
当前视觉导航作为具身智能与自主系统的核心能力,需实现智能体对第一视角视觉输入的解读及目标导向的连续动作选择,但其发展受两大关键问题制约:
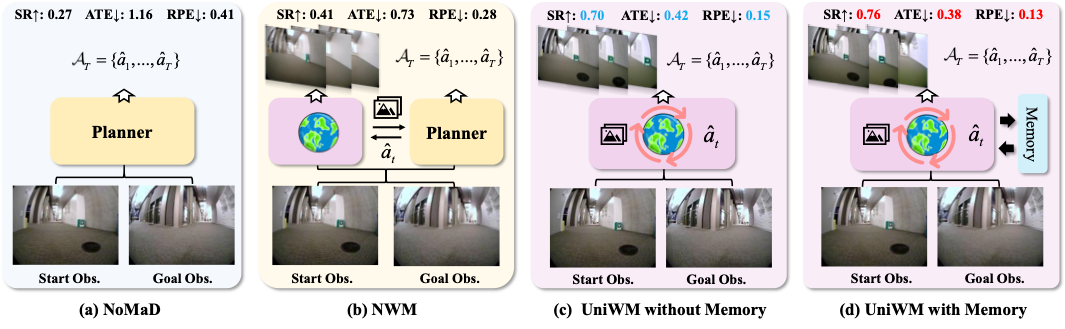
直接策略方法(如 GNM、NoMaD)虽在熟悉环境有效,但过度依赖训练数据,陌生场景适应性差;
模块化方法(如 NavCoT、NWM)将规划器与世界模型分离训练,且缺乏轨迹记忆,导致状态 - 动作错位,长期导航误差累积。
为此,华盛顿大学、卡内基梅隆大学与微软研究院团队,提出 UniWM 统一记忆增强世界模型。让机器人能够在行动过程中实时“想象”未来数步的视觉场景,并基于推演结果规划最优路径。
这一设计将视觉感知、状态记忆与行动决策融合为统一世界模型,成为机器人“看见 - 推演 - 行动”环思考落地的关键突破。

Planner+World model
过去的视觉导航体系往往是“分裂”的:
一边是 planner(规划器),负责决定动作;
另一边是 world model(世界模型),负责预测下一帧视觉。
两个模块分开训练——planner 不知道自己想象的结果是否真实,而 world model 也不了解行动的真实意图。
久而久之,二者逐渐失配。研究者认为,真正的具身智能,应该像人脑那样统一思考:
行动决策与未来想象必须在同一架构内交替进行。

▲图1|UniWM 框架总览©️【深蓝具身智能】编译
于是他们提出了 UniWM,一个多模态自回归架构,在每个时间步交替执行两个子任务:
预测下一步动作(Planner角色)
想象下一帧画面(World Model角色)
为了让推理更稳定,他们又加入了一个关键结构——层级记忆(Hierarchical Memory):
短期记忆负责捕捉当前画面的细节;
长期记忆负责整合跨时间的轨迹线索。
这样,模型不仅能“想象下一步”,还能“记得上一步”,实现真正的连续性推理与视觉一致性。

技术亮点
统一架构:打破“感知—规划”割裂
UniWM 将导航规划(Planner)与世界建模(World Model)融为一体,在同一个多模态自回归 Transformer 中交替完成动作预测与视觉想象。
输入包括起点图像、目标图像、当前位置姿态及过往记忆,模型通过“下一步动作→下一帧画面”的交替生成方式,在一个闭环中完成“想→做→再想”。
这种统一式结构避免了以往模块化系统的“状态—动作错位”,让每一次行动都与模型的视觉想象紧密对齐。
层级记忆机制:短期与长期并行
研究者设计了双层记忆库——
Intra-step Memory:缓存当前时刻的视觉键值对;
Cross-step Memory:累积多个时间步的记忆轨迹;
系统通过两种机制动态融合这两类记忆:
相似度筛选(Similarity Gating) —— 计算当前关键帧与历史记忆的余弦相似度,只选取最相近的 Top-k 条目;
时间衰减(Temporal Decay) —— 对时间更久远的记忆赋予更低权重,以指数衰减方式强化近期观测影响。

