

引言
视觉-语言导航(Vision-and-Language Navigation, VLN)作为具身智能的关键研究领域,旨在赋予智能体根据自然语言指令在未知三维环境中导航的能力。近期,多模态大语言模型(MLLM)凭借其卓越的语义理解与推理能力,极大地推动了VLN领域的发展。然而,当前主流方法普遍依赖于构建显式记忆(如文本拓扑地图或存储历史图像序列),这一范式面临三大核心挑战:
1. 空间信息损失:基于文本的记忆难以精确表征复杂的空间几何关系。
2. 计算效率低下:重复处理历史观测数据导致巨大的计算冗余与推理延迟。
3. 记忆无限膨胀:记忆体积随导航步数线性增长,阻碍了模型在长时序任务中的有效信息提取。

更根本的矛盾在于,现有模型大多沿用为2D图文任务设计的视觉编码器,未能充分利用RGB图像中蕴含的丰富3D空间线索(如透视、遮挡),从根本上限制了其三维空间感知能力。为突破这些瓶颈,我们从人类认知科学中获得启发——人脑在导航时,左右半球分别处理语义与空间信息,并形成高效的隐式表征。
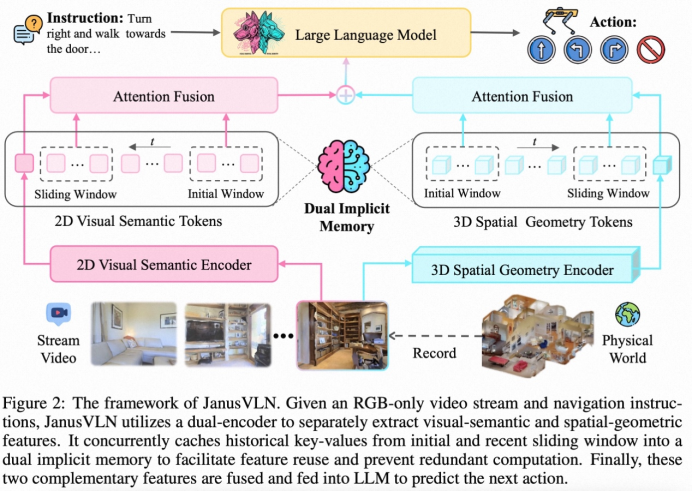
基于此,我们提出了一种全新的VLN框架——JanusVLN。该框架首次引入双重隐式神经记忆(Dual Implicit Neural Memory),将视觉语义与空间几何信息解耦,并将其建模为两个独立的、紧凑的、固定大小的神经表征 (neural representation)。JanusVLN仅需单目RGB视频流,便能赋予模型强大的3D空间推理能力,并通过高效的增量式更新机制,在实现卓越性能的同时,显著降低了计算开销。
论文标题:JanusVLN: Decoupling Semantics and Spatiality with Dual Implicit Memory for Vision-Language Navigation
论文链接:https://arxiv.org/abs/2509.22548
项目主页:https://miv-xjtu.github.io/JanusVLN.github.io/
代码地址:https://github.com/MIV-XJTU/JanusVLN
JanusVLN:双重隐式记忆框架

JanusVLN的核心创新在于其双重隐式记忆框架,它将导航记忆从显式、高维的原始数据,转变为隐式、紧凑的神经网络内部表征。
核心设计理念
1.解耦的视觉感知:语义与空间
为实现全面的环境理解,JanusVLN采用双编码器架构,分别处理“是什么”(语义)与“在哪里”(空间)的问题:
2D视觉语义编码器:采用Qwen2.5-VL的视觉编码器,提取图像中的高级语义特征。 3D空间几何编码器****:引入预训练的3D视觉几何基础模型(VGGT),仅从RGB视频中便可推断出蕴含深度、遮挡等丰富3D结构的几何特征,赋予模型无需昂贵深度传感器的3D感知能力。
2.双重隐式神经记忆:以KV缓存为载体
我们创新地将神经网络注意力模块的键值对(Key-Value, KV)缓存作为记忆的载体。这种经网络深度处理的KV对是环境信息的高度抽象和浓缩,构成了紧凑且高效的隐式记忆。JanusVLN分别为语义与空间编码器维护独立的KV缓存,形成了互补的双重记忆。
3. 高效的混合增量更新
为维持记忆的固定大小并兼顾全局与局部信息,我们设计了一种混合缓存更新策略:
滑动窗口:缓存最近几帧的KV,确保对即时环境的敏锐感知。 初始窗口:永久保留任务初始几帧的KV。研究表明,这些初始帧如同“注意力接收器”,为长期任务提供关键的全局锚点。
该机制使得模型在每一步仅需处理当前帧,并通过与固定大小的隐式记忆交互来复用历史信息,彻底避免了对历史帧的重复计算,从而解决了记忆膨胀问题并大幅提升了推理效率。
实验验证
1. 定量性能对比
我们在权威的VLN-CE基准上进行了全面评估。实验结果表明,JanusVLN在各项指标上均取得了SOTA性能。
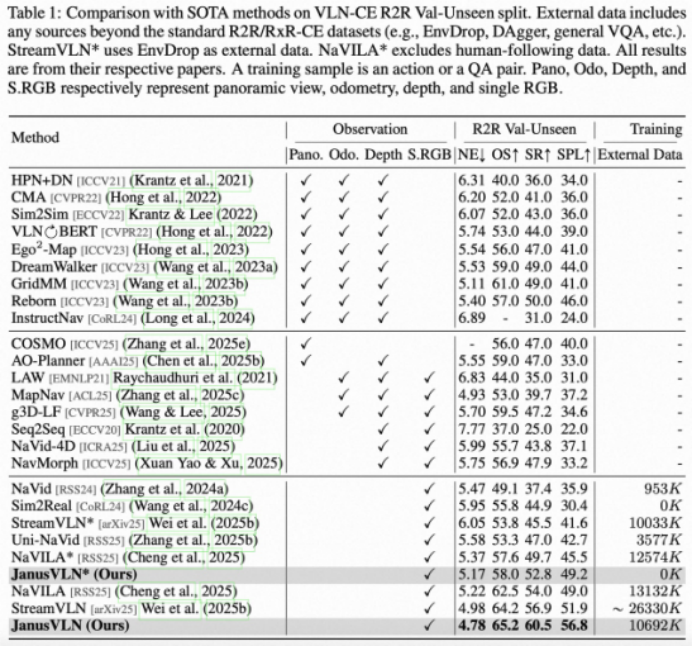

