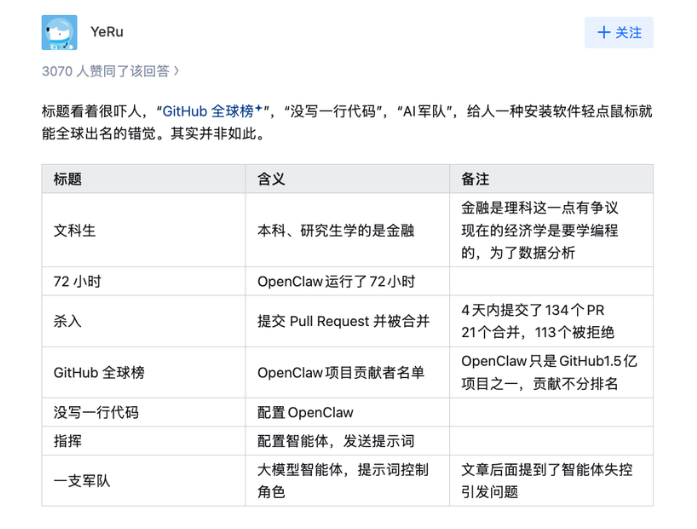
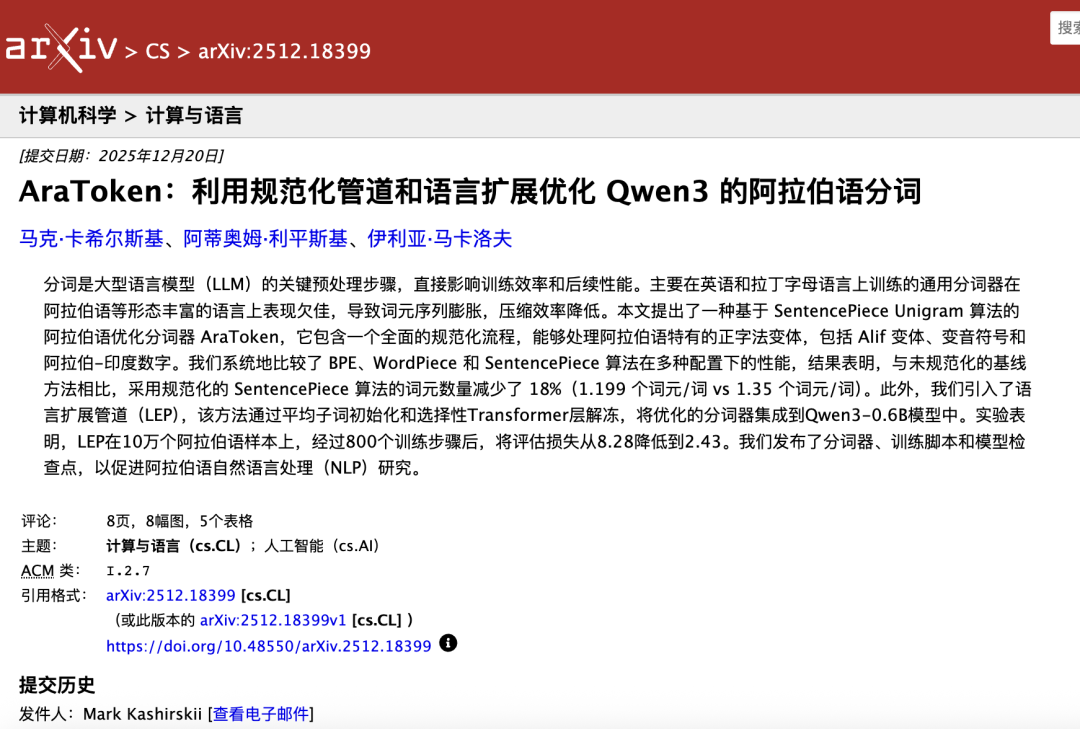
「文科生也可以做 AI」 「逆袭!」在中文互联网上,文科和 AI 的拉郎配,简直成了定番。每隔一段时间,这个标签就会被贴在某个人身上,制造出一轮短暂的流量。要么是逆袭故事,要么是嘲讽素材,取决于评论区的心情。一个标签,三种做法最新的案例是杨天润, AI 创业者,金融出身,正在开发一个多智能体协调平台。他自称「一行代码都不会写的文科生」,搭建了一组 AI Agent,向 GitHub 上最热门的开源项目之一 OpenClaw 批量提交代码贡献。想验证一个假设:一个完全不懂技术的人,能不能仅靠指挥 AI,就参与到顶级开源项目中去。结果是:134 个 PR,21 个被合并,113 个被拒绝。前几个 PR 质量还算不错,被维护者认可并合并。但当他给 Agent 下了一条加速指令后,事情迅速失控——Agent 开始像流水线一样批量生产低质代码,在评论区疯狂@维护者催促审核。OpenClaw 管理员介入清理,GitHub 随后修改了 PR 提交上限规则。黑红也是红,红过之后再黑更加是。杨天润被包装成「文科生逆袭」的代表,而他本人似乎也乐于接受这个角色。在接受品玩的采访时,他说了一句这样的话:不懂代码反而是优势。AI 是梵高,你是个小画家,你有什么资格告诉梵高中间该用什么笔触?细思极恐。他把「不懂底层结构」理解为一种解放:不需要知道系统在做什么,只需要告诉它你想要什么。结果就是当 Agent 开始批量刷垃圾代码时,他连发生了什么都诊断不出来,因为他根本不知道自己在操作什么。他以为自己在指挥梵高,实际上他在盲开一辆没装刹车的车,而且根本不知道刹车在哪。围绕这件事的讨论,也随之落入两个极端:要么「文科生也能做 AI」,要么「文科生别碰 AI」;前者是跨越鸿沟的壮举,要么是掉进鸿沟的笑话如果我们对「文科生做 AI」的想象力只有这些,那未免太贫乏了。Claude 为什么需要一个哲学家我们之前写过,Anthropic 的办公室里,有一位正儿八经的文科生,深度参与了 Claude 的建设。不是测试它能不能写代码,不是检查它的数学能力,而是和它进行漫长的、关于价值观、关于措辞分寸、关于「面对不确定性应该如何表达」的对话。Amanda Askell,苏格兰人,今年 37 岁。她的职业路径本身就是一个不太寻常的故事:在大学,她最初学的是美术和哲学,后来转向纯哲学,在牛津拿到了 BPhil,又在纽约大学拿到了哲学博士。她博士研究的是无限伦理学中的帕累托原则:当涉及无限数量的道德主体或无限时间跨度时,伦理排序应当遵循什么规则。这听起来像是距离硅谷最远的学术方向,但她先后加入了 OpenAI 的政策团队和 Anthropic 的对齐团队。2021 年起,她成为 Anthropic「性格对齐」团队的负责人,工作重点是塑造 Claude 如何与人类对话、如何在不确定时表达立场、如何在价值观冲突中做出判断。2024 年,她入选了 TIME100 AI 榜单。《华尔街日报》描述她的日常工作是「学习 Claude 的推理模式,用长度超过 100 页的提示词来修正它的行为偏差」。