
> 本文来自社区投稿
引言
GTA-2 将智能体评测从原子级工具调用扩展到长程开放式工作流,在结果导向的评估框架下,统一衡量模型能力与执行框架(agent harness)的系统级表现。实验发现前沿模型工具调用率超 90%,但端到端任务完成率仅 14.39%,而执行框架的设计差异可带来数量级的性能提升。

论文标题:GTA-2:Benchmarking General Tool Agents from Atomic Tool-Use to Open-Ended Workflows
作者团队:本篇论文由上海交通大学与南洋理工大学联合完成,指导团队包括上海交通大学关新平教授、陈彩莲教授、乐心怡教授,以及南洋理工大学陶大程教授。合作者还来自上海人工智能实验室和腾讯。第一作者王骥泽为上海交通大学博士生,研究方向为大模型智能体;共同第一作者刘萱暄为上海交通大学 John Hopcroft Class 本科生,研究方向为多智能体协同与人机交互。
论文链接:https://arxiv.org/abs/2604.15715
代码与数据:https://github.com/open-compass/GTA
研究背景:工具调用不等于完成任务
大模型智能体快速发展的这两年,工具调用能力已经成为核心指标。从搜索、计算到图像处理和代码执行,语言模型通过调用外部工具,已经能够完成越来越复杂的任务。以 Manus、OpenClaw、Kortix 等为代表的系统不断涌现,推动智能体从"会用工具"走向"能完成任务"。
然而,当这些能力真正落地到现实场景时,一个问题逐渐显现出来:模型会用工具,并不代表它能把事情做完。
现有评测体系大多围绕过程层面的正确性展开——工具选择是否合理、参数是否准确、步骤是否符合预期。但真实世界中的任务往往并不是这样。让一个智能体完成一份数据分析报告,它需要读取表格、计算指标、绘制图表、整合内容,并最终生成结构化文档。整个过程包含多个阶段,路径并不唯一,评判标准也变成了"最终结果是否真正满足需求"。
正是在这个意义上,评测目标正在从工具调用能力,转向端到端任务完成能力。这一转变也使得模型能力之外,系统层的执行框架(即 agent harness)开始发挥越来越重要的作用。
GTA-2:从原子工具调用到真实工作流
