点击下方卡片,关注“具身智能之心”公众号
机器人抓取物件频频打滑落空、自动驾驶仿真难以复刻突发险情、AI生成画面物体浮空穿模、多模态大模型 “看得懂世界却没法预判未来”……长久以来,物理具身智能(Physical AI)始终深陷落地困局。想要打造能在真实物理世界感知、推理、行动的通用智能体,行业被迫拆分视觉理解、图像视频生成、环境仿真、机器人动作决策四类独立模型,不同架构、数据、表征体系各自为战,开发链路冗长、训练成本居高不下,真实场景试错又伴随高昂硬件损耗与安全隐患,海量罕见工况更是永远难以实地采集。一边是仿真和现实的巨大鸿沟,一边是各类AI模型烟囱式割裂,全球具身产业卡在 “仿真不像现实、智能难以落地” 的两难关口。
近日,英伟达正式开源Cosmos3全模态世界模型,彻底打破行业延续多年的技术范式。作为全球首款统一文本、图像、视频、音频、动作五大模态理解与生成的通用物理世界基座,它跳出分模块造模型的传统思路,依靠独创 MoT双塔式混合Transformer 架构,用单一套网络同时实现多模态推理、画面生成、音视频同步、动力学仿真、机器人动作预测全能力。从通用AIGC创作,到工业机械臂、人形机器人、自动驾驶、智能仓储、数字人五大落地场景,一套开源底座便可完成从仿真数据生成到智能体闭环训练全流程。

依托全套开放权重、五大自研物理仿真数据集与标准化评测基准,Cosmos3横扫图文、视频、音画同步、机器人策略全赛道开源榜单,多项性能对标闭源头部模型。这份来自英伟达的重磅开源成果,不仅补齐了物理AI缺失的通用世界建模底座,大幅降低全球具身企业、科研团队的研发门槛,更标志着具身智能正式迈入 “单基座大一统” 的全新发展阶段,或将加速通用物理智能从实验室走向规模化产业落地。
★论文链接:https://arxiv.org/pdf/2606.02800
项目链接:research.nvidia.com/labs/cosmos-lab/cosmos3

Physical AI的行业历史痛点
传统物理AI研发的碎片化瓶颈
传统具身智能落地长期被感知、推理、仿真、动作决策四大模块割裂锁死,也是Cosmos3立项的核心动因。想要完成餐后桌面清洁任务,传统方案必须串联多套独立模型:
VLM视觉语言模型:识别餐具、桌面环境,拆解任务指令生成执行方案;
VLA视觉动作模型:基于环境信息输出机械臂动作序列;
世界前向动力学模型:仿真动作执行后的环境变化,预判碰撞、掉落风险;
四类模型架构、表征空间完全隔离,无共享特征池,模型间需要额外胶水代码做特征对齐、格式转换,算力冗余、调试成本极高、跨任务泛化极差(Figure1 直观对比:传统四类分立模型 VSCosmos3单模型覆盖 VLM/图像生成/音视频生成/前向/逆向动力学/机器人策略全品类)。

