当大语言模型在虚拟世界里 “狂飙突进”,展现出惊人的理解和创造能力时,机器人技术却似乎还在物理世界中 “蹒跚学步”。尽管我们已经拥有了能下围棋、能写代码、能创作艺术的 AI,但让一个机器人在陌生的家庭环境中自主完成 “收拾餐桌”、“整理衣物” 这样看似简单的日常任务,依然困难重重。感知与动作的割裂、泛化能力的缺失、训练效率的低下、学习方式的单一,这些瓶颈如同一道道难以逾越的鸿沟,阻碍着通用机器人真正走进千家万户,成为人类的得力助手。
Physical Intelligence 团队的系列工作,正是为了系统性地跨越这些鸿沟而生。它以一条清晰、连贯且层层递进的技术演进路径,系统地回答了一个具身智能领域的核心问题:如何让人工智能模型真正理解并操控物理世界,实现从专用工具到通用智能体的跨越?

本文将沿着 、FAST、、、 的发表顺序,深度解析这一系列工作如何从理论奠基到实践突破,从实验室走向真实世界,最终构建出一个能够自主学习、持续进化的通用具身智能基座。
因其对全球具身领域的发展产生“重大价值”, 我们也已将pi系列工作收录到具身智能之心开源知识库内。
:破局之作,为机器人装上 “会思考的大脑”
在 诞生之前,机器人领域存在一个致命的矛盾,被业内称为 “感知与动作的死亡之谷”。一方面,以 GPT、PaliGemma 为代表的视觉语言模型(VLM)已经展现出强大的语义理解能力,它们能够看懂复杂的图片、听懂模糊的指令,甚至能进行逻辑推理和创意生成,但这些能力完全局限于虚拟的数字世界,无法直接转化为物理世界中机器人所需的、精确且连续的动作指令。另一方面,传统的机器人控制算法,如 PID 控制、模型预测控制(MPC),虽然能精确控制机械臂的每一个关节,实现高精度的运动,但它们缺乏对任务目标和环境语义的基本理解,只能执行预设的、固定的轨迹,无法应对开放世界的不确定性。
这种 “大脑” 与 “手脚” 的严重割裂,使得机器人要么是 “有思想无行动” 的 “空想家”,要么是 “有行动无思想” 的 “执行者”。如何构建一个统一的框架,让机器人既能 “看懂世界、听懂人话”,又能 “灵活动手、精准执行”,成为当时机器人领域最核心、最迫切需要解决的挑战。
论文信息
-
名称:: A Vision-Language-Action Flow Model for General Robot Control -
发表时间:2024 年 10 月 -
开源地址:https://physicalintelligence.company/blog/pi0
核心创新:首次定义通用 VLA 机器人范式
的革命性贡献在于,它首次提出并验证了一套完整的、面向通用机器人控制的 VLA(Vision-Language-Action)模型范式,成功为机器人装上了 “会思考的大脑”,并实现了大脑与手脚的无缝连接:

以 VLM 为核心,打通感知与认知:开创性地将预训练的视觉 - 语言模型(PaliGemma)作为整个系统的感知与决策主干。这一设计的颠覆性在于,它让机器人直接继承了互联网规模数据训练出的丰富视觉常识(如识别不同物体、理解场景布局、判断物体关系)和语言理解能力(如解析复杂的自然语言指令、理解模糊的意图)。这从根本上解决了机器人 “看不懂、听不懂” 的问题,使其具备了理解物理世界和人类意图的基础能力。
流匹配动作生成,实现精细操控:为了解决连续动作生成的难题,抛弃了传统的自回归离散动作范式,首创了基于 流匹配(Flow Matching)的连续动作专家。这一技术能够直接输出高达 50Hz 的平滑连续动作序列,就像为机器人提供了 “高清流畅的动作视频”,使其能够完成诸如折叠衣物、纸箱装箱、餐具整理、精细装配等需要极高灵巧度和实时性的任务。这在当时的 VLA 模型中是前所未有的突破。
跨具身通用训练,打破机型壁垒:提出了 跨具身训练(Cross-Embodiment Training)的概念,通过巧妙的动作空间归一化和标准化,统一了 7 种不同类型机器人(包括单臂机械臂、双臂机械臂、移动操作平台等)和 68 个不同任务的动作表示。这使得单一模型能够 “一视同仁” 地控制多种不同形态的机器人,打破了不同机器人之间的 “信息孤岛”,证明了 “一个模型控制所有机器人” 的可行性。
