点击下方卡片,关注“具身智能之心”公众号
作者丨Runhua Zhang 等
编辑丨具身智能之心
本文只做学术分享,如有侵权,联系删文
>>
更多干货,欢迎加入国内首个具身智能全栈学习社区:(戳我),这里包含所有你想要的。
近年来,扩散策略(Diffusion Policy, DP)凭借其强大的多模态行为建模能力,在机器人操纵和视觉导航领域掀起了研究热潮。然而,传统基于模仿学习(IL)训练的扩散策略往往会无差别地继承专家演示中的次优选择和冗余轨迹,迫使系统在推理时不得不采用高计算成本的"生成-过滤"(Generate-then-Filter)管线。
为了打破这一实时部署的计算瓶颈,来自浙江大学控制科学与工程学院与宇泛科技(Uni-Ubi Technology)的研究团队提出了一种全新的视觉导航框架——自模仿扩散策略(Self-Imitated Diffusion Policy, SIDP)。该方法通过"自生成、自筛选、自模仿"的闭环,将轨迹选择能力内化至网络权重中,彻底摒弃了传统的外部辅助评价网络,在嵌入式边缘设备上实现了高达 2.5 倍的推理加速!
目前,该工作已被机器人学权威期刊 IEEE Robotics and Automation Letters (RA-L) 接收。
论文链接: https://arxiv.org/abs/2601.22965 项目主页: https://rhzhang1.github.io/sidp.github.io/
01 传统模仿学习扩散策略的"阿喀琉斯之踵"
在复杂的未知室内环境中,依靠纯视觉观测(如 egocentric RGB-D)规划出一条兼顾安全(无碰撞)与效率(路径最短)的无碰撞轨迹,是自主导航的核心任务。扩散模型通过迭代去噪过程来拟合完整的时空轨迹,能够极其灵活地捕捉环境中的多模态路径分布(例如面对障碍物时,左绕或右绕皆可行)。
然而,现有的扩散导航方法(如 NavDP、NoMaD 等)在实际部署时,普遍面临着两个相互交织的物理瓶颈:
专家演示的次优性与高方差(Suboptimality & High Variance): 人类或算法生成的专家数据集往往混杂着冗余的路径和次优的调整动作。标准模仿学习一成不变地拟合这些数据,导致扩散模型生成的轨迹分布过于发散、intra-modal 收敛性差。 "生成-过滤"管线的高延迟成本: 为了确保机器人的绝对安全,前人方法通常需要在推理时利用扩散模型同时并行采样 条候选轨迹,再外挂一个规则或学习型的"辅助选择器/评价网络(Auxiliary Selector/Critic)"进行打分和过滤。这种"生了再筛"的机制极大地榨干了车载微型计算单元(如 Jetson Orin Nano)的算力,成为阻碍其实时反应的"罪魁祸首"。
如图 1 所示,如何让扩散策略在保持多模态探索能力的同时,"本能地"收敛到高质量轨迹上,实现真正的端到端轻量化推理?这是本项研究的核心出发点。

02 SIDP 核心方法解构:从分布匹配到自我进化
SIDP 框架的核心逻辑是** Internalizing Trajectory Selection(将轨迹选择内化)。它包含三个有机串联的相位:Phase 1 提案采样、Phase 2 拓扑过滤与重要性重缩放、Phase 3 策略权重更新**。

1. 基于相对熵(REPS)的分布匹配
研究团队将优化目标形式化为让当前策略 去匹配未知的最优轨迹分布 。通过最小化两者之间的 KL 散度 ,可以将其转化为在 概率空间下最大化策略对数似然的对偶问题:
由于直接从 采样并不可行,SIDP 将当前策略 作为提案分布(Proposal Distribution)在线生成 个候选样本,并借助重要性采样进行近似。为了防止 Boltzmann 分布带来的高方差和梯度爆炸,团队借鉴了相对熵策略搜索(REPS)的约束优化理论,在限定信息损失的信赖域内求解 Lagrangian 闭式解,并引入了 Top-k 截断机制:
通过 normalized 奖励加权,模型将注意力聚焦在自身产生的最优经验模态上,逐步对冗余和危险动作进行"剪枝"。最终,加权对数似然优化被优雅地转化为奖励加权扩散去噪损失(Reward-Weighted Denoising Loss),巧妙绕过了强化学习微调扩散策略时极不稳定的通过时间反向传播(BPTT)链条:
03 双轮驱动:确保平稳冷启动与几何泛化
纯粹的自模仿规划容易陷入局部最优或在初期由于随机噪声而崩溃。为此,SIDP 设计了两套协同互补的训练策略:
1. 无目标探索正则化器 (Goal-agnostic Exploration)
为了防止扩散模型在训练中发生"模态崩溃(Mode Collapse)"并退化为单模态的窄路径拟合,团队在训练重置时主动采样了大量辅助的相对偏角()和距离(3~5 m)作为无目标 embedding,并将重要性权重设为均匀分布。 这种机制强迫智能体学到的是具有"空间通用性"的几何表征(如走廊拓扑、墙体边界),而非机械地过拟合特定的绝对终点,极大地增强了跨场景的零样本泛化能力。
2. 奖励驱动课程学习门控 (Reward-Driven Curriculum)
在冷启动阶段,环境探索会产生大量不可学习的极度嘈杂信号。SIDP 通过两条派生指标动态过滤场景数据:
最大奖励 : 设定硬性阈值 ,自动屏蔽当前策略完全无法处理的极难场景,抑制梯度噪声。 奖励极差 : 设定阈值 ,剔除没有任何梯度区分度的过于平庸/空旷的场景。
通过这两级门控,系统实现了单调、有保障的单调收敛,彻底杜绝了策略在初期可能遭遇的早期崩溃(Early-stage collapse)。
04 严苛仿真基准评估:SR/SPL 的双重登顶
研究团队在 Isaac Sim 驱动的高保真 InternVLA-N1 S1 闭环导航基准上进行了大规模评测,包含 60 个充满未结构化障碍物的多样化场景(Commercial 商业、Home 居家、ClutteredEnv 杂乱环境)。
表 II:InternVLA-N1 S1 量化对比
SR (%) 与 SPL (%),mSR / mSPL 为各场景均值;RSR 以 ClutteredEnv-Easy 为基线,mRSR 为三种域偏移下的平均保留率。
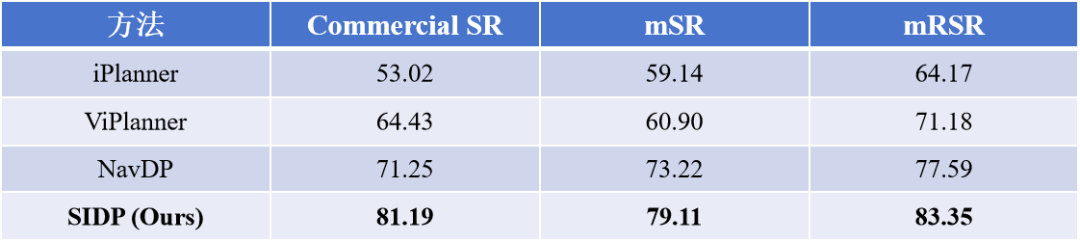
iPlanner
Commercial:SR 53.02 / SPL 51.44 / RSR 59.04 Home:SR 39.16 / SPL 37.27 / RSR 43.61 ClutteredEnv Easy:SR 89.80 / SPL 88.70 ClutteredEnv Hard:SR 80.69 / SPL 79.28 / RSR 89.86 综合:mSR 59.14 / mSPL 57.57 / mRSR 64.17
ViPlanner
Commercial:SR 64.43 / SPL 62.90 / RSR 78.50 Home:SR 43.61 / SPL 42.07 / RSR 53.13 ClutteredEnv Easy:SR 82.08 / SPL 81.98 ClutteredEnv Hard:SR 67.24 / SPL 67.07 / RSR 81.92 综合:mSR 60.90 / mSPL 59.83 / mRSR 71.18
NavDP
Commercial:SR 71.25 / SPL 68.89 / RSR 76.31 Home:SR 57.38 / SPL 55.08 / RSR 61.45 ClutteredEnv Easy:SR 93.37 / SPL 91.44 ClutteredEnv Hard:SR 88.71 / SPL 86.31 / RSR 95.01 综合:mSR 73.22 / mSPL 70.95 / mRSR 77.59
SIDP (Ours) ⭐
Commercial:SR 81.19 / SPL 73.36 / RSR 86.04 Home:SR 63.17 / SPL 56.48 / RSR 66.95 ClutteredEnv Easy:SR 94.36 / SPL 89.86 ClutteredEnv Hard:SR 91.58 / SPL 86.78 / RSR 97.05 综合:mSR 79.11 / mSPL 72.72 / mRSR 83.35
从表 II 的核心量化结果可以看出:
在最具挑战性的 Commercial 商业场景中,SIDP 的成功率(SR)达到了 **81.19%**,相比纯模仿学习的基准模型 NavDP(71.25%)实现了高达 9.94% 的绝对性能跃升。 团队引入了相对成功保留率(Relative Success Retention, RSR)来衡量感知扰动下的稳健性。在面对高烈度的视觉噪声、亮度衰减和对比度下降时,NavDP 的成功率保留率直接暴跌至 65% 以下,而 SIDP 依然坚挺地维持在 ~80% RSR,展现了极其惊人的视觉抗噪与纠错韧性。

为什么 SIDP 能打败 DAgger?
