点击下方卡片,关注「3D视觉工坊」公众号
选择星标,干货第一时间送达
来源:3D视觉工坊
星球内新增20多门3D视觉系统课程、入门环境配置教程、多场顶会直播、顶会论文最新解读、3D视觉算法源码、求职招聘等。想要入门3D视觉、做项目、搞科研,欢迎扫码加入!

导语
具身智能(Embodied AI)正引领人工智能迈向与物理世界深度交互的下一阶段。其中,视觉-语言导航(VLN)——即智能体根据自然语言指令在三维环境中自主导航,是实现这一宏伟蓝图的核心技术。然而,当前主流模型在“记忆”这一关键环节遭遇了严重瓶颈,制约了其在复杂、长时序任务中的表现。
为应对这一挑战,作者从人类认知科学中汲取灵感,正式发布了名为JanusVLN的创新导航框架。该框架首次提出双重隐式记忆(Dual Implicit Memory)范式,通过解耦并高效编码语义与空间信息,彻底革新了VLN领域的记忆机制。JanusVLN仅需单目RGB视频流,便在权威基准上实现了性能的全面超越,为构建具备高级空间认知能力的下一代具身智能体开辟了全新的道路。
论文标题:JanusVLN: Decoupling Semantics and Spatiality with Dual Implicit Memory for Vision-Language Navigation 论文链接:https://arxiv.org/abs/2509.22548 项目主页:https://miv-xjtu.github.io/JanusVLN.github.io/ 代码地址:https://github.com/MIV-XJTU/JanusVLN
一、当前视觉语言导航的记忆困境
智能体在真实环境中导航,如同人类探索未知区域,需要持续记忆“走过了哪里”、“看见了什么”。当前基于多模态大语言模型(MLLM)的VLN方法,普遍依赖显式记忆,但这带来了三大根本性难题:
空间关系的编码难题:将视觉观测压缩为文本拓扑地图(如“桌子在椅子左边”),会不可逆地丢失物体间的精确距离、方位等连续几何信息,导致空间推理能力严重受限。 计算资源的线性消耗:将历史图像序列作为记忆,意味着模型在每一步决策时都需对不断增长的图像流进行重复处理,计算开销随导航步数线性增加,难以满足实时性要求。 记忆过载与信息稀释:随着导航轨迹变长,显式记忆库无限膨胀,导致关键信息被淹没在海量冗余数据中,模型提取有效信息的难度剧增,即“记忆爆炸”。
问题的根源在于,现有模型大多沿用为2D图文理解设计的架构,天然忽视了RGB图像作为三维世界投影所蕴含的丰富空间线索。

二、JanusVLN:源于认知科学的双重隐式记忆
人类大脑在导航时,左右半球协同工作,分别处理语义概念(“这是什么”)与空间关系(“它在哪里”),并形成高效、抽象的隐式记忆。受此启发,JanusVLN构建了全新的双重隐式记忆框架。
核心思想:语义与空间解耦JanusVLN将复杂的导航记忆任务分解为两个并行且互补的子任务:语义理解与空间几何感知。这两种能力由独立的神经网络模块负责,其处理后的信息被编码为两个固定大小、高度浓缩的隐式神经表征(KV缓存),而非原始数据。 关键实现:纯RGB驱动的三维感知为赋予模型强大的空间感知力,JanusVLN集成了一个预训练的3D视觉几何基础模型(VGGT)。该模型能够仅从普通的RGB视频流中推断出场景的深度、遮挡、透视等三维结构信息,从而摆脱了对激光雷达、深度相机等昂贵传感器的依赖,极大增强了方案的普适性和部署可行性。 效率保障:恒定大小的增量式更新为根治“记忆爆炸”,JanusVLN采用了一种创新的混合增量更新策略。通过维护一个固定大小的“滑动窗口”(缓存近期观测)和一个保留初始几帧的“锚点窗口”(提供全局上下文),实现了记忆规模的恒定。在决策时,模型仅需处理当前帧并与这两个紧凑的隐式记忆交互,从而以极低的计算成本高效复用历史信息。
三、JanusVLN框架解析