从全行业通用技术范式看,过往PhysicalAI形成四类烟囱式研发体系:
上述四类模型训练数据、网络参数、表征空间完全不互通,同一物体的空间位置、物理属性、交互逻辑需要在多模型中重复学习,造成海量数据与算力浪费,也是机器人、自动驾驶难以从仿真迁移到真实物理世界的核心障碍。
真实世界训练成本与安全难题
Physical AI(机器人、自动驾驶)直接在真实物理世界采集训练数据存在三大致命短板:
成本昂贵:工业机械臂、自动驾驶整车硬件采购、场地测试耗资千万级,海量极端工况(暴雨侧滑、机器人抓取打滑)无法规模化实地采集;
安全风险:自动驾驶路试碰撞、人形机器人摔倒、工业设备误操作极易引发财产与人身安全事故;
场景稀缺:极端小概率事件(突发障碍物、罕见物体交互)现实中样本极少,天然导致模型长尾失效。
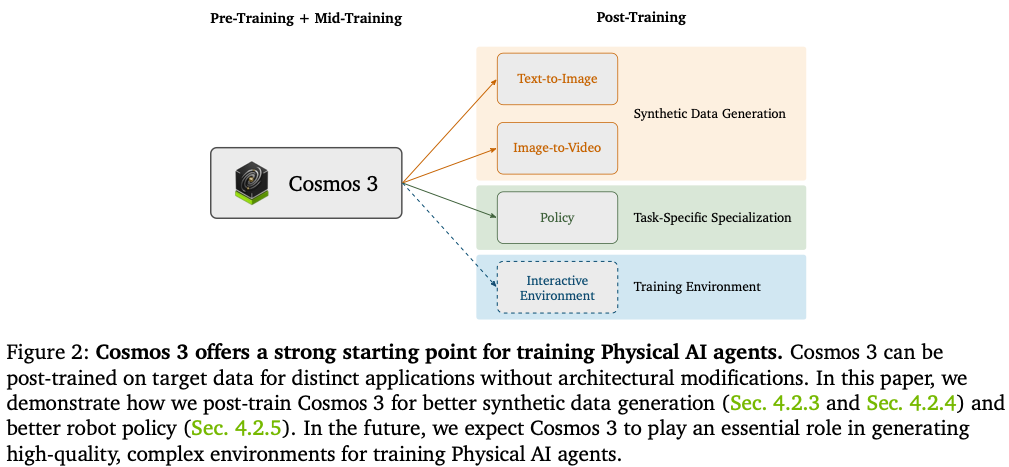
行业主流解决方案是数字仿真训练:在虚拟世界生成海量物理场景供具身智能智能体训练,但此前仿真引擎与AI模型相互独立,仿真产出的图片、动作数据格式无法直接适配各类AI训练,仿真-模型链路割裂,进一步推高落地成本。Cosmos3核心定位正是通用世界大模型,打通 “仿真数据生成-智能体训练-闭环环境仿真” 全链路(Figure2:Cosmos3预训练→中段训练→专项后训练三级落地链路),用AI生成高保真物理仿真数据替代昂贵实地采集,从源头解决 PhysicalAI数据荒痛点NVIDIA。
多模态融合的历史技术缺口
过往大模型路线分化严重:
LLM/VLM路线:主打文本+静态图像理解,几乎不支持时序视频、音频、可执行动作生成; AIGC视频路线:聚焦画面生成,缺少物理常识与空间推理,生成内容违背重力、刚体碰撞等基础物理规则; 机器人 VLA路线:专注图像→动作映射,无法生成完整环境视频,不能做前置环境预判。
没有一款模型可以同时输入文本/图像/视频/音频/动作、又能跨五类模态做理解与双向生成,这就是Omnimodal全模态世界模型诞生的行业刚需,英伟达Cosmos3瞄准该空白,依托MoT混合Transformer架构实现五类模态统一表征。
前代Cosmos系列产品的迭代铺垫
英伟达Cosmos产品线历经三代演进:Cosmos Predict(视频生成)、Cosmos Reason(VLM理解)、Cosmos Transfer(可控生成)三款分立模型,Cosmos3基于前序产品技术沉淀,合并三条技术线,摒弃多模型串联架构,把理解与生成塞进同一套Transformer主干,是Cosmos全栈技术集大成之作。
Cosmos3核心架构创新:MoT双塔式混合Transformer全模态底座
Cosmos3最核心突破为MoT (Mixture-of-Transformers) 双塔式混合Transformer架构,整体分为多模态专属编码器层→Token 规整与多生成模式模块→MoT 双主干 Transformer→多模态位置编码→三大尺寸模型变体五层结构,单模型同时承载自回归Reasoner(推理塔)与扩散式Generator(生成塔)两大计算通路,是实现 “一模型多用” 的底层基石。
五大模态独立编码器
Cosmos3对语言、图像、视频、音频、动作五大模态配置差异化编码器,所有编码输出统一映射至共享隐空间,实现跨模态特征互通:
图像&视频双编码器
理解分支:ViT编码器(16×16 Patch),搭配DeepStack特征聚合方案,用于Reasoner塔做图像/视频视觉理解; 生成分支:复用Wan2.2-TI2V的视频VAE,空间压缩32×32、时序压缩4倍,VAE训练全程冻结,仅做特征压缩,适配Generator扩散生成。
音频编码器:采用48kHz采样音频VAE,单秒输出25个音频Token,编码后线性映射至模型隐维度,仅服务音视频同步生成。

动作编码器(全行业关键创新,Figure3):首创统一动作表征范式,把机器人、自动驾驶、相机、人手四类完全不同的设备控制信号,统一数学编码,解决多具身设备动作空间异构难题:
,
动作基础单元:Ego本体位姿(9D:3 平移+6D旋转)+执行器位姿(9D)+抓取状态(1D/多手指维度); 分领域定制:自动驾驶仅保留Ego位姿、单臂机器人含Ego+执行器,人手增加多手指抓取(最高57D); 领域专属输入/输出投影矩阵:不同设备(Franka Panda、UR 机械臂、无人车)配置独立权重Win/Wout,统一映射进共享Token空间,这也是Cosmos3能跨机器人、自动驾驶、手持设备做动作生成的关键。
过往 VLA模型大多针对单一机器人定制动作头,换硬件就要重训输出层,Cosmos通过领域自适应投影实现一套主干兼容全品类具身设备。
Token双序列排布与全生成模式

