点击蓝字 关注我们

欢迎各位专家学者在公众号平台报道最新研究工作,荐稿请联系小编Robert(微信ID:BrainX007);或将稿件发送至lgl010@vip.163.com。
英文标题:SYNAPSE: Neuro-Symbolic Visual Thought-to-Text Decoding via Topological Semantic Denoising
https://doi.org/10.48550/arXiv.2605.27790

成果简介
大语言模型的最新进展加速了开放词汇的脑电图到想象文本的解码研究。在该任务中,视觉感知期间记录的非侵入性神经活动被翻译成对所视刺激的连贯自然语言描述。然而,现有系统仍然极易受到生物噪声的影响——受损的神经投射会导致冻结的语言模型产生幻觉化或语义不稳定的生成结果。本研究提出了 SYNAPSE(用于精确语义提取的符号神经对齐),一个轻量级的神经-符号框架,通过推理时的符号正则化来稳定神经文本生成。通过使用常识图谱结构和潜在样本净化从脑电图导出的语义候选词,SYNAPSE 无需端到端的大语言模型微调即可提高语义稳定性。在流行的脑电图解码基准测试和多个冻结的大语言模型后端上的实验表明,与无约束的提示基线相比,该方法取得了一致的提升,在对象标签消融下具有鲁棒性,并且性能与资源密集度更高的微调系统相当,同时通过将原始脑电图处理完全限定在编码器堆栈内,保护了生物识别隐私。
主要贡献
提出了一种图净化机制,能够在去除断开的语义噪声的同时,保留高置信度的神经意图。
开发了一种潜在样本检索策略,通过注入句法模板,在噪声生物条件下稳定下游生成过程。
在多个脑电图语料库、冻结的大语言模型以及不同消融设置下,展示了鲁棒且具有竞争力的解码性能。
研究方法
SYNAPSE包含三个核心模块:拓扑图净化、关系时间提取和潜在样本检索。该方法分三步:首先从EEG信号中检索候选关键词,然后通过ConceptNet常识图谱进行拓扑净化(剔除孤立噪声词,保留高置信度词)并提取关系事实,同时检索历史样本作为句法模板,最后将净化后的词袋、关系事实和句法模板整合为提示词,输入冻结的大语言模型生成最终文本。整体框架如图1所示:
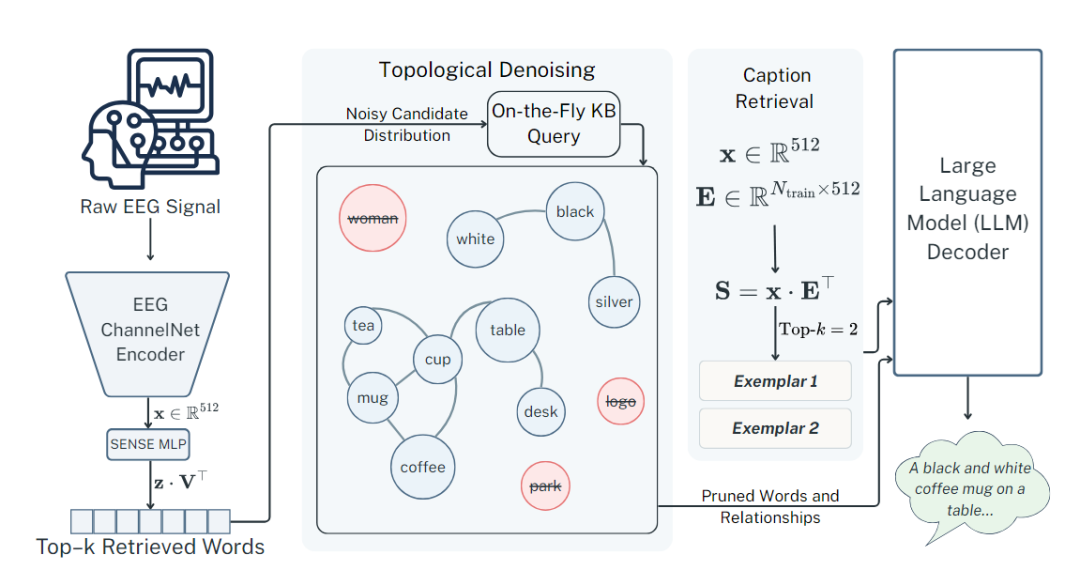
