点击下方卡片,关注「3D视觉工坊」公众号
选择星标,干货第一时间送达
来源:3D视觉工坊
「3D视觉从入门到精通」知识星球(点开有惊喜) !星球内新增20多门3D视觉系统课程、入门环境配置教程、多场顶会直播、顶会论文最新解读、3D视觉算法源码、求职招聘等。想要入门3D视觉、做项目、搞科研,欢迎扫码加入!

0. 论文信息
标题:Stereo Any Video: Temporally Consistent Stereo Matching
作者:Junpeng Jing, Weixun Luo, Ye Mao, Krystian Mikolajczyk
机构:Imperial College London
原文链接:https://arxiv.org/pdf/2503.05549
代码链接:https://tomtomtommi.github.io/StereoAnyVideo/
1. 导读
本文介绍Stereo Any Video框架,该框架实现了无需依赖相机位姿或光流等辅助信息的视频立体匹配。其核心能力源于单目视频深度模型的丰富先验知识,这些先验通过与卷积特征融合生成稳定的特征表示。为进一步提升性能,我们提出两项关键架构创新:全对关联(all-to-all-pairs correlation)构建平滑鲁棒的匹配代价体,时间凸上采样(temporal convex upsampling)增强时间一致性。这些组件共同确保了算法的鲁棒性、精确性和时间连贯性,为视频立体匹配树立了新标杆。
2. 效果展示
对动态真实世界立体视频的预测。我们的方法能够在不出现闪烁的情况下产生时间上连贯且准确的差异,从而能够重建动态场景中的密集且干净的度量点云。

来自南肯辛顿SV数据集的动态室内场景定性比较。上图:使用不同方法为同一区域输入左侧帧以及预测的三帧差异下图:将这些差异转换为全局对齐的点云,并从相机视角渲染出来以供比较。错误区域用红色箭头标出。我们的方法能够生成连贯且准确的差异,且不会出现闪烁现象。

对南肯辛顿SV数据集中的动态户外场景进行定性比较

3. 引言
大量实验证明,在零样本学习设置下,该方法在多个数据集上均取得了定性与定量层面的最优性能,并在真实室内外场景中展现出强大的泛化能力。视频立体匹配旨在通过双目相机重建三维场景,其通过识别校正后左右图像在每个时间步的水平对应关系来估计视差。持续精确捕获视差对三维场景重建与理解至关重要,可赋能自动驾驶、机器人导航及虚拟/增强现实等下游任务。
随着深度学习的发展,立体匹配取得了显著进展,在公共基准测试中表现出色。然而,现有方法多针对单帧图像设计,未显式利用视频序列中的时间信息。直接应用于视频数据时,这些方法易产生时间不一致性,导致视差图和重建点云出现明显闪烁与伪影。为缓解此问题,近期视频方法通过预定义模型或可学习机制引入相机位姿或光流等时间线索。例如,CODD采用位姿网络估计相对相机运动,并在融合框架内对齐相邻视差;TemporalStereo和TC-Stereo则在此范式基础上改进架构设计与对齐操作。另一类方法如BiDAStereo集成光流模块进行时间特征对齐,并引入时间聚合模块传播跨帧信息。推荐课程:机械臂6D位姿估计抓取从入门到精通。
尽管如此,现有视频方法在动态场景、相机运动及辅助信息精度方面仍存在脆弱性。真实场景中,动态物体的复杂运动与形变会违反传统多视点约束,破坏视差估计的平移不变性。此外,依赖辅助线索的模型受限于相机位姿或光流估计模块的性能。在复杂相机运动环境下,这些估计模块可能退化,成为限制视频立体方法鲁棒性的瓶颈。
为此,我们提出Stereo Any Video框架,该框架无需依赖相机位姿或光流即可实现鲁棒的视频立体匹配。受视频生成领域研究启发,我们强调特征表示的鲁棒性与稳定性对时间一致性的关键作用,并基于此设计框架。具体而言,在特征提取阶段,我们将卷积线索与在百万级数据上训练的冻结单目视频深度基座模型(Video Depth Anything)结合,生成富含先验的鲁棒特征图。在对应匹配阶段,我们引入全对关联模块,通过联合考虑目标视图与参考视图的双向对应关系,实现平滑可靠的匹配。在代价聚合阶段,我们提出时间凸上采样机制,结合全时间循环单元维持时间一致性。
4. 主要贡献
Stereo Any Video方法能准确稳定生成视差,有效支持动态场景重建。本文贡献可总结为:(1)提出Stereo Any Video框架,集成单目视频深度先验实现精确且时间一致的立体匹配;(2)设计全对关联模块与时间凸上采样机制,确保代价体表示与聚合的鲁棒性与稳定性;(3)在多个基准测试中取得至少15%的性能提升,为视频立体匹配树立新标准。
5. 方法
所提Stereo Any Video框架概述如下:输入双目视频序列后,模型首先通过可训练卷积编码器与冻结单目视频深度编码器(Video Depth Anything)提取特征及上下文信息。在每次迭代中,全对关联计算特征相关性,随后经MLP编码器生成紧凑表示。视差通过集成代价体特征的3D门控循环单元(GRU)进行迭代优化,并通过时间凸上采样层实现分辨率提升。该过程在级联流水线中重复执行,逐步恢复全分辨率视差。

