SMARTFLOW AI · 速攻 / FLASH
Claude Opus 4.8 深夜发布
5-28 美国时间 · 距 4.7 仅 41 天 · bug 砍 4 倍 · 把"诚实"写进 release note
昨天凌晨,Anthropic 端出 Opus 4.8。距上一代 4.7 整 41 天。
它的 release note 第一句不是 SOTA、不是新 benchmark,而是:"sharper judgement, more honesty about its progress"——更敏锐的判断力、对自己进展更诚实。
一个领先模型不秀肌肉、来宣布"我更诚实",这件事本身比任何 benchmark 都耐人寻味。具体怎么个诚实法、benchmark 涨多少、谁会被影响——下面拆。
速览 / At a Glance
📊 BENCHMARK
7 个内部 benchmark 赢 6 个,唯一输 Terminal-Bench 2.1 给 GPT-5.5
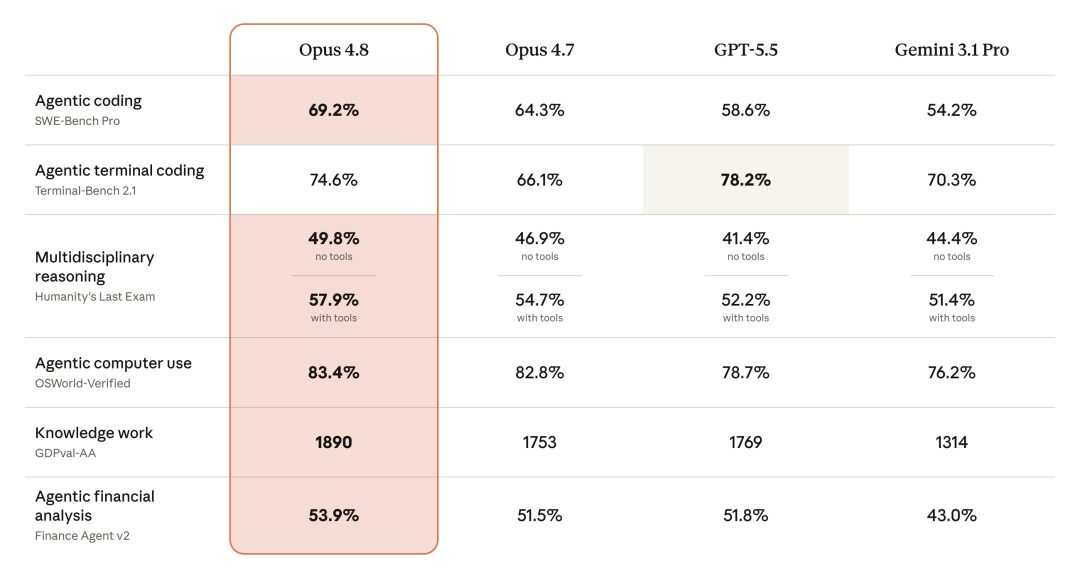
关键数字:agentic 编码 64.3% → 69.2%、多学科推理 54.7% → 57.9%、电脑使用 82.8% → 83.4%、知识工作 1753 → 1890。Legal Agent Benchmark 上首次有模型把全通过率推过 10%。
🐛 CODING
让自己写的 bug "悄悄溜过去" 的概率,约为 4.7 的 1/4

不是说写得对的概率涨 4 倍,而是 写错时主动 flag 出来 的概率高 4 倍。Anthropic 用了"around four times less likely to allow flaws in its code to pass unremarked"这句官方原话。
🌀 DYNAMIC WORKFLOWS
Claude Code 新 feature:单次会话里启动数百个并发子 agent
Anthropic 自己的 use case 是 跨数十万行的 codebase 重构。当前 research preview,Enterprise / Team / Max plan 可用。
⚙️ EFFORT CONTROL
用户在 claude.ai 直接选"想多少"——high / xhigh / max 三档
默认 high(与 4.7 看齐),低档调下来=回答更快 + rate limit 消耗更慢。Cowork 也支持。OpenAI o-series 内部已有 reasoning_effort,但 Anthropic 第一次把它暴露给普通消费者。
💰 PRICING
普通价没动,但 fast mode 砍到 1/3 + 速度提到 2.5×
Opus 4.8 标准价:5 美元/百万 input token + 25 美元/百万 output;fast mode 10/50(比上一代 fast mode 便宜 3 倍)。GitHub Copilot 5-28 同步上线。
🚫 ONLY OPUS
这次只有 Opus,没 Sonnet 4.8 / Haiku 4.8
Anthropic 的小步快跑策略——先把旗舰拉满、Sonnet/Haiku 后续可能 dedicated 节奏。Sonnet 4.6 + Haiku 4.5 当前仍是各自档位的主力。
核心思考 / Why This Matters
① "诚实" 这件事,第一次正式变 release feature
过去三年大模型迭代的主旋律是"更强"——更多参数、更长 context、更高 benchmark 分。"诚实"一直是 RLHF / Constitutional AI 的隐藏底色,从来不上 release note 头条。
Anthropic 这次把它推到 C 位,是个信号:当模型能力强到足以闯祸时,"不闯祸"本身就是一项可以 ship 的能力。换个说法——模型卡这个层次的应用层,再卷 SOTA 收益已经低于卷可靠性。
② "4 倍少 bug 漏报" 是开发者放手的临界点
关键不是写对率涨,而是写错时模型自己说"我可能错了"的频率涨。开发者用 agent 写代码最大的负担——不是 agent 写错,是不知道它什么时候写错。
