编辑丨具身智能之心
本文只做学术分享,如有侵权,联系删文
>>
更多干货,欢迎加入国内首个具身智能全栈学习社区:(戳我),这里包含所有你想要的。
如果说过去一段时间里,Vision-Language-Action(VLA)模型让机器人第一次真正展现出“看得懂、听得懂、做得到”的统一能力,那么离散扩散 VLA(dVLA)则进一步把多模态对齐和动作生成的上限推高了一截。它们不仅能更好地继承大模型的预训练知识,也在复杂语义理解和动作建模上展现出很强的潜力。
但是离散扩模型的推理速度往往难以满足真实机器人对高频实时控制的要求,很多任务要求控制频率稳定在 30 Hz 左右,才能真正应对动态环境、移动目标和连续操作。
最近的工作 Fast-dVLA,正是想解决这个问题:能不能在尽量保留离散扩散 VLA 性能优势的同时,把推理速度真正推进到实时控制区间?
Fast-dVLA 首次在保留离散扩散 VLA 性能优势的同时,将推理速度真正推进到真实机器人的实时控制区间,实现 2.8x-4.1x 加速与稳定 30 Hz 控制,在我们搭建的流水线场景上一分钟完成13个物件处理。
传送带抓取任务中,Fast-dVLA 能更稳定地跟上动态目标,推理速度优势也会直接转化为任务表现。

链接
arXiv: https://arxiv.org/abs/2603.25661 Project: https://chris1220313648.github.io/Fast-dVLA/
为什么不够快?
我们认为,现有离散扩散 VLA 的速度瓶颈,主要来自两个方面。
第一,传统 dVLA 通常采用双向注意力机制。虽然这种结构有助于全局建模,但也带来一个直接代价:很难有效复用 KV Cache。这意味着模型在每一轮去噪时,都需要重复做大量计算,推理开销始终降不下来。
第二,许多 dVLA 在设计上直接沿用了 diffusion LLM 的解码方式,但动作并不是普通文本 token。动作天然具有结构性、时序性和维度对齐特征,如果不针对这一模态单独设计解码机制,就很难把效率真正做出来。
也就是说,dVLA 的问题并不是“模型不够强”,而是“生成方式还没有真正为动作而设计”。
一个关键观察:双向 dVLA 里,其实藏着块级左到右规律
Fast-dVLA 的出发点,并不是简单做工程优化,而是先回到模型本身。
我们观察到,尽管传统 dVLA 使用的是双向注意力,但它在实际去噪过程中,内部依然表现出一种隐含的块级左到右解码规律。换句话说,模型虽然表面上是双向的,但在动作生成时,前面的动作块往往会先被“清理干净”,后面的动作块再逐步完成。