Cosmos把所有输入Token拆分为AR 自回归子序列(Reasoner)+DM 扩散子序列(Generator)两大区块,排布规则固定:AR在前、DM在后;DM内干净条件Token在前、带噪生成Token在后,统一 Vision→Audio→Action 排序,靠一套Token格式实现十几种生成任务切换:
Reasoner塔自回归(因果注意力)、Generator塔双向全注意力:AR序列内部只用因果自注意力(和LLM一致,只能看前文),DM扩散序列全双向注意力,可跨序列读取AR全部上下文,实现 “先看懂再生成” 的逻辑闭环,从架构根源杜绝生成内容违背前文物理逻辑。
MoT双塔式Transformer主干
MoT架构是Cosmos3核心专利设计,单个Transformer层拆独立Reasoner、Generator双通路,共享跨通路联合注意力,各自拥有LN、FFN、Attention权重:

Reasoner塔(理解引擎):输入AR自回归Token,因果注意力,负责图文/视频/音频理解、时空物理推理,输出全局场景表征,是整个模型的 “大脑”;
Generator塔(生成引擎):输入DM扩散带噪Token,全向注意力,复用Reasoner的全局表征做条件生成,基于流匹配扩散方案迭代去噪生成图像、视频、音频、动作;
跨通路联合注意力:Generator的Q可以同时读取Reasoner+Generator的K/V,但Reasoner永远看不到Generator特征,保证推理结果不会被生成噪声污染。
$O_{\mathrm{AR}}=\mathrm{Attn}{\mathrm{causal}}(Q{\mathrm{AR}},K_{\mathrm{AR}},V_{\mathrm{AR}}) $
优势:同一套主干,微调/切换任务不用改网络结构,只需要在后训练阶段微调输出投影,实现T2I/I2V/机器人策略等专项模型,这是Cosmos能从通用基座快速衍生出Cosmos3-Super-T2I、Nano-DROID机器人专用模型的底层原因。
3D MRoPE绝对时序位置编码
针对视频、音频、动作采样帧率不统一痛点(16/24/30FPS、音频 25Token/s、动作采样率各异),Cosmos在 3D MRoPE基础上增加绝对时序调制:

图像/视频:t(时序)、h/w(空间三维位置);
音频/动作:仅t时序,h=w=0;
基准TPS=6(24FPS/4 倍 VAE 压缩),不同帧率按缩放时序步长,把不同采样速率的模态对齐到同一真实物理时间轴,解决音画不同步、动作和画面时序错位行业通病,也是Cosmos音视频同步生成效果领先的关键技术。
三大尺寸模型参数
Cosmos3分Edge(待发布)、Nano、Super三个版本,Nano (16B 总,基座 8B Qwen3-VL)、Super (64B 总,基座 32B Qwen3-VL) 全权重开源(Huggingface 可下载):
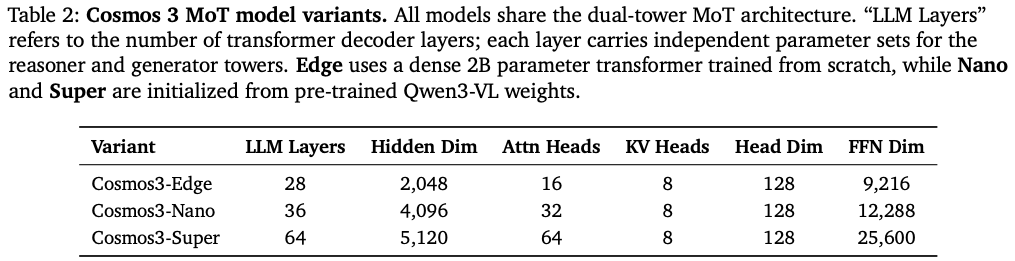
Nano与Super基于Qwen3-VL预训练权重初始化,Edge自研2B基座,三个版本架构完全统一,仅参数量缩放,小模型可以无缝复用大模型训练配方,极大降低落地适配成本。
全链路数据体系:Reasoner+Generator双轨分层数据
Cosmos3分Reasoner(理解数据)、Generator(生成数据)两套完全独立的数据基建,合计数十亿级多模态样本,同时开源五大 SDG物理合成数据集(Huggingface 公开),是模型物理常识优异的核心保障。
Reasoner训练数据
Reasoner分预训练(2200 万)+监督微调 SFT(217 万)两级数据:
预训练集:1881万图文、101万视频文本、217万纯文本,以OCR、2D空间标注、通用VQA为主,构建基础多模态理解能力,数据经过语义去重(Kmeans+余弦相似度0.95过滤)+Gemma4大模型AI质检(三项指标全≥2 分留存)双重筛选,剔除错误标注;
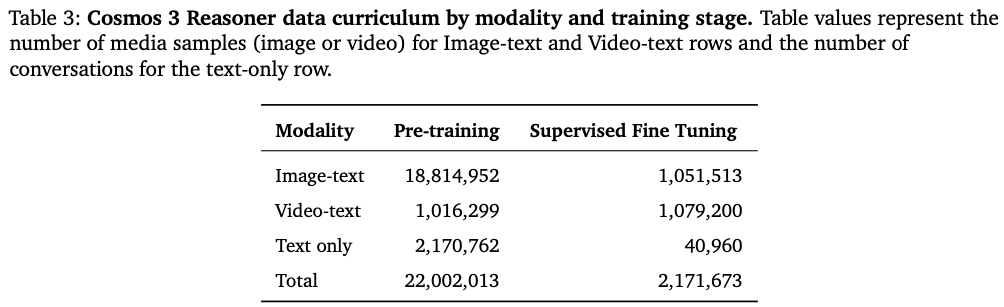
SFT 微调集:105万图文+108万视频文本,50% 样本聚焦机器人/自动驾驶/智慧基建三大 PhysicalAI领域,细分17项机器人基准、9项智能设施、3项自动驾驶专项数据集(Figure7饼图:预训练 vs 微调数据结构对比),包含 DROID、BEHAVIOR、手术机器人、仓储、交通异常等细分标注,让Reasoner从通用图文理解进阶到物理空间、动作因果推理。

