
> 本文来自社区投稿
逻辑智能团队关于低资源语言 TTS 的研究论文被机器学习顶级会议 ICML 2026 接收。该工作证明,即使真实语音数据稀缺,合成数据也能训练出稳定、自然、可克隆的语音模型。
作者丨逻辑智能
SE-Bridge-TTS 是一套面向低资源语言的语音合成方案,核心能力是:在真实语音数据稀缺的情况下,仍然生成稳定、自然、可克隆的多语言语音,可用于博客配音、视频翻译配音、跨语言内容本地化、数字人、语音助手和小语种内容生产。
逻辑智能邀请您体验免费配音,官网:https://luoji.cn/
开源项目 Video Translator:面向 AI 编程助手和 Agent 工作流,支持通过 Skill 方式快速接入,方便开发者在现有工具链中一键安装和使用,也可参考其实现扩展到更多国内外 AI 编程工具。
项目地址:https://github.com/InsiderX-Pro/video-translator
近一年,多语言 TTS 正在成为语音生成领域的主流方向。新的系统不断出现,目标也越来越统一:支持更多语言、更多说话人、更强的跨语言提示合成,以及 0-shot voice cloning。
但多语言覆盖并不等于低资源语言真的被解决了。对泰语、老挝语这类小语种来说,模型能“支持”某个语言,和模型能在这个语言上稳定、自然、像目标说话人一样生成语音,是两件不同的事。
SE-Bridge-TTS 的切入点正是在这里。它没有从头训练一个更大的多语言基础模型,而是基于 CosyVoice2 这样的开源底座,从数据层面重新拆解低资源 TTS:真实语音稀缺时,合成数据该如何使用?合成数据越多是否一定越好?当发音稳定性和语音表现力发生冲突时,训练流程应该如何修正?
这项工作已被 ICML 2026 接收。更关键的是,项目近期公开了 Thai / Lao 权重,并补充了 FLEURS Lao/Thai 多语言提示评测:在与 Higgs Audio v3、OmniVoice、X-Voice Stage1 等近期开放多语言 TTS 系统的对比中,SE-Bridge-TTS 在老挝语和泰语目标语言上达到与现有 SOTA 一致甚至更优的效果。
论文标题 | Bridging the Stability-Expressivity Gap: Synthetic Data Scaling and Preference Alignment for Low-Resource Spoken Language Models |
项目名称 | SE-Bridge-TTS |
会议 | ICML 2026 |
关键词 | Spoken Language Models · Low-Resource TTS · Preference Alignment · Zero-Shot Voice Cloning |
论文链接 | https://arxiv.org/abs/2605.27383 |
项目主页 | https://insiderx-pro.github.io/SE-Bridge-TTS/ |
官方仓库 | https://github.com/InsiderX-Pro/SE-Bridge-TTS |
模型权重 | https://huggingface.co/isabeth/SE-Bridge-TTS |
开源项目地址 | https://github.com/InsiderX-Pro/video-translator |
项目企业官网 | https://luoji.cn/ |
低资源语言的 TTS 系统长期受限于真实标注语音不足。合成数据看似是最直接的扩容方案:它能提供稳定的文本-语音配对,帮助模型学会发音和读词。但论文系统性地证明,合成数据并不是简单的“越多越好”。