这一现象给了我们一个非常自然的启发:
如果模型本身就有块级解码趋势,那么我们是否可以顺着这个规律,重构 dVLA 的推理过程,让已经完成的块被缓存,让后续块继续并行去噪?
这就是 Fast-dVLA 的核心思想。
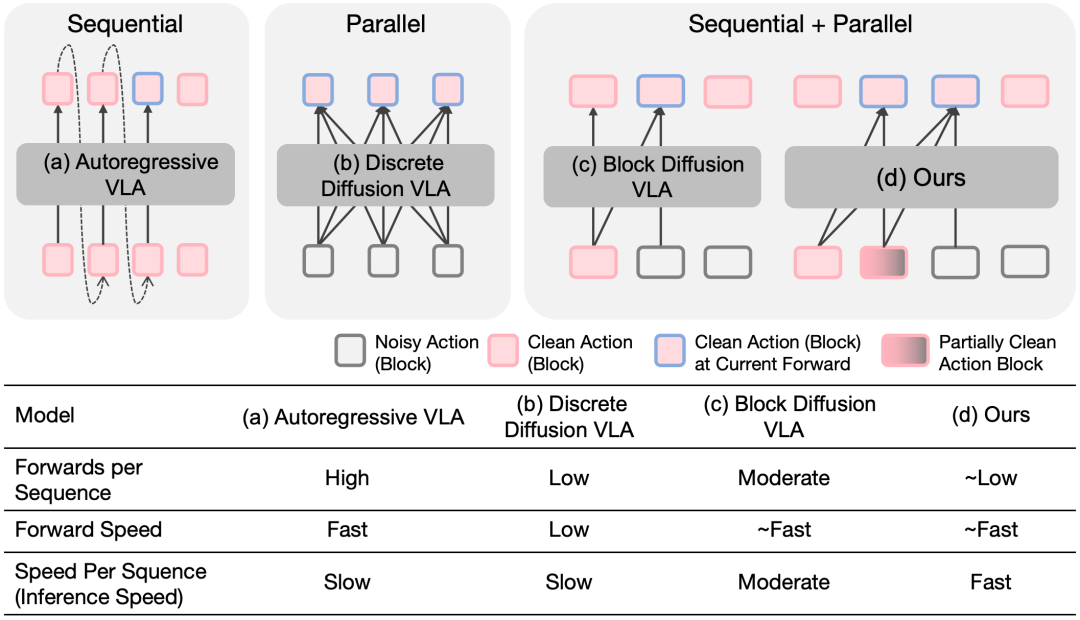
Fast-dVLA:既要 KV Cache 复用,也要跨块并行
围绕这个观察,我们提出了 Fast-dVLA,一套面向离散扩散动作生成的 block-wise diffusion 加速框架。
它主要包含三层关键设计。
1. 用 block-wise attention 让 KV Cache 真正可复用
我们将动作 token 按块组织,并采用 block-wise causal attention 约束注意力模式。这样一来,一旦前面的动作块已经完成去噪,它对应的 KV 状态就不会再变化,可以被稳定缓存并复用。
更进一步,我们发现:当 block size 与动作维度对齐时,可以同时获得更优的解码效率和更好的性能表现。 这说明,动作结构本身并不是推理优化的负担,反而可以成为设计高效解码机制的重要线索。
2. 用 discrete diffusion forcing 保留扩散建模优势
如果只做块顺序解码,虽然可以利用缓存,但速度提升仍然有限。为此,我们进一步引入 discrete diffusion forcing 的噪声调度方式,让不同动作块在同一次推理中处于不同噪声水平。
直观来说,就是让前面的块更快收敛,后面的块继续并行细化。这样既保留了扩散模型逐步去噪的建模能力,也把跨块并行真正做了出来。
3. 用不对称蒸馏,把传统 dVLA 高效迁移成 Fast-dVLA
除了推理,训练成本同样重要。为了避免从头训练一个全新的 block diffusion VLA,我们提出了不对称蒸馏策略:以已经微调好的双向 dVLA 作为教师模型,把它的能力蒸馏到 block-wise student 上。
这样做的好处是非常直接的:只需要少量蒸馏步数,就能把传统双向 dVLA 高效迁移成 Fast-dVLA。 再配合我们设计的 pipelined parallel decoding,最终把这种结构优势转化为真实可用的实时推理能力。
实验结果:不只是更快,而且是真的快很多
在多个经典基准上,Fast-dVLA 都展现出了非常稳定的加速效果。
在 LIBERO、CALVIN 和 SimplerEnv 上,Fast-dVLA 带来了 2.8x 到 4.1x 的推理加速,同时保持甚至略微提升任务性能。 在 LIBERO 上,基于 DD-VLA 的 Fast-dVLA 达到 96.6% 平均成功率,相比原始 DD-VLA 还有小幅提升。 在 CALVIN 上,Fast-dVLA 在长时序任务中实现 2.8x 加速,并保持强任务完成能力。 在 SimplerEnv 上,Fast-dVLA 达到 366.4 tokens/s,在对比的离散输出 VLA 中展现出非常突出的解码速度。



真实机器人实验:稳定 30 Hz,真正进入实时控制区间
我们在真实世界双臂机器人平台上,对 Fast-dVLA 进行了多项动态操作任务测试,包括:
传送带抓取 蔬菜分类收纳 按语言指令抓取目标蔬菜并放入容器

结果非常直接:Fast-dVLA 在所有真实任务中都能稳定维持 30 Hz 控制频率。 这意味着离散扩散 VLA 真正具备了进入高频控制场景的可能性。尤其是在传送带抓取这类对响应速度极其敏感的任务中,Fast-dVLA 的速度优势直接转化为了更强的任务表现;而在需要语言理解与语义区分的任务上,它又延续了离散扩散模型在多模态理解上的优势。
换句话说,Fast-dVLA 并不是单纯为了“加速而加速”,而是在保持 dVLA 原有能力边界的同时,把它真正推向可部署、可落地、可实时控制的区间。
演示
下面这几个真实任务 demo,更直观地体现了 Fast-dVLA 在速度与能力上的平衡。
1. Conveyor Picking
Baseline
Fast-dVLA
在高速传送带抓取任务中,对比 baseline 可以更直观地看到:Fast-dVLA 能更稳定地跟上动态目标,推理速度优势也会直接转化为任务表现。
2. Vegetables Stowing

在蔬菜分类收纳任务中,Fast-dVLA 同时考验语义理解、抓取决策与执行效率,能够兼顾准确性与响应速度。
3. Vegetables Retrieving
Put the top right vegetable into the pot

Put the top left vegetable into the pot

在按语言指令抓取目标蔬菜并放入容器的任务中,两段 retrieval demo 更直观地展示了 Fast-dVLA 在真实世界场景下的位置泛化与语义理解表现。
我们想说明什么?
只要真正从动作模态的结构出发,重新思考解码顺序、缓存机制和并行方式,dVLA 完全有机会同时兼顾:
强多模态理解 高质量动作建模 高频实时控制
实验也验证了我们的方法适配不同的dvla模型,我们希望Fast-dVLA能 作为dvla有效的后训练范式,进一步缩小dVLA实际部署的距离