数据筛选亮点:用Gemma4做标注裁判,从忠实度、完备性、正确性三个维度打分,SFT阶段严格筛选全维度满分(≥5)样本,从源头降低模型物理常识幻觉。
Generator生成数据
Generator采用预训练→中段训练→专项后训练三阶渐进式数据引入策略,循序渐进加图像/视频/音频/动作四类数据(Figure8各专项后训练数据量汇总):
预训练(图像7.67亿、视频3.48亿):海量全网图文视频,构建通用视觉生成先验,只引入图像+音频,暂不加入动作数据;
Mid中段训练(核心扩容):新增三大类数据
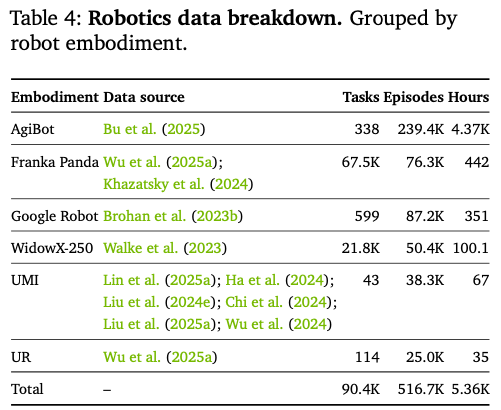
高精实拍图像/视频(通用+机器人/驾驶细分); 开源五大SDG合成数据集: SDG-PhyxSim:刚体、流体、光学物理仿真场景; SDG-RobotSim:多品类机器人操作仿真; SDG-DriveSim:全场景自动驾驶仿真; SDG-SynHuman:真人肢体、人体交互数字人数据; SDG-Warehouse:叉车仓储工业场景; 可控迁移数据(边缘/深度/分割图→RGB),支撑Control型视频生成; 840万动作样本(61.3K小时,Figure9):67.4%人本位自握持、16.3%自动驾驶、8.7%多机器人、7.5%相机运动,覆盖Franka Panda、AgiBot、WidowX全品类机械臂数据;

