
TC-Light 是由中科院自动化所张兆翔教授团队研发的生成式渲染器,能够对具身训练任务中复杂和剧烈运动的长视频序列进行逼真的光照与纹理重渲染,同时具备良好的时序一致性和低计算成本开销,使得它能够帮助减少 Sim2Real Gap 以及实现 Real2Real 的数据增强,帮助获得具身智能训练所需的海量高质量数据。
它是如何实现的呢?本文将为你揭秘 TC-Light 背后的黑科技!本工作已中稿 NeurIPS2025,论文与代码均已公开,欢迎大家试用和体验,也欢迎大家到 Project Page 体验 Video Demo。

论文题目:TC-Light: Temporally Coherent Generative Rendering for Realistic World Transfer
项目主页: https://dekuliutesla.github.io/tclight/
论文链接: https://arxiv.org/abs/2506.18904
代码链接: https://github.com/Linketic/TC-Light
研究背景
光线及其与周围环境的交互共同塑造了人类以及具身智能体感知数字世界和现实世界的基本方式,在不同光照条件下对世界的观测使得我们理解光线与物质的交互关系,使得我们形成对周边环境物质和几何属性的基本判断,并且也使得我们能够在不同的光照条件下都能够鲁棒且正确地完成与世界的交互。
然而,在现实环境中采集不同光照与场景条件下的数据代价高昂,而仿真环境中尽管可以获得近乎无限的数据,但受限于算力资源,通常需要对光线的多次折射衍射以及纹理精度进行近似和简化,使得视觉真实性无可避免地受到损失,在视觉层面产生 Sim2Real Gap。而如果能够借助生成式模型根据所需的光照条件对现实或仿真环境下采集到的视频数据进行重渲染,不仅能够帮助获得增加已有真实数据的多样性,并且能够弥合计算误差带来的 CG 感,使得从仿真器中得到视觉上高度真实的传感器数据,包括 RL-CycleGAN 在内的许多工作已经证实,这一策略能够帮助减少将具身模型迁移到真实环境中所需微调的数据量和训练量。
尽管这一任务意义重大,但实际解决过程面临许多挑战。用于训练的视频数据往往伴随复杂的运动以及前景物体的频繁进出,同时视频序列有着较长的长度以及较高的分辨率。我们的定量和定性实验证据(参见论文实验部分及 Project Page)表明,在这些复杂且困难的输入条件下,已有的算法要么受制于训练所用视频数据的分布(如 COSMOS-Transfer1,Relighting4D),要么难以承受巨大的计算开销(如 Light-A-Video, RelightVid),要么难以保证良好的时序一致性(如 VidToMe, RAVE 等)。

图 1 TC-Light 效果展示
为了推动这一问题的解决,我们提出了 TC-Light 算法,在提升视频生成模型计算效率的同时,通过两阶段在线快速优化提升输出结果的一致性,如图 1 和视频Demo所示所示,本算法在保持重渲染真实性的同时,时序一致性和真实性相比于已有算法取得了显著提高。下面对算法细节进行详细介绍。
二、TC-Light 算法介绍
零样本时序模型扩展
TC-Light 首先使用视频扩散模型根据文本指令对输入视频进行初步的重渲染。这里我们基于预训练好的 SOTA 图像模型 IC-Light 以及 VidToMe 架构进行拓展,同时引入我们所提出的 Decayed Multi-Axis Denoising 模块增强时序一致性。具体而言,VidToMe 在模型的自注意力模块前后分别对来自不同帧的相似 token 进行聚合和拆分,从而增强时序一致性并减少计算开销;如图 2 中 (a) 所示,类似 Slicedit,Decayed Multi-Axis Denoising 模块将输入视频分别视作图像 (x-y 平面) 的序列和时空切片(y-t 平面)的序列,分别用输入的文本指令和空文本指令进行去噪,并对两组噪声进行整合,从而使用原视频的运动信息指导去噪过程。不同于 Slicedit,我们在 AIN 模块对两组噪声的统计特性进行了对齐,同时时空切片部分的噪声权重随去噪步数指数下降,从而避免原视频光照和纹理分布对重渲染结果的过度影响。

