PAPERSCOPE × 机智流 · 联合出品
Loop 时代到来:世界模型走向 Physical AI
本周 193 篇 HF Daily Papers · 5 大信号 · 代表论文带「🤔 真正的 insight」

JoyAI-VL 实时视觉-语言交互智能(本周 #1,191 票)
本周 HF Daily Papers 共 193 篇。我们读完 top 30 + 重点 paper card 全文,得到一句话判断——AI 正在从「卷模型」走向「卷系统」,三条主线和两条暗线同时浮出水面。
⏱ 30 秒读完本周报(TL;DR)
| 算法工程师 | |
| 截图 |
🎯 本周一句话
2026 年的 AI,关键词从「炼丹」换成了「建基建」。
模型不再卷深度,改卷循环次数;
视频生成长大了,长成了 Physical AI 的世界模拟器;
agent 不再是 prompt+tool 拼出来的,它有了自己的 harness 和操作系统。
——本周 193 篇 HF 论文,把这三件事推到了同一个时间点。
5 个信号,本周交汇
💎 本周 7 句金句(截图传播友好)
1. Loop 是 chain-of-thought 的下一代——它把循环写进了模型架构里。
2. World Model 不再是 video gen 的"升级版",它是 Physical AI 的环境模拟器。
3. Agent 从手工作坊进入工业化——主角换人了,从 reasoning 算法换成 harness、orchestration、observability。
4. 可验证推理与不可验证推理正在拉开 scaling 差异:前者 3B 就够,后者还得堆。
5. 静态 benchmark 都是 Markov 的,但现实从来不是——这是 benchmark 与现实之间最大的 gap。
6. 模型的"记忆"不是 retrieve,是 reconstruct——RAG 这一代假设错了。
7. 让 model 自己决定何时开口,整个 conversational UX 就变了。
💡 可分享元素:5 信号表 + 7 金句,配合开篇排比段,任意一段单独截图都自带钩子。
写在前面(3 个反直觉)
1. "更大就更强"这句话不再万能。 3B 参数的 VibeThinker 在可验证推理上做到了 frontier;0.2B 参数的 Moebius 在图像 inpainting 上做到了 10B 级别表现。本周两个独立工作同时把"参数效率"这条边界往前推了一大截。
2. 世界模型不再是视频生成的副产品。 从 LoopWM 的最高 100× 参数效率(论文原话 "up to 100x"),到 DreamX-World 的可交互长 horizon,再到 Kairos 直接自称"Physical AI 的原生世界模型 stack"——业界已经把 world model 当成了具身、机器人、游戏 agent 的基础设施,而不是"更高级的 Sora"。
3. Loop(循环计算)正在悄悄替代深度。 LoopCoder-v2、LoopWM 都把循环次数(loop count)当成了一个显式的设计自由度——一次预测要 loop 几次,由模型、任务、cost 共同决定。Test-time scaling 这条路,今年从 chain-of-thought 进化成了 chain-of-loops。
📊 数据速览
| 论文总数 | 193 篇 | |
| 最高 upvotes | 191 | |
| 评论最热 | 8 条 | |
| Top 主题 |
📈 每日产出趋势(柱状图)
📊 节奏解读:周一开高(48)→ 周三回落(31)→ 周四回升(37)。HF 编辑团队的"周中节奏"很稳——周一蓄势、周三换气、周四再发。建议把 周一早上和周四晚上 设为 Daily Papers 的优先查看时段。
🔥 本周高热度论文(≥ 5 评论)
🔁 趋势一 · Loop 时代来了
把模型"做深"换成把 block"反复跑"——同样的算力,能打更难的题。
过去一年我们听够了 chain-of-thought。但本周 3 篇 top 论文,把"循环"这件事推到了模型架构层面——模型本身就是一个 loop,而不是 loop 跑在模型外面。
📜 这条线的历史脉络
·2019 Universal Transformer 首次提出 weight sharing + 自适应深度,但训练不稳,没成主流。
·2024 Looped Transformer 系列工作(CMU / Princeton)让 loop 在算法推理任务上重新引起关注,但停留在 toy benchmark。
·2025 Test-time compute scaling 成为热词(o1 / DeepSeek-R1 类),思路是"推理时多算几步",但靠的是 prompt + 验证。
·2026 本周 LoopWM / LoopCoder-v2 把 loop 从"训练 trick"变成显式架构参数——loop count 像 layer count 一样可以在论文里画曲线。
这条线从"理论玩具"到"主流架构"用了 7 年。本周的拐点是:有人开始用 7B 体量的实证工作系统比较不同 loop count 的 gain-cost——这意味着 loop 进入了"工程优化期"。
💡 真正的 insight