据说她是这个星球上和 Claude 对话次数最多的人类。为什么一个 AI 公司需要一个哲学家来做这件事?答案藏在一些非常具体的技术选择里。今年 1 月,Anthropic 发布了一份长达 80 页的文件,被称为 Claude 的「宪法」。媒体关注的是文件末尾关于 AI 意识的推测——当然,老板 Dario Amodei 也话里话外「暗示」这一点。但更值得注意的是它的底层逻辑:教 AI 理解为什么要这样做,比告诉它应该怎样做更有效。这是一个技术判断,认为内化价值比遵守规则能产出更可靠的行为,而这种判断的知识根基,来自一个学美术、学哲学的人。Amanda 的案例回答了一个问题:被视为「无用」的学科知识,能否成为技术系统的核心能力?答案不仅是能,而且,没有她的哲学训练,Claude 的对齐问题用现有的工程方法解决不了。被重新命名的学科如果 Amanda 的故事说明了,某些被归为「文科」的学科训练可以是 AI 的核心能力,那么林俊旸的故事要说的是一件更重要的事:有一整个学科,一直在大模型技术栈底层运行。林俊旸离开通义千问后,中文互联网的报道反复使用同一个说法:他有应用语言学背景。稍微传几次,这个话就变形了,变成了他是「文科生」。这个标签和杨天润身上贴的是同一个,但其实被严重扭曲。林俊旸学的是语言学,这是一个伞状学科,它的分支覆盖语言教学、语言政策、翻译研究,也包括计算语言学。可以说,计算语言学,就是自然语言处理(NLP)之子。乔姆斯基在 1950 年代提出了形式语法,这个理论工具直接催生了早期 NLP 的句法分析技术;Daniel Jurafsky 和 Christopher Manning,这两位 NLP 领域被引用最多的两本教科书的作者,都是语言学出身。乔姆斯基换句话说,「学语言学的人去做 NLP」就像「学物理的人去做芯片设计」一样,是一条正统路径,不是跨界。那个「意外感」完全是中国语境制造的。高考文理分科的制度惯性,把「语言学」塞进了「文科」的心智模型里。但语言学的核心方法论——形式化、统计建模、语料标注——本质上是工程思维。林俊旸在北大的合作者孙栩、苏祺,都是 NLP 方向的研究者;他 2019 年加入达摩院时进入的是 NLP 团队。这不是一个文科生误入技术领域的故事,从一开始就不是。比「林俊旸不算文科」更值得展开的,是语言学在大模型技术栈里实际扮演的角色。它比大多数人以为的要深得多,也隐蔽得多。比如分词。所有语言模型处理文本的第一步,是把输入切成模型能处理的基本单元。对英语来说,空格提供了天然的词边界,看起来简单。但中文里,没有空格,且每一个标点符号的用法,都可以左右句子的表达意思。「我在北京大学读书」是切成「我/在/北京/大学/读书」还是「我/在/北京大学/读书」?这不是一个有标准答案的工程问题,它取决于你对中文词汇结构和语义单元的理解。2024 年底有研究者专门发表论文,讨论如何优化 Qwen 模型的阿拉伯文分词效率,因为通用方案在处理这类语言时效率显著下降。Qwen 系列在多语言上的表现,不是把所有语言当英语的变体来处理,而是基于对语言间结构性差异的理解,做出的设计选择。又比如反馈对齐。