
> 本文投稿自VLANeXt团队
视觉-语言-动作模型(VLA)在具身智能领域展现出巨大潜力,但当前研究往往缺乏统一、系统性的架构设计规范。为此,MMLab@NTU 联合中山大学提出 VLANeXt 框架。
这项研究没有简单提出一个新模型了事,而是系统性地从12个关键维度,深度剖析了VLA的设计空间。从基础组件到感知要素,再到动作建模的额外视角,每一步都有扎实的实验支撑。
最终的产物VLANeXt,在标准基准LIBERO及泛化性测试LIBERO-plus上,全面超越了包括7B参数模型在内的各类SOTA方法。面对未见过的光照、背景、相机位姿等扰动,其成功率较此前最佳方法大幅跃升了10%。
无论你是刚入局具身智能的小白,还是想进一步优化模型的老手,这份“菜谱”都能帮你找到答案。

论文地址:https://arxiv.org/abs/2602.18532
代码地址:https://github.com/DravenALG/VLANeXt
checkpoints地址:https://huggingface.co/DravenALG/VLANeXt
研究背景
随着大基础模型的崛起,视觉-语言-动作模型 (VLA) 展现出了极大的潜力,通过继承丰富的视觉理解和语言基础,为通用机器人策略学习提供了可扩展的途径。然而,目前的VLA研究领域依然处于一种“原始汤 (primordial soup)”阶段——充满了各种天马行空的探索和设计,但缺乏清晰的架构。
A组说自己的模型很强,取得了非常棒的性能,B组也说自己的模型达到了SOTA。但是由于各家在训练协议和评估设置上的不一致,我们其实很难辨别到底哪些设计选择才是真正起核心作用的。
为了给这个碎片化的设计带来秩序,我们决定回归本质:在统一的框架和评估设置下,从最基础的模型出发,全面重新审视VLA的设计空间。
方法剖析:12个维度的“配方”
RT2模型是VLA模型的起点。
为了帮助大家更好的理解和建模VLA模型的整一个发展流程,我们也从一个类似RT2的模型出发,来一步步添加新的设计构建强大的VLA模型,这样我们可以清晰的看过VLA的发展过程,以及一些关键的模块设计。
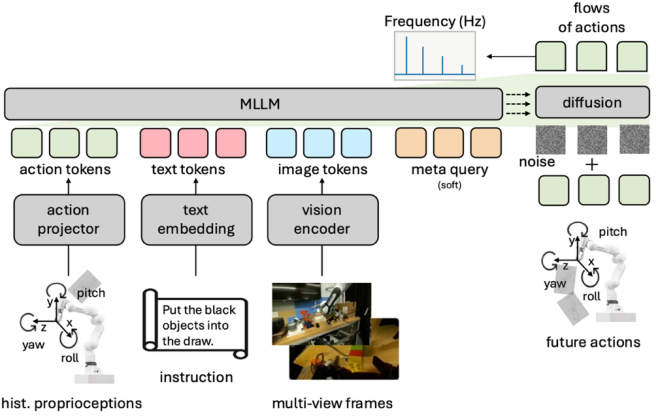
我们的RT2-like的baseline模型是一个非常简单的模型,其基于LLaMA作为backbone,输入是一张当前帧的第三视角照片,以及对应的任务指令文本,输出是下一个时间步的action。action的建模则采用复用最不常用的文本tokens作为动作tokens的方式。损失函数则直接采用分类损失,将每个维度的action分成了256个bins进行学习。整个探索过程的预览如下图所示:
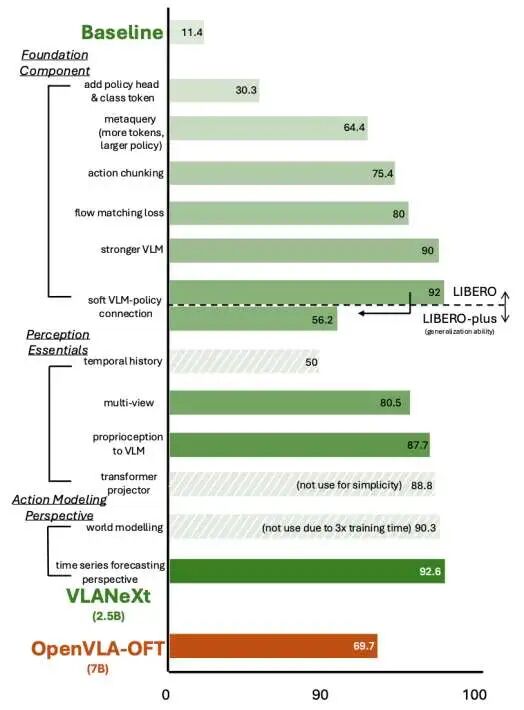
基础组件 (Foundational Components)
基础组建部分,我们探索VLA设计最基础的部分,包括结构的设计,损失函数的设计等。
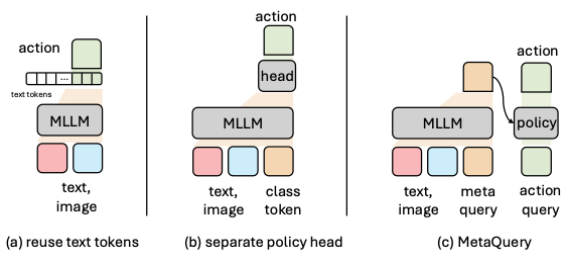
独立策略模块:首先,我们发现解耦语言和行为空间,采用独立的Policy模块比直接复用文本token进行动作分类的效果要好得多。因此,我们将baseline的复用文本token的策略换成了独立的policy head。 深层策略建模:进一步,我们发现独立出来的策略模块需要一定的深度建模,才能学好action的分布。因此,我们进一步将独立的policy head加深,最后我们使用了29层的policy,和VLM的backbone保持一致。
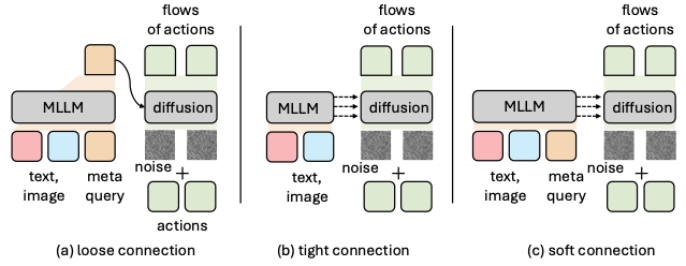
