
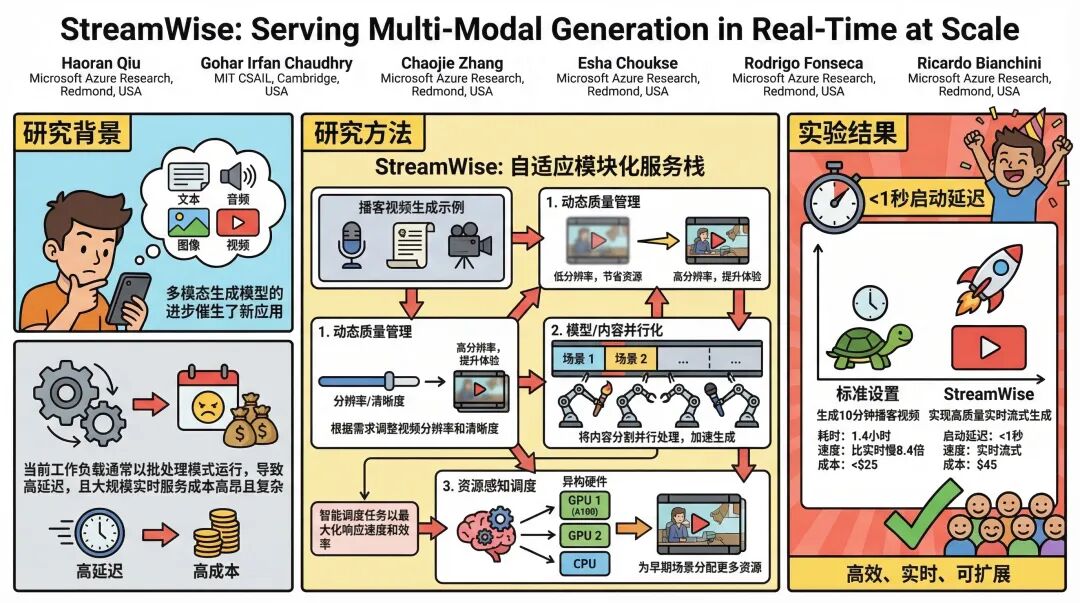
在AI内容生成狂飙突进的今天,从一段文字生成一张精美图片已不稀奇,但你是否想象过,输入一篇研究论文,AI就能在几秒钟内开始为你流式播放一段由虚拟人物主持、声画同步的解读视频播客?这背后,是文本、语音、图像、视频等多种模态AI模型的复杂协作,而实现这种“实时流式生成”,对现有的计算系统提出了前所未有的挑战。
近日,来自微软Azure研究院与MIT CSAIL的研究团队提出了一种名为 StreamWise 的全新服务系统,专门为实时、大规模的多模态生成工作负载而设计。他们以“播客视频生成”这一极具代表性的应用为切入点,成功构建了一个能够动态协调质量、并行性与资源的自适应系统,将高质量实时流式生成的启动延迟降至亚秒级,同时将成本控制在极具竞争力的水平。
论文标题:StreamWise: Serving Multi-Modal Generation in Real-Time at Scale
论文链接:https://arxiv.org/pdf/2603.05800
研究背景
当前,多模态生成(如文生图、文生视频)应用大多以“批处理”模式运行。用户提交一个提示词,可能需要等待数分钟甚至更久才能看到结果。对于像Sora、Veo这样的顶尖视频生成模型,生成一段短短数秒的视频也需不菲的计算成本和时间。当我们将视野扩展到更复杂、更长的内容(如10分钟的视频播客)时,问题被急剧放大。
这种工作流程涉及大型语言模型(LLM)生成剧本、文本转语音(TTS)模型合成对话、图像模型生成角色与场景、视频模型让画面动起来,最后还需进行音画同步。每一个环节都消耗着不同的计算资源,并有着严格的先后依赖关系。简单地串联这些模型,在8块顶级A100 GPU服务器上生成一段10分钟的视频,可能需要长达8.3小时,成本超过70美元,这完全无法满足“实时”体验的需求。
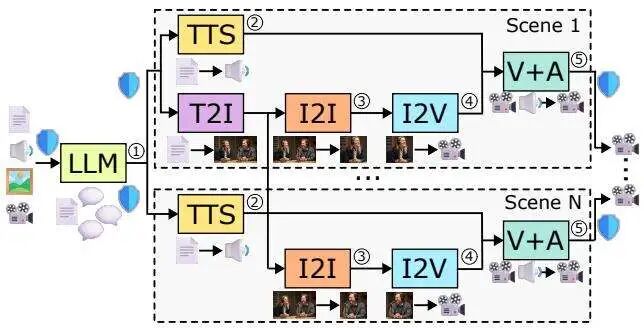
图1:AI生成播客视频的典型工作流程。从输入内容开始,依次经过剧本生成、音频生成、图像生成、视频生成和音画同步等多个环节,环环相扣。(图片来自原论文)
真正的实时流式播放意味着:视频需要在用户提交请求后的极短时间内开始播放(低首帧时间,TTFF),并且后续帧的生成速度必须跟得上播放速度(稳定的帧间时间,TBF)。这为系统调度带来了严格的截止时间要求,例如,系统必须精确计算出第2个场景的第172帧必须在7.2秒内准备好。
StreamWise的核心创新:像指挥乐团一样调度AI