JanusVLN的整体架构精炼而高效,主要包括三大核心模块:
双流感知模块:并行采用2D视觉语义编码器(基于Qwen2.5-VL)提取高级语义特征,以及3D空间几何编码器(基于VGGT)从单目视频中提取三维几何特征,为智能体提供全面、解耦的场景理解。 双重隐式记忆模块:将上述两个编码器在处理过程中的注意力键值对(KV)缓存直接作为记忆载体。这些经过深度网络提炼的特征,构成了关于语义和空间几何的、紧凑而高效的双重隐式记忆库。 高效增量更新机制:结合滑动窗口与初始窗口(作为“注意力接收器”Attention Sinks,稳定长时序注意力)的策略,在保持记忆规模恒定的前提下,既能敏锐感知近期环境变化,又能维持全局任务目标的一致性。
四、卓越的实验性能
我们在两大权威VLN基准VLN-CE和RxR-CE上对JanusVLN进行了严格评估,结果证明了其卓越的性能。
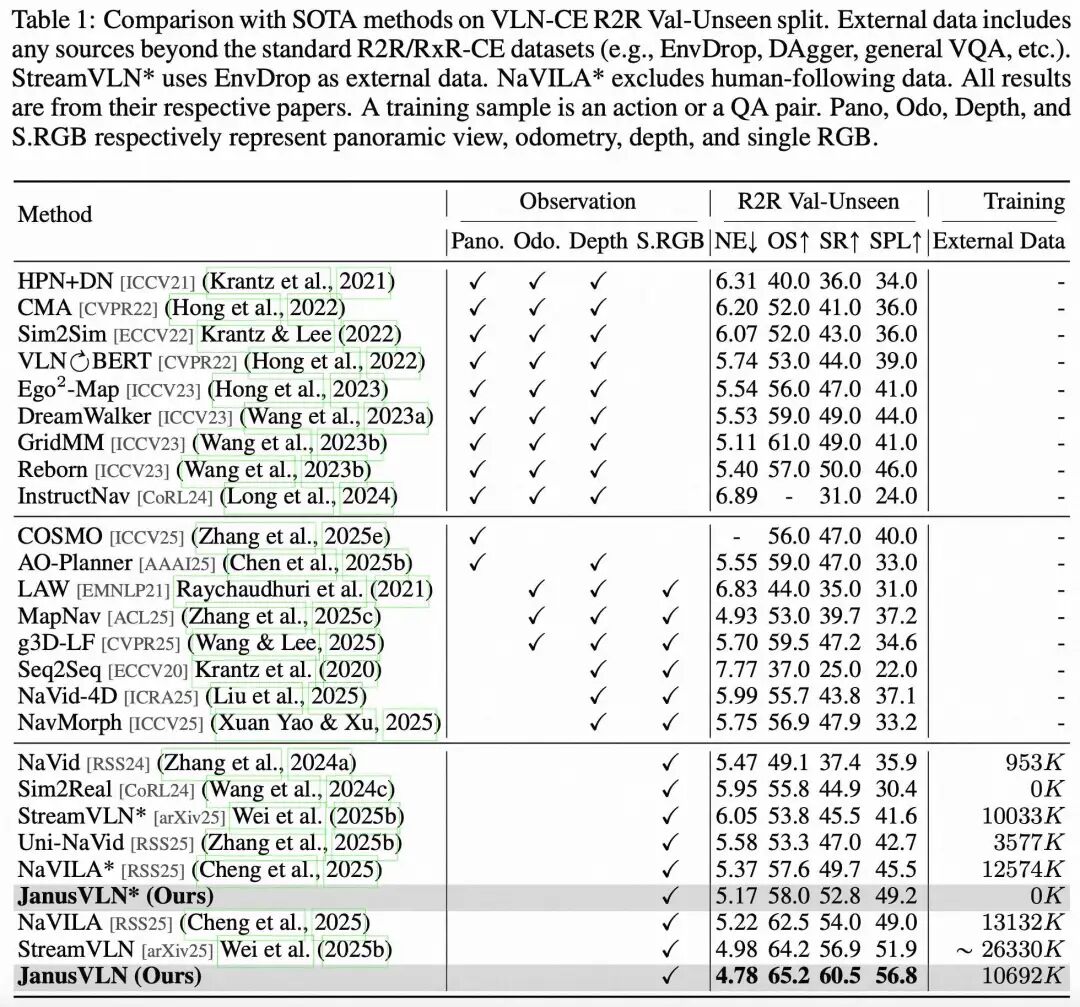
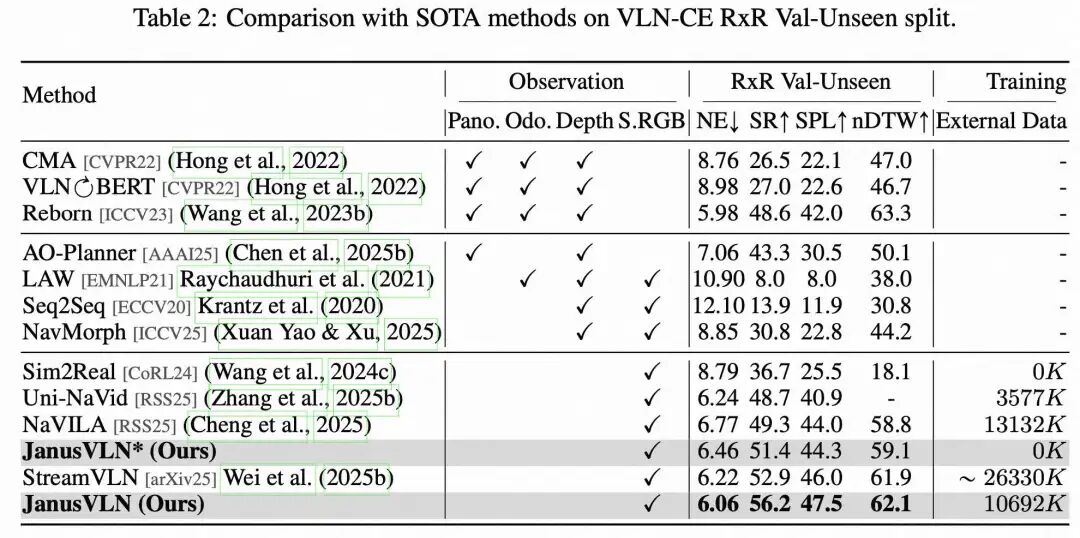
定量分析: SOTA性能:在仅使用单目RGB输入的情况下,JanusVLN在两大基准上的成功率(SR)指标,均显著超越了当前所有已发表的前沿方法,包括那些依赖全景图、深度图等更多模态输入的方法,领先优势最高可达35.5个百分点。 范式优越性:与同样使用RGB输入但采用显式记忆(如历史帧、文本地图)的SOTA方法(如NaVILA, StreamVLN)相比,JanusVLN取得了3.6至10.8个点的性能提升,充分证明了双重隐式记忆范式的优越性。 杰出泛化性:在语言指令更复杂、场景更多样的RxR-CE数据集上,JanusVLN同样刷新了SOTA记录,展现了其强大的跨场景泛化能力。