总结与不足
成功奠定了 VLA 机器人控制的底层范式,是具身智能领域的一次重要突破,它证明了 “VLA + 流匹配” 的架构在通用机器人控制上的巨大潜力。然而,作为初代原型,它也暴露了两个关键的、亟待解决的短板:
训练效率瓶颈:流匹配生成的连续动作序列在训练时存在严重的信息冗余问题,导致模型收敛速度极慢,训练成本极高,难以支撑大规模、多样化的数据训练。
环境泛化局限:的能力局限于训练数据中见过的实验室环境,一旦将其部署到完全陌生的真实家庭场景,由于环境布局、物体摆放、光照条件的变化,其性能会急剧下降,无法实现真正的开放世界部署。
这两个问题,直接催生了后续的 FAST 和 工作,成为系列下一步演进的明确方向。
FAST:效率革命,为大规模训练 “踩下油门”
的成功证明了 “VLA + 流匹配” 架构的有效性,但它也揭示了一个严峻的现实:连续动作序列的训练效率问题。为了实现对机器人的精细控制,动作序列的维度非常高(例如,一个 7 自由度的机械臂,其动作空间包括 7 个关节角度、末端执行器的位置和姿态等,维度超过 10),并且为了保证实时性,采样频率高达 50Hz。这意味着每个动作序列都包含大量的、高度冗余的信息。
直接使用这样的原始数据进行训练,会导致数据量爆炸,模型参数规模庞大,训练过程极其缓慢且难以收敛,成为一个巨大的 “算力黑洞”。传统的动作分词方法(如简单的逐维度分箱)只是将连续空间粗暴地离散化,并未从根本上解决信息冗余问题,反而可能丢失关键的动作细节,导致控制精度下降。因此,如何在不损失动作精度和连续性的前提下,高效地表示和训练连续动作序列,成为当时亟待解决的核心技术难题,也是制约 VLA 模型向更大规模、更多样化数据扩展的主要瓶颈。
论文信息
-
名称:FAST: Efficient Action Tokenization for Vision-Language-Action Models -
发表时间:2025 年 1 月 -
开源地址:https://pi.website/research/fast
核心创新:从信号压缩视角重构动作表示
FAST 的核心思想是将动作序列视为一种时间序列信号,并利用成熟的信号处理技术对其进行高效压缩和表示,从而为大规模训练 “踩下油门”,解决算力瓶颈问题:

频域变换(DCT):首先,将时域的动作序列通过 离散余弦变换(DCT)转换到频域。这一步的关键在于,它能够将动作序列的主要能量集中在低频分量上(对应动作的整体趋势和形状,例如手臂的整体移动轨迹),而高频分量则对应着快速、微小的抖动或噪声(例如关节的微小振动),这些高频分量可以被安全地忽略或压缩,而不会影响整体动作的执行效果。
稀疏化与无损压缩(BPE):在频域空间,FAST 保留了最重要的低频系数,此时的系数序列已经变得非常稀疏。然后,对这些稀疏的系数序列应用字节对编码(BPE)进行进一步的无损压缩。这使得动作序列的 token 数量相比原始方法减少了 3到13倍,极大地降低了数据量和训练复杂度。
通用分词器(FAST+):基于上述压缩原理,FAST 团队训练了一个通用的动作分词器 FAST+,它能够适配单臂、双臂、移动机器人等多种具身,实现开箱即用,无需为每种机器人单独设计分词策略,大大提升了模型的通用性和易用性。
效率与性能的平衡:基于 FAST 分词器训练的 -FAST 模型,在保持与原始流匹配版 性能持平的前提下,训练速度提升了整整 5 倍,这是一个非常显著的效率提升。
承上启下:扫清障碍,支撑未来突破
FAST 的出现,为系列后续的大规模数据训练扫清了算力与收敛性障碍。没有 FAST 带来的效率革命,后续 .₅所需的海量、多样化的真实家庭场景数据训练将变得不可想象。它是系列从 “演示级原型” 走向 “可规模化系统” 的关键技术支撑,为开放世界泛化能力的突破奠定了坚实的基础。
:泛化跃迁,让机器人走出 “象牙塔”
在 和 FAST 的基础上,模型的训练效率问题得到了有效解决,这使得训练更大规模、更多样化的数据成为可能。然而,另一个更关键、更根本的挑战浮出水面:如何让机器人从高度结构化、可预测的实验室环境(“象牙塔”),成功泛化到完全陌生、充满不确定性和动态变化的真实开放世界(如普通家庭)?