超越SOTA方法:与同样仅使用RGB输入的SOTA方法(如NaVILA, StreamVLN)相比,JanusVLN在成功率(SR)上取得了3.6至10.8个点的显著提升,且使用了更少的外部训练数据,验证了双重隐式记忆范式的优越性。
超越多模态输入方法:相较于依赖全景图、深度图等昂贵多模态输入的方法,JanusVLN仅凭单目RGB输入,便在SR指标上实现了10.5至35.5个点的巨大优势。
强大的泛化能力:在更具挑战性的多语言RxR-CE数据集上,JanusVLN同样刷新了SOTA记录,展现了其卓越的泛化性能。
2. 计算效率优势
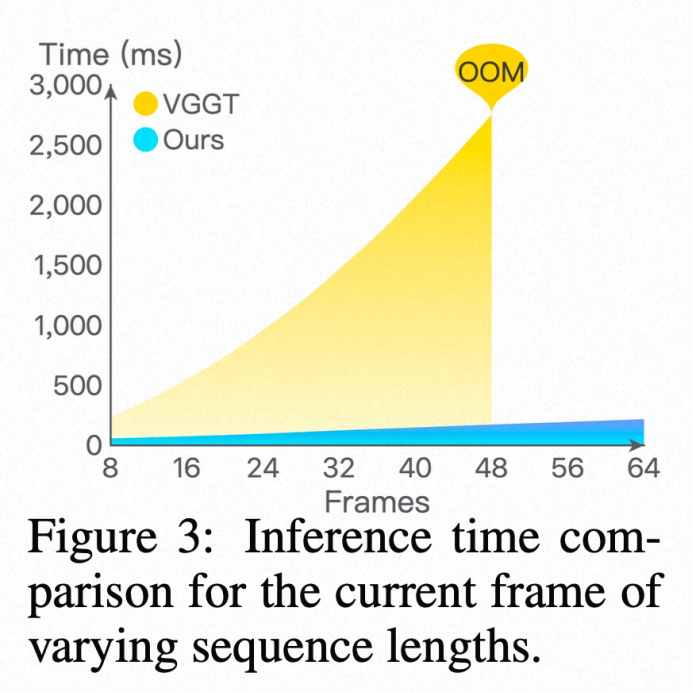
图3:随着序列长度增加,JanusVLN(Cached Memory)与基线方法(VGGT)的单帧推理时间对比
如图所示,JanusVLN的增量式更新机制使其推理时间几乎不受导航步数影响,而VGGT由于需要重复处理整个序列,其计算成本呈指数级增长。这证明了JanusVLN在实现长时序导航方面的巨大潜力。
3. 空间推理能力定性分析

我们选取了几个对空间理解要求极高的导航任务,例如:
深度感知(定位到“最远的”黄色凳子) 相对方位理解(停在盆栽“旁边”而非“前方”) 空间关联推理(找到橙色柜子“旁边”的凳子)
实验表明,得益于空间几何记忆提供的3D感知能力,JanusVLN能够准确理解这些复杂的空间指令,并成功完成任务,而这正是传统VLN模型面临的主要挑战。
总结与展望
本文提出的JanusVLN框架,通过引入开创性的双重隐式神经记忆,成功将视觉语义与空间几何信息解耦,从根本上解决了传统VLN方法在记忆机制上的核心瓶颈。该框架不仅实现了仅依靠RGB输入进行精确的3D空间感知,还通过高效的增量式更新大幅提升了计算效率。
全面的实验结果验证了JanusVLN的卓越性能与泛化能力。我们相信,这项工作将推动VLN研究从“2D语义主导”的范式,迈向“3D空间与语义协同”的新阶段,为构建下一代具备高级空间认知能力的具身智能体铺平了道路。