在与经典交互式模仿学习算法 DAgger 的消极对比中(图 9),研究团队给出了极具洞察力的解释:由于缺乏交互物理器,DAgger 在拟合具有不可观测全局状态的特权专家时,极易诱发因果混淆(Causal Confusion),并对非分布式(OOD)恢复状态产生灾难性遗忘(Catastrophic Forgetting)。而 SIDP 完全在自身的表示空间内部生成纠错轨迹,天然保持了分布的一致性与梯度稳定性。
05 边缘设备大解放:Deterministic 采样下的 2.5 倍加速
由于自模仿训练成功让轨迹分布实现了极高精度的集聚(Intra-modal Convergence),SIDP 摆脱了传统方法对 DDPM 随机性采样的依赖,转而能够无损地运用 DDIM 确定性采样加速。
表 III:推理时间与成功率(SR)对比
在 Jetson Orin Nano 上对比不同模型与采样器的推理延迟;加速倍数以 NavDP + DDPM 10 步(273 ms)为基线。
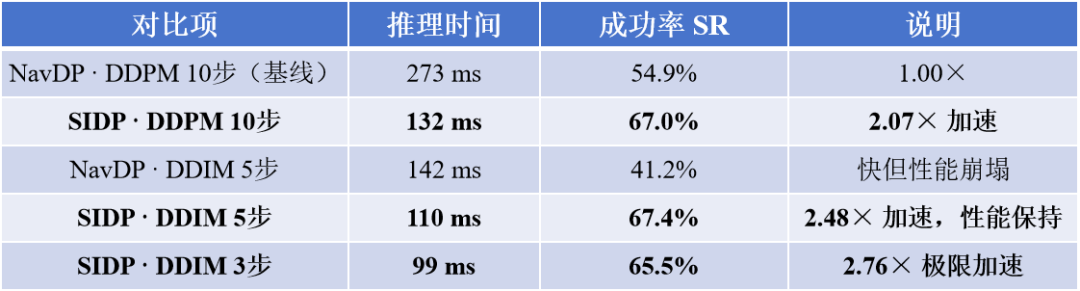
在真实的嵌入式边缘计算平台 NVIDIA Jetson Orin Nano (8GB) 上:
在同等的 10 步 DDPM 配置下,SIDP 凭借免除外部选择器的精简架构,直接将延迟从 273ms 砍到了 132ms(2.07倍加速)。 当进行极限压缩、将去噪步数激进地缩减到 5步 DDIM 时,NavDP 的成功率剧烈滑坡至 41.2%,直接丧失实用性;而 SIDP 依旧展现了强悍的鲁棒性,保持了 67.4% 的高成功率,此时单次高频控制推理仅需 110ms(2.48倍整体提速)!
这表明 SIDP 完美攻克了生成式模型由于计算延迟过高、长期难以在低算力机器人硬件上进行高频闭环反应的顽疾。
06 异构多平台真机部署:跨越 Sim-to-Real 的鸿沟
为了验证算法在真实物理世界中的鲁棒性,研究团队将 SIDP 策略直接零样本(Zero-shot)移植到了两种截然不同的物理平台上:Agilex T-rex 轮式机器人和 Unitree Go2 四足机器人。车辆搭载的立体双目视觉信号经由模糊感知注意力网络(BANet)处理后,直接喂给 SIDP 预测未来的相对位移路径点。

实测表明(表 IV),SIDP 斩获了 90.25% 的平均真机成功率(mSR),超越基准模型 7.0个百分点。最令人振奋的是,面对四足机器人在行进中由于高频对地踏击所带来的机身剧烈颠簸与视场振荡,SIDP 凭借其出色的分布弹性和纠错机制,依然稳稳实现了 88.00% 的单项成功率,完成了敏捷的障碍物绕行和顺滑的目标点靠泊。
总结与展望
自模仿扩散策略(SIDP)通过一种极其优雅的内在匹配形式,闭环解决了数据源次优和推理架构冗余的两大根本矛盾,成功打通了扩散模型在机器人规划应用中的"最后一公里"。团队指出,未来将进一步探索流匹配(Flow Matching)等更新一代的高效生成式范式与 SIDP 框架的有机融合,朝着更轻量、更敏捷的具身智能体目标不断迈进。
作者简介
张润华 (Runhua Zhang): 本文共同第一作者,浙江大学控制科学与工程学院研究生。邮箱:rhzhangchn@gmail.com 侯俊毅 (Junyi Hou): 本文共同第一作者,浙江大学控制科学与工程学院硕士研究生。 程昌旭 (Changxu Cheng): 本文通讯作者,宇泛科技高级研究员,长期从事计算机视觉与机器人感知规划研究。邮箱:ccx0127@gmail.com
推荐阅读 :