这是机器人技术从实验室研究走向实际应用的最大鸿沟。传统的模仿学习方法严重依赖于训练环境与测试环境的高度相似性,一旦环境布局、物体摆放、光照条件或物体外观发生变化,模型的性能就会急剧下降,甚至完全失效。这使得机器人在实验室里表现出色,但在真实世界中却寸步难行,沦为昂贵的 “实验室玩具”。如何让机器人学会 “举一反三”,理解任务的本质而非仅仅复制演示的轨迹,成为当时机器人领域最核心的研究课题。
论文信息
-
名称:: a Vision-Language-Action Model with Open-World Generalization -
发表时间:2025 年 4 月 -
开源地址:https://pi.website/blog/pi05
核心创新:异构数据协同与层级推理,实现开放世界泛化
通过架构级的创新和数据策略的革新,首次实现了 VLA 模型在真实开放世界的有效泛化,成功让机器人走出了 “象牙塔”:
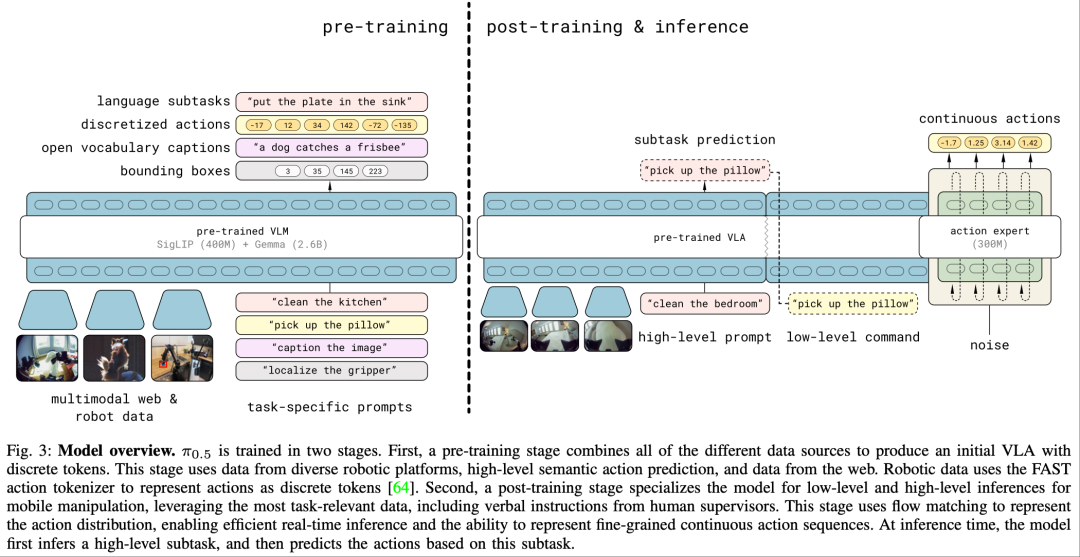
异构数据协同训练(核心突破):的最大胆尝试,是将五种完全不同类型、不同来源的数据融合到同一个模型中进行协同训练:
-
移动机械臂家庭数据:在真实住宅中由移动机械臂执行日常任务(如整理、清洁)的经验数据。
-
静态机械臂多环境数据:在不同实验室环境中由静态机械臂完成的各种操作任务数据。
-
实验室跨具身数据:来自 的、在多种机器人上完成的通用操作数据。
-
互联网多模态数据:用于增强模型的视觉理解和语言理解能力的通用数据。
-
人工语言指令数据:丰富模型对复杂、多样化自然语言指令的解析能力的数据。
令人惊叹的是,在训练数据中,高达 97.6% 的数据并非来自目标测试家庭,但依然能够在完全陌生的真实住宅中,成功完成厨房清洁、整理床铺、衣物收纳、物品归位等一系列复杂任务。这证明了异构数据协同训练策略的巨大成功,它让机器人学会了任务的本质(如 “清洁” 是清除污渍,“整理” 是将物品归位),而非具体的执行轨迹,从而有效打破了 “训练环境与测试环境必须高度相似” 的传统认知。
层级双路径推理架构(架构创新):为了应对真实世界中长时序、多步骤的复杂任务,首创了高层语义子任务 + 低层精细动作的双路径推理架构。
-
高层路径:负责理解整体任务目标,并将其分解为一系列可执行的语义子任务(例如,将 “准备早餐” 分解为 “打开冰箱”、“取出牛奶”、“倒入杯中”、“取出面包” 等)。这一层主要依赖于 VLM 的强大语义理解能力。
-
低层路径:负责根据高层分解的子任务,生成具体的、实时的连续动作序列来执行。这一层主要依赖于动作专家的精细控制能力。