把模型做深是有代价的:显存、延迟、训练成本都跟着层数线性涨。而 looped transformer 是另一个思路:只造一个 block,让它反复跑。一次预测里跑几次,由任务复杂度决定;越难的样本自动 loop 更久。这是把"算力"从"weight 参数量"解耦到"inference loop 次数",意味着同样的模型,跑 100 步推理和跑 5 步推理可以表达完全不同的能力。
🛠 学到什么:loop 是一个架构设计选择——LoopCoder-v2 等 PLT 模型在训练时就把 loop count 固定下来;LoopWM 这类则在 inference 时根据预测难度自适应深度。两条路径的共同信号:当你设计一个新模型时,"做更深" 不是唯一杠杆,"做能反复跑的浅 block" 是新选项。
代表论文
🥇 Looped World Models (LoopWM)
172👍 · 当周第 2
2606.18208|HF: https://huggingface.co/papers/2606.18208
做了什么: 在 world model 上做参数共享的 looped transformer,最高 100× 参数效率(论文原话 "up to 100x",是上限不是均值),深度根据预测难度自适应。
🔍 学到什么:
·"compounding error" 是 long-horizon world model 老大难——loop 给了一个新解法:短模型多 loop 几次,比一个深模型一次过更稳。
·"depth = quality" 不再绝对正确,"loop count = quality" 是新轴。
💡 真正的 insight:world model 不需要"真的很深",它需要"能反复看自己刚才生成的"。循环就是反思。
🥈 LoopCoder-v2: Only Loop Once for Efficient Test-Time Computation Scaling
138👍
2606.18023|HF: https://huggingface.co/papers/2606.18023
做了什么: Parallel Loop Transformer(PLT),通过 cross-loop position offsets(CLP)和共享 KV gated sliding-window attention,让 loop 不再串行,loop count 真正成为可调超参数。
🔍 学到什么:
·Loop 的最大问题是 KV-cache 爆炸——这篇用 sliding window + 共享 KV 把 cost 压下来。
·训练时发现一个"gain-cost" 曲线:多 loop 一次有信息增益,但 CLP 引入位置失配;存在最优 loop 数。
💡 真正的 insight:"loop 次数"不是越多越好,存在一个 sweet spot——这跟 chain-of-thought 越长越好(直到 saturate)的直觉相反。
🥉 JoyAI-VL-Interaction: Real-Time Vision-Language Interaction Intelligence
191👍 · 当周第 1
2606.14777|京东|HF: https://huggingface.co/papers/2606.14777
做了什么: 一个始终在场的视觉-语言模型——它持续看视频流,自己决定是否开口(而不是被 prompt 触发)。从 turn-based 走向 streaming。
🔍 学到什么:
·这论文的"loop"是更高阶的——整个 agent 是一个 perception-decision loop,每帧都判断"现在该不该说话"。
·落地数据形式:实时 livestream 评论、安防摄像头自动告警、视频通话自动 summarize。
💡 真正的 insight:turn-based 不是 LLM 的限制,是交互范式的限制。让 model 自己决定何时回应,整个 UX 就变了。这才是 conversational AI 的下一步。
💎 趋势一一句话记忆:Loop 把循环写进了模型架构里——test-time scaling 从此不只是 prompt 工程,是架构选择。
🌍 趋势二 · 世界模型走出"视频生成"
它不再是更高级的 Sora,是机器人、具身、游戏 agent 的环境模拟器——Physical AI 的基础设施。
本周 4 篇代表论文都在把 world model 从"高级版视频生成"重新定位为"agent 的环境模拟器"。
📜 这条线的历史脉络
·2018 World Models 论文(Ha & Schmidhuber)首次系统提出"agent 在压缩的潜在环境里学习",但只在简单游戏上 work。
·2023 Dreamer 系列(V1-V3)+ Genie 把 world model 推进到 game generation,但没人把它当成"环境",只当成"视频生成器"。
·2024-2025 RT-2 / OpenVLA / Pi 等 VLA 模型崛起,但 action 端是 control policy,环境端还是 closed-loop simulator(MuJoCo / Isaac)。
·2026 本周 Kairos / DreamX-World / LoopWM 三篇同时出手,定位都是 "给 Physical AI 当环境的 world model"——这是数据基建从控制端转向感知端的信号。