专项Post后训练:针对T2I、I2V、DROID机器人三个细分方向做小样本精调,也是三个SOTA专项开源模型的训练来源。
结构化JSON标注体系
Cosmos摒弃自由文本caption,全训练数据采用标准化JSON结构化标注(图像/视频两套Schema),拆解主体、光影、构图、动作时序、音频、相机运动等数十个字段(A2/A3),训练时统一输入格式是模型精准跟随提示、物理合规的关键,同时开源Prompt上采样模板,开发者可直接复用Reasoner做短提示→结构化长提示扩充,大幅提升生成质量。
开源数据集汇总(文档开篇数据集列表)
全量开源5大SDG合成数据集+Cosmos-HUE人类评测基准:
SDG-PhyxSim(物理交互仿真)、DG-RobotSim(机器人仿真)、SDG-DriveSim(自动驾驶)、SDG-SynHuman(数字人)、SDG-Warehouse(仓储作业)
Cosmos-HUE:物理AI人类评测数据集,用于视频物理合规打分,全部托管于Huggingface数据集仓库,采用OpenMDW-1.1开源协议,工业开发者免费商用。
分阶段完整训练方案:Reasoner先行+Generator继承权重
Cosmos训练顺序固定:先训Reasoner推理塔→Reasoner权重初始化Generator主干→Generator分三阶预/中/后训练,利用 VLM成熟知识迁移生成模型,是区别于所有从头训生成模型的关键训练策略。
Reasoner两阶段训练
预训练:AdamW 优化器,LLM 峰值5e-5、ViT 5e-6,余弦衰减,2epoch全样本遍历,序列上限16k Token,采用平方根损失加权平衡长短样本;
SFT微调:采样权重优化,1:4混入预训练通用数据防止过拟合,迭代8200步,学习率下调至1e-5,侧重机器人、自动驾驶领域专项知识注入。
Generator三阶训练
Generator全部基于整流流匹配损失做扩散训练,区别传统DDPM,用速度预测优化去噪,分三阶段:
Pre预训练

多分辨率并行训练(256p/480p/720p,Table5分辨率规格),固定单批次74000Token打包(Figure10打包策略); 采样配比:视频80%、图片20%,视频内T2V56%/I2V16%/V2V8%; Cosmos3-Nano:1024张GB200、31.05T Token;Super:2048GB200、17.86T Token。
Mid中段训练(模型通用能力成型)
新增动作、迁移数据(Table6数据占比:动作 25%、控制迁移 25%),损失对Action加权 ×10补偿数值差异,至此基座Nano/Super定型,后续所有专项模型从该checkpoint后训练得到。

三大专项后训练(衍生开源子模型)
Cosmos3-Super-Text2Image:两阶段SFT(20k粗训+2k精调,45%实景+40%合成+15%带字图),登顶 Artificial Analysis开源T2I榜单(Table11,UniGenBench91.36 全榜第一);

Cosmos3-Super-Image2Video:20k合成+千级精选真人视频,480p/8秒189帧规格,拿下开源I2V全球第一(Table12 PAIBench-G);

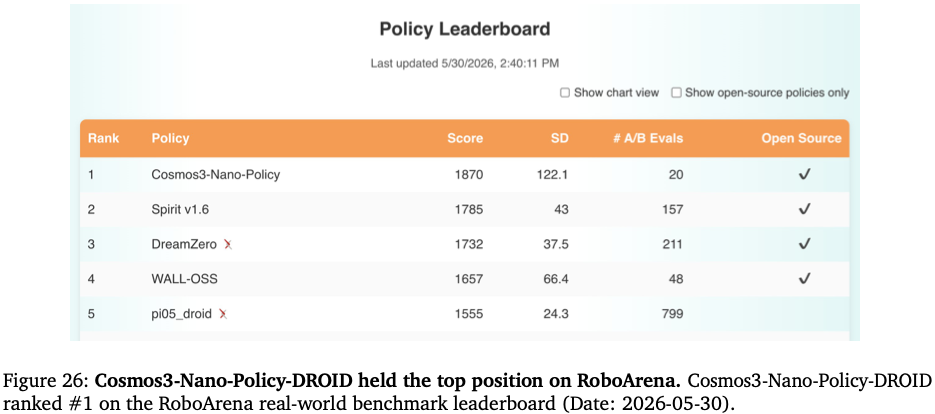
Cosmos3-Nano-Policy-DROID:基于DROID机器人数据集后训练,输入三目拼接图像+本体关节,单次预测 32 步动作,RoboLab、RoboArena双榜单开源第一(Table19、Figure26 榜单)。


全栈软硬件基建:数据/训练/推理/评测四大底座
Cosmos整套研发基于SILA数据平台+定制训练框架+vLLM/TensorRT-LLM推理栈,英伟达全自研工程体系,支撑数十亿样本处理与超大模型分布式训练。
SILA 数据基建
自研SILA分布式数据处理平台,基于Lance+LanceDB构建统一数据湖,替代传统Postgres分库,实现分布式去重、AI筛选、可视化排查,相较前代Cosmos架构吞吐提升10倍,十亿级样本聚类、向量检索落地。
训练基建(HSDP+Ulysses上下文并行)
分布式:HSDP混合分片数据并行+Ulysses 上下文并行,拆分超长序列,适配74k超大Token;
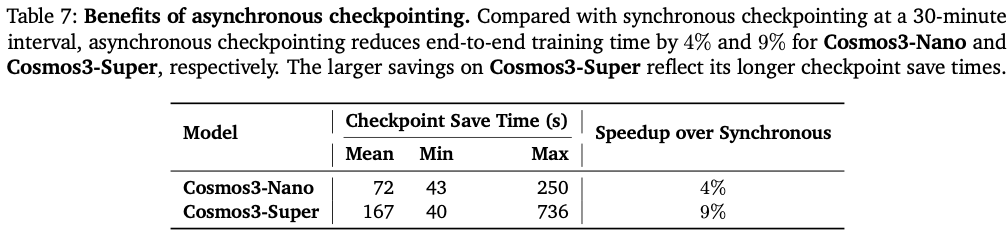
优化:选择性激活重计算、TorchCompile编译Transformer、Chunk分片 VAE 解码、异步断点保存(Table7 异步存盘提速数据);
GB20实测吞吐:Nano单GPU每小时4.56M图像+16.23M视频Token(Table8)。