这种分层架构极大地提升了模型在处理长时序任务(10-15 分钟)时的稳定性和成功率,使得机器人能够像人类一样,先规划 “做什么”,再思考 “怎么做”。
承上启下:关键一跃,但仍需进化
.₅成功地将 VLA 模型从实验室带到了真实家庭,标志着机器人技术从 “玩具” 到 “工具” 的重大跃迁。它证明了开放世界泛化的可行性,为家庭服务机器人的发展奠定了坚实基础。但它的能力仍局限于模仿学习的范畴。模型只能复现人类演示过的行为,一旦遇到新的、未见过的情况,或者在执行过程中出现微小偏差,就无法自主纠错、调整速度或优化策略。这为下一代工作指明了方向:从 “模仿者” 进化为 “学习者”。
:基座饱和,打造 “开箱即用” 的强大通用模型
证明了开放世界泛化的可行性,让机器人技术向实用化迈出了关键一步。然而,在模仿学习的框架下,模型的性能仍有提升空间。如何进一步优化模型结构、提升基座能力,打造一个 “开箱即用” 的强大通用模型,成为新的目标。同时,随着模型能力的增强,如何更好地隔离不同类型的知识(如通用的视觉语言知识和特定的动作执行知识),以防止在学习新任务时破坏已有的通用能力,避免过拟合,也成为一个重要的研究方向。此外,用户对于机器人模型的易用性要求越来越高,希望模型能够在无需大量微调的情况下,直接完成各种复杂任务。
论文信息
-
名称: Model Card -
发表时间:2025 年 11 月
核心创新:全面能力提纯,实现性能饱和
并非对架构的颠覆,而是在其基础上进行的全面能力提纯与性能饱和,旨在将模仿学习路线下的 VLA 基座能力推到极致,打造一个强大的、开箱即用的通用模型:

主干模型升级:将视觉 - 语言主干从 PaliGemma 升级为性能更强的Gemma3 4B。Gemma3 拥有更大的参数量和更强的语义理解能力,这使得能够更好地理解复杂、模糊的自然语言指令,更精准地解析复杂的视觉场景细节,从而做出更智能的决策。
动作专家扩容:动作生成专家的参数规模从 300M 大幅提升至860M。更大的参数规模意味着动作专家能够学习更复杂的动作模式和更精细的控制策略,从而增强模型生成复杂、精细连续动作的能力,使其能够处理更具挑战性的操作任务,如更复杂的衣物折叠、更精细的物品组装等。
知识隔离训练(KI):引入了创新的知识隔离(Knowledge Isolation)训练策略。在训练过程中,该策略确保动作专家的梯度不会回传到 VLM 主干。这意味着模型在学习特定任务的动作执行时,不会干扰或破坏其已有的通用视觉语言知识,从而提升了模型的稳定性和泛化能力,使其能够更好地应对分布外的新任务和新环境。
开箱即用性能的质变:
-
任务能力提升:无需任何任务微调,即可稳定完成如洗衣折叠、纸箱组装等必须经过微调才能胜任的复杂任务。 -