转折点:当 VLA 的瓶颈从 policy 变成 environment data 时,world model 就从"视频生成的高级品"重新被定义为"环境模拟器"。本周三篇是这个转折的标志。
💡 真正的 insight
视频生成是"看",世界模型是"看 + 想 + 行动"。当 world model 学会响应 action 输入并生成下一帧时,它就不再是 visual decoder,而是 environment simulator——这正是机器人和具身 agent 缺的那一块。本周 Kairos 干脆把这个产品形态叫做 "Native World Model Stack for Physical AI",意图很明显:占住 robotics 的基础设施 layer。
🛠 学到什么:自家场景如果有视频流 + action 数据(机器人、自动驾驶、游戏、AR),现在是开始训练任务专属世界模型的窗口期。RT-1 / VLA 那一代是 control policy,下一代是 world simulator + plan。
代表论文
DreamX-World 1.0: A General-Purpose Interactive World Model
102👍 · 7 评论
2606.16993|HF: https://huggingface.co/papers/2606.16993
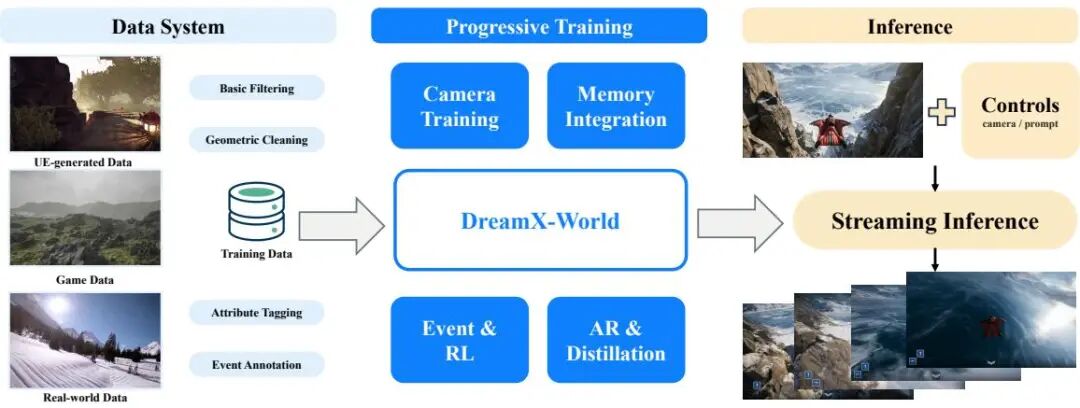
通用文/图生视频,支持相机导航 + 重访已观察区域 + 可控事件。数据 engine 融合了 Unreal Engine 渲染、游戏录像和真实视频。
🔍 学到什么:long-horizon generation 的难点不是"画得好",是"记得住"——它必须知道 5 分钟前 camera 看过的地方,下一次回去时长什么样。这是 world model 与 video model 的本质区别。
Kairos: A Native World Model Stack for Physical AI
32👍
2606.16533|HF: https://huggingface.co/papers/2606.16533
定位很直接:Physical AI 专用的 world model stack,不是泛用 video model。
💡 insight:标题里 "Native" 是关键——意味着 stack 从数据采集、训练、推理、部署都是针对物理交互场景的,而不是把 video gen 模型硬塞过来。
Geometric Action Model for Robot Policy Learning
108👍 · 3 评论
2606.17046|HF: https://huggingface.co/papers/2606.17046

之前的 VLA / WAM 主要在 2D 图像或 2D-derived latent 上跑,implicit 处理 3D。这篇直接把 pretrained geometric foundation model 改造成 manipulation policy,explicit 3D。
💡 insight:contact-rich manipulation(拧螺丝、抓鸡蛋)需要 3D 几何信息——2D 视觉 + 隐式 latent 不够,必须 explicit。这是机器人学界今年最重要的方法论争论。
ACE-Ego-0: Unifying Egocentric Human and Robotic Data for VLA Pretraining
44👍
2606.17200
把第一人称人类视频(egocentric, Ego4D 之类)和机器人数据统一到一个 VLA pretraining 框架里。
💡 insight:机器人数据贵,人类第一人称视频便宜。把两者放到一个 pretraining 里,用人类视频学 "看",用机器人数据学 "动"——这是 VLA 数据 scaling 的捷径。
💎 趋势二一句话记忆:世界模型不是"高级 Sora"——它是 Physical AI 的环境模拟器,机器人/具身/游戏 agent 共用的基础设施。
⚡ 趋势三 · 小模型摸到 verifiable reasoning 的天花板
3B 做可验证推理 frontier,0.2B 做 10B 级别 inpainting——"参数效率"被重新定义。
"小模型挑战大模型"年年说,今年的 differentiation 在于:verifiable reasoning(可验证推理) 的边界确实被压到了 3B。
📜 这条线的历史脉络
·2023 LLaMA-7B / Mistral-7B 时代,小模型靠 SFT 跟大模型差一大截。
·2024 Phi-3 系列首次证明"高质量数据 + 小参数"可以做到中端推理水平,但仍依赖数据 curation。
·2025 DeepSeek-R1 distill 系列把 RL 蒸馏推到 7B 规模——但需要先有一个"大教师模型"。
·2026 本周 VibeThinker-3B 走了完全不同的路:没有教师模型,直接 Spectrum-to-Signal 三步训练(curriculum SFT → multi-domain RL → offline self-distillation),3B 单模型自验自学,达到 frontier。
这是从"借大模型力量"到"小模型自洽训练"的拐点。Moebius 0.22B 在 inpainting 上的成功,证明这一路径在视觉任务上同样 work。