在此前 NeurIPS 2024 提出的 GTA 基准(GTA: A Benchmark for General Tool Agents)中,研究团队已经通过真实用户问题、真实工具和多模态输入,评估了模型在复杂场景下的工具使用能力。系统性实验揭示了一个关键瓶颈:即使是最强大的 GPT-4,在真实场景中也难以完成超过一半的任务。
在此基础上,GTA-2 进一步关注一个更根本的问题——当任务从"调用工具"扩展为"完成完整工作流"时,现有智能体是否仍然具备稳定的任务完成能力?
GTA-2 将评测体系拆分为两个层次。一方面保留原有 GTA(在 GTA-2 中称为 GTA-Atomic),用于评估短流程的工具调用能力;另一方面引入全新的 GTA-Workflow,面向长流程、开放式的真实任务。相比只关注单步或短链条调用,GTA-2 更进一步追问:在一个完整任务中,智能体能否真正把事情做完。

面向真实生产力场景的工作流评测
GTA-Workflow 的设计直接对齐现实中的生产力场景,评测围绕最终交付结果展开。一个典型任务可能要求智能体分析一份 Excel 数据,计算关键指标,生成多种图表,并最终输出结构完整的 PDF 报告;又或者需要结合网页检索与文档信息,整理并生成一份完整的方案说明。这类任务跨越多个工具与多种模态,允许不同的解决路径。
与原 GTA 相比,GTA-Workflow 在多个维度都有明显扩展。输入从图像与文本扩展到 PDF、CSV、XLSX、PPT 乃至音频与视频,工具数量从 14 个增加到 37 个,覆盖感知、操作、逻辑与创作四大类能力。任务结构也从短链条调用,演变为包含多个阶段和子目标的长流程工作流。更关键的是,评测目标从"过程是否符合预期",转向"结果是否真正可用"。
这种以最终交付为中心的评估方式,使 GTA-2 能够同时衡量两类能力:一是模型本身的推理与工具使用能力,二是智能体系统(即 execution harness)在复杂任务中的组织与执行能力。

数据集构建:从真实需求到可评测任务
为了让工作流任务真正贴近实际应用,GTA-Workflow 并没有依赖纯人工设计,而是从真实世界中收集需求,再进行系统化重写。一部分任务来源于当前主流的智能体系统(Manus、Kortix、Minimax Agent、CrewAI、Flowith 等)中的真实案例,直接反映了当前 agent 在复杂任务中的能力边界。另一部分则来自 Reddit、Stack Exchange 等社区中的用户问题,更开放、更接近真实使用场景。
在此基础上,研究团队对原始任务进行了重写与扩展,使其能够在统一环境中稳定执行,并具备清晰的评测标准。最终得到的任务既保留了现实需求的特征,又能够支持系统化评估。