移动任务增强:在移动操作任务上的吞吐量(单位时间完成任务数)全面超越 ,效率更高。 -
分布外泛化:能够处理训练数据中从未出现过的物体(如用面包擦污渍)和指令(如把短裤挂在烤箱把手),展现出更强的零样本泛化能力。
承上启下:模仿学习的终点,自主学习的起点
.₆代表了模仿学习路线的终点。它证明了通过优化模型结构、扩大参数规模和改进训练策略,可以将基于演示的 VLA 模型性能提升到一个非常高的水平。它打造了一个强大的、开箱即用的通用基座,为后续的自主学习奠定了坚实的基础。然而,模仿学习的本质决定了它无法让机器人超越人类演示的水平,也无法自主应对环境变化和执行错误。要实现真正的智能,必须引入自主学习机制。
:终极闭环,实现从 “模仿者” 到 “学习者” 的进化
尽管已经非常强大,但它仍然是一个 “被动的模仿者”,其能力上限被人类演示数据所限制。它只能复现人类教给它的行为,无法自主探索新策略、纠正执行中的错误、优化任务完成的速度和效率。在真实世界中,环境是动态变化的,任务需求也是多样的,仅仅依靠模仿学习无法让机器人适应复杂多变的场景。
要让机器人真正走向实用,成为能够自主适应环境变化、持续提升能力的通用智能体,必须赋予它从自身实践经验中学习、进化的能力。这就需要引入强化学习(RL)这种能够从试错中学习的强大范式。然而,如何将强化学习与现有的 VLA 框架无缝结合,是实现这一目标的核心挑战。传统的强化学习方法通常需要设计复杂的奖励函数,并且难以直接处理 VLA 模型生成的连续动作序列。
论文信息
-
名称:: a VLA That Learns From Experience -
发表时间:2025 年 11 月 -
开源地址:https://pi.website/blog/pistar06
核心创新:RECAP 强化学习框架,实现自主进化
通过创新的 RECAP(Reward-Conditioned Action Prediction)强化学习框架,成功地将强化学习融入 VLA 模型,实现了从模仿到自主学习的终极跃迁:
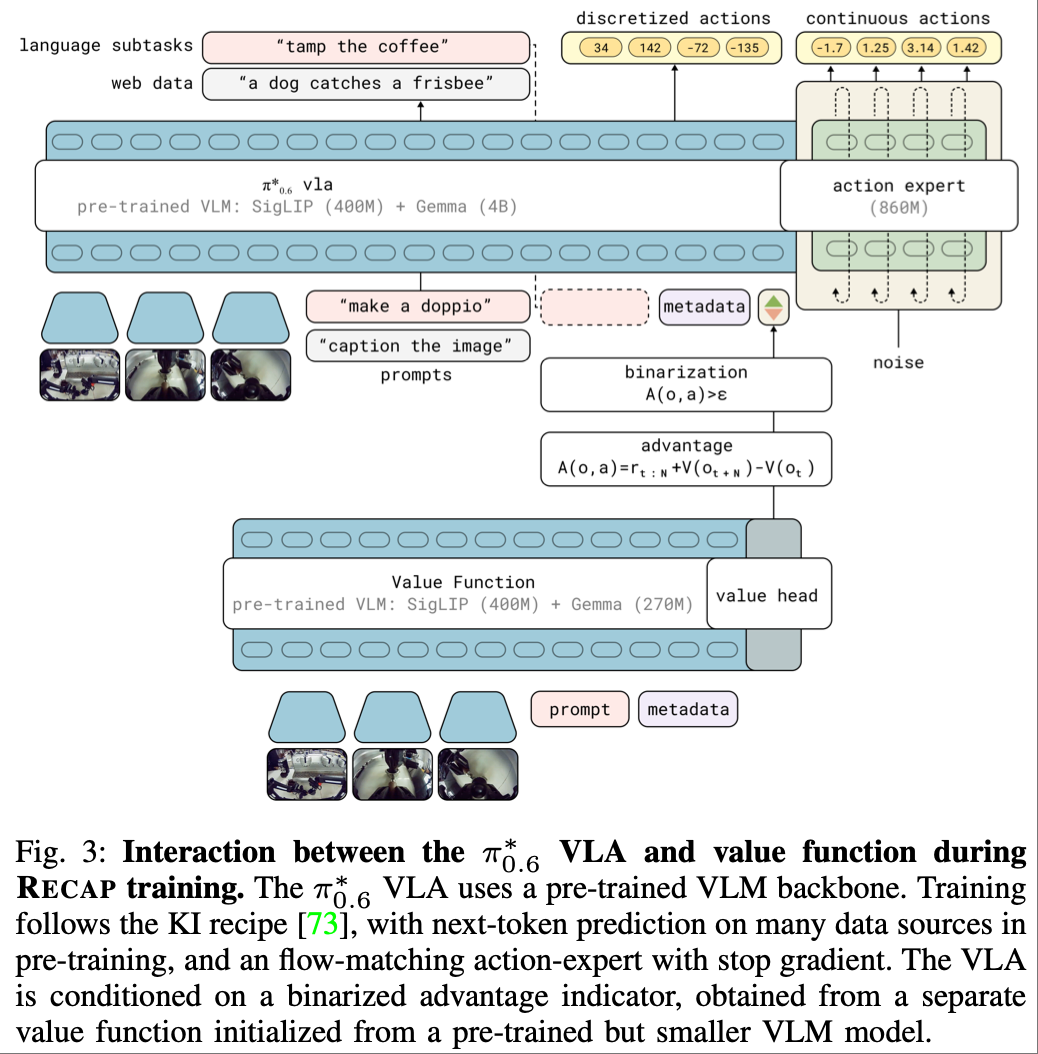
优势条件注入:RECAP 框架将强化学习的 “优势函数”(Advantage Function)作为一种条件,无缝地融入到 VLA 的推理过程中。这个优势函数能够评估当前动作相对于平均水平的好坏,以及该动作对任务整体进度的贡献,从而为模型提供明确的学习信号,指导模型生成更优的动作。这一设计无需修改原有的流匹配动作生成结构,实现了强化学习与 VLA 的平滑结合。
多源数据融合学习:模型能够同时从三种来源学习,形成一个闭环的学习系统:
-
人类演示数据:提供高质量的基础策略,让模型快速学习正确的行为模式。 -
