点击下方卡片,关注【Xbotics具身智能实验室】公众号
更多具身干货,欢迎加入(戳我)
👉具身智能学习资料汇总:https://github.com/Xbotics-Embodied-AI-club/Xbotics-Embodied-Guide
👉具身智能求职/实习信息汇总:https://github.com/Xbotics-Embodied-AI-club/Xbotics-Embodied-AI-Job
你想要的这里都有~~
做机器人模仿学习时,我们常常会从一个很朴素的想法开始:给机器人当前看到的画面和状态,让它预测下一步该怎么动。
这个想法就是 Behavior Cloning(行为克隆,简称 BC)。它像是在教机器人“照着老师做”:老师在什么状态下做了什么动作,模型就学着在相似状态下给出相似动作。
但问题是,机器人真的上手执行时,环境会连续变化。如果它每一步都只盯着“下一步”,很容易出现两个麻烦:
一步偏了,后面越偏越远; 同一个场景里,明明有好几种正确做法,模型却学成了一个“不左不右”的平均动作。
ACT(Action Chunking with Transformers)就是为了解这两个问题而来。下面我们用一篇文章把 ACT 的算法逻辑和 LeRobot 代码实现串起来。
先记住一句话
ACT 的核心直觉
ACT 不是让机器人每次只猜下一步,而是让它一次生成一小段未来动作。
可以把它想成开车:普通 BC 像是每 0.1 秒问一次“现在方向盘该打多少”;ACT 更像是先规划接下来几秒“我先沿这条轨迹开过去”。
这样做的好处是:动作更连贯,模型不用每一步都重新做一次决策,也不容易因为某个小误差立刻滚雪球。
1|为什么“一步一步预测”会出问题?
问题一:一步错,后面更容易错
训练时,模型看到的是专家示教里的标准动作轨迹。可到了真实执行时,只要某一步动作有一点偏差,机器人下一刻看到的画面和姿态就可能不再像训练数据里的样子。
关键直觉
模型正在面对一个“老师没怎么教过”的场景。下一步更容易错,错完又进入更陌生的场景,误差就像滚雪球一样越滚越大。
问题二:同一个场景,可能有多种正确动作
同样是抓一个物体,专家可能从左边绕过去,也可能从右边绕过去。两种方式都对。
如果模型只能给出一个确定答案,它可能会学到“左边方案”和“右边方案”的平均值。听起来很折中,但对机器人动作来说,这个平均值往往不是任何一种有效动作:既不像左绕,也不像右绕,最后卡在中间。
关键直觉
正确答案不止一个,但普通回归模型容易把多个正确答案平均成一个错误答案。
2|ACT 的两个核心
遇到的问题 | ACT 的做法 | 更直观的理解 |
一步错后面步步错 | Action Chunking | 不只预测下一步,而是一次预测未来一段动作 |
同一场景多种正确做法 | Conditional VAE | 给动作加一个“风格旋钮”,让模型知道这段动作属于哪种模式 |
2.1 Action Chunking:一次给出一段动作清单
Action Chunking 的意思很直接:模型不是输出“下一步动作”,而是输出“未来 k 步动作”。用不那么数学的写法就是:
当前观测 → 接下来 n 步动作清单
在 LeRobot 默认配置里,这个“动作清单”的长度就是 100。模型先生成这 100 步,再由策略层一条一条拿出来执行。
这有点像做饭前先列好接下来几步:切菜、热锅、下油、翻炒。你不会每切一刀都重新思考整个菜谱,而是先有一个短期计划,再按计划推进。
2.2 Conditional VAE:给动作一个“风格旋钮”
如果同一个画面下有多种合理动作,ACT 希望模型不要把它们硬平均,而是能先选一种动作风格。
这里的“风格旋钮”就是隐变量 z。你可以把 z 理解成一个看不见的动作标签:从左边绕、从右边绕、更快、更慢、更贴近桌面等动作习惯,都可以被编码进去。
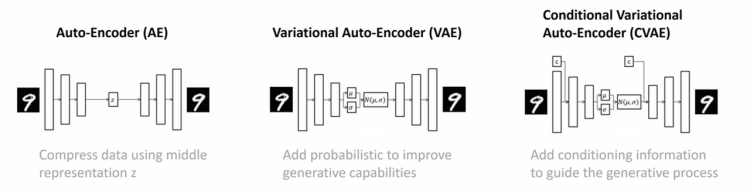
图1:从 AE 到 VAE 再到 CVAE 的演进。CVAE 可以理解成“在当前条件下生成合理结果”的模型。
3|不用硬啃公式,怎样理解 AE / VAE / CVAE?
