百度百舸 团队 投稿
量子位 | 公众号 QbitAI
随着AI Coding、Agent、Deep Research 等应用快速普及,模型单次处理的上下文长度正在从几万Token迈向几十万甚至百万Token。
一个看似“隐形”的瓶颈正悄然制约着推理效率——
KV Cache(键值缓存)的内存占用随序列长度线性增长,不仅推高显存成本,更直接限制了批量推理的吞吐能力。
对此,百度百舸团队联合复旦大学可信具身智能研究院,在长上下文高效推理方向取得重要进展。

相关成果《Predicting Future Utility: Global Combinatorial Optimization for Task-Agnostic KV Cache Eviction》被机器学习顶会ICML 2026录用。
联合团队提出的LU-KV框架,在80% KV Cache压缩率下,相对性能损失仅0.52%(以Qwen2.5-32B在LongBench 的评测结果为例),在效率–精度权衡曲线上达到新的SOTA水平。
为什么现有方法会“看走眼”?
当前主流的KV Cache压缩方案(如SnapKV、KeyDiff、AdaKV等)通常遵循一个朴素假设:注意力分数高的Token更重要,应该优先保留。
这种“看当前分数大小”的策略在单头内部往往有效,但当预算需要在几十层、几百个注意力头之间分配时,问题就暴露了。
本工作发现,这种「看当前分数大小」的分配逻辑会忽略不同注意力头在长期语义信息保留能力上的差异,容易把缓存预算分配给短期分数高、但长期贡献有限的Token,造成缓存预算与长程信息价值之间的错配。
针对这一问题,团队提出Long-horizon Utility KV(LU-KV)框架,将头级KV Cache预算分配建模为面向长程边际效用的全局组合优化问题。
LU-KV 的核心思路:用“投资回报率”思维重构缓存分配
既然核心瓶颈在于跨头预算分配,LU-KV具体如何运作?
团队并未在单头打分器上做修补,而是构建了一套从“理论标尺”到“全局优化”,再到“工程落地”的完整技术路径,大致拆解为三步。
第一步:立下“真标尺”——定义Oracle Importance,量化认知偏差
要解决预算错配,首先得知道“什么才是真正的重要”。
LU-KV提出 Oracle Importance(真实重要性) 指标,将Token的重要性定义为:
通过前瞻未来K步解码窗口,直接计算每个Token能产生的最大潜在贡献。
这把重要性评估从“单步瞬时注意力”升级为“长程前瞻效用”。
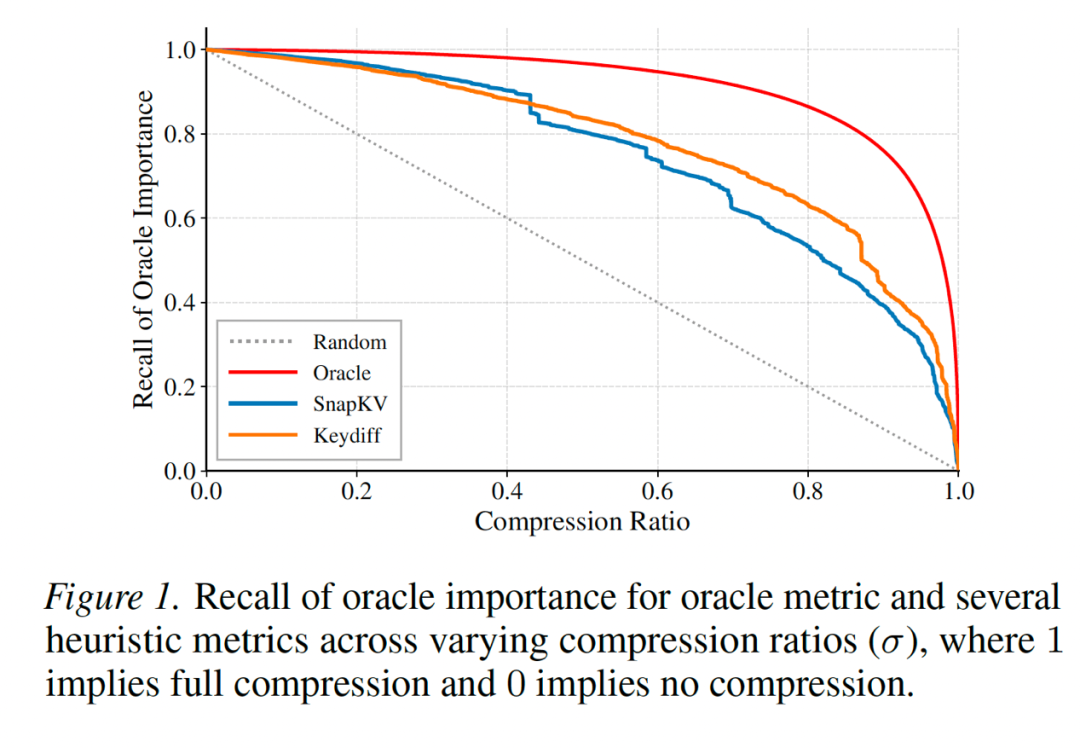

有了这把标尺,团队首次严格量化了现有启发式指标与真实重要性之间的 “最优性差距(Optimality Gap)”,证明了盲目按瞬时分数分配预算必然导致长期语义流失,也为后续的优化提供了明确的数学靶心。