这一档提升直接降低 review 工作量。用 agent 写代码的工程师都有"每 PR 都得自审"的习惯——如果 self-flag 真能稳定提到这个水平,next-gen IDE 的 review UI 可能会从"diff + 通过"演化成"diff + agent 自己列的不确定点 + 通过",整个 code review SaaS 类目都得重新想自己卖什么。
③ "数百子 agent" 把 multi-agent 从框架层拉下来到 model 层
半年前,"让 LLM 自己 spawn subagent 跑大任务" 还是社区第三方框架(LangGraph / Autogen / CrewAI 等)的事情。现在 Anthropic 把它做成原生 product feature,名字叫 Dynamic Workflows。
这是个分水岭:agent 编排正在从框架层下沉到模型/API 层。换句话说——把 "怎么并行/怎么 plan/怎么 merge 结果" 这套抽象封装起来直接卖钱。多 agent 框架公司接下来 12 个月得想清楚自己还卖什么。
④ 把"想多想少"变成消费者可见 UX
thinking budget 一直是 reasoning model 的隐藏旋钮——OpenAI o1 / o3 series 有内部档,但默认对 chat 用户不暴露。Anthropic 这次把档位直接做成 claude.ai 上能选的 toggle。
表面是 UX 改动,底层是定价权下放——以前是 "你付一个固定价钱,模型决定动多少脑子";现在是 "你想付多少钱、等多久,自己挑"。再往后推一步,整个 chatbot 行业的产品形态会向 "Effort × 任务难度 = 用户主动定价" 演化。
⑤ 输给 GPT-5.5 那一个 benchmark,反而是好消息
Anthropic 主动写"我们 7 个赢 6 个,那一个输了"——这个 framing 过去几代基本看不到(早期惯例是只挑赢的 benchmark 上图)。
这是实验室成熟度的标志——承认 OpenAI 在某些 use case 上更强,但把自己想要服务的 use case 拉满(Legal Agent 全通过率破 10%、agentic 多步任务自我检查率涨 4 倍)。两家 lab 开始分流——OpenAI 拼 raw capability 上限,Anthropic 拼可靠性下限。
→ 如果你是
开发者 | 拿一个真实仓库,让 Claude Code 跑一次 Dynamic Workflows。看看子 agent 拆任务的颗粒度——是值得自己写脚本还是直接交给它。
Agent 框架作者 | 研究 Dynamic Workflows 的 API 形状。Anthropic 同步开放了 messages array 内嵌 system entries 的能力——multi-agent 编排可能开始下沉到 prompt 层,graph 层框架要考虑差异化定位。
PM / 产品 | 把 effort 档位这种 UX 加进 product roadmap。用户开始期待"我能调这个模型出多少力",类似当年 Spotify 让用户调音质。
投资人 | multi-agent 框架公司、code review SaaS 是两个新的"被 model 吃掉一截能力"的赛道——下一轮估值时要扣减。
这种发布解读每周都有?
AI Insight 每周拆 1 个这种发布、1 个赛道趋势研报:
· 深度研报(涵盖 benchmark 自测 + 商业影响推演)
· 飞书 + 微信群 双通道每日资讯(3000+ 篇)
· 历史研报含 Cursor SDK / Claude for Legal / Codex Mobile / Sandbox 等
点击下方「阅读原文」加入 PRO →
读到这里 🙏
觉得有收获就顺手 点赞、在看、转发 三连
想第一时间看推送的,给公众号加个 星标 ⭐
下篇见 👋
© 2026 机智流 · AI Insight 出品 · 图片来自 Anthropic 官方公告 · 内容由 AI 团队采集生成可能有误,欢迎指正