面对上述挑战,StreamWise并没有选择等待一个能“一口吃成胖子”的端到端全能模型,而是采用了模块化、自适应的设计哲学。其核心思想是,将复杂的生成任务视为一个由多个异构“乐手”(不同AI模型)共同演奏的乐章,而StreamWise就是那位洞察全局、动态调配的“指挥家”。
1. 全局优化与动态资源调配
StreamWise首先将硬件(不同类型的GPU,如A100, H100, H200)和软件(各种图像、视频、语音模型)的供应视为一个优化问题。系统会分析目标工作负载(如“生成10分钟中质量播客视频”),并自动寻找在给定延迟目标下的成本最优配置。它能够混合使用不同代际、不同价格的GPU,甚至跨区域整合资源,并智能利用云平台的Spot实例(抢占式实例)来进一步降低成本。
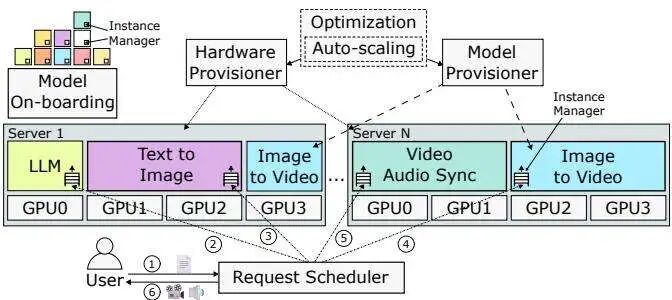
图2:StreamWise系统架构概览。系统包含模型载入、资源与模型供应、请求调度和本地执行等多个层次,协同工作以完成实时生成任务。(图片来自原论文)
2. 基于截止时间的感知调度
这是StreamWise实现实时性的关键。系统将每个生成请求建模为一个有向无环图(DAG),图中的每个节点代表一个子任务(如“生成场景3的音频”)。调度器会为每个节点计算一个严格的截止时间,并优先调度那些位于关键路径上、截止时间更紧迫的任务。例如,为了尽快看到第一帧,系统会优先处理视频开头场景的生成任务。
3. 模型解耦与流水线执行
受大型语言模型服务中“预填充”与“解码”阶段解耦的启发,StreamWise对扩散模型也进行了创新性的解耦。以视频生成为例,它将核心的Diffusion Transformer(DiT)阶段与Variational Autoencoder(VAE)解码阶段分离。这样,DiT在生成潜在空间表示时,VAE就可以开始解码已生成的部分,形成流水线,极大地减少了端到端延迟。
4. 自适应质量与内容复用
为了在资源紧张时仍能保证实时性,StreamWise引入了“自适应质量”机制。系统可以根据当前负载和截止时间压力,动态调整生成内容的参数,例如降低分辨率、减少去噪步数。一个巧妙的策略是:对视频开头的场景使用较低质量快速生成,以确保快速启动;同时对后面的场景使用高质量生成,在播放到那里时,高质量内容已经准备就绪。此外,系统还能复用静态内容(如片头、背景)或缓存中间结果,以提升效率。

图3:结合了模型解耦、截止时间感知调度和自适应质量的执行示例。不同阶段的任务被调度到不同类型的GPU上执行,以实现效率最大化。(图片来自原论文)
性能表现:成本、延迟与质量的精妙平衡
研究团队对StreamWise进行了全面的评估,结果令人印象深刻。
在低成本配置(仅使用8块A100 GPU)下,StreamWise生成一段10分钟高质量(1280x800分辨率,20去噪步数)播客视频的成本低于25美元。虽然总生成时间仍需数小时,但这已经比未经优化的基线方案快2.2倍且便宜得多,适用于没有实时性要求的场景。
