
在机器人操控领域,如何让机器精准理解视觉信息,并转化为流畅的物理动作,一直是困扰科研人员的核心问题。传统的视觉-语言-动作(VLA)模型,虽然凭借大规模数据集的加持展现出一定能力,但在面对分布外任务、变形物体交互等场景时,往往显得力不从心。而以生成式世界模型为代表的新范式,虽然能提供 “视觉预见” 能力,却又面临着像素级规划与可执行动作之间的 “最后一公里” 鸿沟。
近日,来自北京大学人形机器人创新中心、北京大学计算机学院多媒体信息处理国家重点实验室以及香港科技大学的研究团队,提出了一种全新的工具中心逆动力学模型(TC-IDM,ToolCentric Inverse Dynamics Mode)。该模型以机器人末端执行器的轨迹为核心中间表征,成功架起了视觉规划与物理控制之间的桥梁,不仅大幅提升了机器人在复杂任务中的操控成功率,还展现出卓越的零样本泛化能力。

论文标题:TC-IDM: Grounding Video Generation for Executable Zero-shot Robot Motion
论文链接:https://arxiv.org/pdf/2601.18323v1
开源地址:https://github.com/wsbaiyi/TC-IDM
机器人操控的痛点:视觉规划与物理执行的 “断层”
近年来,VLA 模型如 OpenVLA、π₀、RT 系列等的出现,让机器人从视觉和语言指令中学习操控策略成为可能。这类模型通常基于大规模 VLA 数据集预训练,再结合特定的操控数据微调,在既定任务中表现亮眼。但它们的局限性也十分突出:对高质量、大规模机器人数据集的依赖程度极高,一旦遇到训练分布之外的任务,比如从未接触过的变形物体交互,性能就会急剧下降。
为了突破这一限制,科研人员将目光投向了生成式世界模型。像 Sora、Kling、Cosmos 等视频生成模型,能够合成高保真、符合物理规律的视频序列,让机器人可以通过模拟未来状态进行 “视觉规划”。但新的问题随之而来:生成的 RGB 帧序列并不能直接转化为机器人的控制指令。这些视觉合成结果往往存在轨迹噪声、物理幻觉、运动学不一致等问题,再加上缺乏对机器人自身形态和驱动限制的锚定,导致从像素级规划到关节空间或扭矩控制的转化过程十分脆弱。
此前,一些方法试图通过从视频中跟踪物体状态来解决这个问题,比如 AVDC、VidBot 等,但在面对遮挡、快速运动,尤其是布料这类难以定义和跟踪状态的变形物体时,这些方法很容易失效。显然,机器人操控领域迫切需要一种全新的架构,来弥合视觉规划与物理执行之间的断层。
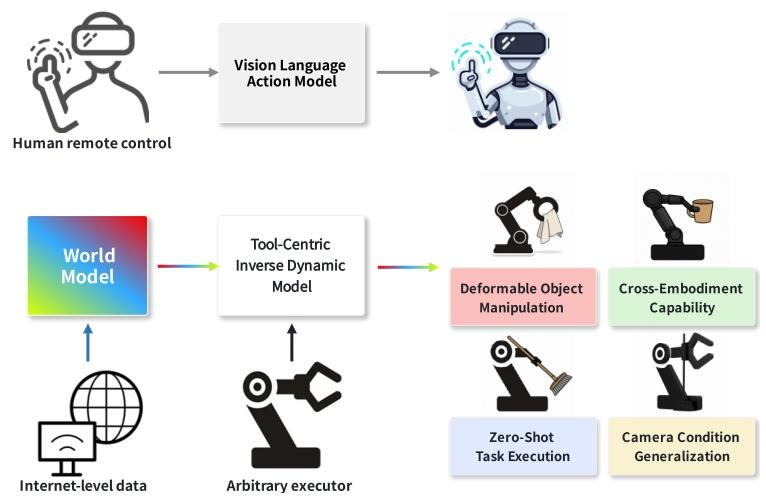
图 1 工具中心世界模型基 IDM 的优势示意图。相较于 VLA 基线模型,该架构具备更强的泛化能力,拥有简洁且稳定的结构,更易于学习,同时能跨设备迁移。
TC-IDM 模型:以工具轨迹为核心,实现 “规划 - 转化” 闭环