图 2 TC-Light 管线示意图
两阶段时序一致性优化策略
尽管通过引入前一小节的模型,视频生成式重渲染结果的一致性得到了有效改善,但输出结果仍然存在纹理和光照的跳变。因此我们进一步引入两阶段的时序一致性优化策略,这同时也是 TC-Light 的核心模块。在第一阶段,如图 2 中 (b) 所示,我们为每一帧引入 Appearance Embedding 以调整曝光度,并根据 MemFlow 从输入视频估计的光流或仿真器给出的光流优化帧间一致性,从而对齐全局光照。这一阶段的优化过程非常快速,A100 上 300 帧 960x540 分辨率只需要数十秒的时间即可完成。
在第二阶段,我们进一步对光照和纹理细节进行优化。如图 2 中 (c) 所示,这里我们首先根据光流以及可能提供的每个像素在世界系下的位置信息,快速将视频  压缩为码本
压缩为码本 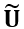 (也即图中的 Unique Video Tensor),即:
(也即图中的 Unique Video Tensor),即:
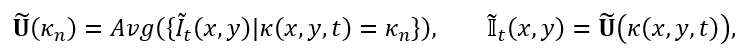
其中 κ(x,y,t) 为视频帧给定像素依据光流及空间信息得到的码本索引,这一基于时空先验的压缩方式在原视频上近乎可以保持无损。不同于 Vector Quantization 仅考虑颜色相似性的做法,这一压缩方案保证了被聚合的像素之间的时空关联性,使得对应同一个码本值的不同像素具有相似的时空一致性优化目标和梯度。随后,我们以码本 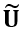 作为优化目标,以解码后的帧间一致性作为主要优化目标,并且以 TV Loss 抑制噪声,同时以 SSIM Loss 使得与一阶段优化结果保持一定程度的结构相似性。实验结果表明,这一阶段的优化能显著改善时序一致性,同时非常快速,A100 上 300 帧 960x540 分辨率通常只花费 2 分钟左右,且由于以压缩后的码本作为优化目标,不仅避免了以往工作以 NeRF 或 3DGS 为载体带来的 10-30 分钟的训练代价,显存开销上也能得到优化。
作为优化目标,以解码后的帧间一致性作为主要优化目标,并且以 TV Loss 抑制噪声,同时以 SSIM Loss 使得与一阶段优化结果保持一定程度的结构相似性。实验结果表明,这一阶段的优化能显著改善时序一致性,同时非常快速,A100 上 300 帧 960x540 分辨率通常只花费 2 分钟左右,且由于以压缩后的码本作为优化目标,不仅避免了以往工作以 NeRF 或 3DGS 为载体带来的 10-30 分钟的训练代价,显存开销上也能得到优化。
三、实验与分析

表 1 与主流算法的定量性能比较,其中 VidToMe 和 Slicedit 的基模型都换成了 IC-Light 以进行公平比较。Ours-light 指不用 Multi-Axis Denoising 模块的结果,相当于对 VidToMe 直接应用两阶段优化算法。
为了验证算法在长动态序列的重渲染表现,我们从 CARLA、Waymo、AgiBot-DigitalWorld、DROID 等数据集收集了 58 个序列进行综合评测,结果如表 1 所示。可以看到我们的算法克服了已有算法在时序一致性和计算开销等方面的问题,取得了最佳的综合性能表现。图 3 的可视化对比也表明,我们的算法在保持内容细节的同时得到了高质量的重渲染性能表现。

图 3 一致性与生成质量可视化对比。TC-Light 避免了 (a) 中像 Slicedit 和 COSMOS-Transfer1 那样不自然的重渲染结果和 (b) 中展现出的模糊失真,或 (c) 中像 IC-Light 和 VidToMe 那样的时序不一致性。
此外,我们也在有 GT 数据的仿真数据集 Virtual KITTI 上进行了比较,从而可以使用 SSIM 和 LPIPS 等指标替换 CLIP-T 等代理指标获得更客观的性能评估。表 2 的结果同样表明,我们的算法很好地取得了计算开销和性能之间的平衡,取得了最佳的重渲染效果。

表 2 Virtual KITTI 数据集上与主流算法的定量性能比较
四、总结
TC-Light 作为一种新的生成式渲染器,克服了具身环境下视觉传感器数据重渲染面对的时序一致性和长序列计算开销两大挑战,在性能表现上优于现有技术,不仅为 Sim2Real 和 Real2Real 数据扩展带来了新的思路,也为视频编辑领域带来了新的模型范式。TC-Light 的论文和代码均已开源,希望能够相关领域带来不同的思考和启发。

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com