推理部署
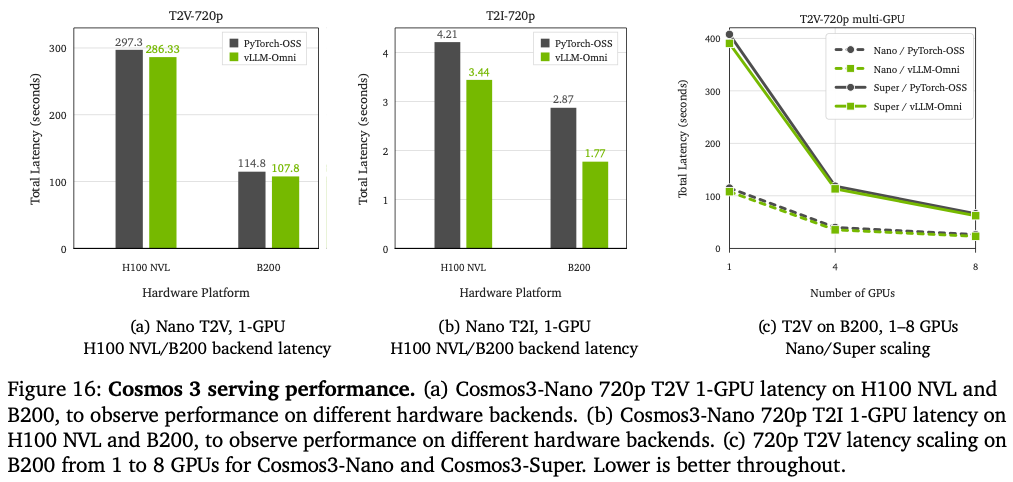
Reasoner:TensorRT-LLM、vLLM双优化; Generator:vLLM-Omni(扩散专用推理引擎),支持CFG并行、上下文拆分、FP8量化、VAE分块加速,Nano可单张RTX Pro6000跑机器人实时推理。
评测基础设施
自研统一评测平台,自动跑VLMEvalKit、PAIBench、RoboLab全基准,自动归档生成样本与打分结果,实现模型迭代自动化回归。
全维度实测性能:跨模态SOTA 量化结果
依托通用理解、图像、视频、音频、动作五大类基准,Cosmos3在开源模型全维度霸榜,部分指标对标闭源 Veo、Gemini。
Reasoner多模态理解
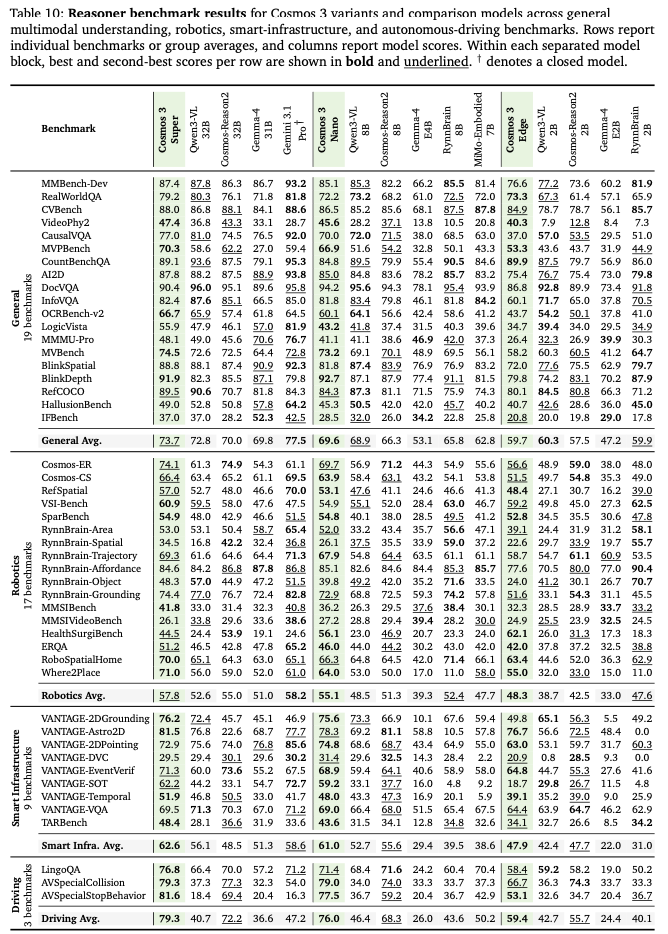
通用19项基准平均:Super73.7、Nano69.6,略低于闭源Gemini3.1Pro (77.5),全面超越Qwen3-VL、Gemma4全系列开源模型; 机器人17项平均:Super57.8、Nano55.1,高于Qwen、Gemma,仅小幅落后Gemini; 自动驾驶平均 Super62.6、Nano61.0,大幅甩开所有开源VLM(Qwen3-VL仅40.7),在碰撞、停车行为专项任务断层领先。
核心优势:物理类基准(VideoPhy 物理视频 QA)Super47.4,远高于Qwen3-VL36.8,证明物理常识建模显著领先竞品。
图像生成