图1.SYNAPSE neuro-symbolic框架概述
1)拓扑图净化:该模块首先利用冻结的SENSE前端将原始EEG信号编码为512维的潜在向量,并通过与冻结词汇矩阵的余弦相似度检索出Top-15个候选关键词。随后,将这些候选词投射到ConceptNet常识图谱中,构建诱导子图并计算每个节点的归一化度中心性。最终采用混合剪枝规则:保留度中心性大于0的节点(即在图谱中有连接的词)或属于前5个高置信度优先保护集的词,从而去除断开的语义噪声,同时保留高置信度的神经意图。
2)关系事实提取:该模块在已构建的子图基础上,遍历所有边并筛选出视觉相关的关系类型(如位于、用于、有属性、能够、是…的一部分)。对于每条满足条件的有向边,通过规则映射函数将抽象图三元组(头节点、关系类型、尾节点)转换为自然语言字符串,形成语义断言。最后取前5条事实作为上下文缓存,为下游解码器提供显式的、结构验证过的常识约束,帮助LLM更准确地进行语义接地。
3)潜在样本检索:该模块将历史训练集中所有EEG样本的ChannelNet嵌入存储为冻结矩阵。在推理时,将当前未精炼的EEG特征向量作为查询,通过单次张量运算计算其与历史嵌入矩阵的并行余弦相似度,检索出Top-2个最近邻的训练样本。随后从本地存储中提取这两个样本对应的自然语言描述文本,构建句法样本集。这些句法模板为冻结的LLM提供了结构参考,使其能够在不进行微调的情况下生成符合语法规范的描述。
研究结果
表1. ImageNet-EEG基准上的消融跟踪与对比框架性能。所有指标的值越高表示性能越优。最佳结果以粗体显示(并列者以下划线表示),次优结果以斜体显示(并列者以下划线表示)。配置设置说明:A1:完整框架;A2:m=0m=0;A3:完整框架无对象标签;A4:完整框架无样本;A5:完整框架无事实;A6:最小基线(仅词袋 + 对象标签)。
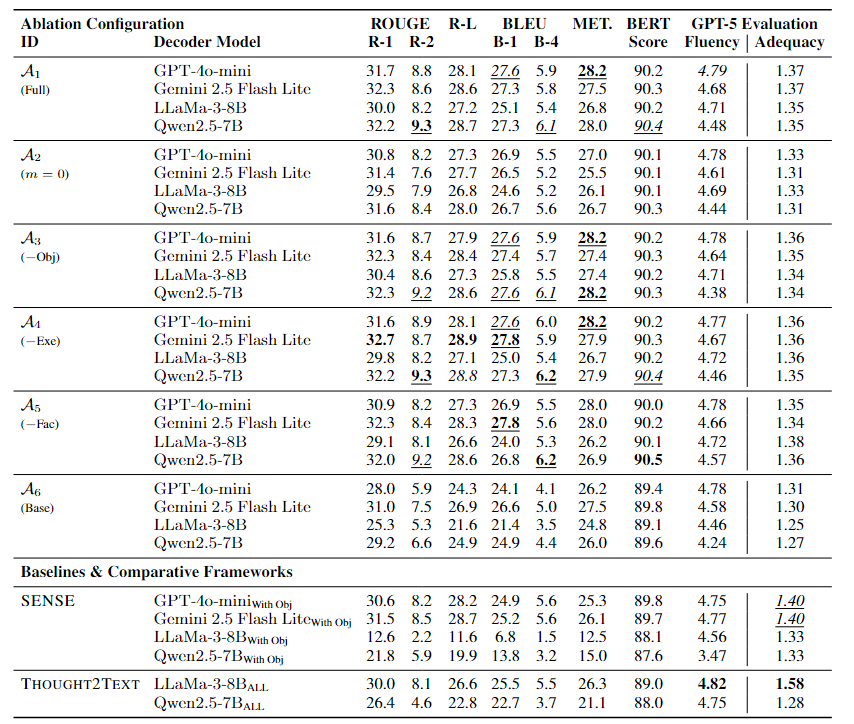
表2. 在不同优先保护约束下,ImageNet-EEG(N = 1,987)和THINGS EEG2(N = 1,654)数据集上的宏观拓扑剪枝与纠错敏感性统计对比。在所有评估中,单次试验中最少丢弃的标记数为0。