在泰语实验中,随着合成数据比例提高,词错误率(WER)持续下降,说明发音稳定性确实改善;但超过关键比例后,语音 token 熵、自然度 MOS、说话人相似度 MOS 都开始下降,重复率显著上升。论文将这种现象命名为 Synthetic Erosion:低熵、平坦的合成语音分布逐渐侵蚀模型从预训练骨干中继承的表现力。
围绕这一问题,论文提出“稳定性-表现力鸿沟”(Stability-Expressivity Gap),并给出两套自对齐框架:DGSA 用于有一定真实参考语音的场景,通过韵律-音色解耦自动构造偏好样本;TDSC 用于几乎没有真实语音锚点的极低资源场景,通过多温度采样、ASR 过滤和迭代偏好学习,让模型在纯合成训练下逐步自我修正。
01
多语言 TTS 已经很热,但低资源语言仍然难做
过去一年,多语言 TTS 正在快速成为语音生成领域的重要方向。越来越多系统开始强调多语言覆盖、跨语言 prompt 合成、多说话人建模以及 0-shot voice cloning 能力。
但“支持某种语言”和“真正把这种语言说好”,并不是一回事。
对于泰语、老挝语这类低资源语言来说,模型不仅要读准文本,还要保持自然韵律、稳定发音和目标说话人的声音特征。尤其在 0-shot voice cloning 场景中,系统需要根据一小段参考音频,在目标语言中生成像同一位说话人所说的语音,这对模型的数据覆盖、音色建模和跨语言泛化能力都提出了更高要求。
低资源语言的难点并不只来自模型结构。更核心的问题往往是训练数据不足:高质量标注语音少,公开语料有限,语言内部还可能包含复杂的声调、音系变化和口音差异。合成数据因此成为一种直观的补充手段,但它带来的影响并不完全正向。
SE-Bridge-TTS 关注的正是这个问题:在不重新训练一个庞大多语言基础模型的前提下,能否基于 CosyVoice2 这样的开源底座,通过更合理的数据与训练策略,把低资源语言 TTS 做到足够稳定、自然且可复用?
02
合成数据能补稳定性,也可能损失表现力
论文首先系统研究了合成数据比例对低资源 TTS 的影响。研究团队固定使用 300 小时真实泰语语音,并将合成语音规模从 10 小时逐步增加到 1500 小时,对应合成数据比例 α 从 3% 提升到 100%。
实验显示,合成数据带来的收益并不是线性增长。
当 α ≤ 50% 时,合成数据能够同时改善稳定性和表现力。WER 从 75.0% 降至 47.0%,说明发音错误明显减少;自然度 NMOS 从 3.82 提升至 4.51,说话人相似度 SMOS 也从 4.31 提升至 4.63。
但当 α 继续升高,问题开始出现。
在 α = 80% 时,WER 进一步下降到 38.9%,模型读得更准;但 NMOS 降到 3.61,SMOS 降到 3.54,重复率也从 2.16% 上升到 6.51%。当训练进入 100% 纯合成设置时,WER 虽然达到 36.2%,但 NMOS 只剩 3.08,重复率升至 9.83%。
也就是说,合成数据继续帮助模型“读对”,却开始让模型“说得不自然”。论文将这一现象称为 Synthetic Erosion:低熵、分布更平坦的合成语音逐渐侵蚀模型从预训练骨干中继承来的语音表现力。
这一发现也引出了论文的核心问题:低资源 TTS 并不是单纯的数据规模问题,而是稳定性与表现力之间的结构性权衡。WER、CER 等自动指标可以衡量模型是否读准,但一个真正可用的 TTS 系统,还需要自然韵律、丰富表达和稳定的说话人身份保持。

03
SE-Bridge-TTS 的路线:不重造底座,而是重做数据方案
SE-Bridge-TTS 并不是从零开始训练新的多语言大模型,而是基于 CosyVoice2 生态构建低资源语言增强方案。项目已经发布 Thai / Lao 两个 checkpoint,官方 Hugging Face model card 也说明,这些权重属于 CosyVoice2 LLM checkpoints,需要配合 CosyVoice2-compatible checkout 以及标准 CosyVoice2 base model assets 使用。
