
背景:扩散模型推理成本亟待优化
扩散模型(Diffusion Models)近年来在高保真图像和视频生成上取得了令人瞩目的成果。然而,这类模型在推理阶段需要经过数十步乃至上百步的迭代去噪,每一步都要运行庞大的 U-Net 或 Transformer 模型,导致推理耗时巨大。对于高分辨率生成或视频生成等应用,迭代推理的开销更是呈指数级上涨,使实时应用变得非常困难。如何在不牺牲生成质量的前提加速扩散模型的推理,已成为学界和工业界共同关注的课题。
01
扩散模型推理优化的总体方案
基于上述需求,PaddleMIX 从模型蒸馏、模型推理缓存(Training-Free)以及深度学习框架编译优化等多个技术维度出发,打造了 Fast-Diffusers 扩散模型推理加速工具箱,便于开发者根据实际场景灵活组合运用,从而有效提升扩散模型的推理速度。本稿件主要介绍缓存加速相关的方案。

图1 推理加速工具箱
02
推理缓存加速方案
传统的加速方案主要包括推理引擎优化和推理策略优化两类。在推理策略优化方面,近年来涌现出了一系列无需额外训练(Training-Free)的扩散模型推理加速模块,其中计算缓存(Computation Caching)是一种颇具代表性的方法。其核心思想是在推理过程中缓存并复用模型某些层的中间输出,避免每一步都重复完整计算。由于扩散模型在相邻时间步的特征变化往往很小且平稳,许多层的输出在连续步之间冗余度高。因此,只要妥善选择哪些层、在何时复用之前的结果,就能节省大量计算,同时几乎不影响生成图像质量。这些方法不需要对原有扩散模型进行额外训练或修改模型权重,只需在推理时即插即用地启用相应模块,便可大幅减少冗余计算。PaddleMIX 最新发布的扩散模型工具箱 PPDiffusers 中,就自主设计和集成了多种这类加速插件,包括 SortBlock、TeaBlockCache 和 FirstBlock-Taylor 等。它们能够在不改动主干网络的情况下插入模型推理流程,在保证生成图像质量的同时,实现2倍以上的端到端推理加速效果。
下面我们将介绍这些加速方案的原理。
03
方法简介
▎ PART 01 Sortblock
■ 1.1 时间步之间的区别
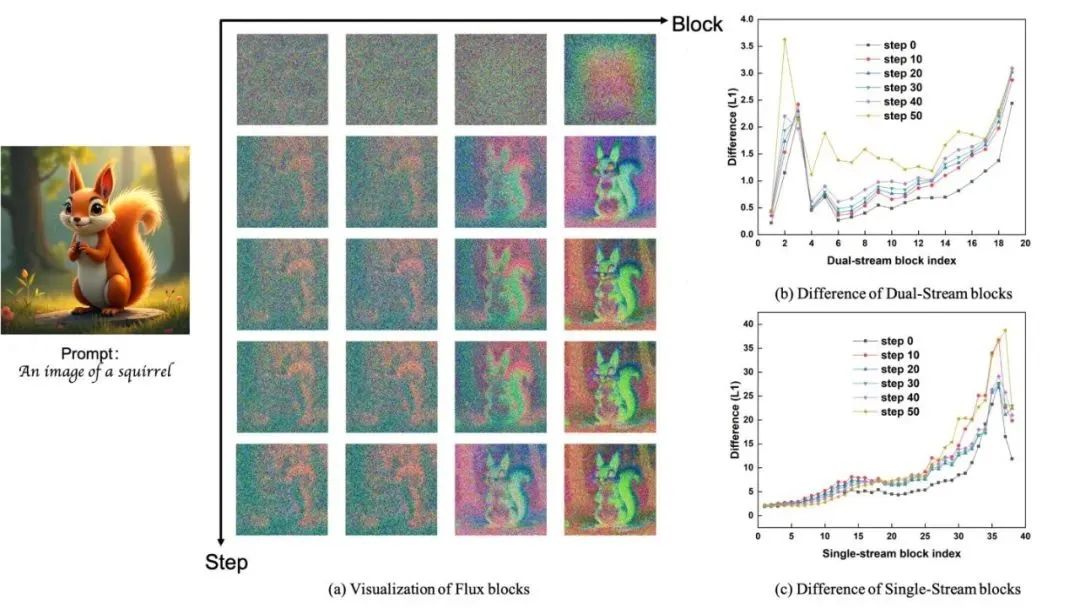
为了更好的探索在不同去噪阶段在时间步上的差异,我们量化了在扩散时间步上的所有时间步的输出差异,如图1所示。我们的分析表明,在中间部分大约70%的扩散步骤中,前后时间步的输出显示出低差异。这段存在大量冗余信息,也是我们主要应用策略的部分,首尾两头差异较大的部分,我们认为在后续缓存策略中需要分配较大的重计算比例甚至是全量计算,才能够更好的减少加速前后模型输出误差。