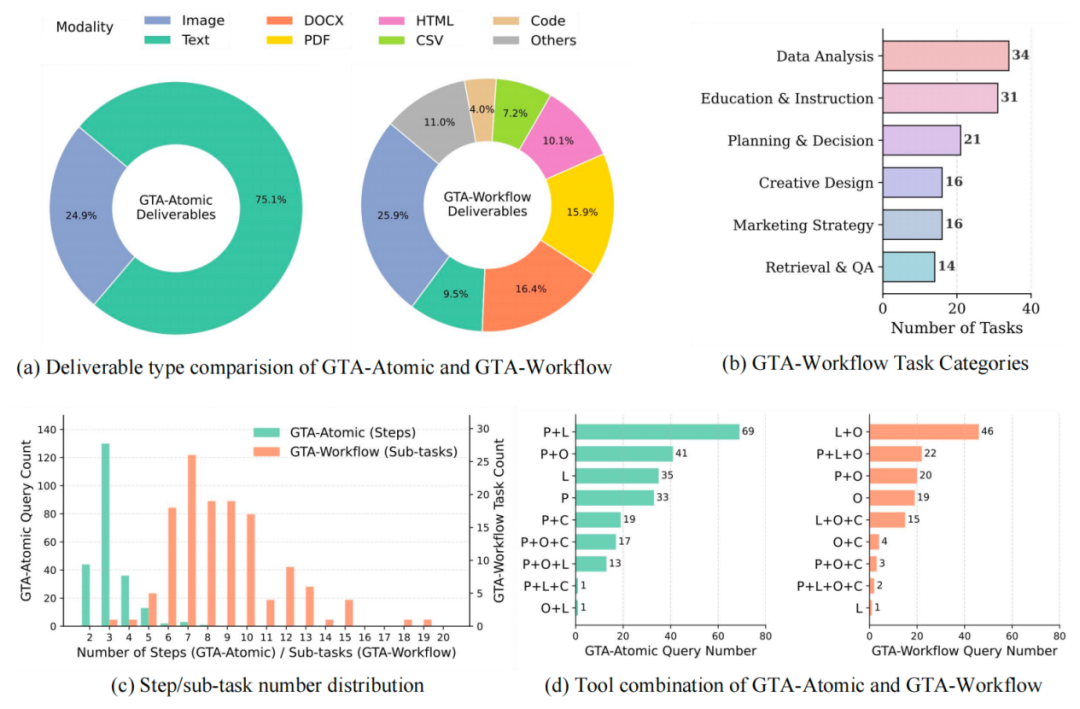
与 GTA-Atomic 相比,GTA-Workflow 在任务模态和复杂度上都有明显提升:从以感知为主的短流程闭式任务,转向以操作与执行为核心的长流程开放式工作流,对智能体提出了更高要求。

最终构建的数据集包含 132 个 GTA-Workflow 任务(相比 GTA-Atomic 的 229 个),涵盖数据分析与可视化、教育辅导、规划决策、创意设计、营销策略、检索问答六大类。每个任务包含平均 8.5 个子任务,总子任务数达 1156 个,工具调用总步数超过 3000 步。任务的交付物形式也极为多样——从文本、图片、音频、视频到代码、PDF、HTML、CSV、PPTX、JSON 和 Markdown,几乎覆盖了所有常见的生产力产出格式。
Checkpoint 评测:没有标准答案也能打分
当任务变成开放式工作流之后,一个新的问题随之出现:如果没有固定步骤,也没有唯一答案,该如何进行评测?GTA-2 给出的核心思路是:将任务拆解为一组可验证的目标。
每个任务被分解为一系列 checkpoint,描述的是最终结果需要满足的条件,而非执行过程中必须遵循的步骤。评测时,只需根据这些目标判断最终产出的结果是否达标。例如在一个报告生成任务中,可以从数据分析是否正确、图表是否合理、内容是否完整等多个维度进行评估,而无需限制模型必须按照某一条固定路径完成任务。
这种设计带来了两个关键变化。一方面,评测从对过程的约束转向对结果的验证,使得开放式任务具备了可评估性;另一方面,它天然适配不同的 agent 系统——无论底层模型或执行策略如何,只要最终结果满足目标,就可以在统一标准下进行比较。
实验结果:高工具调用率 ≠ 高任务完成率
在 GTA-2 的大规模实验中,研究团队系统评测了当前主流的前沿模型及多种 agent 系统。结果揭示了一个显著的能力鸿沟:当前模型在原子工具调用(GTA-Atomic)上的表现已经达到较高水平,但在工作流任务(GTA-Workflow)上的完成率却断崖式下跌。
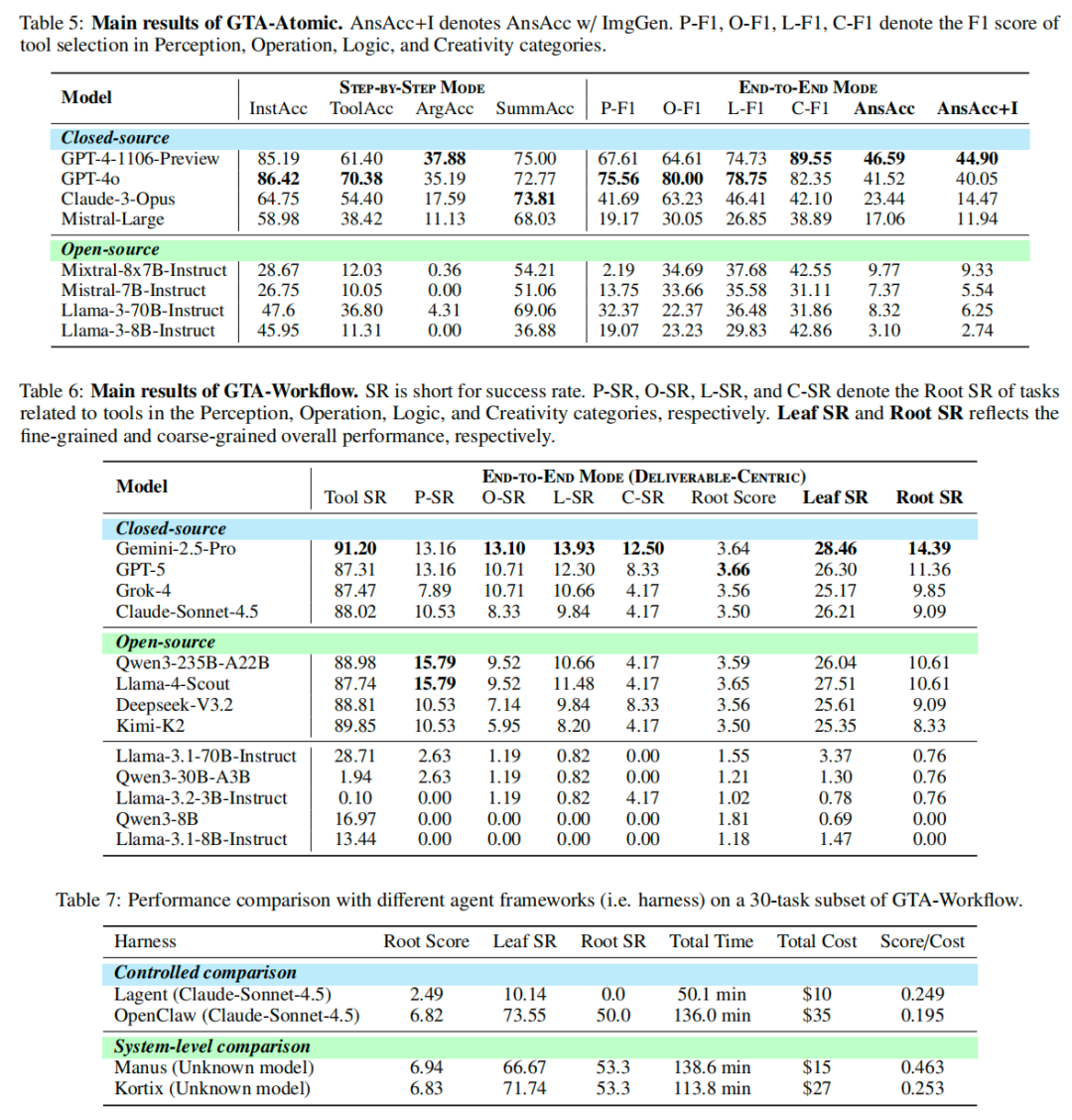