Cosmos3-Super-T2I在UniGenBench总分91.36(含570个物理AI专项样本),开源第一、全榜第四(含闭源);CVTG中英文字生成指标领先FLUX、Qwen-Image,在场景文字、工业标牌生成优势明显,是工业图纸、仓储标识生成优选模型。Artificial Analysis T2I榜单开源第一名(Figure18)。

视频生成
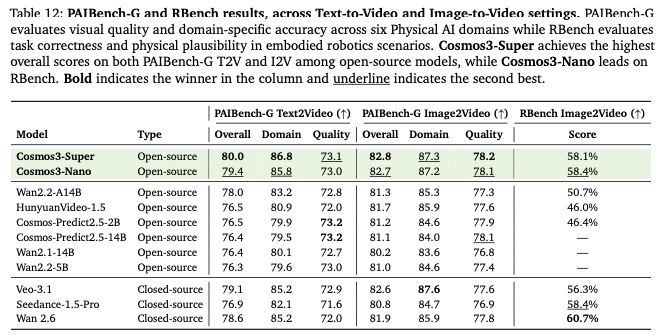
PAIBench-G(物理AI视频基准):Super T2V80.0、I2V82.8,开源第一,超越Wan2.2、Hunyuan、闭源 Veo3.1;
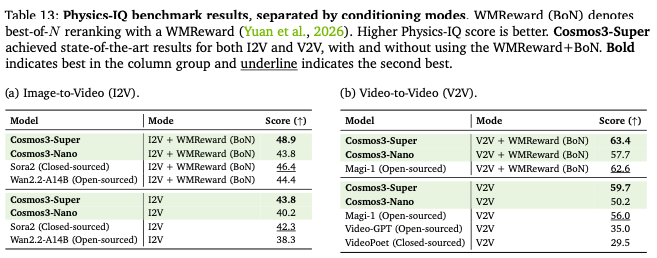
Physics-IQ(物理规则生成基准):I2V 带奖励 48.9、V2V63.4,超过 Sora2 闭源模型;
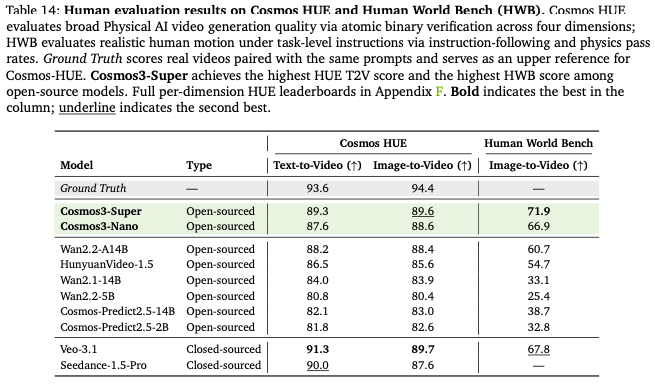
Cosmos-HUE人类评测(Table14):T2V89.3、I2V89.6(开源第一,仅低于 Veo 闭源 91.3);
HWB人体动作基准 71.9,全模型第一(含闭源),自然人手交互、人体运动生成行业天花板。
音频&视频联动
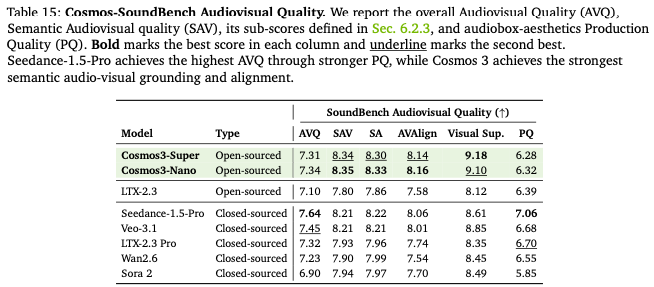
Nano/SAV(音画对齐得分)8.35全榜第一,音画事件精准同步(Figure20 锤击音频和画面瞬态对齐),虽音质略逊闭源Seedance,但物理事件发声精准度行业最优,适配工业设备、机器人碰撞音效生成。