自主尝试数据:包括机器人在环境中自主探索的成功和失败案例,提供试错学习信号,让模型从实践中学习。 -
人工纠错干预数据:当机器人执行失败时,人类进行少量的干预和纠正,提供快速修正的指导,加速学习过程。
缺陷精准消除:通过强化学习,模型能够精准地识别并消除在模仿学习阶段形成的固定错误模式(例如,折叠衬衫时总是将衣领朝下),仅需少量的自主尝试数据即可完成修正,显著提升了任务执行的鲁棒性。
实用化能力的飞跃:在多个实用化任务上展现出了惊人的性能提升:
-
任务效率翻倍:在意式咖啡制作、纸箱工厂组装、多样化衣物折叠等任务中,任务完成的吞吐量(单位时间完成任务数)相比实现了翻倍。 -
鲁棒性显著增强:任务失败率降低了 50%,能够更好地应对环境中的微小干扰和不确定性,例如物体位置的轻微偏移、光照的变化等。 -
长时间稳定运行:实现了连续 13 小时的稳定任务执行,这是迈向实用化部署的关键一步,证明了模型的可靠性。
总结:完整的进化闭环
标志着系列完成了从 “被动模仿者” 到 “主动学习者” 再到 “自我优化者” 的终极进化。它证明了 VLA 模型可以通过与物理世界的交互,不断积累经验、优化策略,最终达到甚至超越人类演示的水平。这为通用具身智能的未来发展指明了清晰的路径。
最终总结:一条完整的具身智能进化之路
回顾整个系列的发展历程,我们可以清晰地看到一条从理论到实践、从实验室到真实世界、从被动接受到主动学习的完整技术闭环:
定范式:解决了 “感知与动作割裂” 的问题,定义了 “VLM 主干 + 流匹配动作专家 + 双阶段训练” 的通用机器人基座范式,为机器人装上了 “会思考的大脑”。
FAST 提效率:解决了 “训练效率低下” 的问题,通过信号压缩技术重构动作表示,为大规模数据训练扫清了障碍,让模型能够 “跑得快”。
破泛化:解决了 “开放世界泛化” 的问题,通过异构数据协同训练和层级推理架构,让机器人从实验室走向真实家庭,实现了 “走出去”。
满能力:将 “模仿学习能力” 推向极致,打造了强大的开箱即用基座,实现了无需微调即可完成复杂任务的性能,做到了 “用得好”。
闭进化:解决了**“自主学习与进化” **的问题,通过强化学习赋能,实现了从模仿者到学习者的终极转变,让机器人能够从经验中持续进化,达到了 “学得快”。
系列不仅是一系列技术创新,更是一套完整的、可落地的通用具身智能解决方案。它完整地回答了具身智能领域最核心的问题:如何让人工智能模型从互联网知识出发,成功扎根物理世界,实现通用操控、开放泛化,并最终通过自主学习达到精通的水平。这为未来家庭服务机器人、工业自动化以及更广泛的人工智能应用奠定了坚实的基础,推动着具身智能从 “蹒跚学步” 迈向 “自主进化” 的新纪元。