6. 实验结果
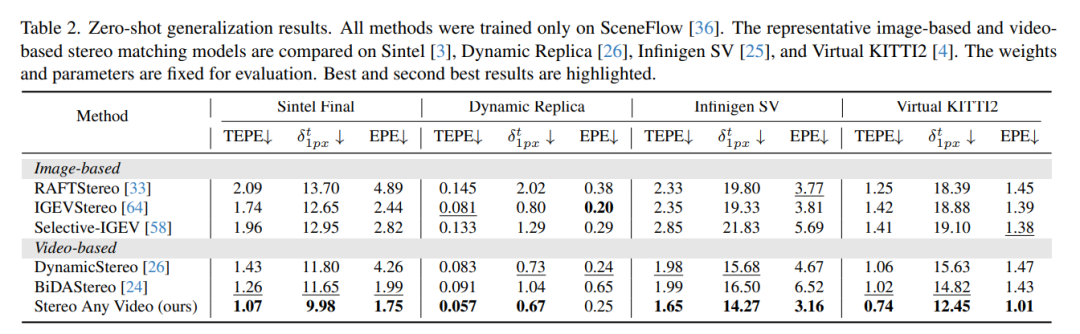
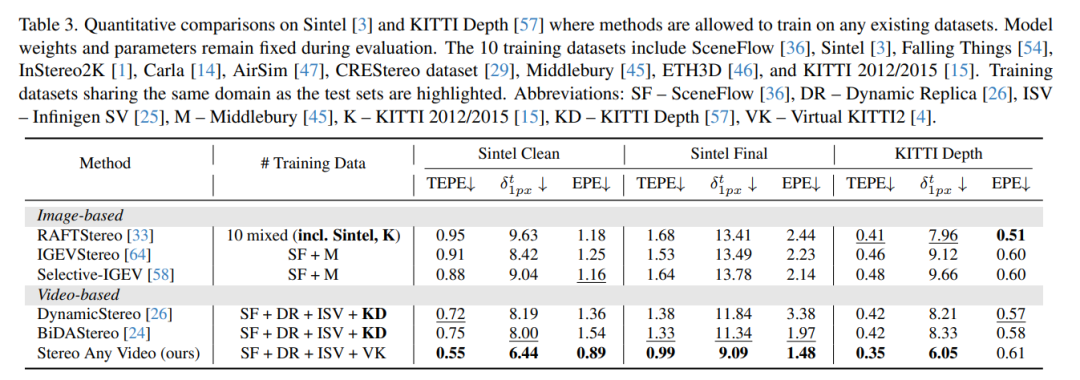
7. 总结 & 未来工作
综上,本文提出Stereo Any Video框架,通过融合单目先验、全对关联机制及时间凸上采样层,在无需额外输入(如相机位姿或光流)的情况下生成时间一致且精确的视差。大量评估表明,该模型在零样本学习设置下于多个标准基准测试中达到最优性能,并在真实双目视频中有效处理多样化内容、运动及相机运动。
对更多实验结果和文章细节感兴趣的读者,可以阅读一下论文原文~
3D视觉硬件,官网:www.3dcver.com

3D视觉学习圈子
「3D视觉从入门到精通」知识星球(点开有惊喜) !星球内新增20多门3D视觉系统课程、入门环境配置教程、多场顶会直播、顶会论文最新解读、3D视觉算法源码、求职招聘等。想要入门3D视觉、做项目、搞科研,欢迎扫码加入!

3D视觉全栈学习课程:www.3dcver.com

3D视觉交流群成立啦,微信:cv3d001