针对上述痛点,研究团队提出的 TC-IDM 模型,核心创新点在于摒弃了不稳定的物体状态或像素信息,转而锚定机器人末端执行器在生成视频中的稳定运动轨迹,以此作为连接高层视觉规划与底层物理控制的桥梁。整个模型采用 “规划 - 转化” 的两阶段流水线,实现了从视觉序列到机器人操控指令的精准转化。
第一步:时空预测,生成视觉规划与空间信息
TC-IDM 的第一步是依托生成式世界模型,完成对未来操作场景的视觉规划和空间信息提取。给定初始 RGB 帧、深度图和文本指令,世界模型会生成一段想象中的 RGB 视频序列,作为机器人的高层规划依据。需要注意的是,初始帧必须确保机器人末端执行器出现在视野中,这样才能获取其初始姿态,避免后续运动规划中出现碰撞风险。
在得到视频序列后,模型会利用 VGGT 模型生成初始深度图序列和相对相机姿态。为了获取精准的度量信息,研究团队还引入了参考度量深度图,通过最小二乘法计算出缩放和偏移参数,将预测的深度图和相机姿态进行校准,最终得到完全度量对齐的相机轨迹和深度序列,为后续的轨迹提取打下坚实基础。
第二步:解耦动作转化,实现精准操控
在完成时空预测后,TC-IDM 模型进入核心的动作转化阶段。这一阶段被巧妙地解耦为两个互补的分支:视觉驱动的状态生成分支,以及几何锚定的姿态生成分支,最终输出的控制向量包含抓手动作和末端执行器动作两部分。
视觉驱动的状态生成分支,主要负责生成抓手的控制指令。该分支采用编码器 - 解码器架构,利用预训练的 DINOv3 视觉编码器,从生成的 RGB 视频中提取具有时间一致性的语义特征,这些特征涵盖了物体身份、接触状态、任务阶段转换等关键信息。随后,一个轻量级的多层感知机(MLP)抓手控制网络,会基于这些语义特征预测连续的抓手开合参数。
几何锚定的姿态生成分支,则聚焦于末端执行器的 6 自由度(6-DoF)姿态控制。该分支的核心是提取末端执行器的密集 3D 点轨迹,并通过刚体运动约束确保轨迹的稳定性。首先,模型利用 SAM3 为视频的每一帧生成密集的抓手掩码,以此抑制背景运动,将跟踪范围限定在抓手区域。接着,3D 点跟踪器结合对齐后的 RGB-D 数据和抓手掩码,提取抓手表面点在机器人基坐标系中的 3D 运动轨迹。
考虑到生成式模型可能存在局部轨迹不一致的问题,研究团队还引入了刚体运动先验,筛选出最符合刚体运动假设的前 K 条轨迹。最后,通过求解刚体变换方程,计算出相邻帧之间末端执行器的相对位姿变换,这个变换结果就是可以直接驱动机器人的 6-DoF 动作指令。这种基于几何信息的解析方法,无需依赖学习型动作解码器,保证了运动生成的可解释性。
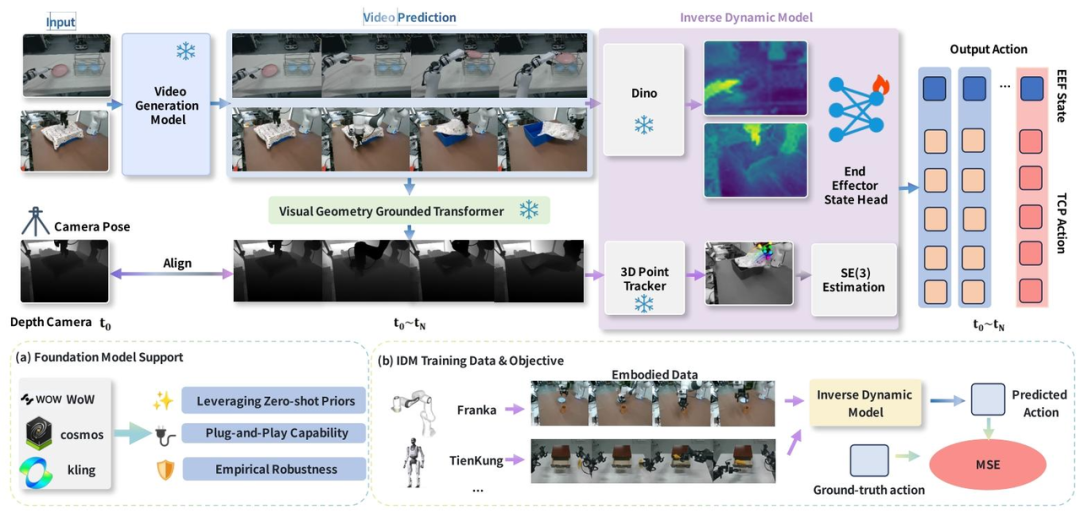
图 2 TC-IDM 工具中心视频生成框架总览。输入初始 RGB 帧、深度图和文本指令后,模型利用世界模型生成高层规划,提取语义视觉特征和深度对齐几何信息,再通过 3D 点跟踪器得到抓手中心流,最终由专用 MLP 头预测抓手和姿态状态。