在 GTA-Atomic 上,GPT-4o 和 GPT-4.1-Preview 等闭源模型的回答准确率(AnsAcc)分别达到 89.55% 和 87.40%,但在 GTA-Workflow 中,表现最好的 Gemini-2.5-Pro 的根成功率(Root SR)仅为 14.39%,尽管其工具调用成功率(Tool SR)高达 91.20%。这一悬殊差距说明:高水平的工具调用能力并不能自然转化为稳定的端到端任务完成能力。
进一步的分析揭示了失败发生的深层原因。失败主要集中在执行阶段(EXECUTE,占比约 34%)和最终交付阶段(HANDOFF,占比约 20%),而推理阶段的错误(REASON)仅占 3%–7%。这表明当前模型并非缺乏推理能力,而是在长流程执行中难以维持稳定的工具交互和最终交付物的构建。
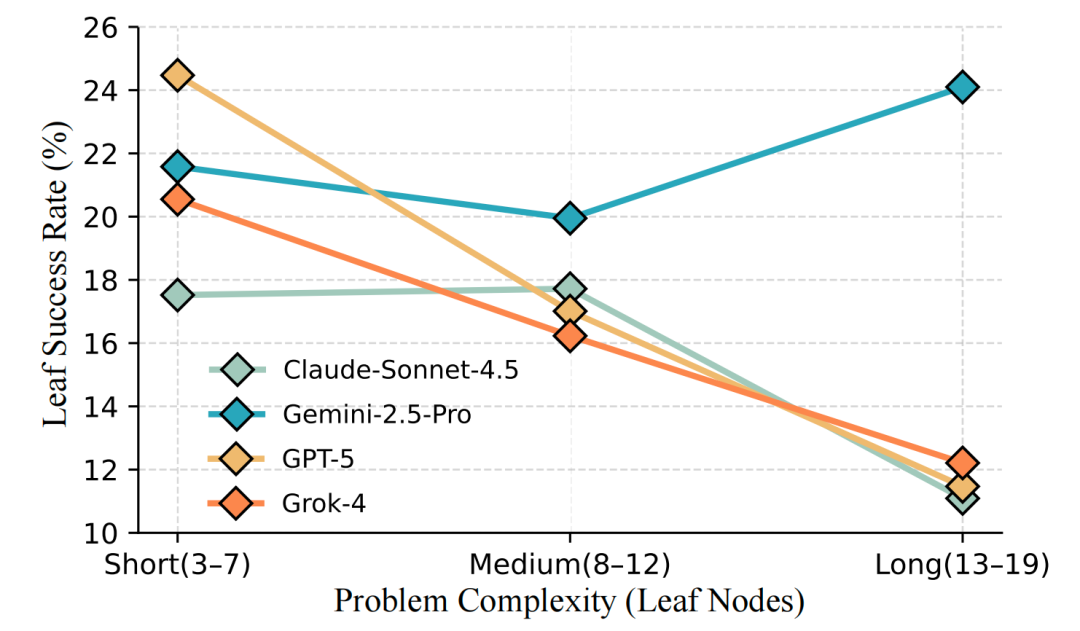
随着任务复杂度提升——从 3–7 个子任务增加到 13–19 个——模型性能持续下降,多阶段协调与长期依赖管理成为限制系统表现的关键因素。

此外,我们观察到,引入 checkpoint 作为阶段性反馈,可以在一定程度上提升任务完成率。这一结果说明,模型并非缺乏完成复杂任务的能力,而是在长流程执行中缺少有效的中间约束与目标引导。Checkpoint 在此可以被视为一种弱形式的结构化规划信号,有助于稳定执行过程。然而,这种提升仍然有限。即使引入 checkpoint,整体成功率依然显著低于理想水平,说明长流程任务中的问题本质上属于系统级挑战,难以通过单纯的提示或反馈机制彻底解决。
执行框架决定上限
GTA-2 的另一个核心发现是:模型能力之外,执行框架对最终性能具有决定性影响。
在控制变量实验中,研究团队固定模型为 Claude-Sonnet-4.5,仅替换执行框架——从默认的 Lagent 切换到 OpenClaw。结果显示,任务成功率从 0% 提升至 50%,子任务完成率(Leaf SR)从 10% 提升至 73%。在相同模型能力下,仅通过系统层设计的改变,即可带来数量级的性能提升。
这一现象在真实系统评测中同样成立。Manus 和 Kortix 等完整的 agent 系统,在开放式工作流任务中均能稳定达到 50% 以上的成功率,显著优于"单模型 + 简单框架"的基线表现。这些系统通常具备更完整的执行机制,如显式规划、持久记忆以及多步协调能力。值得注意的是,这些能力并不直接来源于模型本身,而是由执行框架在系统层进行组织与实现。从这个角度看,长流程任务的性能上限,已经不再仅由模型能力决定,而是取决于模型与执行框架之间的协同方式。
失败到底发生在哪里?