AE:像压缩包
AE(Auto-Encoder)可以想成一个压缩包工具。它先把一段数据压缩成一个更小的表示 z,再从 z 尽量还原出原数据。问题是,普通 AE 的 z 没有很好整理过:每个样本可能被放到隐空间里很随意的位置。
VAE:像一张整理过的地图
VAE 在 AE 的基础上做了一件事:它不只学“怎么压缩”,还会约束 z 不要乱跑。更直观地说,VAE 希望隐空间像一张整理过的地图:相似的动作靠得近,不同动作有区别,但不会东一块西一块地散落。
既要还原得像,又要让隐空间别太乱。
也就是说,模型一边学习“动作要和专家示教接近”,一边学习“z 要待在一个比较规整、容易使用的区域”。
CVAE:在“当前场景”这个条件下生成动作
CVAE 多了一个条件。对 ACT 来说,这个条件就是当前机器人看到的画面和状态。
当前观测 + 动作风格 z → 一段合理动作
这样一来,模型就不是盲目生成动作,而是在“当前场景”这个前提下,选择某种动作风格,再生成一段动作。
4|ACT 整体架构:左边负责“学风格”,右边负责“出动作”

图2:ACT 整体结构。左侧 VAE Encoder 只在训练时使用;右侧 Transformer 主干负责根据图像、状态和 z 生成动作序列。
左边的 VAE Encoder 像一个“动作风格分析器”。训练时,它可以看到真实动作序列,所以能判断这段示教动作大概属于哪种风格。
右边的 Transformer 主干像一个“短时动作生成器”。它看当前图像、机器人状态,再结合 z,输出未来一段动作。
架构里的分工
左边主要用于训练;真正部署推理时,主要靠右边的 Transformer 来生成动作。
5|训练时,模型到底看到了什么?
训练 ACT 时,一个样本不再只是“当前画面 + 下一步动作”,而是:
当前观测 + 接下来一整段真实动作
也就是说,模型看到的是一个动作块。以下的训练样本图展示了这一点:输入包含 observation,标签是 ground-truth action sequence。

图3:训练样本由 observation 和 ground-truth action sequence 组成。ACT 从数据层开始就围绕 action chunk 组织监督。
在 LeRobot 的默认设定中,chunk_size = 100。数据集在取样时,会把当前时刻之后连续 100 个动作一起取出来,作为一个动作块。
如果 episode 快结束了,后面已经不够 100 步怎么办?LeRobot 会用 action_is_pad 标记无效位置,训练时这些位置不会真的参与损失计算。
为什么 padding mask 重要
如果不把无效位置屏蔽掉,模型就会被 episode 末尾的假数据误导。
6|训练流程:可以分成三步看
第一步:从真实动作中提取“动作风格”
训练时,VAE Encoder 能看到真实动作块。它的任务不是直接控制机器人,而是回答一个问题:这段专家动作像是哪一种风格?

图4:VAE Encoder 从 robot state 和真实 action sequence 推断 latent。读者可以把 latent 理解成动作风格的压缩表示。
对于刚入门的同学,只需要先抓住这句话:
VAE Encoder 不是输出一个死板标签,而是输出一个“可能的风格范围”。
也正因为它输出的是一个范围,训练时模型可以学习到更平滑、更可用的动作风格空间。
第二步:用图像、状态和 z 生成动作块
拿到 z 之后,Transformer 主干开始生成动作。它会先用 ResNet18 从相机图像中提取视觉特征,再把图像特征、机器人状态、z 放到一起,让 Transformer 进行信息融合。最后,Decoder 端生成未来 100 步动作。
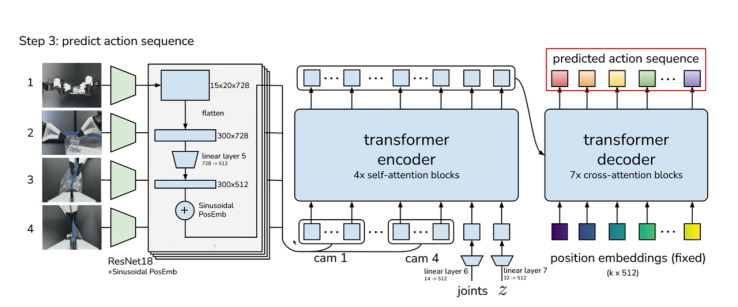
图5:Transformer 主干根据图像、机器人状态和 latent z 生成 predicted action sequence。
看图像 + 看机器人当前状态 + 参考动作风格 → 写出未来动作清单
第三步:训练目标
训练损失包含两部分:L1 重建损失和 KL 正则。我们不急着看公式,先大致理解:
总目标 ≈ 动作要像专家 + 风格空间要规整
“动作要像专家”:预测的每一步、每个动作维度都要尽量接近真实示教动作; “风格空间要规整”:z 不要散得太乱,否则推理时很难稳定使用。
简单用公式描述,可以理解为:
Loss = 动作误差 + 10 × 风格空间约束
这里的 10 来自 LeRobot 默认的 kl_weight = 10.0。它表示实现上比较重视把 z 约束到稳定区域,为后面推理时使用 z = 0 做准备。
7|推理时:为什么可以直接用 z = 0?