这意味着,SE-Bridge-TTS 更像是一套围绕开源底座设计的低资源训练 recipe:它先识别合成数据带来的 Stability-Expressivity Gap,再针对不同资源条件下的语言,分别设计训练和对齐方法。
论文提出两套核心框架:
DGSA(Disentanglement-Guided Self-Alignment)用于目标语言仍有一定真实语音参考的场景,重点解决高合成数据比例下的表现力退化。
TDSC(Temperature-Driven Self-Critique)用于真实语音锚点极少、甚至几乎只能依赖合成数据的场景,重点解决纯合成训练下模型如何自我改进的问题。
这两套方法分别对应低资源语言开发中的两类常见情况:一种是“数据少但仍有真实参考”,另一种是“真实语音几乎不可用,只能靠合成数据起步”。
04
DGSA:当有少量真实语音时,用偏好对齐恢复自然度
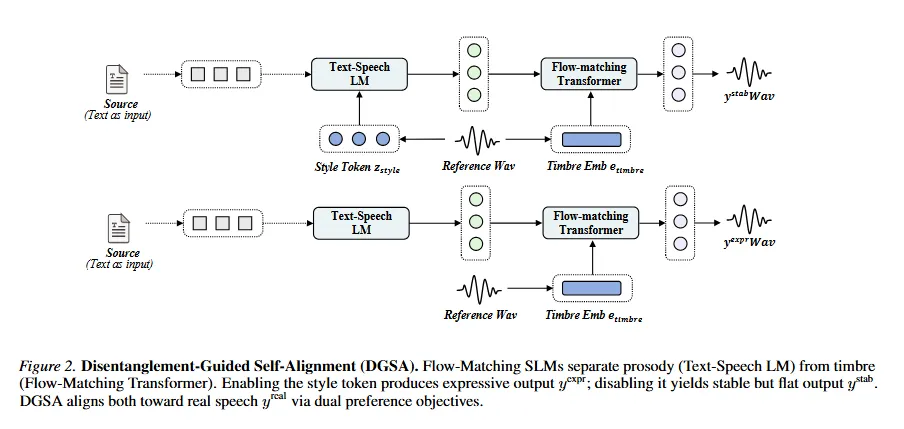
DGSA 适用于相对有利的低资源设定:目标语言虽然缺少大规模高质量数据,但仍有一定真实语音可作为参考。它利用 Flow-Matching SLM 中内容、韵律与音色建模的结构特点,构造偏好数据并进行对齐训练。
在这类模型中,Text-Speech LM 更关注内容和韵律相关的离散 token,Flow-Matching Transformer 则通过参考音频提取音色 embedding,用于维持说话人身份。换句话说,模型内部天然存在一定程度的“韵律—音色”解耦。
DGSA 正是利用这一点,让同一个模型在相同文本、相同参考说话人的条件下生成两类互补样本:
一种开启 style token,生成更有表现力的语音,但可能伴随更高发音错误;另一种关闭 style token,生成更稳定的语音,但韵律更平、表达更弱。
真实语音同时具备稳定性和表现力,因此可以作为偏好学习中的正向参考。随后,DGSA 采用双目标 DPO 进行对齐:一组偏好用于纠正表现力输出中的发音问题,另一组偏好用于修正稳定输出中的韵律平坦问题。
训练过程中,DGSA 还引入动态权重调度。当合成比例 α ≤ 50% 时,模型尚未出现明显 Synthetic Erosion,训练主要保持稳定性;当 α 超过临界点后,表现力目标逐步增强,用于抵消过量合成数据带来的自然度损失。
在 α = 80% 的高合成比例实验中,DGSA 在基本保持 SFT 基线 WER 的同时,显著恢复了自然度、说话人相似度和 token 熵。相比之下,标准 DPO 虽然能提升表现力,但会导致 WER 恶化,说明单一偏好目标容易让模型在自然度和发音准确性之间失衡。
05
TDSC:没有真实语音锚点时,让模型自己筛选、自己修正
老挝语对应的是更困难的低资源场景:目标语言中可用的高质量真实语音非常有限,难以直接像 DGSA 那样依赖真实样本构造偏好对。
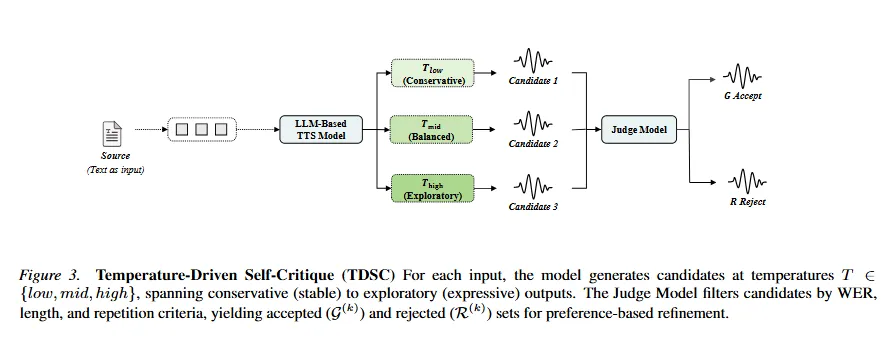
为此,论文提出 TDSC。它的核心思路是让模型通过多温度采样产生候选,再用自动指标筛选,并通过迭代训练不断改善自身生成策略。
具体来说,TDSC 会对同一输入文本使用多个采样温度生成语音候选。低温采样更保守,通常发音更稳,但韵律较平;高温采样探索性更强,可能带来更丰富的表达,但也更容易出错;中温采样则处于二者之间。
生成候选后,Judge 模块会根据 ASR 结果、语音长度、重复率等指标进行过滤。质量较好的样本进入 accepted set;错误更明显但仍满足基础约束的样本进入 rejected set。随后,系统先用 accepted samples 做 SFT,帮助模型建立更稳定的生成能力,再用 accepted/rejected pairs 做 DPO,让模型学会区分更优和更差的候选,从而减少幻觉、重复和错误发音。