动作/机器人策略
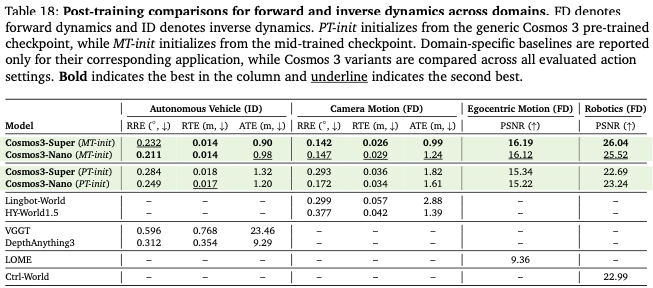
前向/逆向动力学:自动驾驶、相机、人形、机器人四类任务 PSNR/位姿误差全面优于Ctrl-World、VGGT等专用模型;
RoboLab120任务:Cosmos3-Nano-Policy特定指令成功率39.7%,大幅领先 (28.1)、DreamZero (23.9);

RoboArena实机机器人榜单总分1870,断层第一;
新机器人LIBERO环境适配:MT初始化500迭代24.6%成功率,证明多领域动作共训带来极强跨具身迁移能力(Table20)。

开源生态与产业落地价值
开源范围与协议
全量开源清单:
源码:github.com/nvidia/cosmos、cosmos-framework;
权重:Cosmos3-Super/Nano/T2I/I2V/DROID五大模型(HF);
数据:5大SDG合成数据集+HUE评测集;全套训练/后训练/推理脚本;
协议:Linux基金会OpenMDW-1.1。
四大落地赛道
通用AIGC产业:文生图、长视频、音视频一体生成,提升画面物理合理性,解决穿模、浮空痛点;
机器人(工业机械/人形):Nano部署RTX Pro,DROID策略模型直接实机落地,快速微调各类机械臂,省去海量真机采集;
自动驾驶:生成雨雪、突发障碍物等极端仿真路况,补充真实稀有样本,用于感知/规控模型训练;
仓储&数字人:SDG-Warehouse做仓储仿真、SDG-SynHuman生成高保真数字人动作素材。
行业变革意义
Cosmos3彻底打破 “理解、生成、仿真、动作四类模型分头研发” 行业范式,一套基座覆盖全 PhysicalAI需求,中小企业无需同时采购 VLM、视频大模型、机器人策略三套 API,只用Cosmos3一套开源方案即可完成从数据生成到智能体训练全链路,大幅降低具身AI研发门槛,英伟达同步发起Cosmos联盟(Runway、Agile Robots 等企业共建生态)NVIDIA Newsroom。
一些不足与未来的演进
Cosmos3-Edge(4B 端侧模型)尚未开源,轻量化端落地缺少官方权重;
超长(>30s)高分辨率(4K)视频生成仍有细节瑕疵,音频纯音乐生成弱于专业音频模型;
极端非线性物理(流体爆炸、复杂软体形变)生成仍存在少量物理偏差;
多模态超长时序(分钟级)动作闭环仿真仍需进一步迭代。
后续演进
开放Edge 4B小模型,适配嵌入式机器人、车载端侧部署;
扩充海量极端物理仿真数据集,优化流体、软体生成;
完善全模态长时序闭环仿真,直接生成完整机器人训练环境;
持续扩充专项后训练权重(自动驾驶专用、人形机器人专用模型),丰富开源权重生态。
写在最后
Cosmos3凭借MoT双塔式全模态架构、统一动作表征、三阶分层数据训练、全链路工程优化四大创新,完成 PhysicalAI从分立模型走向单基座全模态统一的历史性突破,在图像、视频、音视频、机器人策略、动力学五大开源赛道全面登顶SOTA。全开源策略大幅降低全球具身智能研发门槛,重构机器人、自动驾驶、AIGC、工业仿真产业链研发范式。
短期看是开发者低成本落地物理AI的最优开源底座,长期将加速通用具身智能体落地进程,成为全球PhysicalAI基础设施级基础模型。