实测验证:成功率远超基线模型,泛化能力拉满
为了全面验证 TC-IDM 模型的性能,研究团队设计了多组定量和定性实验,涵盖不同难度的操控任务、多种视频世界模型,以及零样本泛化的多个维度。实验所使用的机器人平台为单臂 Franka Emika Panda 机械臂,搭配 Robotiq 2F-85 自适应抓手,该机械臂具备 7 个自由度,每个关节都配备高分辨率扭矩传感器,支持精准的阻抗控制,能够适应非结构化环境中的接触动态变化。
定量实验:全难度任务碾压基线,简单任务近乎完美
研究团队根据自由度需求和精度约束,将操控任务分为简单、中等、困难三个等级。简单任务包括面包装盘、关抽屉、移动牛奶等基础操作;中等任务需要一定的避障或精准抓取能力,比如将面包放入上层抽屉、从杯架取杯;困难任务则要求 5-6 自由度的精细控制,例如翻转按钮至正确位置、将杯子挂到杯架上、把筷子插入竹筒等。

图 3 不同难度的代表性操控任务。从上至下分别为简单任务、中等任务和困难任务,涵盖了基础取放、避障操作和高精度 6 自由度控制等不同类型的机器人操控场景。
在真实世界回放实验中,TC-IDM 模型展现出压倒性优势。在简单任务中,TC-IDM 的成功率达到 93.3%,近乎完美完成操作;中等任务成功率为 53.3%,困难任务也能达到 28.9%。相比之下,传统的 ResNet-MLPs、AVDC、AnyPos 等基线模型,在困难任务中几乎难以完成。例如在 “筷子插竹筒” 任务中,TC-IDM 能达到 4/15 的成功率,而多数基线模型的成功率为 0。

在跨视频世界模型的测试中,无论是 π₀、CogVideo-IDM 这类基础模型,还是 Cosmos2-IDM、WoW-cosmos2-IDM 等优化后的模型,搭配 TC-IDM 后都能取得最高的任务成功率。统计数据显示,搭载 TC-IDM 的世界模型平均成功率达到 61.11%,其中简单任务成功率 77.7%,远超端到端 VLA 风格基线和其他逆动力学模型。
泛化实验:零样本搞定变形物体、跨设备操控
除了常规任务的测试,研究团队还从五个维度验证了 TC-IDM 的泛化能力,结果同样令人惊艳。
在误差范围分析实验中,以高精度的飞镖放置任务为测试对象,所有模型都接收相同的视觉规划,TC-IDM 能够精准复现动作,飞镖落点与目标的偏差稳定在 4 厘米以内,而 VLA 基线模型则难以遵循指令,偏差极大。
在跨相机泛化实验中,模型仅在 Intel Realsense D457 相机的数据上训练,却能直接迁移到苹果 Pro 相机和 Realsense D435i 相机的观测数据上。即便不同相机的色调、曝光、视角存在显著差异,生成的轨迹依然保持高度一致,操控任务顺利完成。
最值得一提的是变形物体操控实验。TC-IDM 模型在训练过程中仅接触刚性物体,但在面对布料移除任务时,依然能精准识别稳定的抓取区域,生成可靠的移除轨迹,零样本变形物体任务的成功率达到 38.46%。这一结果证明,模型无需对变形物体的复杂状态建模,仅通过跟踪工具轨迹就能完成任务。