随着训练迭代推进,TDSC 会逐步扩大高温采样范围。模型先获得基础稳定性,再逐渐恢复更大的韵律探索空间。
在老挝语实验中,TDSC 从同一个纯合成 SFT 基线出发,将 WER 从 38.5% 降至 29.8%,重复率从 7.62% 降至 4.15%,NMOS 从 3.12 提升至 3.94。这说明 TDSC 不只是推理阶段的筛选机制,而是通过闭环训练改变了模型自身的生成策略。
06
实验与新公开评测:在近期多语言 TTS 对比中仍然领先
论文在泰语和老挝语上比较了开源系统、商业 API 和 SE-Bridge-TTS。泰语实验主要使用 DGSA,老挝语实验主要使用 TDSC;评测覆盖标准 TTS 和 0-shot 语音克隆任务。
整体结果表明,低资源语言 TTS 并不必然在“读得准”和“说得自然”之间二选一。只要显式处理合成数据导致的分布压缩,并通过偏好对齐修正模型,系统可以同时提升发音准确性、自然度和说话人相似度。

我们的方法在发音准确性与语音自然度上整体优于开源及商业系统
项目近期还补充了一个可复现的 FLEURS Lao/Thai benchmark,用于比较 SE-Bridge-TTS 与 Higgs Audio v3、OmniVoice、X-Voice Stage1 等近期开放多语言 TTS 系统。
该评测包含 255 组 Lao/Thai paired target sentences,并使用 Lao、Thai、Chinese、English 作为 reference prompt language。不同模型需要在统一输入条件下生成语音,包括 target_text、prompt_audio、prompt_text、target_language_id 和 prompt_language_id。
其中最核心的结果来自 Chinese/English prompt → Lao/Thai target 的跨语言提示合成设置。这里的 Accuracy 基于 calibrated CER 计算:先扣除 ASR 在原始 FLEURS target audio 上的识别误差,再衡量合成语音额外引入的退化,从而降低低资源语言 ASR 本身误差对结果的影响。
指标定义 calibrated CER = max(0, generated CER - ground-truth CER);Accuracy = 1 - calibrated CER。 |
模型 | 支持样本 | Accuracy ↑ | Speaker similarity ↑ |
Higgs Audio v3 | 1020/1020 | 78.2% | 0.520 |
OmniVoice | 1020/1020 | 75.9% | 0.645 |
SE-Bridge-TTS | 1020/1020 | 83.4% | 0.593 |
X-Voice Stage1 | 510/1020 | 53.7% | 0.361 |
表 2:Chinese/English prompt → Lao/Thai target 的跨语言提示合成主结果
从结果看,SE-Bridge-TTS 在总体 Accuracy 上达到 83.4%,高于 Higgs Audio v3 的 78.2%、OmniVoice 的 75.9% 和 X-Voice Stage1 的 53.7%。在 speaker similarity 上,SE-Bridge-TTS 为 0.593,低于 OmniVoice 的 0.645,但高于 Higgs Audio v3 和 X-Voice Stage1。
此外,X-Voice Stage1 在该评测中的 Lao 方向暂不支持,覆盖率为 510/1020;SE-Bridge-TTS 则完成了 1020/1020 全样本覆盖。