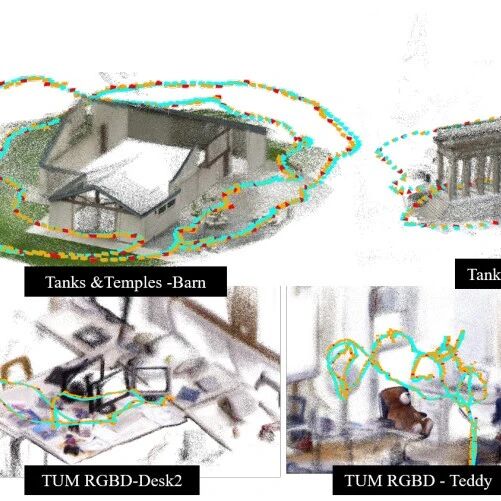
定性分析: 可视化结果显示,在面对需要精细空间推理的指令时(如上图,指令要求“停在有绿色植物的桌子旁边,而不是前面”),JanusVLN凭借其精准的空间几何记忆,能够准确理解并执行复杂的空间关系指令,而其他方法则容易出现混淆。
五、总结与展望
本文提出的JanusVLN框架,通过引入开创性的双重隐式神经记忆范式,成功解决了视觉-语言导航领域长期存在的记忆膨胀、计算冗余和空间感知缺失等核心痛点。
JanusVLN不仅在性能上树立了新的行业标杆,更重要的是,它推动了VLN研究范式从“2D语义驱动”向“3D空间与语义协同”的深刻转变。这一工作为构建能够在复杂物理世界中进行高效、精准导航的下一代具身智能体奠定了坚实的基础,开启了具身智能空间认知研究的新篇章。
3D视觉1V1论文辅导来啦!
3D视觉学习圈子
星球内新增20多门3D视觉系统课程、入门环境配置教程、多场顶会直播、顶会论文最新解读、3D视觉算法源码、求职招聘等。想要入门3D视觉、做项目、搞科研,欢迎扫码加入!

3D视觉全栈学习课程:www.3dcver.com

3D视觉交流群成立啦,微信:cv3d001