动作分块(Action Chunking):进一步,我们发现引入动作分快(Action Chunking)不仅可以提升推理的速度,还能提升模型的性能。因此,我们进一步引入动作分快(Action Chunking),采用了8的分块大小(另外,根据实验结论,4以上的分块均可以取得不错的性能)。 连续动作建模:在动作学习目标上,我们发现流匹配 (Flow Matching)、DDIM或者直接回归这几种连续建模相比离散分类能达到更强的性能。因此,我们采用了流匹配 (Flow Matching)的损失函数替换了原来的分类的方案。 VLM基座容量:在VLM基座上,我们探索了LlaMA,PaliGemma和Qwen这几种VLM,我们发现,更强的VLM基座可以得到更强的VLA性能。因此,我们最后采用了Qwen3VL-2B的模型,替换了原来的LlaMA的backbone。 💡柔性连接 (Soft Connection):在探讨VLM与Policy如何交互时,我们发现,通过插入可学习的Query作为“隐式缓冲”,然后再进行逐层连接,其效果略优于完全松散或生硬的紧密连接。因此,我们采用了Soft Connection的方式。
感知要素 (Perception Essentials)
感知要素探索VLA输入感知的必要性,探索什么样的输入信息是有价值的。
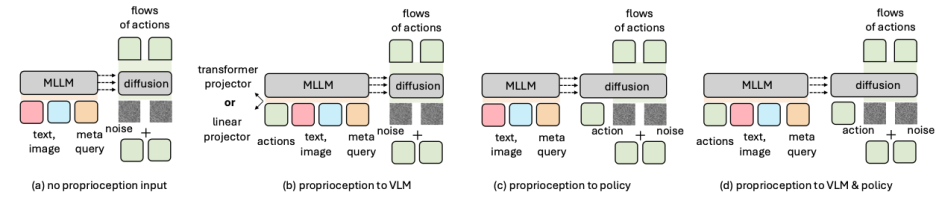
时序历史观察:关于是否需要加历史的视觉信息,我们发现,冗余的时序观察历史并未带来提升,反而可能引入噪声导致性能下降。因此,我们不加入历史的视觉信息,只是用当前帧的图像,维持了原来的设计。高效有用的历史视觉信息建模有待未来进一步探索。 多视角加持:我们发现,结合第三人称和腕部视角的输入,能提供互补的几何线索,让机器人的动作更加准确。因此,我们采用了多视角的方式,替代了原来的单视角(只有第三视角)的形式。 💡本体感觉 (Proprioception) 的归宿:本体感觉该不该加?加在哪里?我们的结论是:将本体感觉注入到VLM端,比不使用或直接注入Policy端效果更好,因为它能在VLM层面更好地与视觉和语言信号融合。因此,我们采用了将本体感知加到VLM侧的方式,替换了原来的不加本体感知的方式。 本体感知的建模:我们进一步探索了本体感知该如何加入到VLM侧,我们探索了linear的建模以及transformer的建模,我们发现,linear的建模已经足够,transformer的复杂建模有可能使得训练不稳定。因此,我们采用了将本体感知经过linear建模加入到VLM中的方式。
动作建模的额外视角 (Action Modeling Perspectives)
动作建模的额外视角主要探索是否可以设计一些multi-task learning的辅助任务来帮助更好的action建模和学习。
世界模型的取舍:采用世界模型的建模来帮助action的学习是如今VLA里的一大流派,称为动作世界模型。我们发现,虽然预测未来图像(世界模型的建模)确实能带来性能提升,但会导致训练时间飙升近三倍。出于对效率的考量,我们在这套实用配方中并没有使用这种建模,维持了原样。 💡时间序列预测视角:进一步,在时间序列预测(time series forecasting)的领域,频域建模也是一个非常有效的流派,而action建模本质上也是一种时间序列的预测任务,因此我们希望在action建模中引入频域建模的思想。具体地,通过离散余弦变换 (DCT),我们引入了简单的频域对齐的辅助损失。这一招将动作生成视为一个时间的整体进行学习,作为了一个正则项,在几乎不增加额外训练开销的情况下,有效提升了模型的泛化能力。
完整的探索过程的实验结果如下所示:

完整的模型VLANeXt的架构图如下所示:
结果验证:用扎实设计一步步铸就高性能
融合上述“配方”的最终产物就是 VLANeXt。
我们证明了,凭借系统化的设计原则,简单的模型架构同样能爆发出惊人的战斗力(并且,我们Huggingface中的checkpoint的效果比论文中report的还要更好,论文中我们report一个偏保守的性能)。
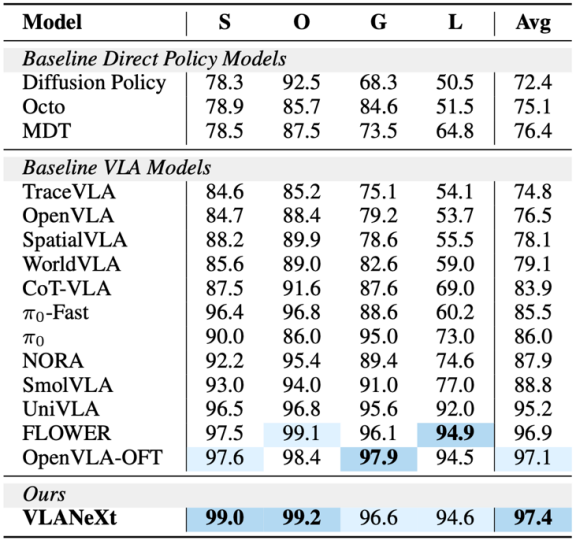
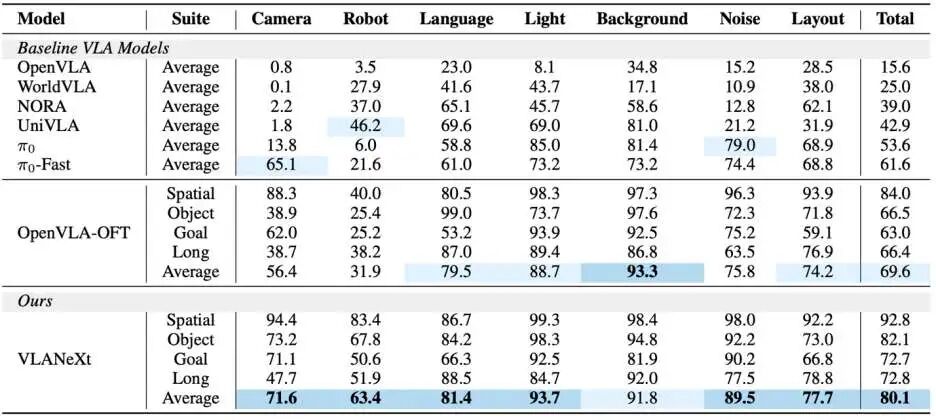
在标准的 LIBERO 基准以及测试模型鲁棒性与泛化性的 LIBERO-plus 基准上,VLANeXt 全面超越了包括 7B 参数模型(如 OpenVLA-OFT)在内的各类 SOTA 方法。
特别是在面对 LIBERO-plus 中未见过的光照、背景、相机位姿或语言指令重写等系统性扰动,**VLANeXt 展现了极强的泛化能力,其成功率较此前最佳方法大幅跃升了 10%**。

在真实的部署和尝试中,VLANeXt不仅在单臂任务(如清理桌面、开抽屉放置物体)表现优异,在没有经过专门双臂预训练的情况下,也能展现出一定的跨形态适应能力,顺利完成了双臂的协作任务(如双臂抬起篮子、双臂清理桌面)。
下面展示了不同场景下VLANeXt模型执行任务过程的可视化。



作者信息
第一作者:来自南洋理工大学MMLab@NTU的一年级博士生伍晓鸣,主要研究具身智能和VLA模型。

共同作者:来自南洋理工大学MMLab@NTU的博士后廖康,主要研究统一多模态大模型和世界模型。

共同作者:来自中山大学的教授郑伟诗。他是中山大学计算机学院的副院长,也是长江学者特聘教授。他也是论文第一作者伍晓鸣的硕士生导师。

通讯作者:来自南洋理工大学的校长讲席教授吕健勤(Chen Change Loy)。他是MMLab@NTU的主任,也是CVPR 2026的程序主席。他是论文第一作者伍晓鸣的博士生导师。

-- 完 --
机智流推荐阅读:
1.
2.
3.
4.
cc | 大模型技术交流群 hf | HuggingFace 高赞论文分享群 lc|LangChain 技术交流群 code | AI Coding 交流群 具身 | 具身智能交流群 硬件 | AI 硬件交流群 推理 | AI 推理框架交流群 智能体 | Agent 技术交流群