这说明 SE-Bridge-TTS 的价值并不局限于论文原始实验设定。即使放入近期多语言 TTS 系统的统一对比框架中,它仍然在低资源语言合成上保持了较强竞争力。
07
为什么 SE-Bridge-TTS 值得关注
SE-Bridge-TTS 的意义不只是某一项指标更高,而是提供了一种更可迁移的低资源 TTS 思路。
首先,它把问题从“模型是否足够大”转向“数据分布是否被正确处理”。对于低资源语言来说,真正的挑战往往不是模型完全不会说,而是有限真实数据和大量合成数据之间存在分布冲突。合成数据可以提供发音覆盖,但也可能带来韵律单一、表现力下降和重复率上升。
其次,它建立在开源底座之上。项目发布的 Thai / Lao 权重是 CosyVoice2-compatible checkpoint,推理和部署说明也围绕 CosyVoice2 展开。这降低了复现门槛,也使方法更容易被迁移到其他低资源语言中。
第三,它覆盖了两类典型低资源场景。DGSA 适合仍有少量真实参考语音的语言,用于修复高合成比例下的表现力退化;TDSC 适合真实语音锚点极少的语言,通过多温度采样、自我筛选和偏好学习,让模型在近似纯合成训练条件下持续改进。
第四,项目提供了相对完整的公开资产。官方仓库包含项目页面、音频 Demo、FLEURS 评测协议、结果 CSV 和 table renderer;Hugging Face 提供模型权重和推理说明。这使得结果不只停留在论文表格中,而是可以被听到、复现和进一步测试。
从研究和应用角度看,如果一种语言缺少大规模高质量录音,但仍能获得基础文本、少量真实语音和可用 ASR,那么类似流程就具备迁移空间:以开源 TTS / SLM 底座为初始化,用合成数据补足发音覆盖,持续监控稳定性与表现力的变化,并根据真实语音可用程度选择 DGSA 或 TDSC 进行偏好对齐和迭代训练。
08
结语
多语言 TTS 的趋势还会继续,模型也会越来越大、覆盖越来越广。但 SE-Bridge-TTS 提醒我们:低资源小语种真正需要的,不一定总是更大的模型,而是更懂数据分布的训练方案。
基于 CosyVoice2 这样的开源底座,SE-Bridge-TTS 通过合成数据 scaling、DGSA 和 TDSC,把低资源语言中的稳定性与表现力矛盾拆开处理,并在新的 FLEURS Lao/Thai 评测中达到甚至超过近期多语言 TTS SOTA 的效果。
一句话概括:合成语音不只是更多数据。它能补足稳定性,也会压缩表现力;SE-Bridge-TTS 的价值,就是让低资源语言模型重新学会自然地说话。
09
更多信息
企业体验官网
https://luoji.cn/
SE-Bridge-TTS 项目主页
https://insiderx-pro.github.io/SE-Bridge-TTS/
SE-Bridge-TTS 官方仓库
https://github.com/InsiderX-Pro/SE-Bridge-TTS
模型权重
https://huggingface.co/isabeth/SE-Bridge-TTS
开源项目 Video Translator
https://github.com/InsiderX-Pro/video-translator
Video Translator 面向 AI 编程助手和 Agent 工作流,支持通过 Skill 方式快速接入,可用于开发者在现有工具链中安装、使用或参考扩展到更多 AI 编程环境。

-- 完 --
机智流推荐阅读:
1.
2.
3.
4.
cc | 大模型技术交流群 hf | HuggingFace 高赞论文分享群 lc|LangChain 技术交流群 code | AI Coding 交流群 具身 | 具身智能交流群 硬件 | AI 硬件交流群 推理 | AI 推理框架交流群 Agent | Agent 技术交流群