表3. THINGS EEG2跨样本评估套件上的消融跟踪性能。所有指标的值越高表示性能越优。配置设置明确映射如下:B1:完整框架(词袋 + 对象标签 + 事实 + 样本);B2:完整框架无样本。

表4. SYNAPSE 与 Thought2Text 基线生成描述的定性比较。“剪枝后词袋”列详细描述了经过拓扑图精炼阶段完成后所得到的剪枝词元集合。* 描述由 Qwen2.5-7B 生成。*


研究结论
本研究提出了 SYNAPSE,一个用于脑电图到文本解码的轻量级神经-符号框架。该框架通过推理时的符号正则化而非资源密集型的端到端微调,来稳定冻结的语言模型。通过结合拓扑图净化、关系接地和潜在样本检索,SYNAPSE 抑制了由噪声神经投射引起的语义漂移和注意力分散。在多个脑电图基准测试和异构大语言模型后端上的实验表明,与无约束的提示基线相比,该方法取得了一致的性能提升,在对象标签消融下表现出强鲁棒性,并且其性能与规模大得多的微调系统相当。更广泛地说,研究结果表明,脑到文本解码可能受益于一种检索增强的范式转变,即利用符号结构和外部语义记忆在不修改模型参数的情况下稳定生成过程。通过将语义校正从自回归权重中外部化,并将其转移到结构化的推理时检索中,SYNAPSE 为下一代神经-符号脑机接口提供了一个可扩展、保护隐私且计算高效的发展方向。
局限性
尽管 SYNAPSE 带来了鲁棒性的提升,但仍存在若干局限性。非侵入式脑电图记录具有固有的低空间分辨率,并且仍然高度易受生理噪声的影响,这对恢复语义意图的保真度构成了根本性限制。虽然拓扑图净化大幅减少了语义漂移和注意力分散,但该框架仍然假设图的连通性意味着上下文有效性;因此,语义上不正确但密集共激活的词簇有时可能会逃避剪枝,并将残留的幻觉传播到下游生成中。此外,符号正则化的有效性取决于外部常识图谱的覆盖范围和关系完整性,而该图谱可能会遗漏稀有或连接较弱的视觉概念。样本检索模块同样受到稠密潜在神经嵌入空间内静态最近邻匹配的限制,在大规模开放词汇设置下,语义上相近的概念可能会发生重叠。更广泛地说,SYNAPSE 继承了检索增强范式中常见的局限性:下游生成质量从根本上受到检索质量的制约,而在本文的设置中,检索是在有噪声的神经语义投影上进行的,而非干净的文本查询。最后,尽管原始脑电图处理和符号净化完全保持本地化以保护生物识别隐私,但所评估的多个解码器后端依赖于外部托管的大语言模型 API,这意味着完全的端到端隐私最终取决于使用完全本地化的语言模型和设备上的推理基础设施进行部署。
免责声明:原创仅代表原创编译,水平有限,仅供学术交流,如有侵权,请联系删除,文献解读如有疏漏之处,我们深表歉意。



公众号丨智能传感与脑机接口