【内容目录】
1.Nvidia为何回归 32 Gb/s NRZ?
【本文涉及的相关企业】
Nvidia、TSMC、、Silterra、iPronics、nEye 、 Salience
Nvidia为何回归 32 Gb/s NRZ?
Nvidia在ISSCC 2026(国际固态电路会议)上发表了一篇里程碑式的论文《A 32Gb/s/λ 256Gb/s/Fiber Half-Rate Bandpass-Filtered Clock-Forwarding DWDM Optical Link in a 3D-Stacked 7nm EIC/65nm PIC Technology》,文中揭示了NVIDIA下一代AI基础设施互连战略背后的技术蓝图,通过3D堆叠封装采用7nm制程的电子集成电路GPU、XPU和65nm制程的光子集成电路256Gb/s光纤半速率带通滤波时钟转发DWDM光链路互联。

Nvidia 论文截图(图源:SemiVision)
当前行业主流趋向于通过高阶脉冲幅度调制(PAM4)来提升比特率,试图在 56 Gb/s、112 Gb/s 甚至 224 Gb/s 的通道上实现突破 。单通道 224 Gb/s PAM4 固然看起来很美,但是其多电平特性需要极高的信噪比(SNR)要求,这就导致接收器灵敏度下降,实现 224 Gb/s 通道需要高达 112 G baud 的信号符号速率,这对通道的高频响应和串扰抑制提出了近乎苛刻的要求。
而且业界最新的研究表明,在最佳的实验室条件下,PAM4的原始误码率(BER)也在1E-4到1E-6量级,因此必须采用前向纠错(FEC)才能达到系统级1E-12或更低的要求,而FEC技术本身就会引入最低10ns的额外延迟,对于Nvidia动辄千卡互联甚至万卡互联的算力集群,10ns的延迟影响很大。
针对上述挑战,NVIDIA 在 ISSCC 2026 发布的论文中提出了一种“反直觉”但极具战略意义的方案:放弃追求单通道 224 Gb/s PAM4,转而回归单波长 32 Gb/s NRZ 调制。这种NRZ 的回归并且“分而治之”策略,也让业界工程师哗然。相比 PAM4,NRZ 仅需两个电压电平,拥有更大的信号摆幅和更高的抖动容限,电路实现更为简洁高效。由于 NRZ 链路在 32 Gb/s 速率下表现稳定,可以省去复杂的 FEC ,使端到端链路延迟降低至 1 ns 以下。相比同等带宽的 PAM4 模块,NRZ 架构能显著降低功耗,每比特能效表现更佳Nvidia 通过波分复用(DWDM)技术,将多条中低速通道并行叠加,实现了在单一光纤中达成 256 Gb/s 的总吞吐量,成功突破了单通道电学传输的物理极限。
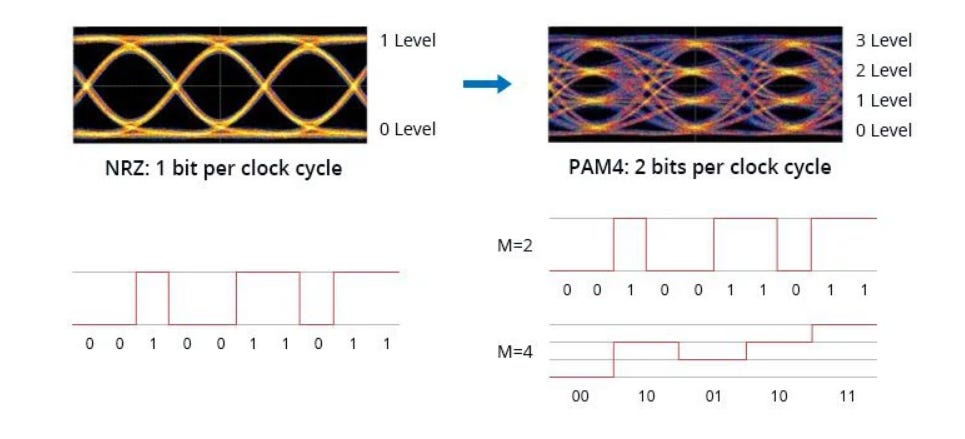
NRZ和PAM4(图源:Web)
在论文中,Nvidia设计了光电共封CPO用了9个波长,波长之间的频率间隔为200 GHz;设计了8个通道,每个通道传输32 Gb/s NRZ数据,并且突破性的引入了全新设计的半速率带通滤波转发时钟架构即16GHz的速率,实现每根光纤8x32=256Gb/s的总吞吐量。