▲图2|层级记忆机制示意:模型在每一步开始时,从选定层中提取特征键值(K、V)并存入短期记忆。随后,这些即时信息会与长期轨迹记忆融合:通过“相似度筛选”选出最相关的历史帧,再用“时间衰减权重”控制远近记忆的影响,最终形成融合记忆,用于增强规划与视觉子任务的注意力计算。当当前步结束后,这一短期记忆会附上时间戳并被存入长期库,为下一步推理提供连续上下文。这套机制让 UniWM 能在长时间导航中保持稳定和高效的想象©️【深蓝具身智能】编译
最终,系统将短期记忆与加权的长期记忆拼接成“融合记忆(Fused Memory)”,直接参与注意力计算,从而在多步预测中维持轨迹一致性与时序连贯性。
论文中的实验证明:在四个数据集上,只有同时使用 intra- 和 cross-memory 时,模型才能在长时导航中保持最低误差和最高成功率。
统一训练:离散动作与图像重建的双目标优化
为了在同一模型中同时学习“行动”和“想象”,研究者设计了交替训练策略(interleaved training)。
(1)每个 batch 中同时包含两类样本:
一类用于导航规划(输入当前视角,输出下一步动作);
另一类用于世界建模(输入动作,输出下一帧图像)。
(2)在训练目标上,模型联合优化两个损失:
离散化动作损失(Lplan):将连续的平移与旋转动作量化为 bin token,以多分类交叉熵方式监督每个维度;
图像重建损失(Lworld):在 VQ-token 空间中度量预测视觉 token 与真实编码的距离,
(3)保证生成画面的结构与语义一致性。
这两种损失的协同优化,使模型同时学会“如何走”与“走后会看到什么”。
在推理时,UniWM 按“预测动作 → 想象画面”的顺序循环执行,形成带记忆的交替闭环推理流程,这也是它能在复杂场景下保持稳定行为的关键所在。

▲图3|这张图展示了两种训练目标对性能的贡献:左侧是导航指标,右侧是视觉生成质量。实验发现:加入图像重建损失(Lworld)能提升模型对未来画面的“想象清晰度”;离散化动作损失(Lplan)则直接提高行动决策的准确性;当两者联合使用时,模型在导航成功率与视觉保真度上均达到最佳©️【深蓝具身智能】编译

实验与表现
UniWM 在四个主流导航基准(Go Stanford、ReCon、SCAND、HuRoN)上,成功率(SR)最高提升 30%,轨迹误差(ATE、RPE)显著下降。
特别是在 Go Stanford 数据集上,成功率从 0.45 提升到 0.75。在未见过的 TartanDrive 环境中,UniWM 依然能零样本泛化,无需微调即可完成导航,SR 达到 0.42。

▲图5|多数据集下的导航性能对比:在四个具身导航基准(Go Stanford、ReCon、SCAND、HuRoN)上,UniWM 的成功率(SR)全面领先,轨迹误差(ATE、RPE)最低。无论是短期精度还是长时一致性,UniWM 都显著优于 GNM、VINT、NoMaD 及 NWM 等当前最强基线。其中,带有层级记忆版本的 UniWM 实现了整体最优表现©️【深蓝具身智能】编译
视觉想象质量同样出色:
在 SSIM、PSNR、LPIPS 等指标上全面超越以往世界模型(如 NWM、Diamond),预测画面更清晰、更一致;

▲图4|可视化对比实验:展示 UniWM、NWM 与 NoMaD 三种方法的导航效果。图中轨迹曲线清晰对比了各方法预测路径与真实路径的差异。可以看到,UniWM 的轨迹最贴近真实路线,在复杂场景中保持更平滑、更稳定的运动趋势©️【深蓝具身智能】编译
而引入层级记忆后,长时推理中的画面漂移几乎消失。实验也揭示了几个关键规律:
同时优化“动作离散化损失(Lplan)”与“图像重建损失(Lworld)”效果最好;
层级记忆的跨步部分(Cross-step Memory)对长时稳定性至关重要。

总结
UniWM 让机器人具备了带记忆的想象力。它不再只是被动响应当前视觉,而能主动在脑中构建未来的“视觉剧本”,并据此规划路径。
从具身智能的角度看,这是一个重要的跃迁:它让“世界模型”从单纯的预测工具,变成了行动的思维引擎。
编辑|阿豹
审编|具身君
Ref
论文题目:UNIFIED WORLD MODELS: MEMORY-AUGMENTED PLANNING AND FORESIGHT FOR VISUAL NAVIGATION
论文地址:https://arxiv.org/pdf/2510.08713
项目地址: https://github.com/F1y1113/UniWM
>>>现在成为星友,特享99元/年<<<


【具身宝典】||||
【技术深度】||||||
【先锋观点】|||
【非开源代码复现】||
我们开设此账号,想要向各位对【具身智能】感兴趣的人传递最前沿最权威的知识讯息外,也想和大家一起见证它到底是泡沫还是又一场热浪?
欢迎关注【深蓝具身智能】👇

【深蓝具身智能】的内容均由作者团队倾注个人心血制作而成,希望各位遵守原创规则珍惜作者们的劳动成果。
投稿|商务合作|转载:SL13126828869(微信)

点击❤收藏并推荐本文