图2 各 step 之间的L1距离随着去噪过程的变化
■ 1.2 DiT 块之间的区别
理想情况下,如果我们可以提前获得下一个时间步的各个 DiT 块的变化,我们可以直接测量相邻时间步 DiT 块的变化之间的差异,并根据它们的差异来决定是否要重新计算这些 DiT 块。在本文中,我们使用余弦相似度作为度量。例如,计算相同 DiT 块在相邻时间步变化的余弦相似度如下:
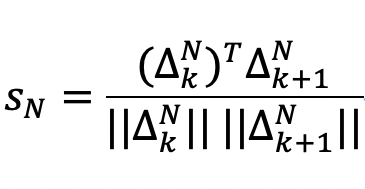
其中,![]() 是第 K 步中第 N 个 DiT 块的输入输出变化,
是第 K 步中第 N 个 DiT 块的输入输出变化,![]() 是第 K+1步中第 N 个 DiT 块的输入输出变化,其中
是第 K+1步中第 N 个 DiT 块的输入输出变化,其中![]() 越接近于0,表明两个 DiT 块的差异越大,应该被重新计算。此外,越接近于1,说明相似度越高,可以重新利用前一时间步的信息来加速模型的推理速度。因此,
越接近于0,表明两个 DiT 块的差异越大,应该被重新计算。此外,越接近于1,说明相似度越高,可以重新利用前一时间步的信息来加速模型的推理速度。因此,![]() 可以用来定义和判断一个 DiT 块是否需要重新计算的标准。
可以用来定义和判断一个 DiT 块是否需要重新计算的标准。
■ 1.3 特征分析
![]()
的相似度判断。
■ 1.4 SortBlock 实现
扩散模型是基于时间步逐步去噪的,然而,这种演化是存在稀疏性的,因为在中间步去噪过程中前后特征变化存在高相似度。这种稀疏性(如上图所示)表明,在每一步中重新计算所有的特征通常是不必要的。
为了利用这种稀疏性,SortBlock 只选择性地更新相邻步骤之间变化最大的一小部分 DiT 块。其挑战在于如何高效、准确地识别此类 DiT 块。图3显示整体算法流程,计算由![]() 的 DiT 块输入输出变化和
的 DiT 块输入输出变化和![]() 的 DiT 输入输出变化之间的余弦相似度。利用每个 DiT 块输入输出变化之间的余弦相似度来识别变化最大的那些 DiT 块。只有这些被选中的 DiT 块才会进行完整的特征重计算和缓存更新。
的 DiT 输入输出变化之间的余弦相似度。利用每个 DiT 块输入输出变化之间的余弦相似度来识别变化最大的那些 DiT 块。只有这些被选中的 DiT 块才会进行完整的特征重计算和缓存更新。

图4 算法流程图
计算余弦相似度需要相邻两个时间步的特征,如果都全量计算会使得时间成本较高,使得策略速度上限受限。通过利用特征轨迹的连续性质,我们使用了一种跨时间步估计中间特征的预测缓存方法。
线性预测方法
与直接拷贝特征不同,我们同时缓存特征值和它们的时间差分。这使得我们可以使用下面的公式来预测 t- k 时刻的特征轨迹:

其中![]() 和
和![]() 表示全量计算时间步的特征。这种一阶近似捕捉了特征轨迹的线性趋势,显著提高了直接特征重用的精度。特别说明,我们的特征预测不仅仅为了计算余弦相似度来预测
表示全量计算时间步的特征。这种一阶近似捕捉了特征轨迹的线性趋势,显著提高了直接特征重用的精度。特别说明,我们的特征预测不仅仅为了计算余弦相似度来预测![]() ,所有需要缓存复用特征值的部分全部替换为线性预测。
,所有需要缓存复用特征值的部分全部替换为线性预测。
缓存策略由两个超参数控制,策略刷新间隔 K 和自适应更新比例![]() ,推理过程一般都会涉及到:
,推理过程一般都会涉及到:
初始化:当 k = 0(mod K)时,当前时间步开始计算所有的特征,并存储所有 DiT 块的输入输出变化。
线性预测:当 k = 1(modK=1)时,基于上一时间步全量计算得到的特征值,通过线性预测来预测当前时间步的所有的特征,并存储所有 DiT 块的输入输出变化

识别变化:计算每个 DiT 块的当前输入输出变化和上一时间步之间的余弦相似度。
选择DiT块:选择最低的个 DiT 块进行标记,形成得到策略序列,标记需要重计算的 DiT 块在序列为1,其余为0。
重算与预测:只对序列中元素为1对应的 DiT 块重计算;其余部分通过线性预测得到当前的输入输出变化。
更新Cache:对于重计算所得到的值替换相应的缓存值。这种自适应更新机制利用时间稳定性来最小化计算量,同时通过有针对性的特征刷新来保持生成质量。
■ 1.5 SortBlock 加速效果展示
SortBlock 可以以无需训练的方式加速 FLUX 2倍+,而不会降低视觉质量。下图显示了 SortBlock 在 FLUX 上使用不同加速比生成的结果:1.0(原始)、2.0倍加速、2.395倍加速、2.88倍加速和3.06倍加速。





左右滑动查看更多
▎PART 02
计算缓存扩散推理加速体系:TeaBlockCache&FirstBlock-Taylor 与经典方法统一集成
除 SortBlock 外,此次发布,还原创了 TeaBlockCache 和 FirstBlock-Taylor 两种计算缓存与预测加速方案,同时兼容并实现了多种经典的开源无需训练方法。
TeaBlockCache:
FirstBlock-Taylor:
与此同时,PaddleMIX 的推理加速框架也兼容并复现集成了多种经典的无需训练加速方法,方便开发者直接调用或与新方法组合。例如,TGATE(Temporal Gating of Attention)方法针对扩散模型推理过程,将文本条件的跨注意力输出在初始若干步后冻结并复用,从而跳过后续步骤中重复的注意力计算(实验显示可加速推理约10%–50%,且对图像质量影响很小)。PAB(Pyramidal Attention Broadcasting)则采用金字塔式的注意力广播策略,在多层之间按固定间隔重用注意力计算结果,减少逐层重复计算。另外,BlockDance 方法则利用相邻时间步之间结构相似的特征,将这些相似度高的特征缓存并复用,以降低冗余计算,在不损失生成一致性的情况下提升了25%–50%的推理速度。而 TaylorSeer 方法进一步表明可以通过多步输出推导高阶导数,用泰勒级数预测未来时间步特征,实现高效率的推理加速且几乎无额外误差。PaddleMIX的加速插件体系融合了以上方法的思想,开发者既可以单独启用某种加速策略,也可以将它们组合使用,以获得更佳的综合提速效果。
04
性能评估:生成质量 vs 推理速度