在接收端对转发时钟采用1-2GHz的带通滤波器,是 Nvidia方案中最核心的技术突破,传统的嵌入式时钟(EC)架构依赖复杂的 CDR 电路,易引入相位噪声;而简单的转发时钟(FC)又容易受到跨阻放大器(TIA)热噪声的影响。论文中引入的半速率带通滤波转发时钟架构,与TIA噪声带宽紧密匹配,有效滤除TIA引入的非相关随机抖动,同时保留并追踪与数据相关的低频时钟噪声,这种设计在不使用CDR的情况下显著减少噪声积累,实现了超低延迟和高稳定性;在发送端Nvidia采用共享时钟、全对称通道架构,所有9个波长通道共享一个基于环形振荡器的TX PLL,分发四个半速率相位,确保源端多通道相干性,并且在每个发送通道集成了一个相位插值器用于补偿半UI相移和通道间偏斜,确保接收端采样精确和对齐数据眼图中心,这样一来就节省了大量在接收端需要额外添加的相位生成电路。
论文中还介绍了Nvidia设计的光路信号链,包括16:1串行器、单端转差分(S2D)转换、发送驱动器和宽带电平转换器。为了使微环调制器能够在高、低电压节点之间工作且不受低截止频率的限制,电平转换器采用差分偏置方案,并且能够接受高达300μA的漏电流。而接收器的设计则专注于低噪声和强PVT(工艺、电压、温度)的稳定性,以提高整体的兼容性和鲁棒性。在接收端PLL则不用于时钟分配,而是为TIA和接收电路提供稳压偏置参考,确保在PVT变化下带宽稳定;TIA(跨阻放大器)则采用了基于反相器的放大拓扑结构,结合Cherry-Hooper级联,并嵌入注入锁定振荡器(ILO),构成了带通滤波机制的核心,强力抑制非相关抖动,同时保留低频相关抖动跟踪。
所以对于Nvidia而言,将每波长数据速率设定为32 Gb/s意味着每个通道可以依赖相对成熟、高能效的光电调制器,并且可以使用DWDM在硅光子平台上部署高达9个波长,这样一来总吞吐量可以与单通道200 Gb/s或更高的PAM4系统相媲美,NRZ架构和3D堆叠封装结合时,串扰和功耗进一步降低,使得NRZ架构成为高性能且高速率互联集成更有吸引力的解决方案。
DWDM 与微环谐振器
上文中NRZ采用的密集波分复用(DWDM)是提升总吞吐量的关键技术,这种跨多波长通道的技术脱胎于波分复用(WDM)。波分复用(WDM)可以使单根光纤能够同时承载不同波长的多个光信号,每个波长对应一个独立的数据通道。根据Smartoptics发布的白皮书,这些波长可以独立运行而互不干扰,因为每个通道使用不同的"颜色"(即频率),允许多个数据流在单根光纤中堆叠。
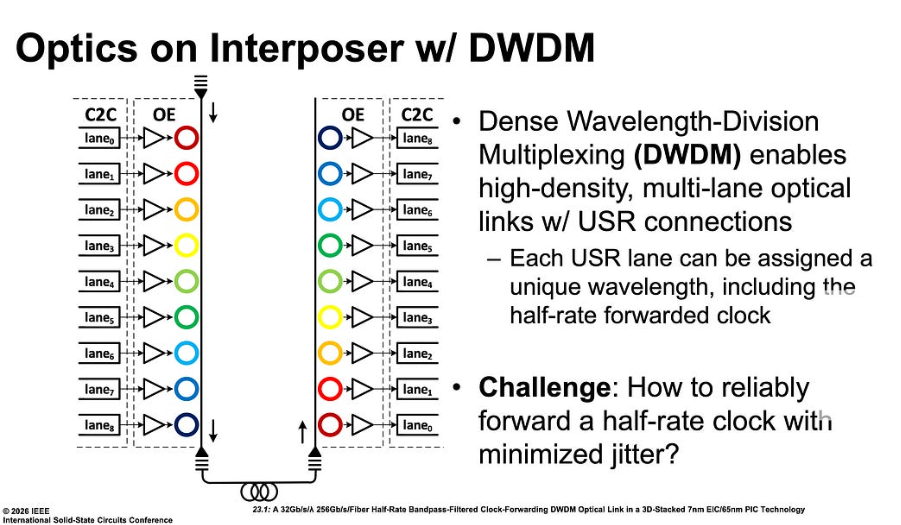
Optics on Interposer w/DWDM(图源:Nvidia)