💡 真正的 insight
传统观念:reasoning 难,要大模型。本周两篇论文给出反证——只要 任务有可验证 ground truth(数学、代码、逻辑),3B 模型通过 curriculum SFT + multi-domain RL + self-distillation 也能做到 frontier。可验证推理与不可验证推理(写作、判断、品味)正在拉开 scaling 差异:前者参数效率正在被 push,后者还是吃模型规模。
🛠 学到什么:公司内部部署 LLM 时,先分清场景——数学 / SQL / 代码 / 规则推理 → 试 3-7B 模型 + 强 RL 训练;自由写作 / 品味判断 / 复杂博弈 → 仍需大模型。一个 router 把任务分流,成本可降一个数量级。
代表论文
VibeThinker-3B: Exploring the Frontier of Verifiable Reasoning in Small Language Models
98👍
2606.16140|HF: https://huggingface.co/papers/2606.16140
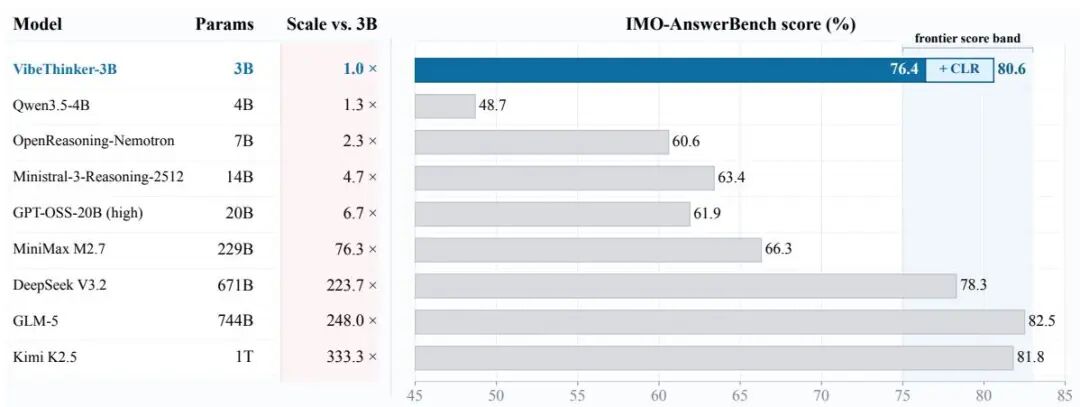
3B dense 模型,Spectrum-to-Signal post-training,达到 frontier-level verifiable reasoning。
🔍 学到什么:
·"Spectrum-to-Signal" 直观是:把 SFT 数据按难度铺成谱(spectrum),然后 RL 把信号提出来。
·Pipeline 是 curriculum SFT → multi-domain RL → offline self-distillation。这三步可以套用到任何 reasoning 小模型训练上。
Moebius: 0.2B Lightweight Image Inpainting Framework with 10B-Level Performance
98👍
2606.19195|HF: https://huggingface.co/papers/2606.19195
0.22B 参数(论文原文,约 0.2B)达到与 11.9B 工业旗舰 inpainting 模型相当或略超的表现,同时推理速度 >15× 加速。核心是 Local-λ Mix Interaction 模块(LλMI)重构 diffusion backbone。
💡 insight:专项 specialist + 结构创新 可以打平通用 generalist。若产品场景固定(修图、抠图、商品图增强),训练专属 0.2B 比调 API 性价比高得多。
💎 趋势三一句话记忆:可验证推理与不可验证推理正在拉开 scaling 差异——前者 3B 够,后者还得堆。任务分流是 cost 优化的第一杠杆。
🤖 趋势四 · Agent 从手工作坊走进工业化
prompt + tool 是去年的事——今年拼的是 harness、orchestration、observability,是 agent 的"操作系统"。
"prompt + tool" 是 2024 年的 agent。2026 年的 agent 是 harness foundry / context engineering / orchestration——属于工程基础设施。
📜 这条线的历史脉络
·2023 AutoGPT / BabyAGI 引爆 agent 概念,但全部是"prompt 拼接 + 简单 ReAct",可观测性近乎为零。
·2024 AutoGen / CrewAI / LangGraph 让 multi-agent 系统第一次工程化,关键词是"graph 编排 + state 管理"。
·2025 DSPy 提出"agent = program with optimizable components",把 agent 训练当成编译器问题。
·2026 本周 HarnessX 自称 "foundry"(铸造厂)、Orchestra-o1 做 omnimodal orchestration、Ling and Ring 在万亿参数尺度做 agentic inference engineering——三篇同时把 agent 推到生产基础设施这一层。
"foundry" 这个词最关键——意味着行业默认 agent 已经进入 mass production 阶段,需要量产模板、配置化、监控化。这跟"每个 agent 是手工小作坊"的 2023 年是两个时代。
💡 真正的 insight
去年大家在拼 agent 的 reasoning 能力(哪个能解题更好);今年拼的是 agent harness 的可组合性、可适配性、可演化性。把 agent 想成一个软件项目:reasoning 是它的"算法",harness 是它的"操作系统"。本周 HarnessX 直接叫自己 "foundry"——这是行业语言,已经默认 agent 进入了平台/基础设施层。
🛠 学到什么:若已经在用 LangGraph / AutoGen / DSPy 搭 agent,建议读 HarnessX、Orchestra-o1、Ling and Ring 这几篇,至少抽出 3-5 个工程模式:context 管理、tool 选择、多 agent orchestration、failure 恢复、observability。这些模式独立于具体框架。
