分摘得桂冠;谷歌的Gemini-3-Pro-Preview和OpenAI的GPT-5.2(high)分别获得65.59分与64.32分,位列第二和第三,共同包揽前三席位。
值得关注的是,国产大模型正加速由“跟跑”转向“并跑”。在开源类别中,Kimi-K2.5-Thinking以61.50分成为国内最佳,位居全球第四;闭源阵营方面,Qwen3-Max-Thinking以60.61分排名第六,展现出强劲追赶势头。
在细分任务中,国产模型实现局部突破:Kimi-K2.5-Thinking在代码生成单项中以53.33分拔得头筹;Qwen3-Max-Thinking则在数学推理任务中与Gemini-3-Pro-Preview同获80.87分,并列世界第一。
整体来看,海内外大模型在开闭源路径上呈现分化格局——闭源领域由海外主导、国产持续追赶,而开源生态则已由国内厂商全面引领,其Top5模型均显著优于海外同类产品。这一趋势表明,中文大模型正进入高质量协同发展的新阶段。










