【区角快讯】2026年4月2日,智谱正式推出专为视觉编程设计的原生多模态Coding基座模型GLM-5V-Turbo。该模型在预训练阶段即实现视觉与文本能力的深度融合,突破传统纯文本编程范式,能够准确解析设计稿、界面截图及网页布局,并据此自动生成完整且可运行的代码,真正达成“看得懂画面、写得出代码”的目标。
GLM-5V-Turbo具备三大关键技术特性。首先,作为原生多模态Coding基座,其可直接处理图片、视频、设计文档等多元输入形式,支持画框标注、屏幕截图等工具调用,上下文窗口容量已扩展至200k,显著拓展了智能体从感知到行动的视觉交互链路。
其次,该模型在强化视觉理解的同时,并未牺牲原有编程能力。通过多任务协同强化学习机制,在多模态Coding与GUI Agent等关键评测中表现领先,同时确保在纯文本环境下的编码、逻辑推理及工具调用能力维持原有水准。
第三,GLM-5V-Turbo深度适配Claude Code框架及龙虾(OpenClaw/AutoClaw)应用场景,构建起“环境识别—动作规划—任务执行”的完整闭环流程,并配套提供全套官方Skills,实现开箱即用的开发体验。
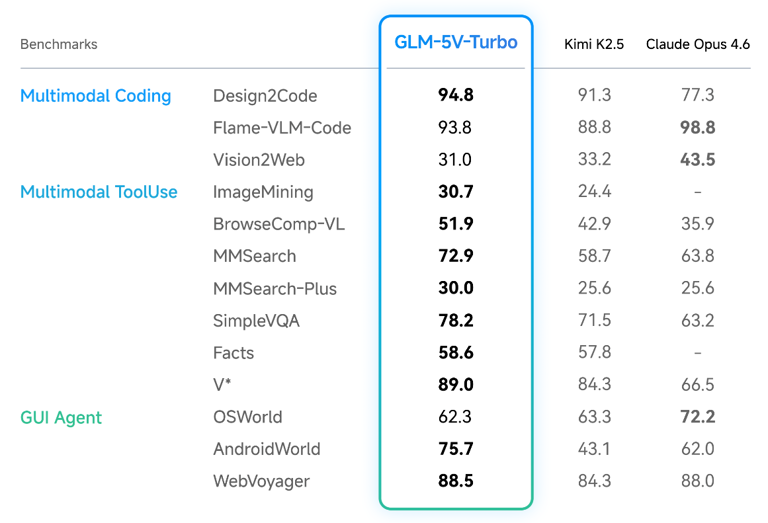
实测结果表明,该模型在设计稿还原、视觉驱动代码生成、多模态检索问答等多项基准测试中均处于行业前列;在AndroidWorld与WebVoyager等真实图形用户界面操控任务中亦展现出卓越性能。接入龙虾Agent后,其视觉感知能力显著提升,在PinchBench、ClawEval及ZClawBench等专业评测中取得优异成绩,复杂任务执行可靠性获得验证。
目前,GLM-5V-Turbo已在“图像即代码”前端复刻、GUI自主探索建站、K线图语义解析及图文报告自动生成等典型场景落地。用户可通过AutoClaw、Z.ai等产品直接体验,亦能经由官方API集成使用,相关Skills已在ClawHub平台上线。
随着多模态交互成为AI Agent实用化的核心路径,GLM-5V-Turbo的发布标志着大模型编程正加速迈入“视觉原生”新阶段。