代表论文
HarnessX: A Composable, Adaptive, and Evolvable Agent Harness Foundry
42👍
2606.14249|HF: https://huggingface.co/papers/2606.14249

标题三个形容词就是定位:可组合、可适配、可演化的 agent harness 工厂。
💡 insight:foundry(铸造厂)这个词暗示 agent 已经在 mass production 阶段——量产意味着模板化、配置化、监控化。这跟 2024 年"每个 agent 都是手工小作坊"是两个时代。
FastContext: Training Efficient Repository Explorer for Coding Agents
84👍
2606.14066|HF: https://huggingface.co/papers/2606.14066

专门给 coding agent 训练仓库探索器——给 agent 一个项目,怎么以最少 context 找到关键文件。
💡 insight:context window 不是越大越好——上 128k token 越想包越多东西,真正稀缺的是"知道该看哪几个文件"。这是新一代 coding agent 的 differentiation。
Orchestra-o1: Omnimodal Agent Orchestration
41👍 · 8 评论 ⭐ 最热评论
2606.13707|HF: https://huggingface.co/papers/2606.13707

多 agent + 多模态的 orchestration——一个总指挥 agent,子 agent 各自负责视觉/音频/代码/搜索。
💡 insight:单 agent + 多 tool vs 多 agent + 单职能,哪种好?目前 orchestration 这条路在赢——因为可观测、可调试、可独立优化。
Data Journalist Agent: Transforming Data into Verifiable Multimodal Stories
118👍 · 5 评论
2606.11176|HF: https://huggingface.co/papers/2606.11176
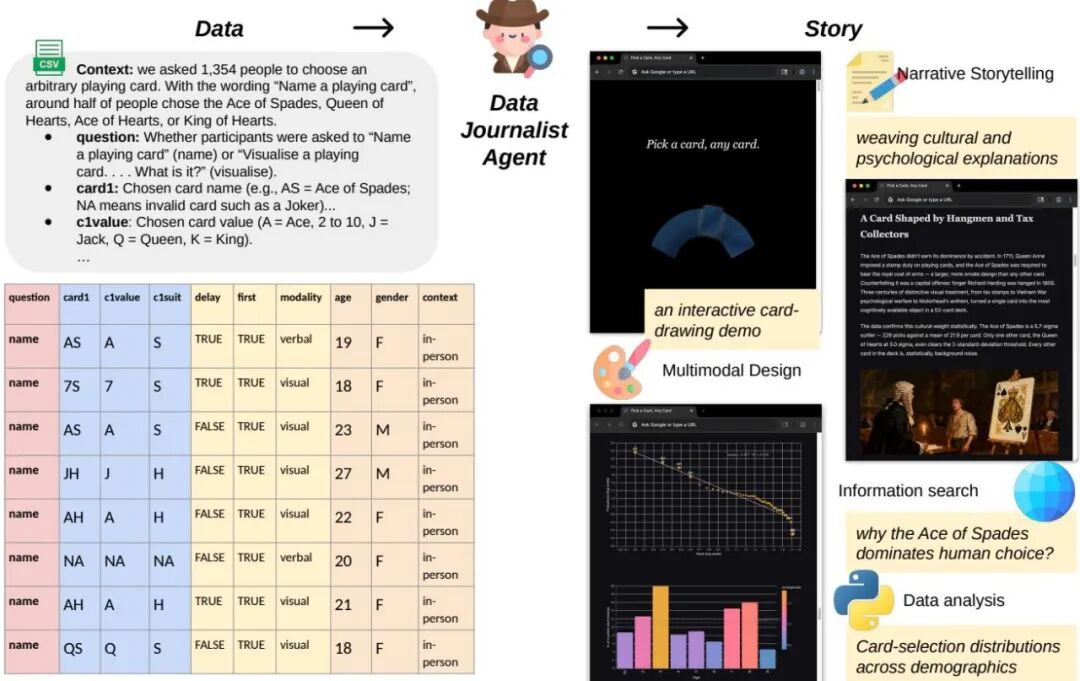
输入 raw 数据,输出可验证的多模态故事(图表 + 文字 + 引用)。每个论点必须能 trace 回原始数据。
💡 insight:generative 内容时代,"可验证(verifiable)"是新关键词——不是只生成结果,要能 trace 来源、可被审计。这是从 demo 到生产的关键一跃。
APPO: Agentic Procedural Policy Optimization
74👍
2606.12384|HF: https://huggingface.co/papers/2606.12384

针对 agentic task 设计的 RL 算法,从 PPO 改造,对 procedure(多步推理 + tool use)友好。
💡 insight:agent 的 RL 跟 LLM 的 RLHF 不一样——奖励信号不在每个 token,而在多步行为序列的某个点。专门算法在产生。
💎 趋势四一句话记忆:Agent 从 prompt+tool 进入 harness+orchestration——主角换人了。reasoning 是它的算法,harness 是它的操作系统。
🎯 趋势五 · 评测时代切换:从答题到造世界
静态 benchmark 都是 Markov 的,现实从来不是——本周一组论文给评测画了新三角:动态、对抗、长期。
静态 benchmark(MMLU、HumanEval)saturate 之后,本周一组论文提出新方向——动态环境、对抗输入、长期任务。
📜 这条线的历史脉络
·2020-2022 MMLU / BIG-Bench 等通用知识 benchmark 主导,模型靠 prompt 工程就能爬榜。
·2023-2024 GSM8K / HumanEval / MATH 等推理 benchmark 主导,多步推理进入评测视野,但仍是静态题集。
·2024 ARC-AGI 提出"评测 should be 抽象推理",但仍是固定题集;GAIA / SWE-Bench 等 agent benchmark 出现,引入工具使用维度。
·2025 LiveCodeBench / Live benchmarks 试图通过"时间窗"避免数据污染,但本质仍是答题。
·2026 本周 Beyond Markov Games / GameCraft-Bench / Epistemic Resilience 同时提出三个新方向——动态环境、构造任务、对抗 context——这是从"评测能不能答题"到"评测能不能在真实场景里活下来"的范式切换。
新评测三要素(动态 / 对抗 / 长期)一旦成为共识,整个 leaderboard 文化都会重构——因为静态 benchmark 的"分数 → 排名 → 营销"链路会失效。
💡 真正的 insight