为了进一步理解长流程任务中的性能瓶颈,研究团队对失败案例进行了细粒度拆解。结果显示,错误主要来自两个层面。首先是执行阶段——在多步工具调用过程中,系统容易出现不稳定行为,局部错误在后续步骤中逐步累积并放大,最终影响整体结果。其次是最终结果构建——即使中间步骤大致正确,最终生成的报告、文件或输出,仍可能在结构、格式或内容完整性上不满足要求。

更精细的三层失败分析揭示了更清晰的结构。子任务(leaf-level)错误只是问题的一部分,更关键的瓶颈出现在中间结果的组合(composition)以及最终结果的构建(deliverable)。在前沿模型中,最终结果层面的失败率甚至可以达到 70%–80%。这些结果表明:长流程任务的难点并不在于单步决策,而在于跨步骤的一致性与整体组织能力。
哪些能力最难?
从能力维度来看,不同类型任务的难度存在明显差异。模型在感知(Perception)和逻辑(Logic)相关任务上表现相对较好,而在操作(Operation)和创作(Creativity)类任务上明显更弱。这类任务通常涉及复杂文件操作、多工具交互以及结果整合,是当前系统最容易失败的场景。

从结果形式来看,文本类产出(如 PDF、HTML)相对容易,而结构化数据(CSV、XLSX)和 PPT 等格式明显更难——因为这些任务不仅要求内容正确,还要求严格的结构与格式约束。
这些实验带来的启示
综合以上结果,GTA-2 揭示了一个关键转变:通用智能体的性能,正在从单一的模型能力问题,转向模型与系统协同设计的问题。
在短流程任务中,模型已经能够在局部做出较为可靠的决策;但在长流程工作流中,瓶颈逐渐转移到系统层面,包括多步执行的稳定性、中间状态的持续管理,以及最终结果的构建与整合。这表明,局部正确并不能保证整体成功,真正的挑战在于如何将一系列中间步骤稳定地组织为一个可用的最终结果。
这一趋势也带来了一个重要启示:未来的进展,不仅依赖于更强的模型能力,也取决于更高效的 agent 系统设计,以及更贴近真实任务的评测范式。
总结
GTA-2 在评测范式上实现了一次关键拓展:将工具智能体的评估从原子级闭式调用,推进到面向开放式工作流的端到端任务;从单一模型能力的衡量,扩展到对完整智能体系统的评估;从过程约束,转向以最终结果为核心的评价方式。这一变化使评测更贴近真实应用场景,也让模型能力与系统设计能够在统一框架下被同时衡量,为下一阶段 agent 系统的发展提供了更加可靠的参考基础。
-- 完 --
机智流推荐阅读:
1.
2.
3.
4.
cc | 大模型技术交流群 hf | HuggingFace 高赞论文分享群 lc|LangChain 技术交流群 code | AI Coding 交流群 具身 | 具身智能交流群 硬件 | AI 硬件交流群 推理 | AI 推理框架交流群 Agent | Agent 技术交流群