第二步:解“全局题”——凸包松弛+贪心策略,将非凸难题转化为高效求解
有了衡量偏差的标尺,预算分配就不再是凭感觉“分蛋糕”,而是一个明确的全局组合优化问题:
如何在总预算固定的约束下,让所有注意力头的长期信息保留总损失最小?该问题本质上是 NP-hard 的非凸离散优化。
为此,团队引入凸包松弛(Convex-hull Relaxation)技术,将原本波动的损失曲线“熨平”为边际收益严格递减的平滑函数。
这一数学变换使得复杂的组合优化问题具备了单调性,从而可以用基于边际效用的全局贪心算法快速逼近最优解。
如下图所示,在凸包松弛下,原本NP-hard的非凸离散优化问题被转化为边际收益严格递减的平滑形式。
此时,采用全局贪心算法求解所得的结果,与动态规划(DP)求解原始组合优化问题的最优解高度吻合。
换言之,系统能自动算出:把下一个Token的缓存配额分给哪个头,才能最大化长程语义的保留收益。

第三步:过“落地关”——离线画像+在线查表,让理论最优实现零开销部署
有了衡量偏差的标尺,预算分配就不再是凭感觉“分蛋糕”,而是一个明
理论上求出了最优分配策略,但直接在线计算Oracle Importance和实时优化,会带来不可接受的推理延迟。
如何让算法真正走向生产?团队抓住了大模型的一个关键特性:不同注意力头的全局-局部压缩率比例,在各类任务中呈现出高度的结构稳定性(如下图所示)。

基于这一洞察,LU-KV设计了数据驱动的离线Profiling 协议:
在部署前,用合成数据预计算每个头在不同压缩率下的最优预算比例,生成一张静态查找表。
在线推理时,系统只需根据目标压缩率“查表”获取各头预算,随即执行独立驱逐。
从理论优化到工程实践,LU-KV成功将复杂的在线计算转化为O(1)的查表操作,实现了真正的零开销部署。
值得一提的是,LU-KV并不替代底层的Token打分方法,而是作为通用的预算分配层,可即插即用适配SnapKV、KeyDiff等多种压缩指标,具备良好的工程兼容性与迁移能力。
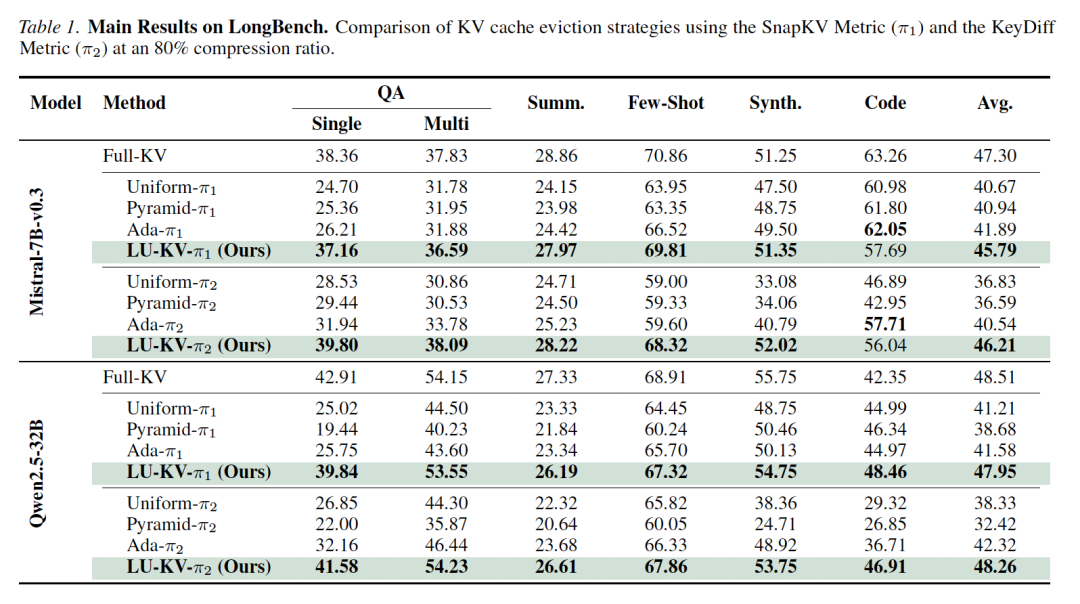
实验数据:压缩 80%,性能几乎不打折
团队在Mistral-7B-Instruct-v0.3和Qwen2.532B-Instruct中评价了该方案,使用Snapkv和KeyDiff作为两种KVCache重要性评价指标,与PyramidKV,AdaKV这类Budget SOTA分配方案进行了对比。对比结果如下:
LongBench上:在80%压缩率下,该方法有效最小化了总体逐出损失,从而带来了显著的精度提升。
在Mistral-7B-v0.3模型上结合KeyDiff方法,该方法将平均准确率从40.54 (AdaKV) 提高到46.21,恢复了压缩模型与Full-KV上界之间84%的性能差距。
重要的是,这些提升在多个领域(从摘要到合成任务)中都很稳健,表明学习到的压缩分布成功捕捉了每个领域的细微差别。
相比之下,在相同的80% 压缩率下,该方法实现了69.98%的平均准确率。值得注意的是,在具有挑战性的multi-key-3任务上,该方法将性能从1.00%(均匀压缩)提升至67.40%,显示出在保留稀疏但关键信息方面的强大鲁棒性。

更多细节,请见ICML 2026论文或访问GitHub项目主页。
论文链接:https://icml.cc/virtual/2026/poster/65241
项目主页:https://github.com/baidu-baige/LU-KV
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
— 完 —
我们正在招聘一名眼疾手快、关注AI的学术编辑实习生 🎓

🌟 点亮星标 🌟