静态 benchmark 的本质:固定问题集 + 固定答案 + 一次性评分。它们已经被 RL/数据增强吃透。新一代 eval 的共同点是:环境会变 / 输入会骗你 / 任务跨多 episode。
🛠 学到什么:内部评测自家 agent 时,别再做单题集 benchmark——做 3 件事:(1) 环境可变(每次跑参数不同);(2) 长任务(agent 跑 10+ 步才打分);(3) 对抗输入(故意误导)。这是新的评测三要素。
代表论文
Beyond the Current Observation: Evaluating MLLMs in Controllable Non-Markov Games
43👍 · 5 评论
2606.19338|HF: https://huggingface.co/papers/2606.19338
设计非马尔可夫游戏环境评测 MLLM——agent 不能只看当前帧做决策,必须记住几步之前发生了什么。
💡 insight:现实世界几乎都是 non-Markov。static benchmark 都是 Markov,因为单题独立——这是 benchmark 与现实之间最大的 gap。
GameCraft-Bench: Can Agents Build Playable Games End-to-End in a Real Game Engine?
46👍 · 5 评论
2606.17861|HF: https://huggingface.co/papers/2606.17861
让 agent 在真实游戏引擎里端到端造一个可玩的游戏——从代码到资源到设计。
💡 insight:这是 agent 评测的"图灵测试 2.0"——不是回答问题,是做出一个能用的东西。
Measuring Epistemic Resilience of LLMs Under Misleading Medical Context
52👍 · 2 评论
2606.12291|HF: https://huggingface.co/papers/2606.12291
测 LLM 在误导性医学上下文下还能不能给出正确答案——既考察知识、又考察对错误信号的免疫。
💡 insight:现实 LLM 部署最大的风险不是"不知道",是"被错误 context 带偏"。这个 benchmark 直接对准了那个 risk。
💎 趋势五一句话记忆:静态 benchmark 都是 Markov 的,现实从来不是——eval 的新三角是动态、对抗、长期。
🔍 额外值得读的 3 篇
Memory is Reconstructed, Not Retrieved: Graph Memory for LLM Agents
67👍
2606.06036|HF: https://huggingface.co/papers/2606.06036

观点很大胆:LLM 的记忆不是"调取",是"重构"——人脑也是这样。提出基于图的动态 memory 系统。
💡 insight:RAG 那一套 "retrieve top-K chunks" 假设 memory 是数据库;但人类记忆从来不是。graph memory 这条路很可能是 RAG 的下一代。
From Chatbot to Digital Colleague: The Paradigm Shift Toward Persistent Autonomous AI
51👍 · 3 评论
2606.14502|HF: https://huggingface.co/papers/2606.14502
观点性论文——argue chatbot 是过渡形态,persistent autonomous "digital colleague" 才是终点。
💡 insight:persistent + autonomous 这两个关键词,跟 JoyAI-VL 的"始终在场"是同一个 vision。整个行业正在从"AI 助手回答你"过渡到"AI 同事跟你协作"。
Ling and Ring 2.6 Technical Report: Efficient and Instant Agentic Intelligence at Trillion-Parameter Scale
74👍 · 2 评论
2606.15079|HF: https://huggingface.co/papers/2606.15079
万亿参数 agentic intelligence 的工程报告。读 architecture + inference engineering 部分。
💡 insight:万亿参数 agentic system 在落地,"agent + 大模型" 已经不是研究而是工程。
✅ 行动清单(这周值得做的 5 件事)
1.如果你做模型架构设计 → 读 LoopCoder-v2,理解 PLT 的 KV-cache 优化模式和 loop count 的 gain-cost 框架,作为下一代架构的设计参考。(注意:这是预训练架构,不是推理时旋钮。)
2.如果你做机器人 / VLA → 读 Geometric Action Model + ACE-Ego-0,思考自家数据里 egocentric 视频和 3D 几何信号怎么混合用。
3.如果你做 agent 平台 → 读 HarnessX + Orchestra-o1 抽 5 个工程模式(context 管理、tool 选择、多 agent orchestration、failure 恢复、observability),独立于具体框架。