在长时程泛化实验中,TC-IDM 成功完成了六步连帽衫折叠任务。世界模型生成完整的六步视觉规划后,模型无需中间修正或重新规划,就能一步步完成折叠操作,即便连帽衫在操作过程中不断变形,也能保持与规划的高度对齐。
跨设备泛化实验更是展现了 TC-IDM 的强大迁移能力。模型将在单臂 Franka 机器人上学到的运动先验,直接迁移到双臂 UR5 机器人上,完成木琴演奏任务。无需任何重新训练,机器人就能精准敲击木琴的黄色琴键,轨迹与规划高度吻合,实现了稳定的节奏性运动。

图 4 变形物体操控泛化能力验证。上方为世界模型生成的布料移除视觉规划,下方为真实机器人的执行过程,模型能准确识别抓取点并完成移除操作。
拓展应用:迁移至灵巧手,解锁更多操控可能
TC-IDM 模型的潜力不止于此,研究团队还将其拓展到了灵巧手操控领域,实现了从人类手部动作到不同灵巧手的迁移。整个流程仅需重新映射执行器状态,上游和下游模块完全无需改动。
具体来说,模型首先利用预训练的 HaMeR 模型,从生成的 RGB 视频中提取人类手部的 3D 姿态表征,该表征涵盖了抓取和操控所需的关键关节信息。随后,一个轻量级的重定向网络,将人类手部状态映射为特定灵巧手的关节控制指令。这种设计将人类手部动作的理解与机器人运动学解耦,只需更换重定向头,就能驱动不同类型的灵巧手。
在气球敲击和布料移除两个任务的测试中,TC-IDM 分别驱动 BrainCo 和 Inspire-Robots 两款灵巧手,成功完成了零样本动作迁移,进一步证明了该模型的通用性和扩展性。
总结:机器人操控的新范式,迈向通用化 embodied AI
TC-IDM 模型的提出,为机器人操控领域带来了全新的解决方案。它以工具轨迹为核心中间表征,通过解耦的 “规划 - 转化” 架构,成功弥合了生成式世界模型视觉规划与物理执行之间的鸿沟。相比传统方法,TC-IDM 不仅大幅提升了任务成功率,还在相机视角变化、变形物体交互、长时程任务、跨设备迁移等多个维度展现出卓越的泛化能力。
这项研究的意义不仅在于提出了一个高性能的模型,更在于为通用化 embodied AI 的发展指明了方向。未来,随着生成式世界模型和 TC-IDM 这类转化架构的不断优化,机器人有望摆脱对大规模标注数据的依赖,真正实现 “举一反三”,在家庭服务、工业制造、医疗护理等更多复杂场景中发挥作用。
论文标题:TC-IDM: Grounding Video Generation for Executable Zero-shot Robot Motion
论文链接:https://arxiv.org/pdf/2601.18323v1
开源地址:https://github.com/wsbaiyi/TC-IDM
> 本文由 Intern-S1 等 AI 生成,机智流编辑部校对
-- 完 --