训练时,VAE Encoder 可以看真实动作;但推理时机器人还没做动作,当然没有“未来真实动作”可以看。ACT 的做法很直接:
推理时默认使用 z = 0
这个结论看起来有点突然,但其实和前面的“风格空间要规整”有关。训练时,KL 约束会不断把 z 拉向一个标准、集中的区域。z = 0 就像这个区域的中心点。推理时直接用中心点,通常会得到一个稳定、可复现的动作模式。
代价是:模型不会在推理时随机选择“左绕”或“右绕”。它更像是选择一个默认动作风格,把稳定性放在优先位置。
8|LeRobot 里的执行方式:先放进动作队列,再一步步吐出来
ACT 不是生成 100 步之后一下子把环境“跳过”100 步。更准确地说,LeRobot 的 select_action() 每次仍然只返回一步动作。区别在于:如果动作队列还没空,它不会重新跑模型,而是继续从上一次生成的动作块里取下一步。
模型生成 100 步动作 → 放入动作队列 → 每次执行取出 1 步

图6:Action Chunking 与 Temporal Ensemble。LeRobot 默认更接近 Action Queue:先预测一个动作块,再逐步消费。
这里也顺便区分两个容易混淆的参数:
参数 | 先用白话理解 | LeRobot 默认值 |
chunk_size | 模型一次预测多少步 | 100 |
n_action_steps | 每次实际拿多少步放入队列消费 | 100 |
默认情况下,两者都是 100,所以模型一次生成 100 步,并把这 100 步都放进队列里慢慢执行。队列耗尽后,再基于新的观测重新规划。
9|代码实现可以记这条主线
不用一上来就钻进每个类和每个张量形状。理解 LeRobot 里的 ACT,先记住这条链路就够了:
ACTConfig 决定 chunk 长度
↓
Dataset 取出未来 100 步动作作为监督
↓
Processor 做归一化和设备搬运
↓
ACTPolicy.forward() 训练模型,计算动作误差和 KL 约束
↓
ACTPolicy.select_action() 推理时管理动作队列
这条链路说明,ACT 不是简单把模型输出维度改大,而是从数据、模型、损失到推理队列都围绕 action chunk 重新组织。
10|最后,用三句话记住 ACT
普通 BC 的问题是每步都只看下一步,容易误差累积,也容易把多种正确动作平均坏。 ACT 的核心是 Action Chunking + CVAE:前者让模型一次生成一段动作,后者让模型用 z 表示不同动作风格。 LeRobot 的实现把这个思想落到了完整数据流里:dataset 先构造动作块监督,模型训练时学习生成动作块,推理时再把动作块放入队列逐步执行。
带走这句话
机器人动作可以不是“一步一步猜”,而是“像短时规划一样生成一段未来动作”。
❝经过数月的精心打磨,我们正式推出 “系统讲解前沿VLA” 的课程!这不是一份简单的代码解读,而是一套旨在帮你系统理解主流VLA算法实现,获得VLA训练、微调、后训练等前沿技术经验的完整知识体系。
更棒的是,作为诚意,我们将第五章【生成式机器人策略】完全免费开放!让你零成本体验国内最前沿的VLA教学。
❝为什么你需要这门课?
机器人不应该只是被写死程序的执行器,而应该能够理解视觉、理解语言,并最终把任务真正做出来。我们希望学员课程结束后,不只是“听过 VLA”,而是能真正建立一套技术判断力与工程实践能力。
我们想做点不一样的。
这门课程的目标人群是:有代码基础,但缺乏机器人基础和VLA算法知识的同学。
我们希望你学完后的结课效果是:
建立VLA的系统知识框架 具备VLA算法工程实践能力 掌握真机实操能力