通过在链路两端部署波分复用器/解复用器(Mux/Demux),多个独立数据流可以合并传输,然后在接收端分离回各自的波长。WDM可以显著提高光纤利用率,减少系统所需光纤数量,并扩展整体带宽,而密集波分复用(DWDM)则是进一步提升系统的波长密度,最高可以同时支持80个波长,系统数据总吞吐量可以高达数十太比特。对于硅光子互联来说,DWDM的本质在于能够精确生成、调制和滤波多个紧密间隔的不同波长的光波,硅光子通常采用SOI绝缘体上硅基材,该种材料具有很高的折射率,允许制造具有极小弯曲半径的波导和谐振腔。
最典型的硅光子就是微环谐振器,可以使用半径仅为~5 μm的环形波导选择性调制特定波长。通过精心设计的换装结构,微环谐振器可以表现出亮眼的高品质因数(高Q)和窄光谱选择性,并且还可以同时作为调制器、复用器和滤波器,体积又小的同时还和CMOS集成制程工艺高度兼容。
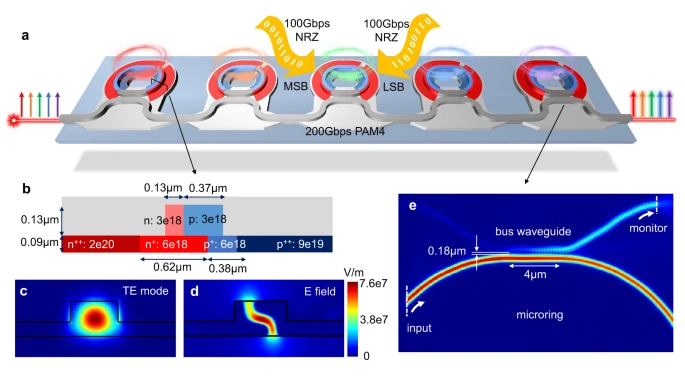
微环谐振器(图源:《A 5 × 200 Gbps microring modulator silicon chip empowered by two-segment Z-shape junctions》)
微环谐振器能够让硅光子在尺寸极小的情况下,实现多波长的DWDM功能,Nvidia的9路波长架构分布在1310 nm O波段(近零色散)附近,其中8个波长承载32 Gb/s NRZ数据,剩余1个波长用于转发半速率时钟信号,并且每个波长的调制器、光电探测器和光波导都集成在65 nm制程的硅光子芯片上。并且Nvidia选择采用半径约5 μm的微环,每个环对应一个通道,半径小可以增加自由光谱范围(FSR),使相邻谐振峰间隔~200 GHz,减少通道间串扰,每个微环旁边放置电加热器和控制电路,以热调谐谐振波长,确保与数据或时钟通道精确对齐。最后通过3D混合键合封装进一步实现了65nm硅光子芯片和7nm电子芯片集成,热耦合器和温度传感器则能实时校正系统的热漂移。

EIC和PIC混合封装(图源:Creideas)
并且论文中还提到Nvidia在仿真建模特殊模拟了每个环的尾峰响应,并调整波导耦合系数和间距,将通道间串扰降低到可忽略的水平,这种手术刀般的精密设计不仅是一个单一的光链路创新,更是一套完整的共封装光学(CPO)架构演示,通过在 3D 空间内重新定义光电边界,NVIDIA 为下一代 AI 数据中心提供了一条清晰的技术演进路径:更简单(NRZ)、更密集(DWDM)、更融合(3D Stacking)。
结语
随着人工智能模型规模的爆发式增长,Nvidia(英伟达)在ISSCC 2026会议上提出了一种创新的互连战略,旨在解决数据传输中的性能瓶颈,NRZ+微环+DWDM 实现近乎完美的新一代解决方案,定义全新的超大规模算力集群光互联新范式。
文中插图为NotebookLM生成
参考:
《2026 NVIDIA Silicon Photonics 3D Stacking and DWDM Half-Rate Optical Link Technology》
《A 5 × 200 Gbps microring modulator silicon chip empowered by two-segment Z-shape junctions》












