点击下方卡片,关注「3D视觉工坊」公众号
选择星标,干货第一时间送达
来源:视觉语言导航
星球内新增20多门3D视觉系统课程、入门环境配置教程、多场顶会直播、顶会论文最新解读、3D视觉算法源码、求职招聘等。想要入门3D视觉、做项目、搞科研,欢迎扫码加入!


作者:Wangtian Shen, Pengfei Gu, Haijian Qin, Ziyang Meng 单位:清华大学,北京信息科技大学 论文标题:EffoNAV: An Effective Foundation-Model-Based Visual Navigation Approach in Challenging Environment 论文链接:https://ieeexplore.ieee.org/document/11012733/ 代码链接:https://github.com/robotnav-bot/EffoNAV
主要贡献
提出基于预训练基础模型的视觉导航方法EffoNAV,在图像目标导航任务中,相较于现有方法,展现出卓越的性能,特别是在应对光照变化等复杂情况时,比现有SOTA提升了40%。 在导航任务中使用预训练基础模型(如DINOv2)进行特征提取,并设计适配器以辅助损失收敛。实验结果表明,基础模型在导航中,尤其是在光照变化等挑战性场景下,具有显著优势。 为有效捕捉目标图像与观测图像之间的空间关系,引入交叉注意力机制,通过Transformer的交叉注意力层处理目标和当前图像,从而获得更有效的目标编码。 考虑到并非所有当前和过去的观测对导航任务同等重要,提出Token注意力机制,动态地为不同Token分配权重,使网络能够更精准地关注对导航最相关的信息,进一步提升导航性能。
研究背景
视觉导航的重要性:自主导航在智能机器人应用中扮演着关键角色,而视觉导航因其低成本和丰富的语义信息而成为首选方案。图像目标导航任务要求机器人根据提供的目标图像导航到相应位置,近年来,基于机器学习的视觉导航取得了显著进展,但现有方法大多使用简单的神经网络结构,从头开始训练,这限制了其在复杂现实情况下的导航性能,例如在多转弯或光照变化的环境中。 预训练基础模型的发展:预训练基础模型(如DINOv2)在大规模互联网数据上进行训练,能够为下游任务提供强大的特征提取能力,已在视觉领域取得巨大成功,这为将其应用于导航任务提供了启发。
方法

基于基础模型的编码器
选择DINOv2作为特征提取器:为了从图像中稳健地提取特征,论文选用DINOv2中的ViT-S14版本作为编码器。DINOv2是一个预训练的基础模型,其在大规模互联网数据上进行训练,能够提供强大的特征表示能力。ViT-S14是DINOv2的一个轻量级版本,能够确保计算效率。 特征提取的具体操作:DINOv2中的每个层(包括query、key、value和token)都可以提取特征。根据文献,value层提供了最佳的特征表示,因此论文选择DINOv2中第11层的value作为从每张图像中提取的特征。

使用DINOv2和EfficientNet结合:为了降低计算开销,论文仅使用DINOv2来计算当前观测图像和目标图像的特征,而过去5次观测的特征则使用EfficientNet进行计算,生成相应的Token(tokens)。 DINOv2与其他模型的对比:论文通过实验对比了DINOv2与其他基础模型(如CLIP、BLIP)、预训练的ResNet50以及从头开始训练的卷积网络的特征提取能力。实验结果表明,DINOv2能够在不同光照条件下稳定地提取同一物体的特征,而其他网络则无法保持这种稳定性。 引入适配器解决训练问题:在训练过程中,直接使用DINOv2提取的特征会导致损失难以收敛。为了解决这一问题,论文在DINOv2之后引入了一个包含六个ResBlocks的适配器。适配器的权重在当前观测和目标图像之间共享。适配器的作用是将DINOv2提取的特征进行进一步的处理,使其更适合于后续的导航任务。
当前目标编码模块

该模块的作用是将从图像中提取的特征(Fc和Fg)进行处理,以计算目标编码。其核心思想是利用交叉注意力机制来捕捉当前观测图像和目标图像之间的空间关系。
交叉注意力与自注意力的结合:模块中交替使用自注意力层和交叉注意力层,共进行四次。在自注意力层中,query(Q)、key(K)和value(V)都来自同一图像;而在交叉注意力层中,query来自一个图像,而key和value来自另一个图像。这种设计使得网络能够识别出当前观测和目标图像中相同的物体和景观,从而捕捉它们之间的空间关系。 注意力层的计算:对于每个注意力层,其输入包括query(Q)、key(K)和value(V),计算公式为:,其中是key向量的维度。 生成目标编码Token:经过交替的自注意力和交叉注意力层处理后,特征Fc和Fg通过两层卷积生成目标编码TokenTg。这个Token包含了当前观测和目标图像之间的空间关系信息,对于后续的导航决策至关重要。
Token注意力
在导航任务中,并非所有当前和过去的观测都同等重要。当前观测和目标图像通常比过去的观测对导航任务更具关键性。因此,论文提出了一种Token注意力机制,用于动态地为不同的Token分配权重。