左右滑动查看更多
上图展示了多种加速方法在 COCO1k 数据集上的推理速度提升倍数(Horizontal: Speed-up)与生成图像质量(Vertical: SSIM,相对于原始模型)的关系曲线。其中,SSIM(结构相似度)越接近1表示加速前后生成图的差异越小。可以看出,传统方法如 TGate、PAB 在获得有限加速时图像质量便急剧下降(例如 PAB 在约1.8倍加速时 SSIM 跌至0.5左右,生成效果明显劣化),难以在保证质量的同时追求更高速度。而 PaddleMIX 推出的几种新插件方法表现出明显更优的速度-质量权衡:在2倍以上加速区域,TeaBlockCache、SortBlock 结合 Taylor 近似等方案依然能将 SSIM 维持在0.9左右的高水平,几乎看不出与未加速结果的差别;即使将加速倍率提高到3×甚至更高,生成质量也仅有轻微下降,远优于其它对比方法。例如,SortBlockCache 在约2.5×加速时仍保持了接近0.90的 SSIM,可谓“大幅提速、质量不损”。上述评测结果证明了无需训练的加速插件完全可以将扩散模型的推理效率提升一倍以上,同时对生成效果几乎没有影响。总体而言,在加速比 ≈ 2.0 的条件下,各方法在 SSIM 和 PSNR 上的优劣次序为:SortBlock > TeaBlockCache > FirstBlock-Taylor > BlockDance > TaylorSeer ≈ TeaCache ≫ PAB/TGate。
05
如何使用这些加速模块?
PaddleMIX 已将上述加速方案开源集成到其扩散模型推理库(PPDiffusers)中。开发者只需通过简洁的配置或调用接口,便可在现有扩散模型推理流程中启用相应的加速插件,而无须修改模型本身代码。例如,在组建 FLUX 推理 Pipeline 时,可以指定使用 SortBlock 或 TeaBlockCache 进行推理加速
import paddlefrom ppdiffusers import FluxPipeline, SortBlockConfig, apply_sort_blockpipe = FluxPipeline.from_pretrained("black-forest-labs/FLUX.1-dev", paddle_dtype=paddle.bfloat16)# Configure SortBlock optimizationconfig = SortBlockConfig(num_inference_steps=50,timestep_start=900,timestep_end=100,percentage=1.0,step_num=1,step_num2=5,beta=0.3,current_timestep_callback=lambda: getattr(pipe, "_current_timestep", None),)# Apply SortBlock optimization using the integrated frameworkapply_sort_block(pipe.transformer, config)prompt = "A cat holding a sign that says hello world"image = pipe(prompt,height=1024,width=1024,guidance_scale=3.5,num_inference_steps=50,max_sequence_length=512,generator=paddle.Generator().manual_seed(42),).images[0]image.save("text_to_image_generation-sortblock-flux-hook-result-0.png")
实际集成时仅需极少的代码改动即可完成,所有加速模块的源码和使用说明都可以在 PaddleMIX 的 GitHub 仓库中获取。感兴趣的开发者可以查阅开源代码,了解各模块的实现细节和参数配置,并将这些加速策略应用到自己的扩散模型项目中。凭借 PaddleMIX 提供的高性能实现,即使是不熟悉底层优化的开发者也能开箱即用地为扩散模型插上“加速器”。
06
总结与展望
本文介绍了 PaddleMIX 最新推出的几款无需训练(Training-Free)的扩散模型推理加速插件。通过动态跳过冗余计算(SortBlock)、智能缓存复用特征(TeaBlockCache)以及利用数学近似预测(FirstBlock-Taylor)等手段,这些模块在不改动原模型的情况下,将扩散模型的推理速度提升了2倍以上,同时保持了与原始模型几乎一致的生成质量。插件化的设计使它们易于使用和组合,开发者可以根据需求灵活地应用单个或多个加速策略。
展望未来,随着扩散模型在更大规模数据和更多应用领域的发展,此类推理高效化的需求将更加迫切。我们有理由相信,Training-Free 的加速方法还有很大潜力可挖——例如更精细的动态裁剪策略、更通用的特征预测模型等,都有望进一步降低推理延迟。PaddleMIX 也将持续完善多模态模型的工具链,在提供强大模型能力的同时兼顾实际部署效率。希望这些加速插件能够帮助开发者更快地落地扩散模型应用,激发出更丰富的创意,实现高质量生成与高效推理的双赢。
PaddleMIX 扩散模型加速插件相关代码已在 GitHub 开源。欢迎大家访问仓库获取源码并提出宝贵意见,共同推进扩散模型技术的发展与应用!
开源代码链接:
https://github.com/PaddlePaddle/PaddleMIX
技术交流:扫描下方二维码,加入 PaddleMIX 官方技术交流群,探索更多技术课程,与官方技术团队交流合作。