4.如果你做 LLM 内部部署 → 把任务分类成"可验证 vs 不可验证",可验证的试 3-7B + 强 RL(VibeThinker pipeline),cost 一个数量级降。
5.如果你做 evaluation → 别再做静态 benchmark,开始设计动态/对抗/长期任务。本周 3 篇 eval 论文是模板。
📚 来源 / 数据
·数据来源:Hugging Face Daily Papers 本周 06-15 ~ 06-19
·论文聚合:PaperScope
·本周共 193 篇,本文盘点 20 篇 top(按 upvotes + 评论数 + 代表性筛选)
·完整周报 / 每日新论文:访问 https://www.paperscope.ai
⚖️ 反方观点 · 这些趋势可能被高估的地方
为了避免单边鼓吹,我们对每条主线列一个最有力的反驳。一份周报的价值,一半在判断,一半在能不能让你看到自己看错的可能。
| 🔁 Loop 替代深度 | ||
| 🌍 World Model 成基础设施 | ||
| 🤖 Agent harness 工程化 | ||
| ⚡ 3B 做 verifiable reasoning | ||
| 🎯 评测三要素 |
💎 判断的智慧:本周三条主线都是真趋势,但每条都有可能在 6-12 个月内被反方观点部分证伪。读者拿这份周报的最大价值,不是当结论,是当思维框架——5 个方向你都需要持续追踪 vs 你的反方观点。
💼 角色对照 · 这周你最该读哪几篇?
每篇 paper 都有一个最该用它的人。下表帮你定位:
| 👨💻 算法 / 架构工程师 | ||
| 🤖 机器人 / 具身研究者 | ||
| 🏗 Agent 平台 / 工程开发者 | ||
| 📊 LLM 产品 / 后端工程师 | ||
| 🎯 ML 研究 / Eval 开发者 | ||
| 📈 PM / 创业者 / 投资人 |
🔁 转发理由(一句话给同事)
👨💻 算法工程师 → "Loop / 小模型 RL pipeline / agent harness 设计模式,3 条主线值得下周直接套用。"
🤖 机器人 / 具身研究者 → "World model 终于不只是 video gen——本周 4 篇代表论文都在重新定义它在 Physical AI 里的位置。"
🏗 Agent 平台 / 创业者 → "你正在搭的 agent,本周 5 篇论文已经把工业化的工程模式画出来了。"
📊 PM / 投资人 → "从'卷模型'到'卷系统'——本周给出了具体证据。决策方向需要更新。"
🔭 接下来 3 个月:分阶段前瞻
⏩ 下周(1-2 周内)
1.Loop count benchmark 出炉:会有 7B/13B 模型把 loop 作为 inference time 显式参数公开,配套 benchmark(loop=1 vs loop=5 在 GSM8K / MATH 上的差异曲线)。
2.VibeThinker 复刻潮:Spectrum-to-Signal pipeline 会被多家在 1-2 周内复刻并在 LiveCodeBench / AIME 上跑分。
3.Long-horizon world model benchmark:Physical AI 缺 benchmark 这件事被多人意识到,新评测(camera-revisit consistency / 5min long horizon coherence)大概率本周出。
📅 1 个月内
4.dLLM 趋势成形:本周已经有 2 篇(Self-future distillation + Reliable Trajectories)—— dLLM 这条线 1 个月内会有 3-5 篇 follow-up,可能挑战 autoregressive LLM 在某些任务的优势。
5.Agent harness 接口标准化讨论:HarnessX、Orchestra-o1 各自定义 API,1 个月内行业会出现"agent harness interface" 类的 RFC / blog 讨论,可能由 OpenAI、Anthropic 或 LangChain 主导。
6.小模型可验证推理产品落地:3B 验证推理 frontier 出来后,1 个月内会有第一波"垂直 3B reasoning 服务"上线(SQL / 数学 / 法律推理 / 医疗逻辑判断等)。
🌅 3-6 个月
7.VLA 数据 scaling 突破:ACE-Ego-0 是开始,3-6 个月内会出现"百万小时 egocentric + 机器人混合数据"的预训练大模型,可能改写 VLA leaderboard。
8.Agent Foundry 工业化标准:HarnessX 是单论文,3-6 个月内会出现"agent foundry"作为独立产品类目(类似 K8s 之于容器编排),可能伴随并购或开源大事件。
9.静态 benchmark 集体让位:动态评测一旦被几个标杆模型采用,整个 leaderboard 文化重构——MMLU 类静态榜的引用率会显著下降,新的动态 / 长期榜成为头条。
10.Physical AI 工业产品:Kairos 这类"原生 stack" 会催生第一批针对工业场景(仓储 / 巡检 / 制造)的 Physical AI 产品发布——不是 demo,是真发货。
📖 延伸阅读 · 想深挖某条主线?