RLHF 流程中,标注员需要判断模型的两个回答哪个「更好」。这个判断听起来主观,但它背后有一套语言学已经研究了几十年的框架:语用学。标注员在评估「好的回答」时,实际上是在判断合作原则(回答是否提供了足够但不过量的信息);会话含义(回答是否捕捉到了用户真正想问的、而不仅仅是字面上问的东西);以及语境适切性(同样的内容,用这种方式说在这个场景下是否得体?)。「Helpful, Harmless, Honest」这套被广泛使用的对齐标准,本质上就是语用学基本原则的工程化翻译。从林俊旸的学术轨迹中,也能看到一种非常语言学的研究风格。他主导的 OFA(One For All),2022 年发表于机器学习领域的顶级会议 ICML,至今被引用近 1500 次。这个工作的核心思路不是为每个任务搭专用方案,而是用一个足够通用的序列到序列框架,把图像生成、视觉定位、图像描述、文本分类等跨模态任务统一起来。从 OFA 到 Qwen-VL(被引超过 2200 次),再到 Qwen2.5,以及最新的 3.5,一条清晰的线索贯穿始终:与其为每个问题发明一套专门的解法,不如找到一个足够好的通用框架,让所有问题在同一个框架里被解决。用最少的规则,覆盖最多的现象——这正是语言学几十年来的核心追求。生成语法的全部学术野心,就是找到一套有限的规则系统,能够生成无限的语言表达。OFA 的架构哲学与此同构,为每种语言现象写一套专门规则并不现实,应该寻找一个底层框架来统一它们。林俊旸做大模型做得好,不是因为语言学背景「也能」做 AI,而是语言学训练塑造了一种特定的学术品味,对统一性和形式化的偏好。这种品味在大模型时代,恰好是核心竞争力。看不见的地基,看得见的需求三个人,同一个标签,三种完全不同的路径。杨天润不懂底层结构,把「不懂」当优势,结果失控。这是「文科生做 AI」的空壳版:标签制造了流量,但没有任何学科训练在起作用。他的故事体现的恰恰是——当「文科生」只是一个营销标签时,会发生什么。Amanda Askell 的哲学训练构成了对齐问题的核心方法论。没有她,Claude 不是 Claude。她的故事回答的问题是,被视为「无用」的学科知识,能否成为技术系统的核心能力。答案是不仅能,而且不可替代。林俊旸的语言学训练构成了大模型技术栈的隐性基础设施。他的「文科背景」从来不是跨界,是正统路径。他的故事回答的问题是,文科对于先进技术的贡献,到底「隐性」到了什么程度,它是不是正在变得显性。而终极问题并不是「文科生能不能做 AI」,而是我们能否理解到一点:靠表面上的「有没有用」来评判知识和学科,已经过时了。随着大模型从追求能用好用,走向追求可靠和可控,这些被归入「文科」的学科训练,价值不是在缩小,而是在扩大。模型越强大,越需要精确的评估体系来诊断它在哪里、为什么出错,也越需要理解语言和意义的复杂性来设计更好的训练数据,越需要在对齐问题上做出有学科敏感度的判断。「文科生逆袭」这个叙事——无论是赞美还是嘲笑——遮蔽了真正在发生的转向:看不见的地基,正在变成看得见的需求。我们正在招募伙伴📮 简历投递邮箱hr@ifanr.com✉️ 邮件标题「姓名+岗位名称」(请随简历附上项目/作品或相关链接)