Token注意力的计算过程: 首先,将当前观测Token(Tc)、目标编码Token(Tg)和过去5次观测的Token(Tp0:5)输入到一个4层的自注意力Transformer中。 然后,通过最大池化(MaxPool)和平均池化(AvgPool)生成两个向量(Vt_max和Vt_avg),每个向量的长度为7(对应7个Token)。这两个向量接着通过一个共享的多层感知机(MLP),该MLP包含一个隐藏层。MLP处理后的两个向量相加,然后通过sigmoid函数计算出Token注意力向量。这个向量中的每个值对应一个特定Token的重要性权重。 最后,原始的7个Token通过元素级乘法与它们各自的注意力值相乘,得到加权后的Token。 公式表示:,其中T表示加权前的Token。
训练
数据集选择:为了便于比较,论文使用了四个大型真实世界导航数据集(RECON、GoStanford、SCAND和SACSoN)来训练模型。这些数据集包含了来自不同环境和机器人平台的轨迹。 数据预处理:由于不同机器人的速度和动态特性不同,论文通过将轨迹中的航点按照机器人的最大速度进行缩放来归一化航点。 训练过程: 在训练过程中,首先从数据集中采样一条轨迹τ,从中选择六个连续的观测作为过去观测和当前观测。然后,随机选择一个未来的观测作为目标图像,其时间步长d从[lmin,lmax]范围内均匀采样。 对应的目标动作和距离作为标签,模型使用均方误差(MSE)损失进行训练。损失函数为:,其中表示所提出的模型,用于平衡动作损失和距离损失。
实验
实验设置

在Autolabor机器人上进行导航实验,该机器人配备RGB相机和用于处理的笔记本电脑。 通过ROS传输图像数据,笔记本电脑配备Nvidia Geforce RTX 4070 GPU和Intel i9-14900 CPU。 在预建的拓扑地图上进行图像目标导航,地图中的每个节点存储一个子目标图像,机器人在地图中定位自身,并将下一个节点提供给网络作为子目标图像,当机器人到达目标节点时,发送“到达目标”信号。模型预测的动作包括接下来5步的航点,选择第4个航点生成低级控制动作,包括线速度v和角速度ω。
基线方法
将EffoNAV与多个现有图像目标导航方法进行比较,包括GNM、VINT和NoMaD。 此外,还进行了消融研究,验证EffoNAV中各个组件的贡献,包括不使用Token注意力机制的EffoNAV版本,以及同时去除Token注意力机制并用卷积网络替换DINOv2的版本。
导航性能
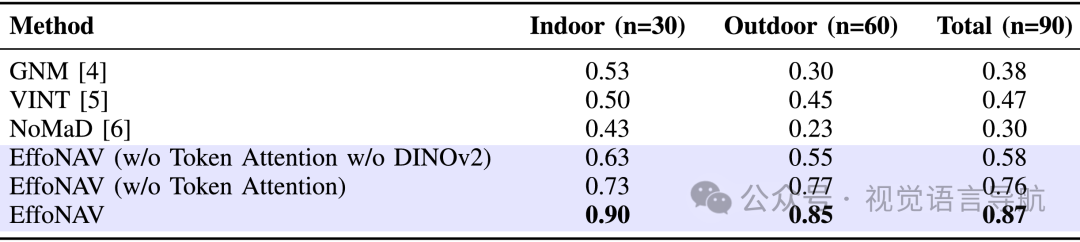
实验环境包括10条室内路线和20条室外路线,这些路线涵盖了多种条件。实验结果表明,EffoNAV在室内和室外环境中均优于所有基线方法。 例如,在具有多个转弯、弱纹理场景或重复图案的更具挑战性路线上,现有方法如GNM、VINT和NoMaD表现不佳,而EffoNAV能够成功导航。



使用DINOv2作为编码器的方法在光照差异较大的场景中表现出显著优势。此外,带有Token注意力机制的EffoNAV的成功率比没有Token注意力机制的版本高出10%,证明了Token注意力机制在提升导航性能方面的有效性。
在大光照变化下的导航性能

为了评估在更具现实性和挑战性场景下的性能,进行了存在显著光照变化的导航实验,即在白天间隔至少三个小时进行建图和导航,导致光照条件存在明显差异。 测试了10条不同的路线,每条路线进行3次重复实验。结果表明,在这些具有挑战性的光照变化场景中,使用DINOv2编码器的方法显著优于其他方法。 完整的EffoNAV保持了90%的高成功率,而没有使用DINOv2的方法则难以实现导航,这进一步证明了DINOv2在环境变化下的强大泛化能力。
Token注意力的进一步探索

为了深入了解Token注意力在导航过程中的变化,计算了在目标图像与当前图像的时间距离分别为2、10和20时,每个Token的注意力值。 结果证实了当前观测和目标编码Token的重要性,并且随着时间距离的增加,对过去观测的注意力降低,而对当前观测和目标编码的注意力增加,这表明Token注意力机制能够动态且灵活地分配注意力,优先关注对导航最相关的信息,是提升导航性能的关键因素。
结论与未来工作
结论: EffoNAV作为一种有效的基于基础模型的导航网络,在图像目标导航任务中表现卓越,尤其在光照变化等复杂场景下,其成功率达到87%,比现有SOTA提升了40%。 该方法在VINT的基础上,通过引入预训练基础模型进行鲁棒特征提取、利用交叉注意力机制增强观测和目标图像的编码以及引入Token注意力动态分配不同Token的重要性,实现了显著的性能提升。 未来工作: 尽管EffoNAV已被证明是有效的导航网络,但视觉导航仍面临一些挑战。例如,当机器人偏离预定义路线并进入拓扑地图之外的区域时,可能无法恢复并到达目标。 未来的研究可以探索改进地图表示方法,如隐式神经地图,以增强机器人的轨迹校正能力。 此外,虽然基于图像的目标规范用户友好,但自然语言指令等其他交互方式可能会更加便捷,将EffoNAV扩展到支持通过自然语言指令指定目标将是未来的一个有趣方向。
3D视觉硬件,官网:www.3dcver.com

3D视觉学习圈子
星球内新增20多门3D视觉系统课程、入门环境配置教程、多场顶会直播、顶会论文最新解读、3D视觉算法源码、求职招聘等。想要入门3D视觉、做项目、搞科研,欢迎扫码加入!

3D视觉全栈学习课程:www.3dcver.com

3D视觉交流群成立啦,微信:cv3d001