在追求实时性的高效成本配置下,StreamWise混合使用了256块A100和64块H200 GPU。此时,系统能在用户提交请求后22秒内输出首帧,并确保后续生成速度跟得上实时播放,总成本控制在45美元以下,真正实现了高质量实时流式生成。

图4:不同硬件配置下,生成10分钟高质量播客视频的首帧时间(TTFF)与成本对比。StreamWise能够找到成本与延迟的最佳平衡点(左下角区域为优)。(图片来自原论文)
如果将质量要求放宽,StreamWise的潜力更大。在低质量模式下,生成成本可降至每分钟0.5美元,首帧延迟小于3秒。结合其自适应质量策略,系统可以从低质量快速启动,在播放过程中无缝切换到高质量,为用户提供“渐进式”的优质体验。

图5:高、中、低三种输出质量下的性能边界。自适应质量策略(红色线)能够以较低成本实现快速启动,并逐步提升至高质量。(图片来自原论文)
更广阔的应用前景
StreamWise的设计并非局限于播客视频生成。其模块化、可调度的架构可以轻松扩展到其他多模态应用场景,例如:
电影/动画生成:根据高级剧情梗概生成长篇叙事视频。 教育讲座生成:将教科书内容转化为带有教授虚拟形象的讲解视频。 视频配音:为原始视频生成翻译并口型同步的新音频。 短视频亮点提取:从长视频中自动识别并生成精彩片段。
研究表明,在这些多样化的应用上,StreamWise相比简单的基线方案,平均能降低17.5倍的成本和10.4倍的延迟。
总结与展望
微软研究院的StreamWise工作,为我们揭示了未来实时、交互式多模态AI应用背后的系统设计蓝图。它通过创新的资源调度、模型解耦和质量自适应技术,在成本、延迟和质量这个“不可能三角”中找到了一个极具吸引力的平衡点。
这项研究不仅为解决当前多模态生成服务的瓶颈提供了切实可行的方案,也预示着AI内容生成将从“离线渲染”步入“实时流式”的新时代。当生成速度足够快、成本足够低时,动态故事叙述、个性化AI导师、实时媒体编辑等今天看来颇具未来感的体验,都将变得触手可及。StreamWise正是通往这个未来的一块关键基石。
> 本文由 Intern-S1 等 AI 生成,机智流编辑部校对
-- 完 --
机智流推荐阅读:
1.
2.
3.
4.
cc | 大模型技术交流群 hf | HuggingFace 高赞论文分享群 lc|LangChain 技术交流群 code | AI Coding 交流群 具身 | 具身智能交流群 硬件 | AI 硬件交流群 推理 | AI 推理框架交流群 智能体 | Agent 技术交流群