🔁 Loop / Test-time scaling 这条线
·基础:Dehghani et al. 2018 *Universal Transformers*(arXiv:1807.03819)—— weight sharing + adaptive computation 的奠基论文
·2024 复兴:Looped Transformers as Programmable Computers(NeurIPS 2024)—— 把 loop 当作可编程指令的视角
·背景阅读:OpenAI o1 system card 中 test-time scaling 的产品视角
🌍 World Model 这条线
·奠基:Ha & Schmidhuber 2018 *World Models*(arXiv:1803.10122)—— 这个方向的源头
·里程碑:Dreamer V3(Hafner et al. 2023, arXiv:2301.04104)—— world model + RL 的工业化样本
·背景阅读:Yann LeCun: A Path Towards Autonomous Machine Intelligence —— world model 为什么重要的总论
🤖 Agent Harness 这条线
·入门:LangGraph 文档 —— graph-based agent 编排的工业基线
·进阶:DSPy 论文(Khattab et al. 2023, arXiv:2310.03714)—— agent as program 的视角
·背景:Andrew Ng: AI Agents 2024 综述 —— agent 这一年的发展节奏
⚡ Verifiable Reasoning + 小模型
·历史:DeepSeek-R1 论文 —— RL 蒸馏的拐点
·小模型路线:Phi-3 技术报告 —— 高质量数据 + 小参数的方法论
·背景阅读:The Bitter Lesson —— 关于"scale vs 巧设计"的经典反思
🎯 评测
·历史:HELM project —— Stanford 标准化评测项目
·新方向:ARC-AGI 评测 —— 抽象推理评测的源头
·背景:Chollet 2024 *On the Measure of Intelligence*(arXiv:1911.01547)
📺 P 站内部相关阅读(互链)
·📰 上周 HF 周报:卷模型时代正式终结,AI 研究的新前沿是评测、架构和 reward 结构
·🎯 4069 篇论文透视 CVPR 2026 八大视觉趋势
·🏗 30 篇代表论文拆解:CVPR 2026 AI 基础设施 4 大工程主线
📡 订阅 P 站
如果这篇对你有用,订阅 P 站本周持续更新:
·📰 每周 HF 周报 → P 站 Insights(每周六更新)
·🤖 接入你的 agent / Claude Code → 一行命令装 PaperScope skill
·🔍 每日新论文 → HF 入口 / arXiv 入口
·🎯 顶会专题 → CVPR 2026(4069 篇)/ ACL 2025 / NeurIPS 2025
✍️ 写在最后
本周三条主线(Loop / World Model / Agent Harness)的共同点是——AI 正在从"模型"过渡到"系统"。
模型还是基础,但已经不再是最稀缺的资源了。
Loop 怎么调、world model 怎么训、harness 怎么搭——这些是工程问题,不再是研究问题。
而工程问题,意味着:有标准答案,有可复用 pattern,有可量化指标。
💎 一句话送你:"当 AI 进入工程时代,跑得快的人不是模型最大的,是 stack 最薄的。"
*[由 PaperScope (P 站) 与机智流(A 站)联合署名|2026-06-20]*
*[本周报为开源内容,欢迎转发、引用、改编。如需深度合作或定制周报,联系 https://github.com/vansin/queue/issues]*
每一篇代表论文,都能点开读全文
PaperScope 收录 9 万+ 篇论文的中文深度解析,HF Daily Papers 全量可检索。点「阅读原文」进 PaperScope 看本期完整盘点。
读到这儿,说明你真的关心 AI 研究的走向 🙏
如果有收获,欢迎 点赞、在看、转发 三连
想追更记得加个 星标 ⭐ 我们下周见 👋
© 2026 PaperScope × 机智流 联合出品 · 本文由论文库解析生成,可能有误